Merge remote-tracking branch 'origin/dygraph' into dygraph
Showing
benchmark/analysis.py
0 → 100644
benchmark/readme.md
0 → 100644
benchmark/run_benchmark_det.sh
0 → 100644
benchmark/run_det.sh
0 → 100644
configs/det/det_res18_db_v2.0.yml
0 → 100644
doc/doc_ch/enhanced_ctc_loss.md
0 → 100644
doc/doc_ch/equation_a_ctc.png
0 → 100644
{kind=link}
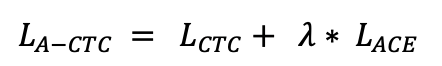
10.2 KB
doc/doc_ch/equation_c_ctc.png
0 → 100644
{kind=link}
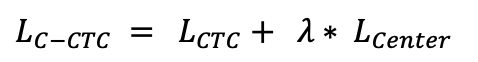
10.6 KB
doc/doc_ch/equation_ctcloss.png
0 → 100644
{kind=link}
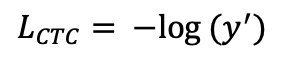
9.3 KB
doc/doc_ch/equation_focal_ctc.png
0 → 100644
{kind=link}
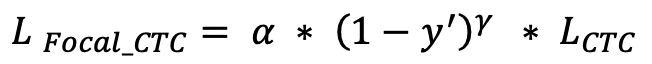
14.5 KB
doc/doc_ch/focal_loss_formula.png
0 → 100644
{kind=link}
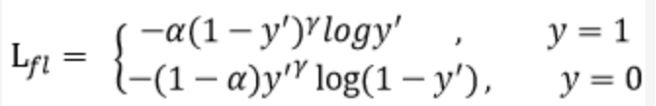
23.3 KB
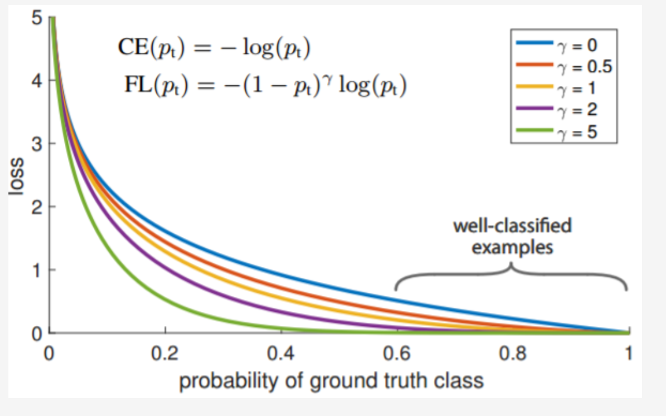
doc/doc_ch/focal_loss_image.png
0 → 100644
{kind=link}
124.7 KB
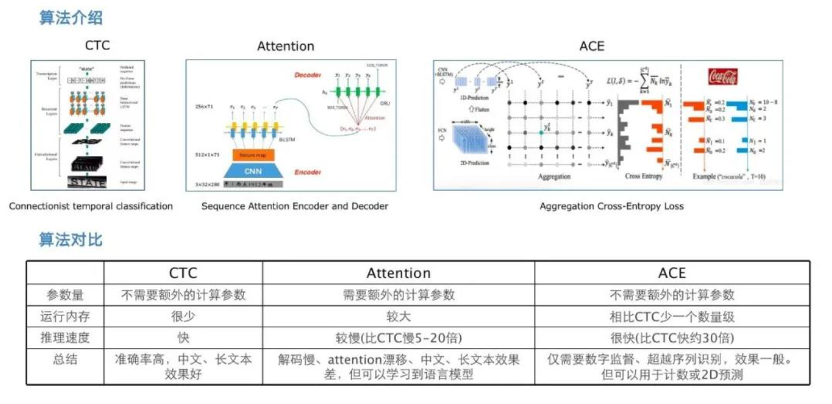
doc/doc_ch/rec_algo_compare.png
0 → 100644
{kind=link}
223.6 KB
ppocr/losses/ace_loss.py
0 → 100644
ppocr/losses/center_loss.py
0 → 100644
ppocr/losses/rec_aster_loss.py
0 → 100644
ppocr/modeling/transforms/stn.py
0 → 100644
ppocr/utils/dict90.txt
0 → 100644
ppocr/utils/profiler.py
0 → 100644
tests/common_func.sh
0 → 100644
tests/ocr_kl_quant_params.txt
已删除
100644 → 0
文件已移动
文件已移动
文件已移动
文件已移动
tests/test_cpp.sh
0 → 100644
tests/test_python.sh
0 → 100644
tests/test_serving.sh
0 → 100644
tools/export_center.py
0 → 100644