[feat]内容重构,删除无用文章,优化文件名
Showing
文件已移动
文件已移动
文件已移动
文件已移动
文件已移动
文件已移动
文件已移动
docs/database/数据库连接池.md
已删除
100644 → 0
{kind=link}
39.9 KB
.png){kind=link}
.png)
59.4 KB
{kind=link}
67.4 KB
{kind=link}
59.3 KB
{kind=link}
15.7 KB
.png){kind=link}
.png)
67.4 KB
{kind=link}
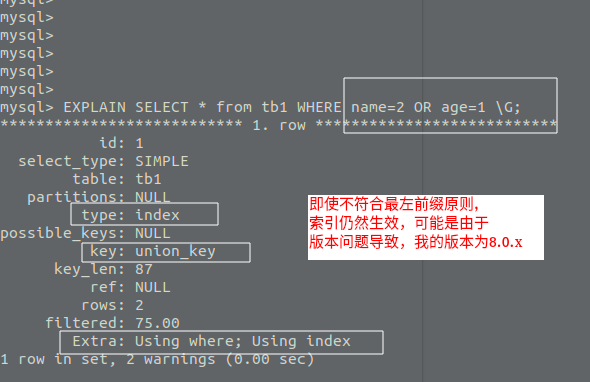
50.4 KB
从无法访问的项目Fork
39.9 KB
59.4 KB
67.4 KB
59.3 KB
15.7 KB
67.4 KB
50.4 KB