Merge branch 'develop' into develop
Showing
doc/demo/build.png
0 → 100644
{kind=link}

13.1 KB
doc/demo/error.png
0 → 100644
{kind=link}
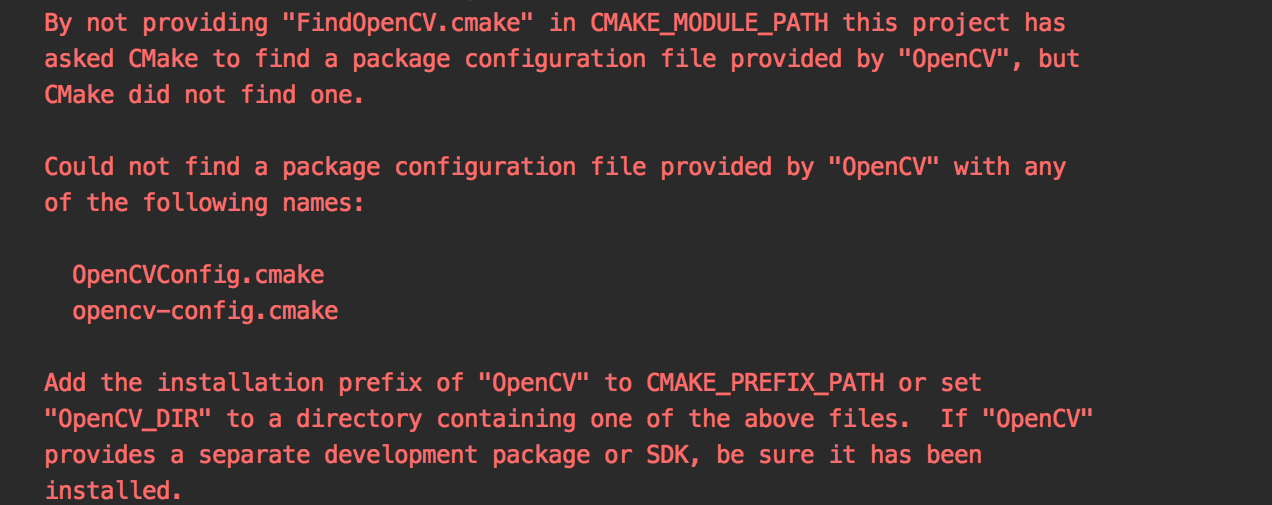
105.3 KB
doc/demo/proxy.png
0 → 100644
{kind=link}
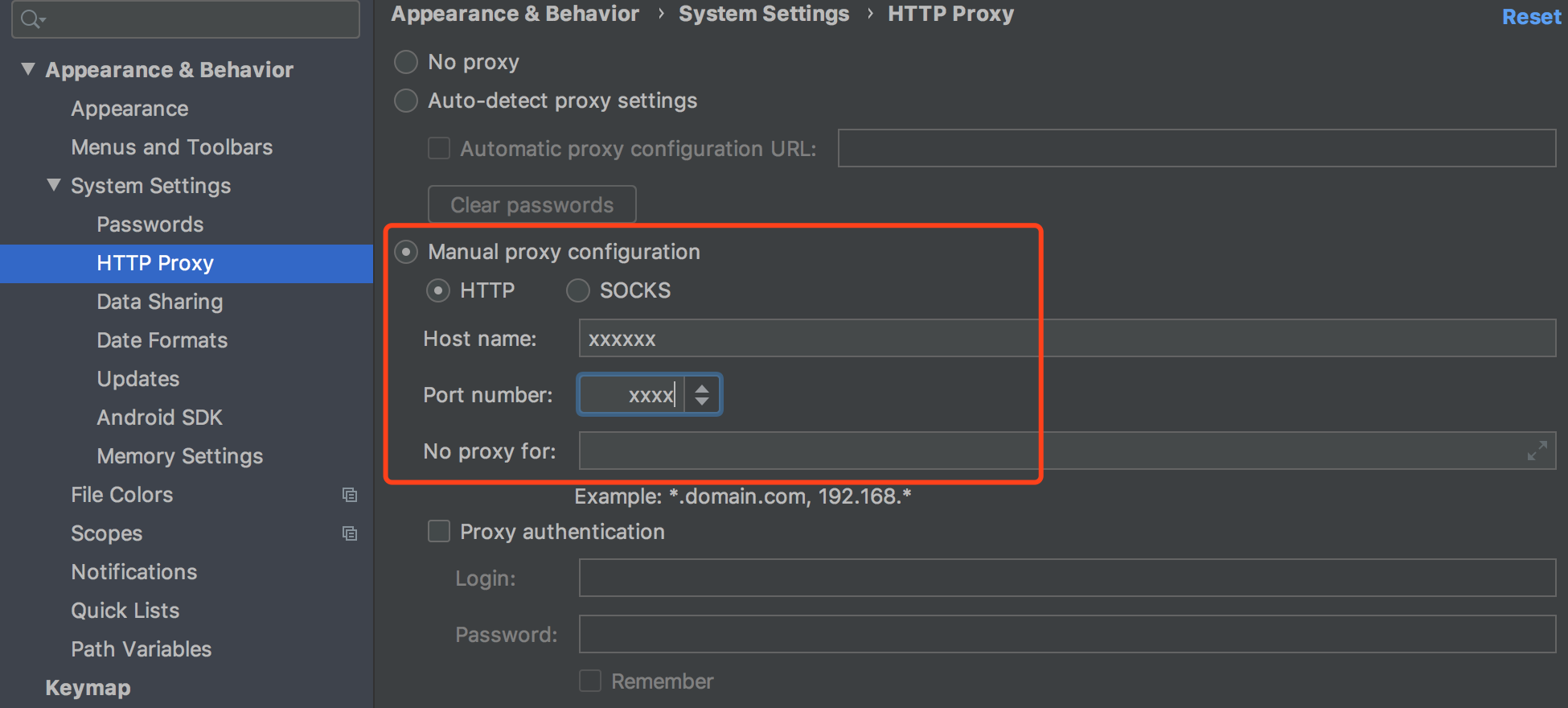
184.7 KB
doc/doc_ch/android_demo.md
0 → 100644
doc/doc_en/android_demo_en.md
0 → 100644