docs: remove 2.6 new functions from 2.4 document in EN
Showing
docs-en/01-index.md
0 → 100644
docs-en/02-intro/_category_.yml
0 → 100644
docs-en/02-intro/eco_system.png
0 → 100644
{kind=link}
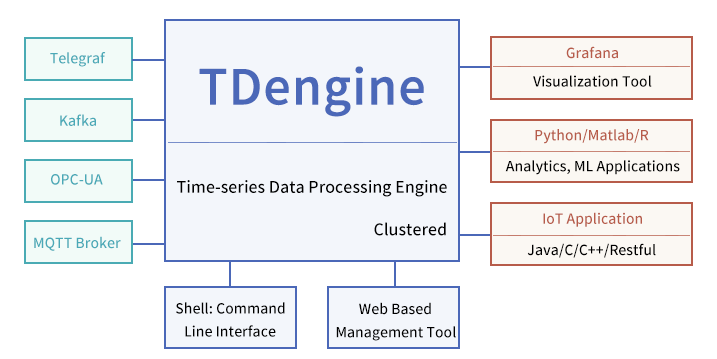
45.0 KB
docs-en/02-intro/index.md
0 → 100644
docs-en/04-concept/_category_.yml
0 → 100644
docs-en/04-concept/index.md
0 → 100644
docs-en/05-get-started/index.md
0 → 100644
docs-en/07-develop/07-cache.md
0 → 100644
docs-en/07-develop/08-udf.md
0 → 100644
docs-en/07-develop/_category_.yml
0 → 100644
docs-en/07-develop/_sub_c.mdx
0 → 100644
docs-en/07-develop/_sub_cs.mdx
0 → 100644
docs-en/07-develop/_sub_go.mdx
0 → 100644
docs-en/07-develop/_sub_java.mdx
0 → 100644
docs-en/07-develop/_sub_node.mdx
0 → 100644
docs-en/07-develop/_sub_rust.mdx
0 → 100644
docs-en/07-develop/index.md
0 → 100644
docs-en/10-cluster/01-deploy.md
0 → 100644
docs-en/10-cluster/_category_.yml
0 → 100644
docs-en/10-cluster/index.md
0 → 100644
docs-en/12-taos-sql/03-table.md
0 → 100644
docs-en/12-taos-sql/04-stable.md
0 → 100644
docs-en/12-taos-sql/05-insert.md
0 → 100644
docs-en/12-taos-sql/06-select.md
0 → 100644
此差异已折叠。
此差异已折叠。
此差异已折叠。
docs-en/12-taos-sql/09-limit.md
0 → 100644
此差异已折叠。
docs-en/12-taos-sql/10-json.md
0 → 100644
此差异已折叠。
docs-en/12-taos-sql/11-escape.md
0 → 100644
此差异已折叠。
此差异已折叠。
此差异已折叠。
docs-en/12-taos-sql/index.md
0 → 100644
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
docs-en/13-operation/06-admin.md
0 → 100644
此差异已折叠。
docs-en/13-operation/07-import.md
0 → 100644
此差异已折叠。
docs-en/13-operation/08-export.md
0 → 100644
此差异已折叠。
docs-en/13-operation/09-status.md
0 → 100644
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
docs-en/13-operation/index.md
0 → 100644
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
{kind=link}
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
此差异已折叠。
此差异已折叠。
{kind=link}
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
docs-en/14-reference/_icinga2.mdx
0 → 100644
此差异已折叠。
此差异已折叠。
docs-en/14-reference/_statsd.mdx
0 → 100644
此差异已折叠。
此差异已折叠。
此差异已折叠。
docs-en/14-reference/index.md
0 → 100644
此差异已折叠。
{kind=link}
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
docs-en/20-third-party/index.md
0 → 100644
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
docs-en/21-tdinternal/01-arch.md
0 → 100644
此差异已折叠。
此差异已折叠。
此差异已折叠。
docs-en/21-tdinternal/dnode.png
0 → 100644
{kind=link}
此差异已折叠。
docs-en/21-tdinternal/index.md
0 → 100644
此差异已折叠。
docs-en/21-tdinternal/message.png
0 → 100644
{kind=link}
此差异已折叠。
docs-en/21-tdinternal/modules.png
0 → 100644
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
docs-en/21-tdinternal/vnode.png
0 → 100644
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
docs-en/25-application/index.md
0 → 100644
此差异已折叠。
docs-en/27-train-faq/01-faq.md
0 → 100644
此差异已折叠。
docs-en/27-train-faq/03-docker.md
0 → 100644
此差异已折叠。
此差异已折叠。
docs-en/27-train-faq/index.md
0 → 100644
此差异已折叠。