Skip to content
体验新版
项目
组织
正在加载...
登录
切换导航
打开侧边栏
weixin_41840029
PaddleOCR
提交
bc7ea032
P
PaddleOCR
项目概览
weixin_41840029
/
PaddleOCR
与 Fork 源项目一致
Fork自
PaddlePaddle / PaddleOCR
通知
1
Star
1
Fork
0
代码
文件
提交
分支
Tags
贡献者
分支图
Diff
Issue
0
列表
看板
标记
里程碑
合并请求
0
Wiki
0
Wiki
分析
仓库
DevOps
项目成员
Pages
P
PaddleOCR
项目概览
项目概览
详情
发布
仓库
仓库
文件
提交
分支
标签
贡献者
分支图
比较
Issue
0
Issue
0
列表
看板
标记
里程碑
合并请求
0
合并请求
0
Pages
分析
分析
仓库分析
DevOps
Wiki
0
Wiki
成员
成员
收起侧边栏
关闭侧边栏
动态
分支图
创建新Issue
提交
Issue看板
提交
bc7ea032
编写于
4月 08, 2022
作者:
T
tink2123
浏览文件
操作
浏览文件
下载
电子邮件补丁
差异文件
update result
上级
94d71d7f
变更
3
隐藏空白更改
内联
并排
Showing
3 changed file
with
11 addition
and
6 deletion
+11
-6
deploy/pdserving/README_CN.md
deploy/pdserving/README_CN.md
+3
-2
deploy/pdserving/imgs/pipeline_result.png
deploy/pdserving/imgs/pipeline_result.png
+0
-0
deploy/pdserving/pipeline_http_client.py
deploy/pdserving/pipeline_http_client.py
+8
-4
未找到文件。
deploy/pdserving/README_CN.md
浏览文件 @
bc7ea032
...
@@ -6,7 +6,6 @@ PaddleOCR提供2种服务部署方式:
...
@@ -6,7 +6,6 @@ PaddleOCR提供2种服务部署方式:
-
基于PaddleHub Serving的部署:代码路径为"
`./deploy/hubserving`
",使用方法参考
[
文档
](
../../deploy/hubserving/readme.md
)
;
-
基于PaddleHub Serving的部署:代码路径为"
`./deploy/hubserving`
",使用方法参考
[
文档
](
../../deploy/hubserving/readme.md
)
;
-
基于PaddleServing的部署:代码路径为"
`./deploy/pdserving`
",按照本教程使用。
-
基于PaddleServing的部署:代码路径为"
`./deploy/pdserving`
",按照本教程使用。
*
AIStudio演示案例可参考
[
基于PaddleServing的OCR服务化部署实战
](
https://aistudio.baidu.com/aistudio/projectdetail/3630726
)
# 基于PaddleServing的服务部署
# 基于PaddleServing的服务部署
...
@@ -19,6 +18,8 @@ PaddleOCR提供2种服务部署方式:
...
@@ -19,6 +18,8 @@ PaddleOCR提供2种服务部署方式:
更多有关PaddleServing服务化部署框架介绍和使用教程参考
[
文档
](
https://github.com/PaddlePaddle/Serving/blob/develop/README_CN.md
)
。
更多有关PaddleServing服务化部署框架介绍和使用教程参考
[
文档
](
https://github.com/PaddlePaddle/Serving/blob/develop/README_CN.md
)
。
AIStudio演示案例可参考
[
基于PaddleServing的OCR服务化部署实战
](
https://aistudio.baidu.com/aistudio/projectdetail/3630726
)
。
## 目录
## 目录
-
[
环境准备
](
#环境准备
)
-
[
环境准备
](
#环境准备
)
-
[
模型转换
](
#模型转换
)
-
[
模型转换
](
#模型转换
)
...
@@ -133,7 +134,7 @@ python3 -m paddle_serving_client.convert --dirname ./ch_PP-OCRv2_rec_infer/ \
...
@@ -133,7 +134,7 @@ python3 -m paddle_serving_client.convert --dirname ./ch_PP-OCRv2_rec_infer/ \
python3 pipeline_http_client.py
python3 pipeline_http_client.py
```
```
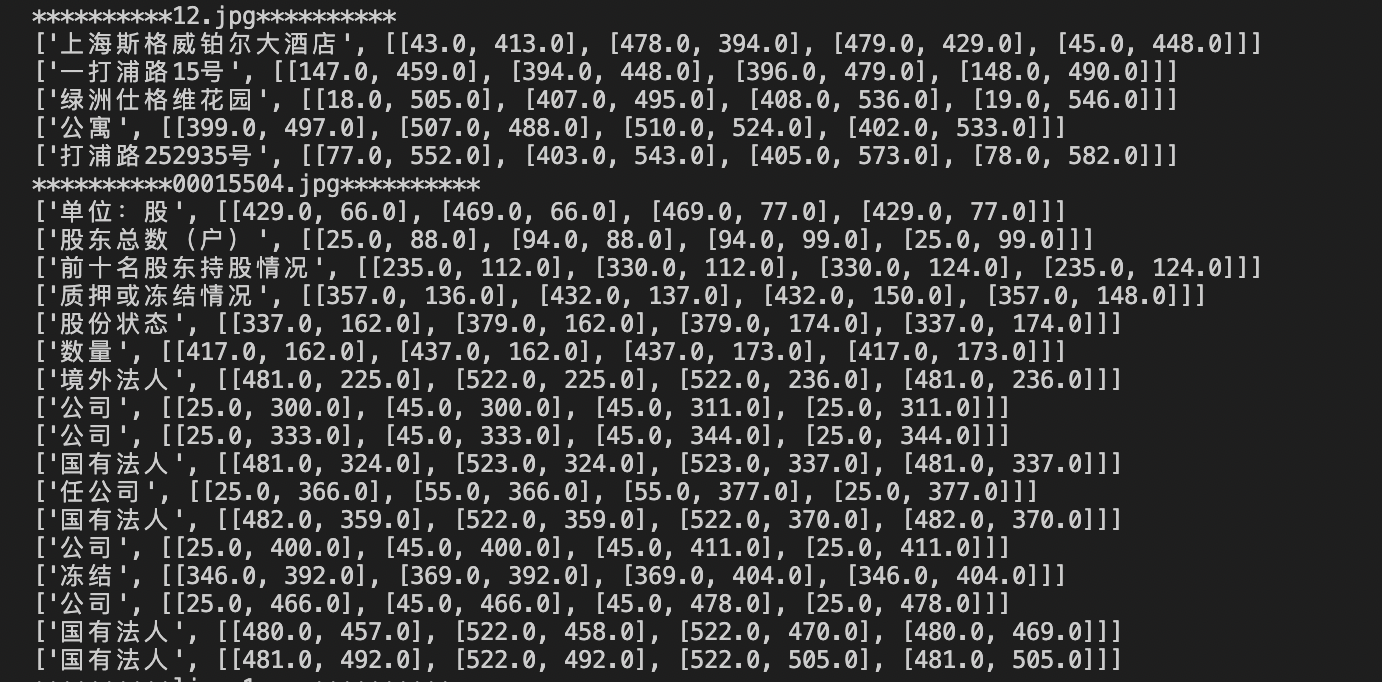
成功运行后,模型预测的结果会打印在cmd窗口中,结果示例为:
成功运行后,模型预测的结果会打印在cmd窗口中,结果示例为:
!
[](
./imgs/
results
.png
)
!
[](
./imgs/
pipeline_result
.png
)
调整 config.yml 中的并发个数获得最大的QPS, 一般检测和识别的并发数为2:1
调整 config.yml 中的并发个数获得最大的QPS, 一般检测和识别的并发数为2:1
```
```
...
...
deploy/pdserving/imgs/pipeline_result.png
0 → 100644
浏览文件 @
bc7ea032
521.8 KB
deploy/pdserving/pipeline_http_client.py
浏览文件 @
bc7ea032
...
@@ -34,12 +34,16 @@ test_img_dir = args.image_dir
...
@@ -34,12 +34,16 @@ test_img_dir = args.image_dir
for
idx
,
img_file
in
enumerate
(
os
.
listdir
(
test_img_dir
)):
for
idx
,
img_file
in
enumerate
(
os
.
listdir
(
test_img_dir
)):
with
open
(
os
.
path
.
join
(
test_img_dir
,
img_file
),
'rb'
)
as
file
:
with
open
(
os
.
path
.
join
(
test_img_dir
,
img_file
),
'rb'
)
as
file
:
image_data1
=
file
.
read
()
image_data1
=
file
.
read
()
print
(
'{}{}{}'
.
format
(
'*'
*
10
,
img_file
,
'*'
*
10
))
image
=
cv2_to_base64
(
image_data1
)
image
=
cv2_to_base64
(
image_data1
)
for
i
in
range
(
1
):
data
=
{
"key"
:
[
"image"
],
"value"
:
[
image
]}
data
=
{
"key"
:
[
"image"
],
"value"
:
[
image
]}
r
=
requests
.
post
(
url
=
url
,
data
=
json
.
dumps
(
data
))
r
=
requests
.
post
(
url
=
url
,
data
=
json
.
dumps
(
data
))
all_result
=
r
.
json
()[
"value"
][
0
]
print
(
r
.
json
())
for
item
in
eval
(
all_result
):
print
(
item
)
#print("len result:", len(result))
#print(eval(result[0]))
print
(
"==> total number of test imgs: "
,
len
(
os
.
listdir
(
test_img_dir
)))
print
(
"==> total number of test imgs: "
,
len
(
os
.
listdir
(
test_img_dir
)))
编辑
预览
Markdown
is supported
0%
请重试
或
添加新附件
.
添加附件
取消
You are about to add
0
people
to the discussion. Proceed with caution.
先完成此消息的编辑!
取消
想要评论请
注册
或
登录
{kind=link}