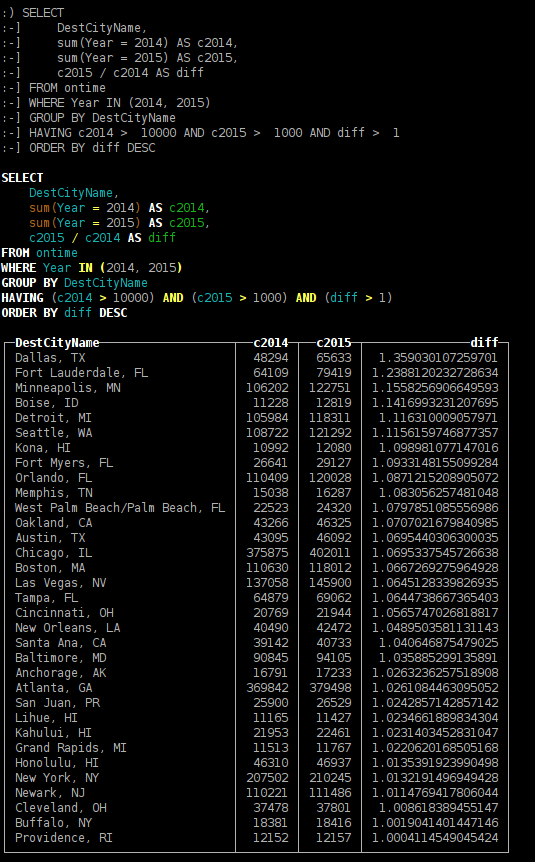
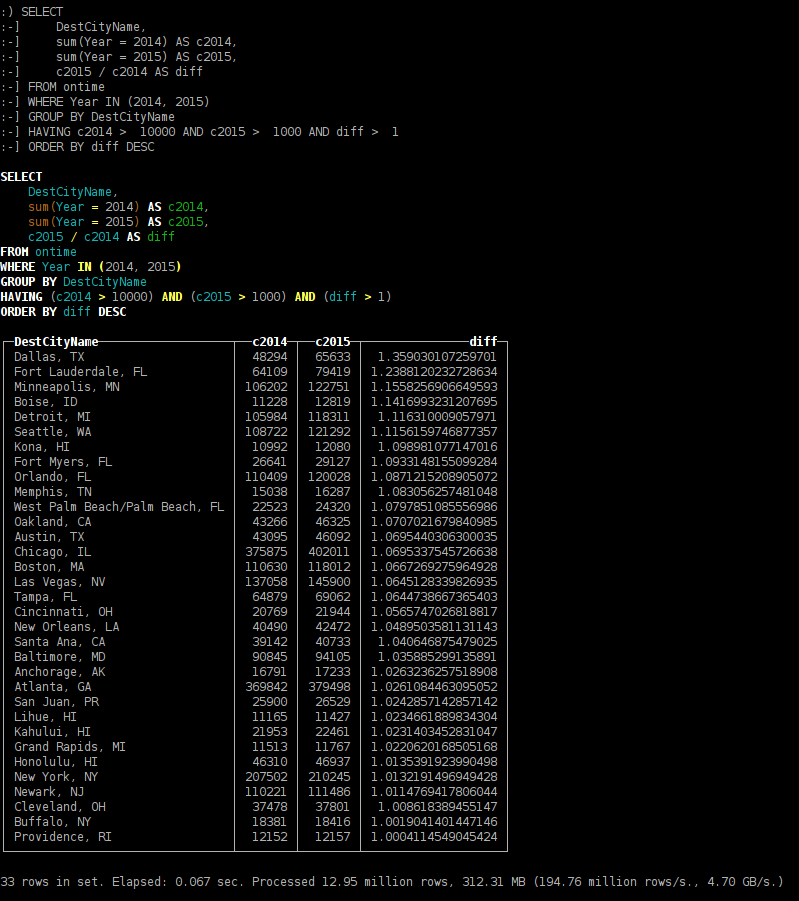
<li><spoilertitle="перелёты в какие города больше зависят от сезонности;">
<sourcelang="SQL">
...
...
@@ -390,11 +390,10 @@ LIMIT 20
<sourcelang="SQL">INSERT INTO ontime_all SELECT * FROM ontime;</source>
Отметим, что для перешардирования больших таблиц, такой способ не подходит, и вместо этого следует воспользоваться встроенной <ahref="https://clickhouse.yandex/reference_ru.html#TODO">функциональностью перешардирования</a>.
Как и ожидается, большинство запросов из распределённой таблицы на трёх серверах, работают в несколько раз быстрее.
TODO SELECT OriginCityName, count(*) AS flights FROM ontime GROUP BY OriginCityName ORDER BY flights DESC LIMIT 20
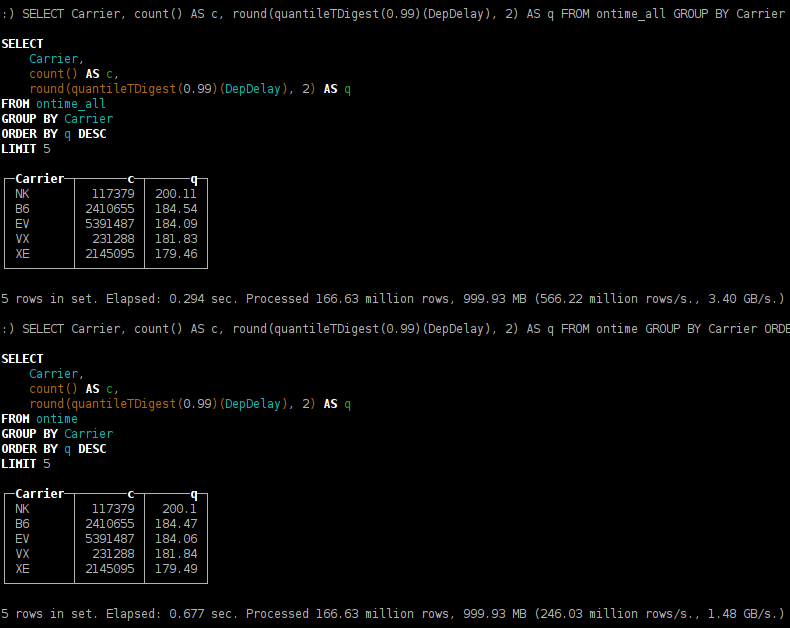
Как и ожидается, более-менее долгие запросы работают в несколько раз быстрее, если их выполнять на трёх серверах, а не на одном. <spoilertitle="Пример">
Можно заметить, что результат рассчёта квантилей слегка отличается. Это происходит, потому что реализация алгоритма <ahref="https://github.com/tdunning/t-digest/raw/master/docs/t-digest-paper/histo.pdf">t-digest</a> является недетерминированной — зависит от порядка обработки данных.</spoiler>
В данном примере, мы использовали кластер из трёх шардов, каждый шард которого состоит из одной реплики. Для реальных задач, в целях отказоустойчивости, каждый шард должен состоять из двух или трёх реплик, расположенных в разных датацентрах. (Поддерживается произвольное количество реплик).
<spoilertitle="Конфигурация кластера из одного шарда, на котором данные расположены в трёх репликах">
{kind=link}
{kind=link}
{kind=link}