Merge branch 'dygraph' into add_rec_sar
Showing
{kind=link}
因为 它太大了无法显示 image diff 。你可以改为 查看blob。
doc/PaddleOCR_log.png
0 → 100644
{kind=link}

75.5 KB
doc/datasets/icdar_rec.png
0 → 100644
{kind=link}

921.4 KB
此差异已折叠。
doc/doc_ch/environment.md
0 → 100644
doc/doc_ch/inference_ppocr.md
0 → 100644
doc/doc_ch/models_and_config.md
0 → 100644
doc/doc_ch/paddleOCR_overview.md
0 → 100644
doc/doc_ch/training.md
0 → 100644
doc/doc_en/environment_en.md
0 → 100644
doc/doc_en/inference_ppocr_en.md
0 → 100755
doc/doc_en/training_en.md
0 → 100644
doc/ic15_location_download.png
0 → 100644
{kind=link}

80.1 KB
{kind=link}

192.4 KB
{kind=link}

93.6 KB
{kind=link}

246.4 KB
{kind=link}
70.9 KB
{kind=link}

48.1 KB
{kind=link}
140.7 KB
{kind=link}

84.5 KB
doc/install/mac/conda_create.png
0 → 100755
{kind=link}

71.6 KB
{kind=link}
173.2 KB
{kind=link}

124.7 KB
{kind=link}

73.8 KB
{kind=link}

321.2 KB
{kind=link}
134.9 KB
{kind=link}

231.4 KB
{kind=link}
{kind=link}

| W: | H:

| W: | H:
doc/overview.png
0 → 100644
{kind=link}

142.8 KB
doc/overview_en.png
0 → 100644
{kind=link}
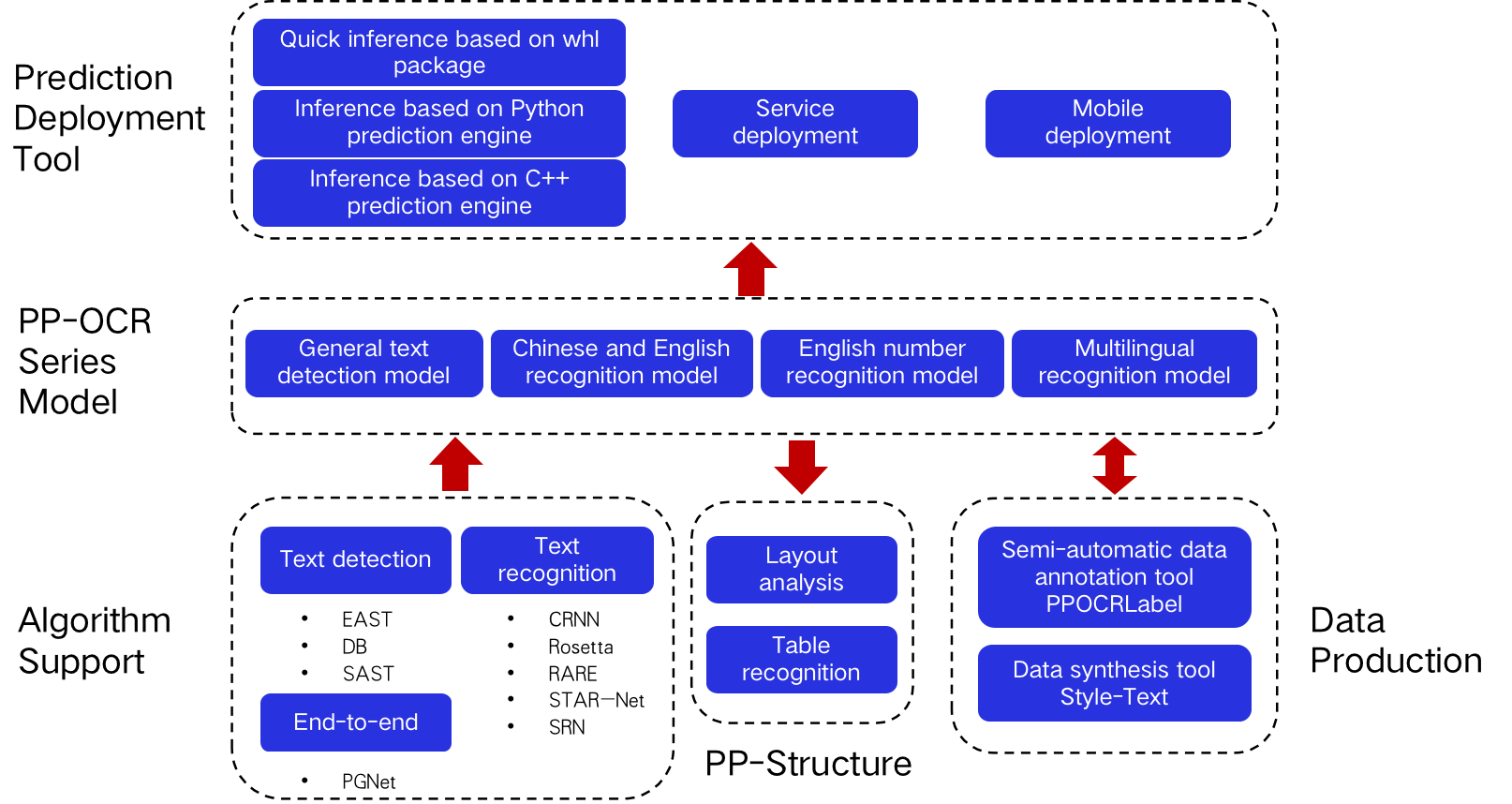
144.4 KB
doc/ppocrv2_framework.jpg
0 → 100644
{kind=link}

260.7 KB
此差异已折叠。
tests/compare_results.py
0 → 100644
此差异已折叠。
此差异已折叠。
此差异已折叠。