Merge remote-tracking branch 'origin/dygraph' into dygraph
Showing
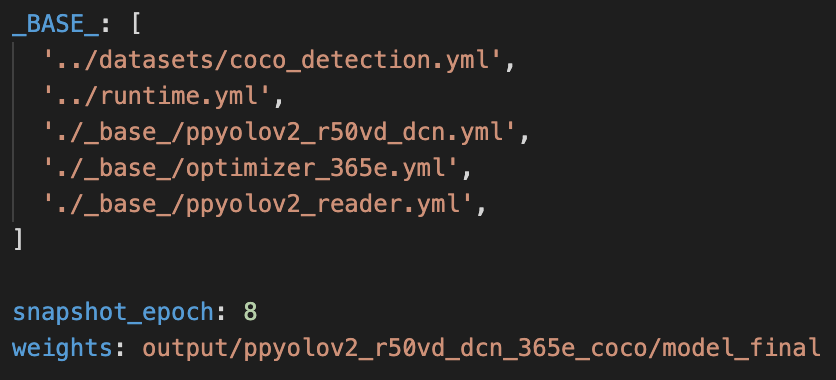
configs/table/table_mv3.yml
0 → 100755
deploy/cpp_infer/src/preprocess_op.cpp
100755 → 100644
doc/table/1.png
0 → 100644
{kind=link}

262.8 KB
{kind=link}
55.4 KB
doc/table/paper-image.jpg
0 → 100644
{kind=link}

671.5 KB
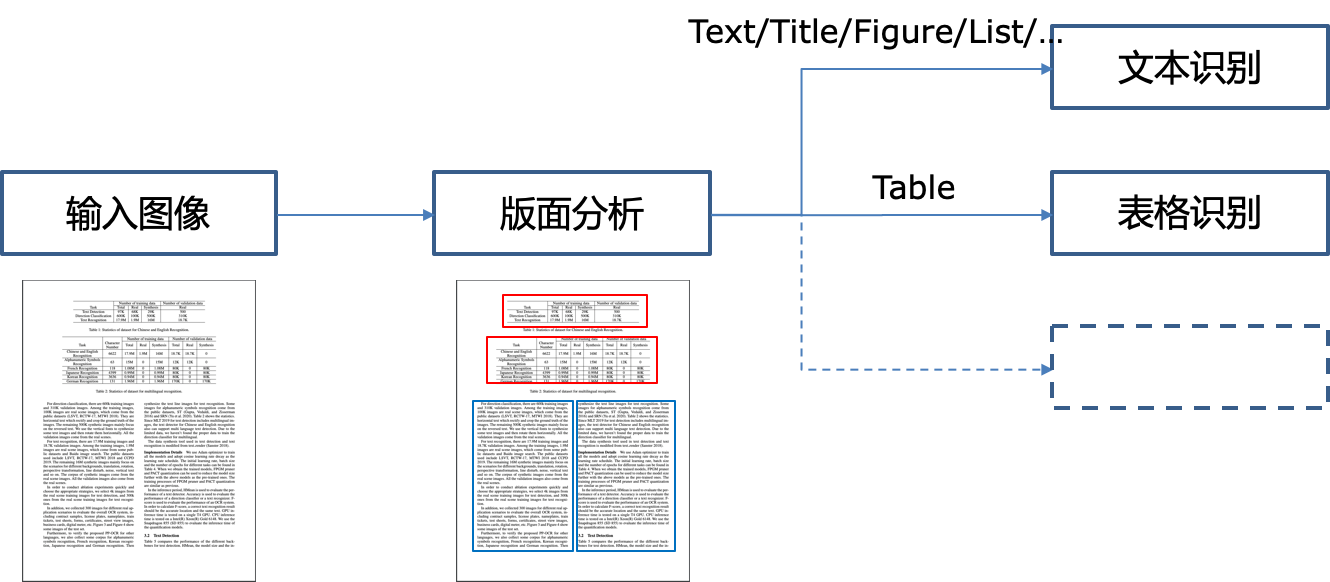
doc/table/pipeline.png
0 → 100644
{kind=link}
115.7 KB
doc/table/result_all.jpg
0 → 100644
{kind=link}

386.5 KB
doc/table/result_text.jpg
0 → 100644
{kind=link}

387.8 KB
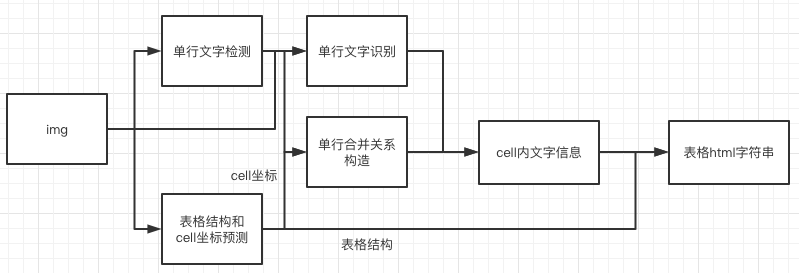
doc/table/tableocr_pipeline.png
0 → 100644
{kind=link}
26.1 KB
ppocr/data/pubtab_dataset.py
0 → 100644
ppocr/losses/basic_loss.py
0 → 100644
ppocr/losses/combined_loss.py
0 → 100644
ppocr/losses/distillation_loss.py
0 → 100644
ppocr/losses/table_att_loss.py
0 → 100644
ppocr/metrics/table_metric.py
0 → 100644
ppocr/modeling/necks/table_fpn.py
0 → 100644
ppocr/utils/dict/table_dict.txt
0 → 100644
此差异已折叠。
ppocr/utils/network.py
0 → 100644
test1/MANIFEST.in
0 → 100644
test1/__init__.py
0 → 100644
test1/api.md
0 → 100644
test1/api_ch.md
0 → 100644
test1/layout/README.md
0 → 100644
此差异已折叠。
test1/paddlestructure.py
0 → 100644
此差异已折叠。
test1/predict_system.py
0 → 100644
此差异已折叠。
test1/setup.py
0 → 100644
此差异已折叠。
test1/table/README.md
0 → 100644
此差异已折叠。
test1/table/README_ch.md
0 → 100644
此差异已折叠。
test1/table/__init__.py
0 → 100644
test1/table/eval_table.py
0 → 100755
此差异已折叠。
test1/table/matcher.py
0 → 100755
此差异已折叠。
test1/table/predict_structure.py
0 → 100755
此差异已折叠。
test1/table/predict_table.py
0 → 100644
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
test1/table/tablepyxl/__init__.py
0 → 100644
此差异已折叠。
test1/table/tablepyxl/style.py
0 → 100644
此差异已折叠。
此差异已折叠。
test1/utility.py
0 → 100644
此差异已折叠。
此差异已折叠。
此差异已折叠。
tools/infer/benchmark_utils.py
0 → 100644
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
tools/infer_table.py
0 → 100644
此差异已折叠。
此差异已折叠。
此差异已折叠。