Skip to content
体验新版
项目
组织
正在加载...
登录
切换导航
打开侧边栏
代码讲故事
Python专题
提交
c8a7861e
Python专题
项目概览
代码讲故事
/
Python专题
与 Fork 源项目一致
Fork自
GitCode官方 / Python专题
通知
2
Star
0
Fork
0
代码
文件
提交
分支
Tags
贡献者
分支图
Diff
Issue
0
列表
看板
标记
里程碑
合并请求
0
DevOps
流水线
流水线任务
计划
Wiki
0
Wiki
分析
仓库
DevOps
项目成员
Pages
Python专题
项目概览
项目概览
详情
发布
仓库
仓库
文件
提交
分支
标签
贡献者
分支图
比较
Issue
0
Issue
0
列表
看板
标记
里程碑
合并请求
0
合并请求
0
Pages
DevOps
DevOps
流水线
流水线任务
计划
分析
分析
仓库分析
DevOps
Wiki
0
Wiki
成员
成员
收起侧边栏
关闭侧边栏
动态
分支图
创建新Issue
流水线任务
提交
Issue看板
前往新版Gitcode,体验更适合开发者的 AI 搜索 >>
提交
c8a7861e
编写于
7月 22, 2021
作者:
M
MaoXianxin
浏览文件
操作
浏览文件
下载
电子邮件补丁
差异文件
load preprcess images
上级
5fb8fa3d
变更
1
隐藏空白更改
内联
并排
Showing
1 changed file
with
63 addition
and
0 deletion
+63
-0
花朵分类.md
花朵分类.md
+63
-0
未找到文件。
花朵分类.md
0 → 100644
浏览文件 @
c8a7861e
本次教程的目的是带领大家学会基本的花朵图像分类
首先我们来介绍下数据集,该数据集有5种花,一共有3670张图片,分别是daisy、dandelion、roses、sunflowers、tulips,数据存放结构如下所示

我们可以展示下roses的几张图片
接下来我们需要加载数据集,然后对数据集进行划分,最后形成训练集、验证集、测试集,注意此处的验证集是从训练集切分出来的,比例是8:2
对数据进行探索的时候,我们发现原始的像素值是0-255,为了模型训练更稳定以及更容易收敛,我们需要标准化数据集,一般来说就是把像素值缩放到0-1,可以用下面的layer来实现
```
normalization_layer = tf.keras.layers.experimental.preprocessing.Rescaling(1./255)
```
为了使训练的时候I/O不成为瓶颈,我们可以进行如下设置
```
AUTOTUNE = tf.data.AUTOTUNE
train_ds = train_ds.cache().prefetch(buffer_size=AUTOTUNE)
val_ds = val_ds.cache().prefetch(buffer_size=AUTOTUNE)
```
下一步就是模型搭建,然后对模型进行训练
```
num_classes
=
5
model
=
tf
.
keras
.
Sequential
([
tf
.
keras
.
layers
.
experimental
.
preprocessing
.
Rescaling
(
1.
/
255
),
tf
.
keras
.
layers
.
Conv2D
(
32
,
3
,
activation
=
'relu'
),
tf
.
keras
.
layers
.
MaxPooling2D
(),
tf
.
keras
.
layers
.
Conv2D
(
32
,
3
,
activation
=
'relu'
),
tf
.
keras
.
layers
.
MaxPooling2D
(),
tf
.
keras
.
layers
.
Conv2D
(
32
,
3
,
activation
=
'relu'
),
tf
.
keras
.
layers
.
MaxPooling2D
(),
tf
.
keras
.
layers
.
Flatten
(),
tf
.
keras
.
layers
.
Dense
(
128
,
activation
=
'relu'
),
tf
.
keras
.
layers
.
Dense
(
num_classes
)
])
model
.
compile
(
optimizer
=
'adam'
,
loss
=
tf
.
losses
.
SparseCategoricalCrossentropy
(
from_logits
=
True
),
metrics
=[
'accuracy'
])
model
.
fit
(
train_ds
,
validation_data
=
val_ds
,
epochs
=
3
)
```
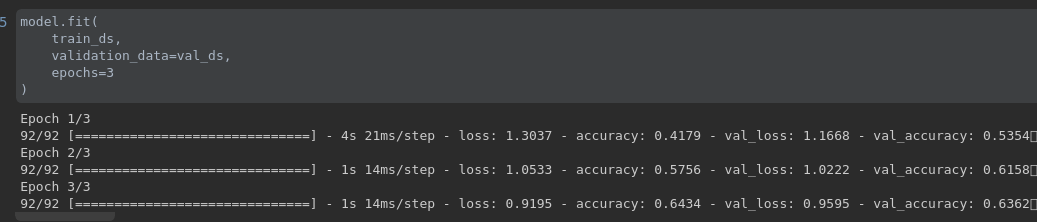
从上图的训练记录可以发现,该模型处于欠拟合状态,我们可以通过多训练几轮来解决这个问题,而且为了快速实验,我们这里用了一个非常简单的模型,我们可以通过更换更强的模型,来提升模型的表现
代码链接: https://codechina.csdn.net/csdn_codechina/enterprise_technology/-/blob/master/load_preprocess_images.ipynb
\ No newline at end of file
编辑
预览
Markdown
is supported
0%
请重试
或
添加新附件
.
添加附件
取消
You are about to add
0
people
to the discussion. Proceed with caution.
先完成此消息的编辑!
取消
想要评论请
注册
或
登录