Merge branch 'dygraph' of https://github.com/PaddlePaddle/PaddleOCR into fx_pse
Showing
{kind=link}
{kind=link}

| W: | H:

| W: | H:
{kind=link}
55.4 KB
doc/table/layout.jpg
0 → 100644
{kind=link}

671.5 KB
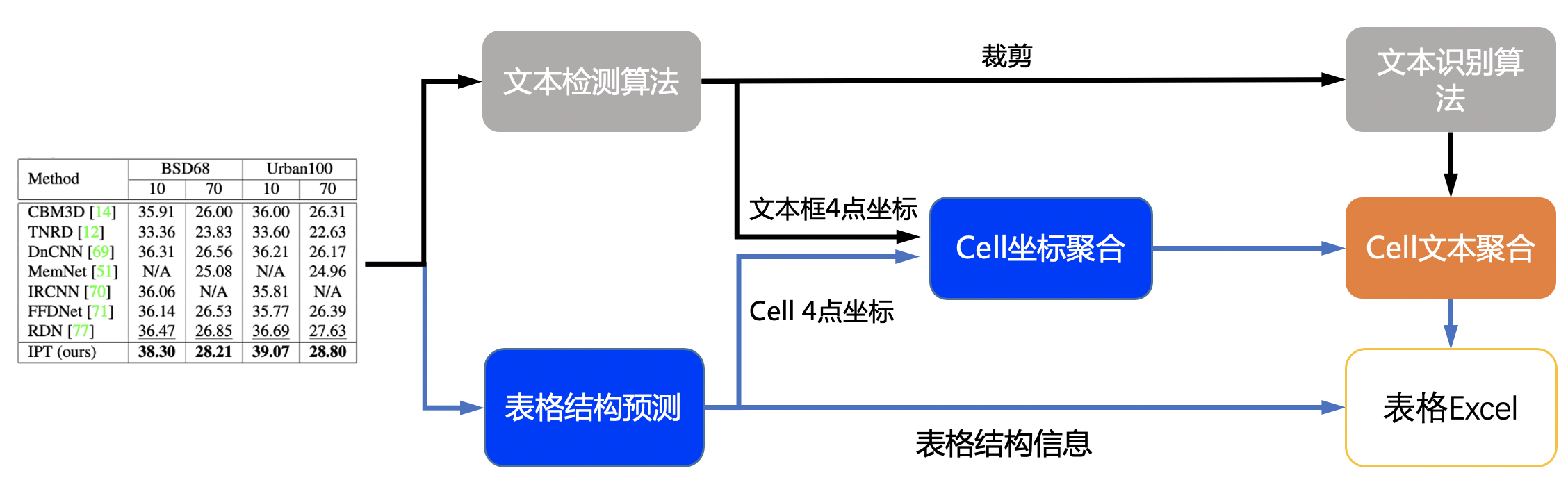
doc/table/pipeline.jpg
0 → 100644
{kind=link}
1.5 MB
doc/table/pipeline.png
已删除
100644 → 0
{kind=link}
115.7 KB
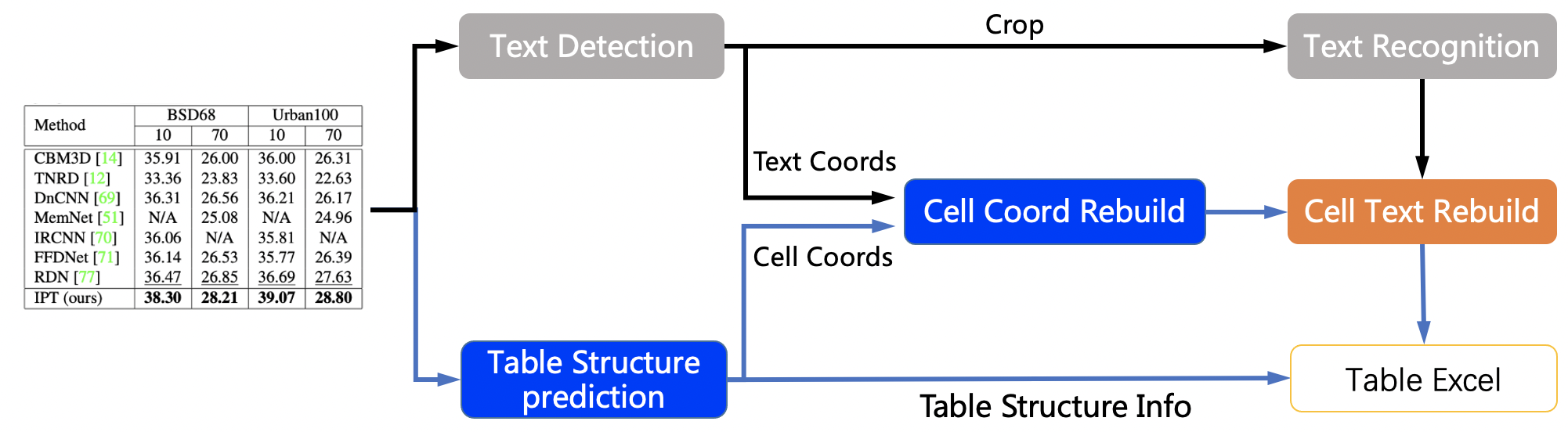
doc/table/pipeline_en.jpg
0 → 100644
{kind=link}
1.4 MB
doc/table/ppstructure.GIF
0 → 100644
{kind=link}

2.5 MB
{kind=link}
{kind=link}

| W: | H:
| W: | H:
{kind=link}
{kind=link}

| W: | H:

| W: | H:
doc/table/table.jpg
0 → 100644
{kind=link}

24.1 KB
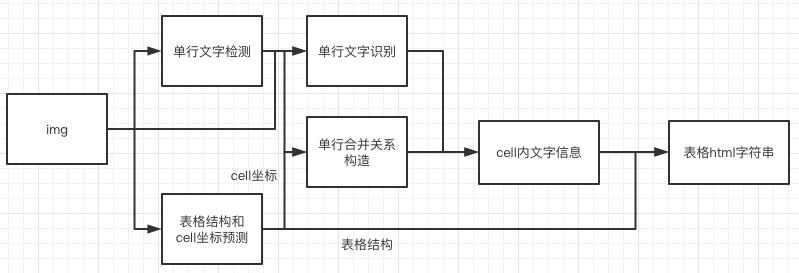
doc/table/tableocr_pipeline.jpg
0 → 100644
{kind=link}
551.7 KB
{kind=link}
26.1 KB
{kind=link}
415.7 KB
ppstructure/README.md
0 → 100644
ppstructure/README_ch.md
0 → 100644
ppstructure/layout/README.md
0 → 100644
ppstructure/table/README.md
0 → 100644
文件已移动
文件已移动
文件已移动
test1/MANIFEST.in
已删除
100644 → 0
test1/api.md
已删除
100644 → 0
test1/api_ch.md
已删除
100644 → 0
test1/paddlestructure.py
已删除
100644 → 0
test1/setup.py
已删除
100644 → 0
test1/table/README.md
已删除
100644 → 0