@@ -27,7 +27,7 @@ There may be multiple dnodes in a cluster, but only one mnode can be started in
...
@@ -27,7 +27,7 @@ There may be multiple dnodes in a cluster, but only one mnode can be started in
SHOWMNODES;
SHOWMNODES;
```
```
The end point and role/status (master, slave, unsynced, or offline) of all mnodes can be shown by the above command. When the first dnode is started in a cluster, there must be one mnode in this dnode. Without at least one mnode, the cluster cannot work. If `numOfMNodes` is configured to 2, another mnode will be started when the second dnode is launched.
The end point and role/status (leader, follower, unsynced, or offline) of all mnodes can be shown by the above command. When the first dnode is started in a cluster, there must be one mnode in this dnode. Without at least one mnode, the cluster cannot work. If `numOfMNodes` is configured to 2, another mnode will be started when the second dnode is launched.
For the high availability of mnode, `numOfMnodes` needs to be configured to 2 or a higher value. Because the data consistency between mnodes must be guaranteed, the replica confirmation parameter `quorum` is set to 2 automatically if `numOfMNodes` is set to 2 or higher.
For the high availability of mnode, `numOfMnodes` needs to be configured to 2 or a higher value. Because the data consistency between mnodes must be guaranteed, the replica confirmation parameter `quorum` is set to 2 automatically if `numOfMNodes` is set to 2 or higher.
...
@@ -58,13 +58,13 @@ When a dnode is offline, it can be detected by the TDengine cluster. There are t
...
@@ -58,13 +58,13 @@ When a dnode is offline, it can be detected by the TDengine cluster. There are t
- If the dnode has been offline over the threshold configured in `offlineThreshold` in `taos.cfg`, the dnode will be removed from the cluster automatically. A system alert will be generated and automatic load balancing will be triggered if `balance` is set to 1. When the removed dnode is restarted and becomes online, it will not join the cluster automatically. The system administrator has to manually join the dnode to the cluster.
- If the dnode has been offline over the threshold configured in `offlineThreshold` in `taos.cfg`, the dnode will be removed from the cluster automatically. A system alert will be generated and automatic load balancing will be triggered if `balance` is set to 1. When the removed dnode is restarted and becomes online, it will not join the cluster automatically. The system administrator has to manually join the dnode to the cluster.
:::note
:::note
If all the vnodes in a vgroup (or mnodes in mnode group) are in offline or unsynced status, the master node can only be voted on, after all the vnodes or mnodes in the group become online and can exchange status. Following this, the vgroup (or mnode group) is able to provide service.
If all the vnodes in a vgroup (or mnodes in mnode group) are in offline or unsynced status, the leader node can only be voted on, after all the vnodes or mnodes in the group become online and can exchange status. Following this, the vgroup (or mnode group) is able to provide service.
:::
:::
## Arbitrator
## Arbitrator
The "arbitrator" component is used to address the special case when the number of replicas is set to an even number like 2,4 etc. If half of the vnodes in a vgroup don't work, it is impossible to vote and select a master node. This situation also applies to mnodes if the number of mnodes is set to an even number like 2,4 etc.
The "arbitrator" component is used to address the special case when the number of replicas is set to an even number like 2,4 etc. If half of the vnodes in a vgroup don't work, it is impossible to vote and select a leader node. This situation also applies to mnodes if the number of mnodes is set to an even number like 2,4 etc.
To resolve this problem, a new arbitrator component named `tarbitrator`, an abbreviation of TDengine Arbitrator, was introduced. The `tarbitrator` simulates a vnode or mnode but it's only responsible for network communication and doesn't handle any actual data access. As long as more than half of the vnode or mnode, including Arbitrator, are available the vnode group or mnode group can provide data insertion or query services normally.
To resolve this problem, a new arbitrator component named `tarbitrator`, an abbreviation of TDengine Arbitrator, was introduced. The `tarbitrator` simulates a vnode or mnode but it's only responsible for network communication and doesn't handle any actual data access. As long as more than half of the vnode or mnode, including Arbitrator, are available the vnode group or mnode group can provide data insertion or query services normally.
@@ -21,7 +21,7 @@ The following example is in an Ubuntu environment and uses the `curl` tool to ve
...
@@ -21,7 +21,7 @@ The following example is in an Ubuntu environment and uses the `curl` tool to ve
The following example lists all databases on the host h1.taosdata.com. To use it in your environment, replace `h1.taosdata.com` and `6041` (the default port) with the actual running TDengine service FQDN and port number.
The following example lists all databases on the host h1.taosdata.com. To use it in your environment, replace `h1.taosdata.com` and `6041` (the default port) with the actual running TDengine service FQDN and port number.
@@ -7,7 +7,7 @@ description: "taosBenchmark (once called taosdemo ) is a tool for testing the pe
...
@@ -7,7 +7,7 @@ description: "taosBenchmark (once called taosdemo ) is a tool for testing the pe
## Introduction
## Introduction
taosBenchmark (formerly taosdemo ) is a tool for testing the performance of TDengine products. taosBenchmark can test the performance of TDengine's insert, query, and subscription functions and simulate large amounts of data generated by many devices. taosBenchmark can flexibly control the number and type of databases, supertables, tag columns, number and type of data columns, and sub-tables, and types of databases, super tables, the number and types of data columns, the number of sub-tables, the amount of data per sub-table, the time interval for inserting data, the number of working threads, whether and how to insert disordered data, and so on. The installer provides taosdemo as a soft link to taosBenchmark for compatibility and for the convenience of past users.
taosBenchmark (formerly taosdemo ) is a tool for testing the performance of TDengine products. taosBenchmark can test the performance of TDengine's insert, query, and subscription functions and simulate large amounts of data generated by many devices. taosBenchmark can be configured to generate user defined databases, supertables, subtables, and the time series data to populate these for performance benchmarking. taosBenchmark is highly configurable and some of the configurations include the time interval for inserting data, the number of working threads and the capability to insert disordered data. The installer provides taosdemo as a soft link to taosBenchmark for compatibility with past users.
## Installation
## Installation
...
@@ -21,9 +21,9 @@ There are two ways to install taosBenchmark:
...
@@ -21,9 +21,9 @@ There are two ways to install taosBenchmark:
### Configuration and running methods
### Configuration and running methods
TaosBenchmark needs to be executed on the terminal of the operating system, it supports two configuration methods: [Command-line arguments](#Command-line arguments in detailed) and [JSON configuration file](#Configuration file arguments in detailed). These two methods are mutually exclusive. Users can use `-f <json file>` to specify a configuration file. When running taosBenchmark with command-line arguments to control its behavior, users should use other parameters for configuration, but not the `-f` parameter. In addition, taosBenchmark offers a special way of running without parameters.
TaosBenchmark needs to be executed on the terminal of the operating system, it supports two configuration methods: [Command-line arguments](#command-line-arguments-in-detail) and [JSON configuration file](#configuration-file-parameters-in-detail). These two methods are mutually exclusive. Users can use `-f <json file>` to specify a configuration file. When running taosBenchmark with command-line arguments to control its behavior, users should use other parameters for configuration, but not the `-f` parameter. In addition, taosBenchmark offers a special way of running without parameters.
taosBenchmark supports complete performance testing of TDengine. taosBenchmark supports the TDengine functions in three categories: write, query, and subscribe. These three functions are mutually exclusive, and users can select only one of them each time taosBenchmark runs. It is important to note that the type of functionality to be tested is not configurable when using the command-line configuration method, which can only test writing performance. To test the query and subscription performance of the TDengine, you must use the configuration file method and specify the function type to test via the parameter `filetype` in the configuration file.
taosBenchmark supports the complete performance testing of TDengine by providing functionally to write, query, and subscribe. These three functions are mutually exclusive, users can only select one of them each time taosBenchmark runs. The query and subscribe functionalities are only configurable using a json configuration file by specifying the parameter `filetype`, while write can be performed through both the command-line and a configuration file.
**Make sure that the TDengine cluster is running correctly before running taosBenchmark. **
**Make sure that the TDengine cluster is running correctly before running taosBenchmark. **
...
@@ -57,9 +57,8 @@ Use the following command-line to run taosBenchmark and control its behavior via
...
@@ -57,9 +57,8 @@ Use the following command-line to run taosBenchmark and control its behavior via
taosBenchmark -f <json file>
taosBenchmark -f <json file>
```
```
**Here are a few examples of configuration files:**
#### Configuration file examples
##### Example of inserting a scenario JSON configuration file
#### Example of inserting a scenario JSON configuration file
<details>
<details>
<summary>insert.json</summary>
<summary>insert.json</summary>
...
@@ -70,7 +69,7 @@ taosBenchmark -f <json file>
...
@@ -70,7 +69,7 @@ taosBenchmark -f <json file>
</details>
</details>
#### Query Scenario JSON Profile Example
##### Query Scenario JSON Profile Example
<details>
<details>
<summary>query.json</summary>
<summary>query.json</summary>
...
@@ -81,7 +80,7 @@ taosBenchmark -f <json file>
...
@@ -81,7 +80,7 @@ taosBenchmark -f <json file>
</details>
</details>
#### Subscription JSON configuration example
##### Subscription JSON configuration example
<details>
<details>
<summary>subscribe.json</summary>
<summary>subscribe.json</summary>
...
@@ -172,7 +171,11 @@ taosBenchmark -A INT,DOUBLE,NCHAR,BINARY\(16\)
...
@@ -172,7 +171,11 @@ taosBenchmark -A INT,DOUBLE,NCHAR,BINARY\(16\)
Switch parameter specifying whether to use escape characters in the super table and sub-table names. By default is not used.
Switch parameter specifying whether to use escape characters in the super table and sub-table names. By default is not used.
-**-C/--chinese** :
-**-C/--chinese** :
<<<<<<< HEAD
Switch specifying whether to use Unicode Chinese characters in nchar and binary. By default is not used.
Switch specifying whether to use Unicode Chinese characters in nchar and binary. By default is not used.
=======
specify whether to use Unicode Chinese characters in nchar and binary, the default is no.
>>>>>>> 108548b4d6 (docs: typo)
-**-N/--normal-table** :
-**-N/--normal-table** :
This parameter indicates that taosBenchmark will create only normal tables instead of super tables. The default value is false. It can be used if the insert mode is taosc, stmt, and rest.
This parameter indicates that taosBenchmark will create only normal tables instead of super tables. The default value is false. It can be used if the insert mode is taosc, stmt, and rest.
...
@@ -373,7 +376,7 @@ The configuration parameters for querying the sub-tables or the normal tables ar
...
@@ -373,7 +376,7 @@ The configuration parameters for querying the sub-tables or the normal tables ar
-**sqls**.
-**sqls**.
-**sql**: the SQL command to be executed.
-**sql**: the SQL command to be executed.
-**result**: the file to save the query result. If it is unspecified, taosBenchark will not save the result.
-**result**: the file to save the query result. If it is unspecified, taosBenchmark will not save the result.
#### Configuration parameters of query super table
#### Configuration parameters of query super table
@@ -36,6 +36,8 @@ There are two ways to install taosdump:
...
@@ -36,6 +36,8 @@ There are two ways to install taosdump:
:::tip
:::tip
- taosdump versions after 1.4.1 provide the `-I` argument for parsing Avro file schema and data. If users specify `-s` then only taosdump will parse schema.
- taosdump versions after 1.4.1 provide the `-I` argument for parsing Avro file schema and data. If users specify `-s` then only taosdump will parse schema.
- Backups after taosdump 1.4.2 use the batch count specified by the `-B` parameter. The default value is 16384. If, in some environments, low network speed or disk performance causes "Error actual dump ... batch ...", then try changing the `-B` parameter to a smaller value.
- Backups after taosdump 1.4.2 use the batch count specified by the `-B` parameter. The default value is 16384. If, in some environments, low network speed or disk performance causes "Error actual dump ... batch ...", then try changing the `-B` parameter to a smaller value.
- The export of taosdump does not support resuming from an interruption. Therefore, if the taosdump process terminates unexpectedly, delete all related files that have been exported or generated.
- The import of taosdump supports resuming from an interruption, but when the process resumes, you will receive some "table already exists" messages, which could be ignored.
@@ -26,7 +26,6 @@ All executable files of TDengine are in the _/usr/local/taos/bin_ directory by d
...
@@ -26,7 +26,6 @@ All executable files of TDengine are in the _/usr/local/taos/bin_ directory by d
- _remove.sh_: script to uninstall TDengine, please execute it carefully, link to the **rmtaos** command in the /usr/bin directory. Will remove the TDengine installation directory `/usr/local/taos`, but will keep `/etc/taos`, `/var/lib/taos`, `/var/log/taos`
- _remove.sh_: script to uninstall TDengine, please execute it carefully, link to the **rmtaos** command in the /usr/bin directory. Will remove the TDengine installation directory `/usr/local/taos`, but will keep `/etc/taos`, `/var/lib/taos`, `/var/log/taos`
- _taosadapter_: server-side executable that provides RESTful services and accepts writing requests from a variety of other softwares
- _taosadapter_: server-side executable that provides RESTful services and accepts writing requests from a variety of other softwares
- _tarbitrator_: provides arbitration for two-node cluster deployments
- _tarbitrator_: provides arbitration for two-node cluster deployments
- _run_taosd_and_taosadapter.sh_: script to start both taosd and taosAdapter
- _TDinsight.sh_: script to download TDinsight and install it
- _TDinsight.sh_: script to download TDinsight and install it
- _set_core.sh_: script for setting up the system to generate core dump files for easy debugging
- _set_core.sh_: script for setting up the system to generate core dump files for easy debugging
- _taosd-dump-cfg.gdb_: script to facilitate debugging of taosd's gdb execution.
- _taosd-dump-cfg.gdb_: script to facilitate debugging of taosd's gdb execution.
@@ -31,38 +31,41 @@ TDengine currently supports Grafana versions 7.5 and above. Users can go to the
...
@@ -31,38 +31,41 @@ TDengine currently supports Grafana versions 7.5 and above. Users can go to the
### Install Grafana Plugin and Configure Data Source
### Install Grafana Plugin and Configure Data Source
<Tabs defaultValue="script">
<Tabs defaultValue="script">
<TabItem value="script" label="Using Script">
<TabItem value="gui" label="With GUI">
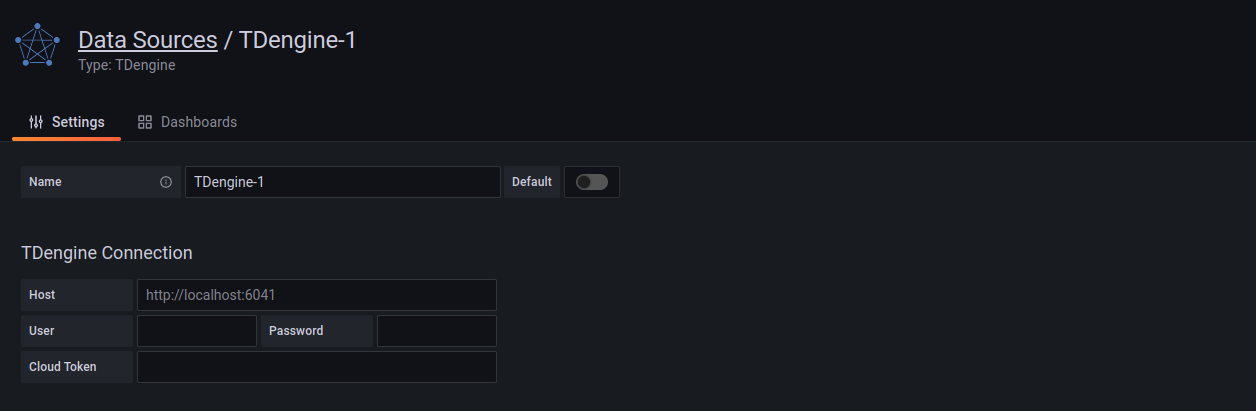
Set the url and authorization environment variables by `export` or a [`.env`(dotenv) file](https://hexdocs.pm/dotenvy/dotenv-file-format.html):
Under Grafana 8, plugin catalog allows you to [browse and manage plugins within Grafana](https://grafana.com/docs/grafana/next/administration/plugin-management/#plugin-catalog) (but for Grafana 7.x, use **With Script** or **Install & Configure Manually**). Find the page at **Configurations > Plugins**, search **TDengine** and click it to install.
```sh

export TDENGINE_API=http://tdengine.local:6041
# user + password
Installation may cost some minutes, then you can **Create a TDengine data source**:
export TDENGINE_USER=user
export TDENGINE_PASSWORD=password

# Other useful variables
Then you can add a TDengine data source by filling up the configuration options.
# - If to install TDengine data source, default is true
export TDENGINE_DS_ENABLED=false

# - Data source name to be created, default is TDengine
export TDENGINE_DS_NAME=TDengine
You can create dashboards with TDengine now.
# - Data source organization id, default is 1
export GF_ORG_ID=1
</TabItem>
# - Data source is editable in admin ui or not, default is 0 (false)
<TabItem value="script" label="With Script">
export TDENGINE_EDITABLE=1
```
Run `install.sh`:
On a server with Grafana installed, run `install.sh` with TDengine url and username/passwords will install TDengine data source plugin and add a data source named TDengine. This is the recommended way for Grafana 7.x or [Grafana provisioning](https://grafana.com/docs/grafana/latest/administration/provisioning/) users.
With this script, TDengine data source plugin and the Grafana data source will be installed and created automatically with Grafana provisioning configurations. Save the script and type `./install.sh --help` for the full usage of the script.
Restart Grafana service and open Grafana in web-browser, usually <http://localhost:3000>.
And then, restart Grafana service and open Grafana in web-browser, usually <http://localhost:3000>.
Save the script and type `./install.sh --help` for the full usage of the script.
Follow the installation steps in [Grafana](https://grafana.com/grafana/plugins/tdengine-datasource/?tab=installation) with the [``grafana-cli`` command-line tool](https://grafana.com/docs/grafana/latest/administration/cli/) for plugin installation.
Follow the installation steps in [Grafana](https://grafana.com/grafana/plugins/tdengine-datasource/?tab=installation) with the [``grafana-cli`` command-line tool](https://grafana.com/docs/grafana/latest/administration/cli/) for plugin installation.
...
@@ -115,6 +118,73 @@ Click `Save & Test` to test. You should see a success message if the test worked
...
@@ -115,6 +118,73 @@ Click `Save & Test` to test. You should see a success message if the test worked
Please refer to [Install plugins in the Docker container](https://grafana.com/docs/grafana/next/setup-grafana/installation/docker/#install-plugins-in-the-docker-container). This will install `tdengine-datasource` plugin when Grafana container starts:
```bash
docker run -d \
-p 3000:3000 \
--name=grafana \
-e "GF_INSTALL_PLUGINS=tdengine-datasource" \
grafana/grafana
```
You can setup a zero-configuration stack for TDengine + Grafana by [docker-compose](https://docs.docker.com/compose/) and [Grafana provisioning](https://grafana.com/docs/grafana/latest/administration/provisioning/) file:
1. Save the provisioning configuration file to `tdengine.yml`.
```yml
apiVersion: 1
datasources:
- name: TDengine
type: tdengine-datasource
orgId: 1
url: "$TDENGINE_API"
isDefault: true
secureJsonData:
url: "$TDENGINE_URL"
basicAuth: "$TDENGINE_BASIC_AUTH"
token: "$TDENGINE_CLOUD_TOKEN"
version: 1
editable: true
```
2. Write `docker-compose.yml` with [TDengine](https://hub.docker.com/r/tdengine/tdengine) and [Grafana](https://hub.docker.com/r/grafana/grafana) image.
@@ -22,9 +22,9 @@ A complete TDengine system runs on one or more physical nodes. Logically, it inc
...
@@ -22,9 +22,9 @@ A complete TDengine system runs on one or more physical nodes. Logically, it inc
**Virtual node (vnode)**: To better support data sharding, load balancing and prevent data from overheating or skewing, data nodes are virtualized into multiple virtual nodes (vnode, V2, V3, V4, etc. in the figure). Each vnode is a relatively independent work unit, which is the basic unit of time-series data storage and has independent running threads, memory space and persistent storage path. A vnode contains a certain number of tables (data collection points). When a new table is created, the system checks whether a new vnode needs to be created. The number of vnodes that can be created on a data node depends on the capacity of the hardware of the physical node where the data node is located. A vnode belongs to only one DB, but a DB can have multiple vnodes. In addition to the stored time-series data, a vnode also stores the schema and tag values of the included tables. A virtual node is uniquely identified in the system by the EP of the data node and the VGroup ID to which it belongs and is created and managed by the management node.
**Virtual node (vnode)**: To better support data sharding, load balancing and prevent data from overheating or skewing, data nodes are virtualized into multiple virtual nodes (vnode, V2, V3, V4, etc. in the figure). Each vnode is a relatively independent work unit, which is the basic unit of time-series data storage and has independent running threads, memory space and persistent storage path. A vnode contains a certain number of tables (data collection points). When a new table is created, the system checks whether a new vnode needs to be created. The number of vnodes that can be created on a data node depends on the capacity of the hardware of the physical node where the data node is located. A vnode belongs to only one DB, but a DB can have multiple vnodes. In addition to the stored time-series data, a vnode also stores the schema and tag values of the included tables. A virtual node is uniquely identified in the system by the EP of the data node and the VGroup ID to which it belongs and is created and managed by the management node.
**Management node (mnode)**: A virtual logical unit responsible for monitoring and maintaining the running status of all data nodes and load balancing among nodes (M in the figure). At the same time, the management node is also responsible for the storage and management of metadata (including users, databases, tables, static tags, etc.), so it is also called Meta Node. Multiple (up to 5) mnodes can be configured in a TDengine cluster, and they are automatically constructed into a virtual management node group (M0, M1, M2 in the figure). The master/slave mechanism is adopted for the mnode group and the data synchronization is carried out in a strongly consistent way. Any data update operation can only be executed on the master. The creation of mnode cluster is completed automatically by the system without manual intervention. There is at most one mnode on each dnode, which is uniquely identified by the EP of the data node to which it belongs. Each dnode automatically obtains the EP of the dnode where all mnodes in the whole cluster are located, through internal messaging interaction.
**Management node (mnode)**: A virtual logical unit responsible for monitoring and maintaining the running status of all data nodes and load balancing among nodes (M in the figure). At the same time, the management node is also responsible for the storage and management of metadata (including users, databases, tables, static tags, etc.), so it is also called Meta Node. Multiple (up to 5) mnodes can be configured in a TDengine cluster, and they are automatically constructed into a virtual management node group (M0, M1, M2 in the figure). The leader/follower mechanism is adopted for the mnode group and the data synchronization is carried out in a strongly consistent way. Any data update operation can only be executed on the leader. The creation of mnode cluster is completed automatically by the system without manual intervention. There is at most one mnode on each dnode, which is uniquely identified by the EP of the data node to which it belongs. Each dnode automatically obtains the EP of the dnode where all mnodes in the whole cluster are located, through internal messaging interaction.
**Virtual node group (VGroup)**: Vnodes on different data nodes can form a virtual node group to ensure the high availability of the system. The virtual node group is managed in a master/slave mechanism. Write operations can only be performed on the master vnode, and then replicated to slave vnodes, thus ensuring that one single replica of data is copied on multiple physical nodes. The number of virtual nodes in a vgroup equals the number of data replicas. If the number of replicas of a DB is N, the system must have at least N data nodes. The number of replicas can be specified by the parameter `“replica”` when creating a DB, and the default is 1. Using the multi-replication feature of TDengine, the same high data reliability can be achieved without the need for expensive storage devices such as disk arrays. Virtual node groups are created and managed by the management node, and the management node assigns a system unique ID, aka VGroup ID. If two virtual nodes have the same vnode group ID, it means that they belong to the same group and the data is backed up to each other. The number of virtual nodes in a virtual node group can be dynamically changed, allowing only one, that is, no data replication. VGroup ID is never changed. Even if a virtual node group is deleted, its ID will not be reused.
**Virtual node group (VGroup)**: Vnodes on different data nodes can form a virtual node group to ensure the high availability of the system. The virtual node group is managed in a leader/follower mechanism. Write operations can only be performed on the leader vnode, and then replicated to follower vnodes, thus ensuring that one single replica of data is copied on multiple physical nodes. The number of virtual nodes in a vgroup equals the number of data replicas. If the number of replicas of a DB is N, the system must have at least N data nodes. The number of replicas can be specified by the parameter `“replica”` when creating a DB, and the default is 1. Using the multi-replication feature of TDengine, the same high data reliability can be achieved without the need for expensive storage devices such as disk arrays. Virtual node groups are created and managed by the management node, and the management node assigns a system unique ID, aka VGroup ID. If two virtual nodes have the same vnode group ID, it means that they belong to the same group and the data is backed up to each other. The number of virtual nodes in a virtual node group can be dynamically changed, allowing only one, that is, no data replication. VGroup ID is never changed. Even if a virtual node group is deleted, its ID will not be reused.
**TAOSC**: TAOSC is the driver provided by TDengine to applications. It is responsible for dealing with the interaction between application and cluster, and provides the native interface for the C/C++ language. It is also embedded in the JDBC, C #, Python, Go, Node.js language connection libraries. Applications interact with the whole cluster through TAOSC instead of directly connecting to data nodes in the cluster. This module is responsible for obtaining and caching metadata; forwarding requests for insertion, query, etc. to the correct data node; when returning the results to the application, TAOSC also needs to be responsible for the final level of aggregation, sorting, filtering and other operations. For JDBC, C/C++/C#/Python/Go/Node.js interfaces, this module runs on the physical node where the application is located. At the same time, in order to support the fully distributed RESTful interface, TAOSC has a running instance on each dnode of TDengine cluster.
**TAOSC**: TAOSC is the driver provided by TDengine to applications. It is responsible for dealing with the interaction between application and cluster, and provides the native interface for the C/C++ language. It is also embedded in the JDBC, C #, Python, Go, Node.js language connection libraries. Applications interact with the whole cluster through TAOSC instead of directly connecting to data nodes in the cluster. This module is responsible for obtaining and caching metadata; forwarding requests for insertion, query, etc. to the correct data node; when returning the results to the application, TAOSC also needs to be responsible for the final level of aggregation, sorting, filtering and other operations. For JDBC, C/C++/C#/Python/Go/Node.js interfaces, this module runs on the physical node where the application is located. At the same time, in order to support the fully distributed RESTful interface, TAOSC has a running instance on each dnode of TDengine cluster.
...
@@ -62,13 +62,13 @@ To explain the relationship between vnode, mnode, TAOSC and application and thei
...
@@ -62,13 +62,13 @@ To explain the relationship between vnode, mnode, TAOSC and application and thei
1. Application initiates a request to insert data through JDBC, ODBC, or other APIs.
1. Application initiates a request to insert data through JDBC, ODBC, or other APIs.
2. TAOSC checks the cache to see if meta data exists for the table. If it does, it goes straight to Step 4. If not, TAOSC sends a get meta-data request to mnode.
2. TAOSC checks the cache to see if meta data exists for the table. If it does, it goes straight to Step 4. If not, TAOSC sends a get meta-data request to mnode.
3. Mnode returns the meta-data of the table to TAOSC. Meta-data contains the schema of the table, and also the vgroup information to which the table belongs (the vnode ID and the End Point of the dnode where the table belongs. If the number of replicas is N, there will be N groups of End Points). If TAOSC does not receive a response from the mnode for a long time, and there are multiple mnodes, TAOSC will send a request to the next mnode.
3. Mnode returns the meta-data of the table to TAOSC. Meta-data contains the schema of the table, and also the vgroup information to which the table belongs (the vnode ID and the End Point of the dnode where the table belongs. If the number of replicas is N, there will be N groups of End Points). If TAOSC does not receive a response from the mnode for a long time, and there are multiple mnodes, TAOSC will send a request to the next mnode.
4. TAOSC initiates an insert request to master vnode.
4. TAOSC initiates an insert request to leader vnode.
5. After vnode inserts the data, it gives a reply to TAOSC, indicating that the insertion is successful. If TAOSC doesn't get a response from vnode for a long time, TAOSC will treat this node as offline. In this case, if there are multiple replicas of the inserted database, TAOSC will issue an insert request to the next vnode in vgroup.
5. After vnode inserts the data, it gives a reply to TAOSC, indicating that the insertion is successful. If TAOSC doesn't get a response from vnode for a long time, TAOSC will treat this node as offline. In this case, if there are multiple replicas of the inserted database, TAOSC will issue an insert request to the next vnode in vgroup.
6. TAOSC notifies APP that writing is successful.
6. TAOSC notifies APP that writing is successful.
For Step 2 and 3, when TAOSC starts, it does not know the End Point of mnode, so it will directly initiate a request to the configured serving End Point of the cluster. If the dnode that receives the request does not have a mnode configured, it will reply with the mnode EP list, so that TAOSC will re-issue a request to obtain meta-data to the EP of another mnode.
For Step 2 and 3, when TAOSC starts, it does not know the End Point of mnode, so it will directly initiate a request to the configured serving End Point of the cluster. If the dnode that receives the request does not have a mnode configured, it will reply with the mnode EP list, so that TAOSC will re-issue a request to obtain meta-data to the EP of another mnode.
For Step 4 and 5, without caching, TAOSC can't recognize the master in the virtual node group, so assumes that the first vnode is the master and sends a request to it. If this vnode is not the master, it will reply to the actual master as a new target to which TAOSC shall send a request. Once a response of successful insertion is obtained, TAOSC will cache the information of master node.
For Step 4 and 5, without caching, TAOSC can't recognize the leader in the virtual node group, so assumes that the first vnode is the leader and sends a request to it. If this vnode is not the leader, it will reply to the actual leader as a new target to which TAOSC shall send a request. Once a response of successful insertion is obtained, TAOSC will cache the information of leader node.
The above describes the process of inserting data. The processes of querying and computing are the same. TAOSC encapsulates and hides all these complicated processes, and it is transparent to applications.
The above describes the process of inserting data. The processes of querying and computing are the same. TAOSC encapsulates and hides all these complicated processes, and it is transparent to applications.
...
@@ -119,65 +119,65 @@ The load balancing process does not require any manual intervention, and it is t
...
@@ -119,65 +119,65 @@ The load balancing process does not require any manual intervention, and it is t
## Data Writing and Replication Process
## Data Writing and Replication Process
If a database has N replicas, a virtual node group has N virtual nodes. But only one is the Master and all others are slaves. When the application writes a new record to system, only the Master vnode can accept the writing request. If a slave vnode receives a writing request, the system will notifies TAOSC to redirect.
If a database has N replicas, a virtual node group has N virtual nodes. But only one is the Leader and all others are slaves. When the application writes a new record to system, only the Leader vnode can accept the writing request. If a follower vnode receives a writing request, the system will notifies TAOSC to redirect.
<center> Figure 3: TDengine Master writing process </center>
<center> Figure 3: TDengine Leader writing process </center>
1.Master vnode receives the application data insertion request, verifies, and moves to next step;
1.Leader vnode receives the application data insertion request, verifies, and moves to next step;
2. If the system configuration parameter `“walLevel”` is greater than 0, vnode will write the original request packet into database log file WAL. If walLevel is set to 2 and fsync is set to 0, TDengine will make WAL data written immediately to ensure that even system goes down, all data can be recovered from database log file;
2. If the system configuration parameter `“walLevel”` is greater than 0, vnode will write the original request packet into database log file WAL. If walLevel is set to 2 and fsync is set to 0, TDengine will make WAL data written immediately to ensure that even system goes down, all data can be recovered from database log file;
3. If there are multiple replicas, vnode will forward data packet to slave vnodes in the same virtual node group, and the forwarded packet has a version number with data;
3. If there are multiple replicas, vnode will forward data packet to follower vnodes in the same virtual node group, and the forwarded packet has a version number with data;
4. Write into memory and add the record to “skip list”;
4. Write into memory and add the record to “skip list”;
5.Master vnode returns a confirmation message to the application, indicating a successful write.
5.Leader vnode returns a confirmation message to the application, indicating a successful write.
6. If any of Step 2, 3 or 4 fails, the error will directly return to the application.
6. If any of Step 2, 3 or 4 fails, the error will directly return to the application.
### Slave vnode Writing Process
### Follower vnode Writing Process
For a slave vnode, the write process as follows:
For a follower vnode, the write process as follows:
<center> Figure 4: TDengine Slave Writing Process </center>
<center> Figure 4: TDengine Follower Writing Process </center>
1.Slave vnode receives a data insertion request forwarded by Master vnode;
1.Follower vnode receives a data insertion request forwarded by Leader vnode;
2. If the system configuration parameter `“walLevel”` is greater than 0, vnode will write the original request packet into database log file WAL. If walLevel is set to 2 and fsync is set to 0, TDengine will make WAL data written immediately to ensure that even system goes down, all data can be recovered from database log file;
2. If the system configuration parameter `“walLevel”` is greater than 0, vnode will write the original request packet into database log file WAL. If walLevel is set to 2 and fsync is set to 0, TDengine will make WAL data written immediately to ensure that even system goes down, all data can be recovered from database log file;
3. Write into memory and add the record to “skip list”.
3. Write into memory and add the record to “skip list”.
Compared with Master vnode, slave vnode has no forwarding or reply confirmation step, means two steps less. But writing into memory and WAL is exactly the same.
Compared with Leader vnode, follower vnode has no forwarding or reply confirmation step, means two steps less. But writing into memory and WAL is exactly the same.
### Remote Disaster Recovery and IDC (Internet Data Center) Migration
### Remote Disaster Recovery and IDC (Internet Data Center) Migration
As discussed above, TDengine writes using Master and Slave processes. TDengine adopts asynchronous replication for data synchronization. This method can greatly improve write performance, with no obvious impact from network delay. By configuring IDC and rack number for each physical node, it can be ensured that for a virtual node group, virtual nodes are composed of physical nodes from different IDC and different racks, thus implementing remote disaster recovery without other tools.
As discussed above, TDengine writes using Leader and Follower processes. TDengine adopts asynchronous replication for data synchronization. This method can greatly improve write performance, with no obvious impact from network delay. By configuring IDC and rack number for each physical node, it can be ensured that for a virtual node group, virtual nodes are composed of physical nodes from different IDC and different racks, thus implementing remote disaster recovery without other tools.
On the other hand, TDengine supports dynamic modification of the replica number. Once the number of replicas increases, the newly added virtual nodes will immediately enter the data synchronization process. After synchronization is complete, added virtual nodes can provide services. In the synchronization process, master and other synchronized virtual nodes keep serving. With this feature, TDengine can provide IDC migration without service interruption. It is only necessary to add new physical nodes to the existing IDC cluster, and then remove old physical nodes after the data synchronization is completed.
On the other hand, TDengine supports dynamic modification of the replica number. Once the number of replicas increases, the newly added virtual nodes will immediately enter the data synchronization process. After synchronization is complete, added virtual nodes can provide services. In the synchronization process, leader and other synchronized virtual nodes keep serving. With this feature, TDengine can provide IDC migration without service interruption. It is only necessary to add new physical nodes to the existing IDC cluster, and then remove old physical nodes after the data synchronization is completed.
However, the asynchronous replication has a very low probability scenario where data may be lost. The specific scenario is as follows:
However, the asynchronous replication has a very low probability scenario where data may be lost. The specific scenario is as follows:
1.Master vnode has finished its 5-step operations, confirmed the success of writing to APP, and then goes down;
1.Leader vnode has finished its 5-step operations, confirmed the success of writing to APP, and then goes down;
2.Slave vnode receives the write request, then processing fails before writing to the log in Step 2;
2.Follower vnode receives the write request, then processing fails before writing to the log in Step 2;
3.Slave vnode will become the new master, thus losing one record.
3.Follower vnode will become the new leader, thus losing one record.
In theory, for asynchronous replication, there is no guarantee to prevent data loss. However, this is an extremely low probability scenario as described above.
In theory, for asynchronous replication, there is no guarantee to prevent data loss. However, this is an extremely low probability scenario as described above.
Note: Remote disaster recovery and no-downtime IDC migration are only supported by Enterprise Edition. **Hint: This function is not available yet**
Note: Remote disaster recovery and no-downtime IDC migration are only supported by Enterprise Edition. **Hint: This function is not available yet**
### Master/slave Selection
### Leader/follower Selection
Vnode maintains a version number. When memory data is persisted, the version number will also be persisted. For each data update operation, whether it is time-series data or metadata, this version number will be increased by one.
Vnode maintains a version number. When memory data is persisted, the version number will also be persisted. For each data update operation, whether it is time-series data or metadata, this version number will be increased by one.
When a vnode starts, the roles (master, slave) are uncertain, and the data is in an unsynchronized state. It’s necessary to establish TCP connections with other nodes in the virtual node group and exchange status, including version and its own roles. Through the exchange, the system implements a master-selection process. The rules are as follows:
When a vnode starts, the roles (leader, follower) are uncertain, and the data is in an unsynchronized state. It’s necessary to establish TCP connections with other nodes in the virtual node group and exchange status, including version and its own roles. Through the exchange, the system implements a leader-selection process. The rules are as follows:
1. If there’s only one replica, it’s always master
1. If there’s only one replica, it’s always leader
2. When all replicas are online, the one with latest version is master
2. When all replicas are online, the one with latest version is leader
3. Over half of online nodes are virtual nodes, and some virtual node is slave, it will automatically become master
3. Over half of online nodes are virtual nodes, and some virtual node is follower, it will automatically become leader
4. For 2 and 3, if multiple virtual nodes meet the requirement, the first vnode in virtual node group list will be selected as master.
4. For 2 and 3, if multiple virtual nodes meet the requirement, the first vnode in virtual node group list will be selected as leader.
### Synchronous Replication
### Synchronous Replication
For scenarios with strong data consistency requirements, asynchronous data replication is not applicable, because there is a small probability of data loss. So, TDengine provides a synchronous replication mechanism for users. When creating a database, in addition to specifying the number of replicas, user also needs to specify a new parameter “quorum”. If quorum is greater than one, it means that every time the Master forwards a message to the replica, it needs to wait for “quorum-1” reply confirms before informing the application that data has been successfully written in slave. If “quorum-1” reply confirms are not received within a certain period of time, the master vnode will return an error to the application.
For scenarios with strong data consistency requirements, asynchronous data replication is not applicable, because there is a small probability of data loss. So, TDengine provides a synchronous replication mechanism for users. When creating a database, in addition to specifying the number of replicas, user also needs to specify a new parameter “quorum”. If quorum is greater than one, it means that every time the Leader forwards a message to the replica, it needs to wait for “quorum-1” reply confirms before informing the application that data has been successfully written in follower. If “quorum-1” reply confirms are not received within a certain period of time, the leader vnode will return an error to the application.
With synchronous replication, performance of system will decrease and latency will increase. Because metadata needs strong consistency, the default for data synchronization between mnodes is synchronous replication.
With synchronous replication, performance of system will decrease and latency will increase. Because metadata needs strong consistency, the default for data synchronization between mnodes is synchronous replication.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}