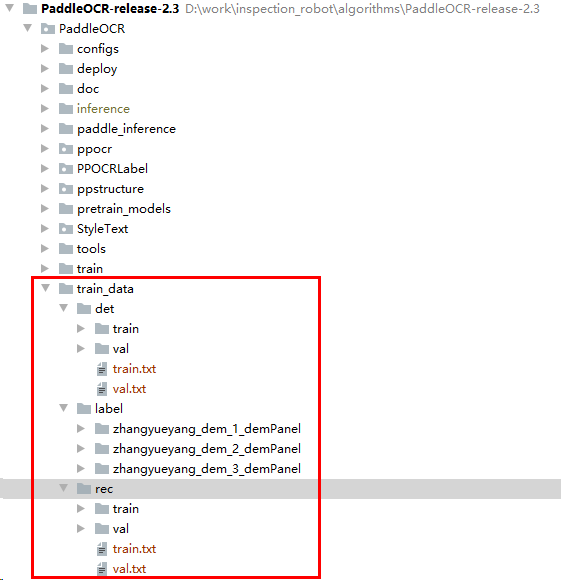
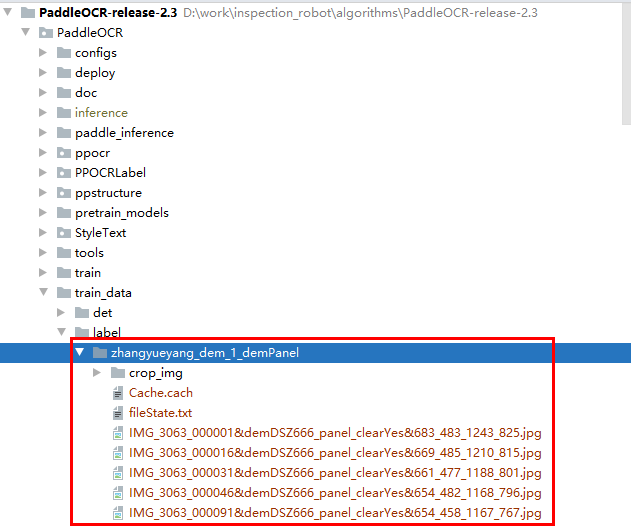
数据集划分
Showing
20211008154929.png
已删除
100644 → 0
{kind=link}
18.9 KB
20211008155029.png
已删除
100644 → 0
{kind=link}
25.1 KB
gen_ocr_train_val.bat
已删除
100644 → 0
gen_ocr_train_val.py使用说明.md
已删除
100644 → 0
gen_ocr_train_val.sh
已删除
100644 → 0