Merge branch 'dygraph' into dygraph
Showing
{kind=link}
{kind=link}

| W: | H:

| W: | H:
{kind=link}
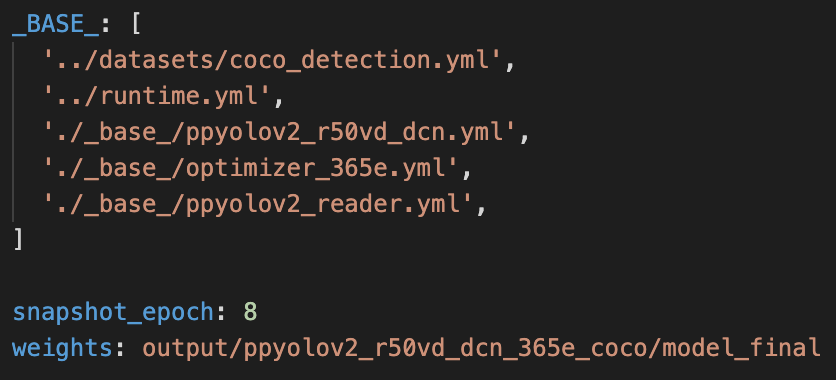
55.4 KB
doc/table/paper-image.jpg
0 → 100644
{kind=link}

671.5 KB
doc/table/result_all.jpg
0 → 100644
{kind=link}

386.5 KB
doc/table/result_text.jpg
0 → 100644
{kind=link}

387.8 KB
test1/layout/README.md
0 → 100644
文件已添加
文件已移动