Skip to content
体验新版
项目
组织
正在加载...
登录
切换导航
打开侧边栏
weixin_41840029
PaddleOCR
提交
4959c1c2
P
PaddleOCR
项目概览
weixin_41840029
/
PaddleOCR
与 Fork 源项目一致
Fork自
PaddlePaddle / PaddleOCR
通知
1
Star
1
Fork
0
代码
文件
提交
分支
Tags
贡献者
分支图
Diff
Issue
0
列表
看板
标记
里程碑
合并请求
0
Wiki
0
Wiki
分析
仓库
DevOps
项目成员
Pages
P
PaddleOCR
项目概览
项目概览
详情
发布
仓库
仓库
文件
提交
分支
标签
贡献者
分支图
比较
Issue
0
Issue
0
列表
看板
标记
里程碑
合并请求
0
合并请求
0
Pages
分析
分析
仓库分析
DevOps
Wiki
0
Wiki
成员
成员
收起侧边栏
关闭侧边栏
动态
分支图
创建新Issue
提交
Issue看板
提交
4959c1c2
编写于
6月 29, 2022
作者:
H
huangjun12
浏览文件
操作
浏览文件
下载
电子邮件补丁
差异文件
update url
上级
4f5b2b97
变更
1
隐藏空白更改
内联
并排
Showing
1 changed file
with
18 addition
and
156 deletion
+18
-156
applications/包装生产日期识别.md
applications/包装生产日期识别.md
+18
-156
未找到文件。
applications/包装生产日期识别.md
浏览文件 @
4959c1c2
...
@@ -40,6 +40,8 @@
...
@@ -40,6 +40,8 @@
| 真实数据finetune | 71.33|
| 真实数据finetune | 71.33|
| 真实+合成数据finetune | 86.99|
| 真实+合成数据finetune | 86.99|
AIStudio项目链接:
[
一种基于PaddleOCR的包装生产日期识别方法
](
https://aistudio.baidu.com/aistudio/projectdetail/4287736
)
## 2. 环境搭建
## 2. 环境搭建
本任务基于Aistudio完成, 具体环境如下:
本任务基于Aistudio完成, 具体环境如下:
...
@@ -96,7 +98,6 @@ PaddleOCR
...
@@ -96,7 +98,6 @@ PaddleOCR
│ └── val.list
# 测试集数据文件列表
│ └── val.list
# 测试集数据文件列表
| ├──
bg
# 合成数据所需背景图像
| ├──
bg
# 合成数据所需背景图像
│ └── corpus
# 合成数据所需语料
│ └── corpus
# 合成数据所需语料
│ └── rec_vit_sub_64_363_all/
# svtr_tiny高精度识别模型
```
```
## 4. 直接使用PP-OCRv3模型评估
## 4. 直接使用PP-OCRv3模型评估
...
@@ -417,160 +418,9 @@ Eval.loader.batch_size_per_card: 评估单卡batch size
...
@@ -417,160 +418,9 @@ Eval.loader.batch_size_per_card: 评估单卡batch size
### 6.1 python爬虫获取数据
### 6.1 python爬虫获取数据
本节介绍如何使用python脚本爬取网络图片,这里以爬取百度图片为例。首先将图片链接都爬取下来,然后用多进程下载图片。使用到的工具有requests库和谷歌浏览器(抓包工具)。
-
推荐使用
[
爬虫工具
](
https://github.com/Joeclinton1/google-images-download
)
获取无标签图片。
准备工作:
1.
获取请求头需要的的设备信息:
(1) 使用谷歌浏览器,打开百度图片,搜索关键词【包装生产日期】
(2) 右键,选择【检查】,打开抓包工具
(3) Network >> XHR >> 选定网址 >> Headers >> RequestHeaders >> UserAgents
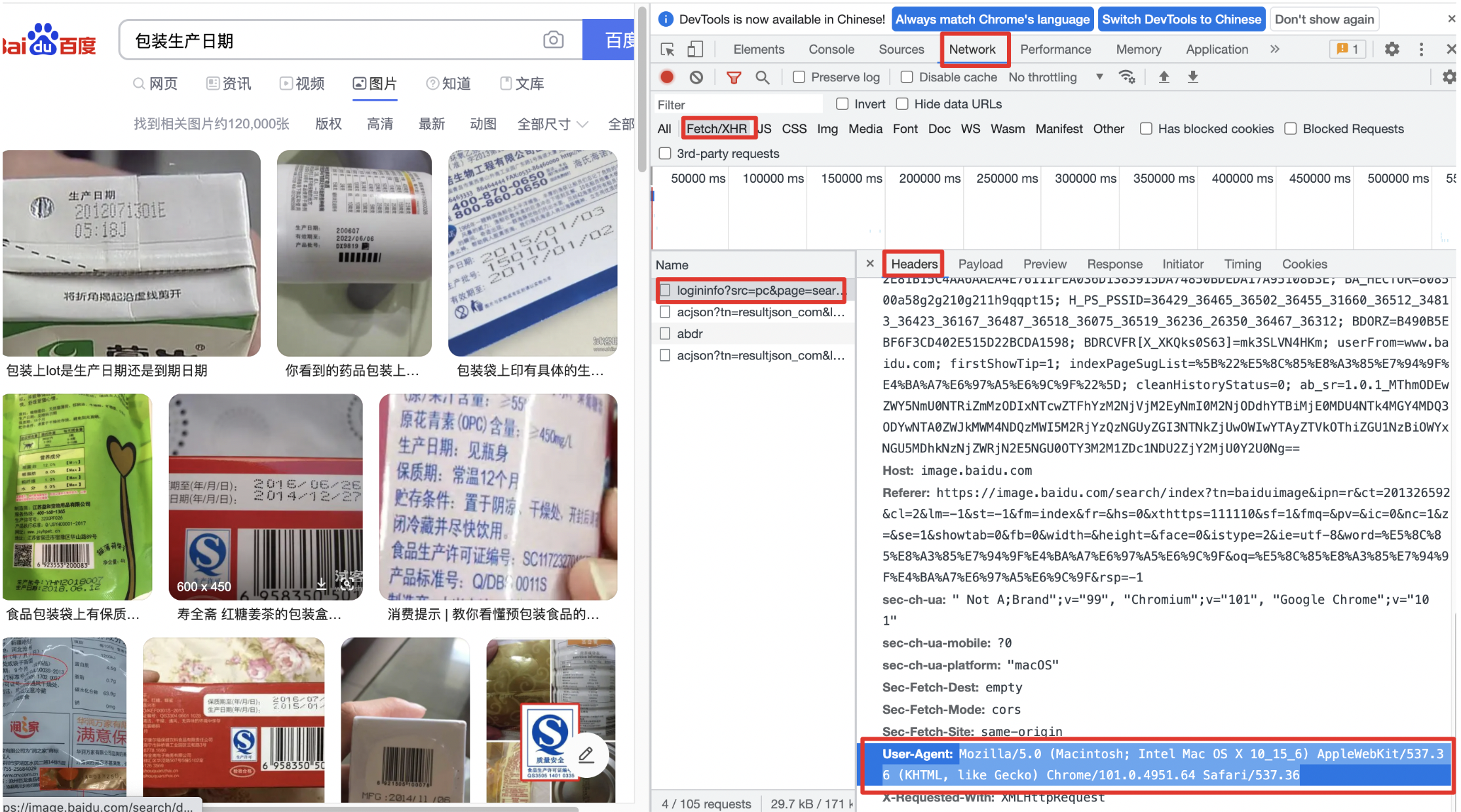
2.
获取网页参数
用类似的方式,在XHR中选择Payload获取网页参数
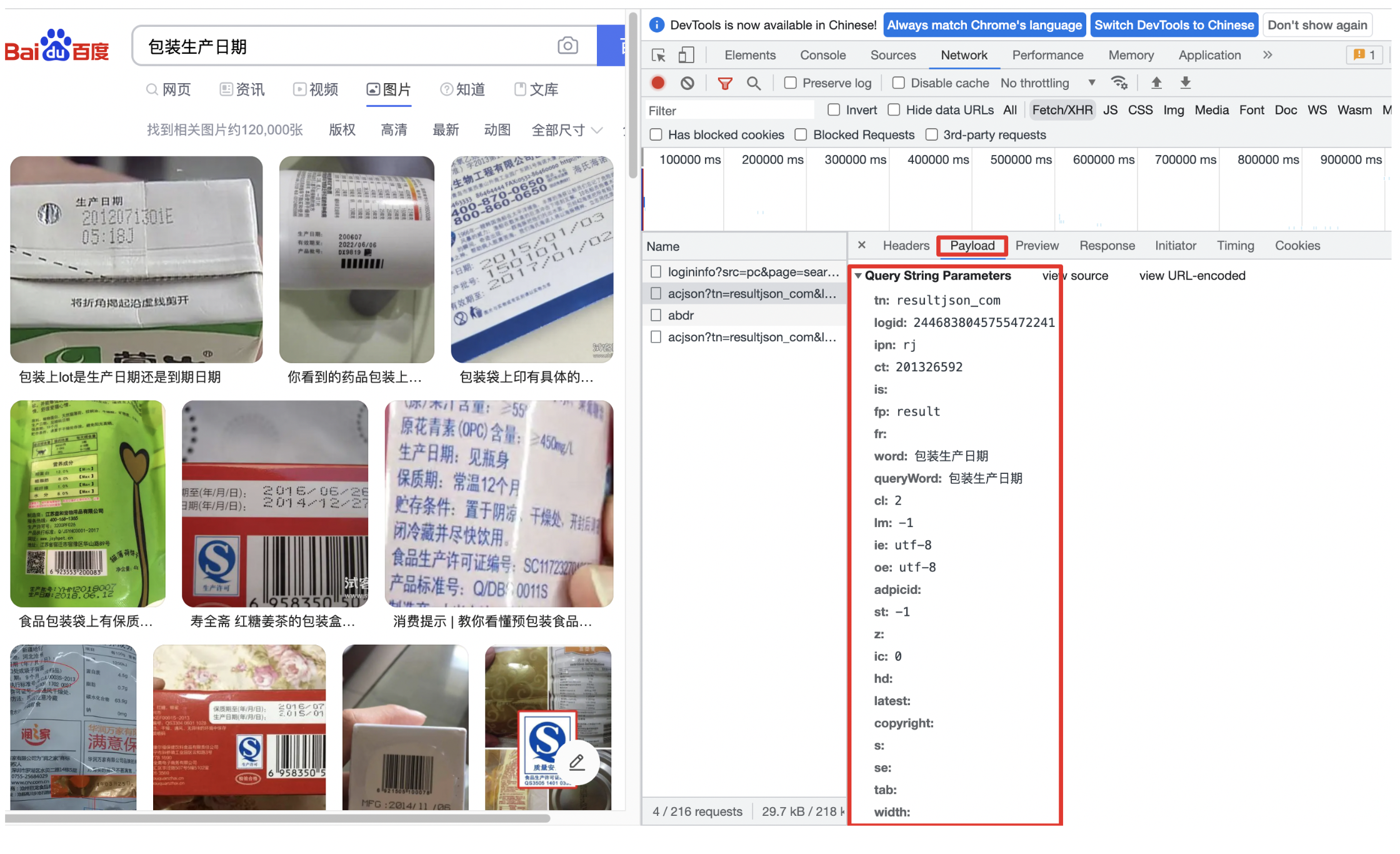
接下来编写代码进行图片抓取:
```
python
import
requests
import
json
import
tqdm
import
os
img_num
=
0
# 记录保存下来的图片数量
num_per_page
=
50
# 每一页展示的图片数量
page_num
=
40
# 页数
page_id
=
0
# 每一页开始索引
# 图片链接保存文件路径
list_path
=
'/home/aistudio/sprider'
if
not
os
.
path
.
exists
(
list_path
):
os
.
mkdir
(
list_path
)
f_list
=
open
(
os
.
path
.
join
(
list_path
,
'file.list'
),
'w'
)
img_dict
=
{}
# 图片链接字典,去重
# 搜索关键词
key_word
=
[
'包装产品生产日期'
,
'包装日期'
,
'生产日期'
,
'保质期'
,
'纸箱生产日期'
,
'商品日期'
,
'黑色生产日期'
,
'黑底生产日期'
]
for
key
in
key_word
:
bar
=
tqdm
.
tqdm
(
total
=
page_num
*
num_per_page
)
for
page_id
in
range
(
page_num
):
# 使用准备好的请求头设备信息
header
=
{
'User-Agent'
:
'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_6) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/101.0.4951.64 Safari/537.36'
}
# 使用准备好的网页参数
url
=
'https://image.baidu.com/search/acjson?'
param
=
{
'tn'
:
'resultjson_com'
,
'logid'
:
'8931113288182398301'
,
'ipn'
:
'rj'
,
'ct'
:
'201326592'
,
'is'
:
''
,
'fp'
:
'result'
,
'fr'
:
''
,
'word'
:
key
,
# 搜索关键词
'queryWord'
:
key
,
# 搜索关键词
'cl'
:
'2'
,
'lm'
:
'-1'
,
'ie'
:
'utf-8'
,
'oe'
:
'utf-8'
,
'adpicid'
:
''
,
'st'
:
'-1'
,
'z'
:
''
,
'ic'
:
'0'
,
'hd'
:
''
,
'latest'
:
''
,
'copyright'
:
''
,
's'
:
''
,
'se'
:
''
,
'tab'
:
''
,
'width'
:
''
,
'height'
:
''
,
'face'
:
'0'
,
'istype'
:
'2'
,
'qc'
:
''
,
'nc'
:
'1'
,
'expermode'
:
''
,
'nojc'
:
''
,
'isAsync'
:
''
,
'pn'
:
str
(
page_id
*
num_per_page
),
# 每一页开始索引
'rn'
:
str
(
num_per_page
),
# 每一页爬取的图片数量
'gsm'
:
'1e'
,
'1652689395185'
:
''
}
# 获取网页信息
page_text
=
requests
.
get
(
url
=
url
,
headers
=
header
,
params
=
param
,
timeout
=
20
)
try
:
page_text
=
page_text
.
json
()
# 网页信息转成json字典
except
:
continue
info_list
=
page_text
[
'data'
]
# 获取不到有效信息后,退出搜索
图片获取后,可按如下目录格式组织:
if
info_list
==
[{}]:
print
(
'===break==='
)
break
del
info_list
[
-
1
]
img_path_list
=
[]
for
info
in
info_list
:
img_url
=
info
[
'thumbURL'
]
# 图片源地址
#bar.update(1)
if
img_url
not
in
img_dict
:
img_dict
[
img_url
]
=
1
f_list
.
write
(
img_url
+
'
\n
'
)
f_list
.
close
()
print
(
'saved image number:'
,
img_num
+
1
)
```
```
python
# 使用多进程下载网页图片
import
requests
from
concurrent.futures
import
ProcessPoolExecutor
file_path
=
'/home/aistudio/sprider/file.list'
image_save_path
=
'/home/aistudio/sprider/data'
if
not
os
.
path
.
exists
(
image_save_path
):
os
.
mkdir
(
image_save_path
)
f
=
open
(
file_path
,
'r'
)
lines
=
f
.
readlines
()
header
=
{
'User-Agent'
:
'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_6) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/101.0.4951.64 Safari/537.36'
}
def
process
(
img_url
,
img_num
):
try
:
img_data
=
requests
.
get
(
url
=
img_url
,
headers
=
header
,
timeout
=
20
).
content
img_path
=
os
.
path
.
join
(
image_save_path
,
'{:05d}.jpg'
.
format
(
img_num
))
with
open
(
img_path
,
'wb'
)
as
fp
:
fp
.
write
(
img_data
)
img_num
+=
1
except
Exception
as
e
:
print
(
'connect Failed, just continue'
)
with
ProcessPoolExecutor
(
max_workers
=
10
)
as
executer
:
for
idx
,
line
in
enumerate
(
lines
):
executer
.
submit
(
process
,
line
.
strip
(),
idx
)
print
(
'done'
)
```
完成以上步骤,便可得到获取的图片,目录格式如下:
```
txt
```
txt
sprider
sprider
...
@@ -591,7 +441,13 @@ sprider
...
@@ -591,7 +441,13 @@ sprider
首先下载预训练模型,PP-OCRv3检测模型下载链接:https://paddleocr.bj.bcebos.com/PP-OCRv3/chinese/ch_PP-OCRv3_det_infer.tar
首先下载预训练模型,PP-OCRv3检测模型下载链接:https://paddleocr.bj.bcebos.com/PP-OCRv3/chinese/ch_PP-OCRv3_det_infer.tar
svtr-tiny识别模型,我们使用的是在内部数据上训练的高精度模型,本项目提供下载链接,完成步骤3的数据准备后,可得数据路径位于:
svtr-tiny识别模型,我们使用的是在内部数据上训练的高精度模型。如需获取该训练模型,请扫码填写问卷,加入PaddleOCR官方交流群获取全部OCR垂类模型下载链接、《动手学OCR》电子书等全套OCR学习资料🎁
<div
align=
"left"
>
<img
src=
"https://ai-studio-static-online.cdn.bcebos.com/dd721099bd50478f9d5fb13d8dd00fad69c22d6848244fd3a1d3980d7fefc63e"
width =
"150"
height =
"150"
/>
</div>
完成下载后,可将模型存储于如下位置:
```
shell
```
shell
PaddleOCR
PaddleOCR
...
@@ -824,4 +680,10 @@ python tools/train.py -c configs/rec/PP-OCRv3/ch_PP-OCRv3_rec_distillation.yml \
...
@@ -824,4 +680,10 @@ python tools/train.py -c configs/rec/PP-OCRv3/ch_PP-OCRv3_rec_distillation.yml \
可以看到,相较于原始PP-OCRv3的识别精度62.99%,使用合成数据+真实数据finetune后,识别精度能提升24%。
可以看到,相较于原始PP-OCRv3的识别精度62.99%,使用合成数据+真实数据finetune后,识别精度能提升24%。
训练完成后,PP-OCRv3模型的推理部署方法可以参考repo文档: https://github.com/PaddlePaddle/PaddleOCR/blob/release/2.5/deploy/README_ch.md
如需获取已训练模型,请扫码填写问卷,加入PaddleOCR官方交流群获取全部OCR垂类模型下载链接、《动手学OCR》电子书等全套OCR学习资料🎁
<div
align=
"left"
>
<img
src=
"https://ai-studio-static-online.cdn.bcebos.com/dd721099bd50478f9d5fb13d8dd00fad69c22d6848244fd3a1d3980d7fefc63e"
width =
"150"
height =
"150"
/>
</div>
将下载或训练完成的模型放置在对应目录下即可完成模型推理。
模型的推理部署方法可以参考repo文档: https://github.com/PaddlePaddle/PaddleOCR/blob/release/2.5/deploy/README_ch.md
编辑
预览
Markdown
is supported
0%
请重试
或
添加新附件
.
添加附件
取消
You are about to add
0
people
to the discussion. Proceed with caution.
先完成此消息的编辑!
取消
想要评论请
注册
或
登录