We are planning to build Deep Speech 2 (DS2) \[[1](#references)\], a powerful Automatic Speech Recognition (ASR) engine, on PaddlePaddle. For the first-stage plan, we have the following short-term goals:
- Release a basic distributed implementation of DS2 on PaddlePaddle.
- Contribute a chapter of Deep Speech to PaddlePaddle Book.
Intensive system optimization and low-latency inference library (details in \[[1](#references)\]) are not yet covered in this first-stage plan.
## Table of Contents
-[Tasks](#tasks)
-[Task Dependency](#task-dependency)
-[Design Details](#design-details)
-[Overview](#overview)
-[Row Convolution](#row-convolution)
-[Beam Search With CTC and LM](#beam-search-with-ctc-and-lm)
-[Future Work](#future-work)
-[References](#references)
## Tasks
We roughly break down the project into 14 tasks:
1. Develop an **audio data provider**:
- Json filelist generator.
- Audio file format transformer.
- Spectrogram feature extraction, power normalization etc.
- Batch data reader with SortaGrad.
- Data augmentation (optional).
- Prepare (one or more) public English data sets & baseline.
2. Create a **simplified DS2 model configuration**:
- With only fixed-length (by padding) audio sequences (otherwise need *Task 3*).
- With only bidirectional-GRU (otherwise need *Task 4*).
- With only greedy decoder (otherwise need *Task 5, 6*).
3. Develop to support **variable-shaped** dense-vector (image) batches of input data.
- Update `DenseScanner` in `dataprovider_converter.py`, etc.
4. Develop a new **lookahead-row-convolution layer** (See \[[1](#references)\] for details):
- Lookahead convolution windows.
- Within-row convolution, without kernels shared across rows.
5. Build KenLM **language model** (5-gram) for beam search decoder:
- Use KenLM toolkit.
- Prepare the corpus & train the model.
- Create infererence interfaces (for Task 6).
6. Develop a **beam search decoder** with CTC + LM + WORDCOUNT:
- Beam search with CTC.
- Beam search with external custom scorer (e.g. LM).
- Try to design a more general beam search interface.
7. Develop a **Word Error Rate evaluator**:
- update `ctc_error_evaluator`(CER) to support WER.
8. Prepare internal dataset for Mandarin (optional):
- Dataset, baseline, evaluation details.
- Particular data preprocessing for Mandarin.
- Might need cooperating with the Speech Department.
9. Create **standard DS2 model configuration**:
- With variable-length audio sequences (need *Task 3*).
- With unidirectional-GRU + row-convolution (need *Task 4*).
- With CTC-LM beam search decoder (need *Task 5, 6*).
10. Make it run perfectly on **clusters**.
11. Experiments and **benchmarking** (for accuracy, not efficiency):
- With public English dataset.
- With internal (Baidu) Mandarin dataset (optional).
12. Time **profiling** and optimization.
13. Prepare **docs**.
14. Prepare PaddlePaddle **Book** chapter with a simplified version.
Phase I | Simplified model & components | *Task 1* ~ *Task 8*
Phase II | Standard model & benchmarking & profiling | *Task 9* ~ *Task 12*
Phase III | Documentations | *Task13* ~ *Task14*
Issue for each task will be created later. Contributions, discussions and comments are all highly appreciated and welcomed!
## Design Details
### Overview
Traditional **ASR** (Automatic Speech Recognition) pipelines require great human efforts devoted to elaborately tuning multiple hand-engineered components (e.g. audio feature design, accoustic model, pronuncation model and language model etc.). **Deep Speech 2** (**DS2**) \[[1](#references)\], however, trains such ASR models in an end-to-end manner, replacing most intermediate modules with only a single deep network architecture. With scaling up both the data and model sizes, DS2 achieves a very significant performance boost.
Please read Deep Speech 2 \[[1](#references),[2](#references)\] paper for more background knowledge.
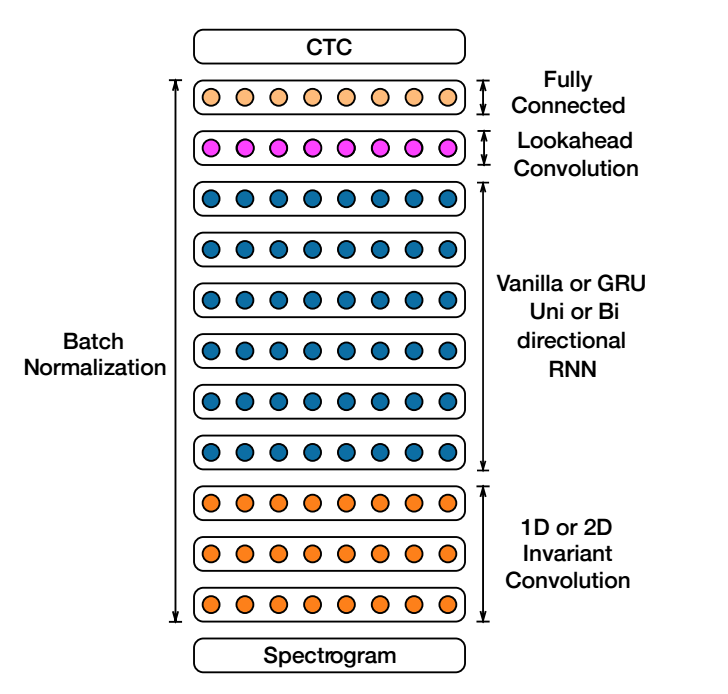
The classical DS2 network contains 15 layers (from bottom to top):
-**Two** data layers (audio spectrogram, transcription text)
-**Three** 2D convolution layers
-**Seven** uni-directional simple-RNN layers
-**One** lookahead row convolution layers
-**One** fully-connected layers
-**One** CTC-loss layer
<divalign="center">
<imgsrc="image/ds2_network.png"width=350><br/>
Figure 1. Archetecture of Deep Speech 2 Network.
</div>
We don't have to persist on this 2-3-7-1-1-1 depth \[[2](#references)\]. Similar networks with different depths might also work well. As in \[[1](#references)\], authors use a different depth (e.g. 2-2-3-1-1-1) for final experiments.
Key ingredients about the layers:
-**Data Layers**:
- Frame sequences data of audio **spectrogram** (with FFT).
- Token sequences data of **transcription** text (labels).
- These two type of sequences do not have the same lengthes, thus a CTC-loss layer is required.
-**2D Convolution Layers**:
- Not only temporal convolution, but also **frequency convolution**. Like a 2D image convolution, but with a variable dimension (i.e. temporal dimension).
- With striding for only the first convlution layer.
- No pooling for all convolution layers.
-**Uni-directional RNNs**
- Uni-directional + row convolution: for low-latency inference.
- Bi-direcitional + without row convolution: if we don't care about the inference latency.
-**Row convolution**:
- For looking only a few steps ahead into the feature, instead of looking into a whole sequence in bi-directional RNNs.
- Not nessesary if with bi-direcitional RNNs.
- "**Row**" means convolutions are done within each frequency dimension (row), and no convolution kernels shared across.
-**Batch Normalization Layers**:
- Added to all above layers (except for data and loss layer).
- Sequence-wise normalization for RNNs: BatchNorm only performed on input-state projection and not state-state projection, for efficiency consideration.
Required Components | PaddlePaddle Support | Need to Develop
{kind=link}