Note: Since snappy lacks pkg-config support (refer to [link](https://github.com/google/snappy/pull/86)), it lead a cmake prompt libsnappy not found. But snappy will works well.
### Setup golang environment
TDengine includes few components developed by Go language. Please refer to golang.org official documentation for golang environment setup.
@@ -79,6 +79,10 @@ TDengine is a highly efficient platform to store, query, and analyze time-series
-[Windows Client](https://www.taosdata.com/blog/2019/07/26/514.html): compile your own Windows client, which is required by various connectors on the Windows environment
-[Rust Connector](/connector/rust): A taosc/RESTful API based TDengine client for Rust
## [Components and Tools](/tools/adapter)
*[taosAdapter](/tools/adapter)
## [Connections with Other Tools](/connections)
-[Grafana](/connections#grafana): query the data saved in TDengine and provide visualization
...
...
@@ -128,4 +132,4 @@ TDengine is a highly efficient platform to store, query, and analyze time-series
* user can reference from[TDengineTest.cs](https://github.com/taosdata/TDengine/tree/develop/tests/examples/C%23/TDengineTest) and learn how to define database connection,query,insert and other basic data manipulations.
* user can reference from[TDengineTest.cs](https://github.com/taosdata/TDengine/tree/develop/tests/examples/C\%23/TDengineTest) and learn how to define database connection,query,insert and other basic data manipulations.
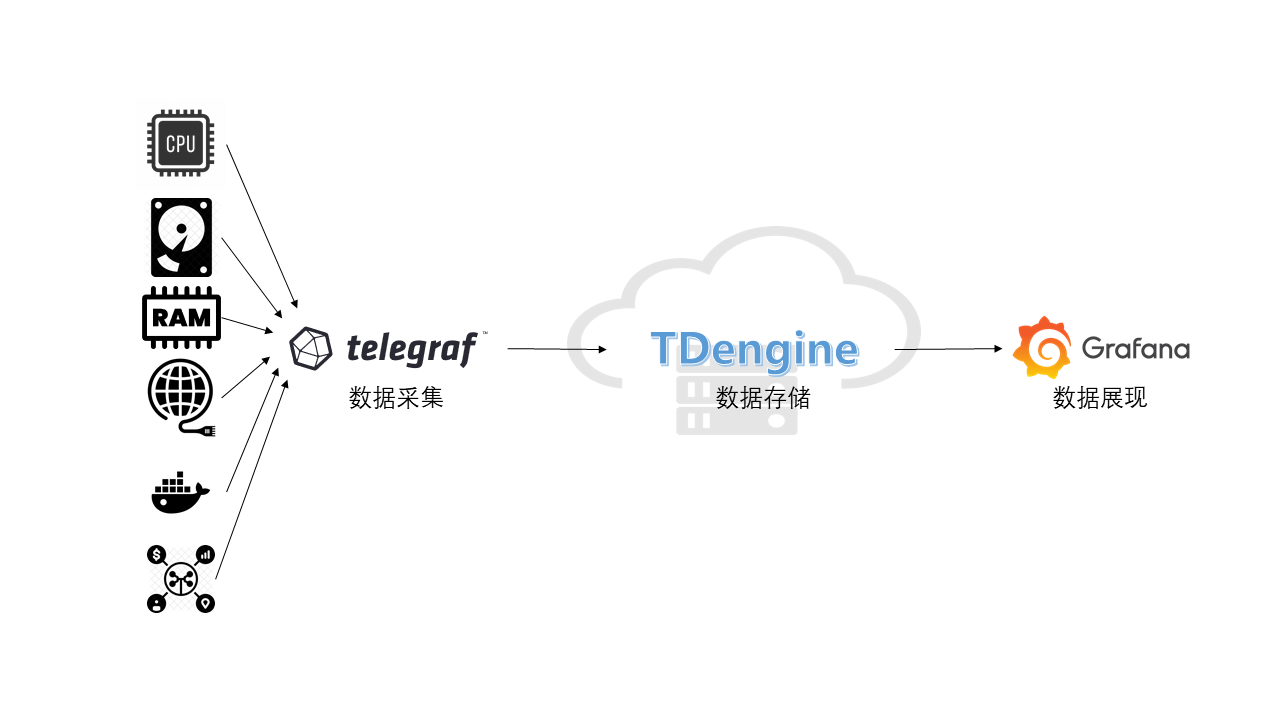
# Rapidly build an IT DevOps system with TDengine + Telegraf + Grafana
## Background
TDengine is an open-source big data platform designed and optimized for Internet of Things (IoT), Connected Vehicles, and Industrial IoT. Besides the 10x faster time-series database, it provides caching, stream computing, message queuing and other functionalities to reduce the complexity and costs of development and operations.
There are a lot of time-series data in the IT DevOps scenario, for example:
- Metrics of system resource: CPU, memory, IO and network status, etc.
- Metrics for software system: service status, number of connections, number of requests, number of the timeout, number of errors, response time, service type, and other metrics related to the specific business.
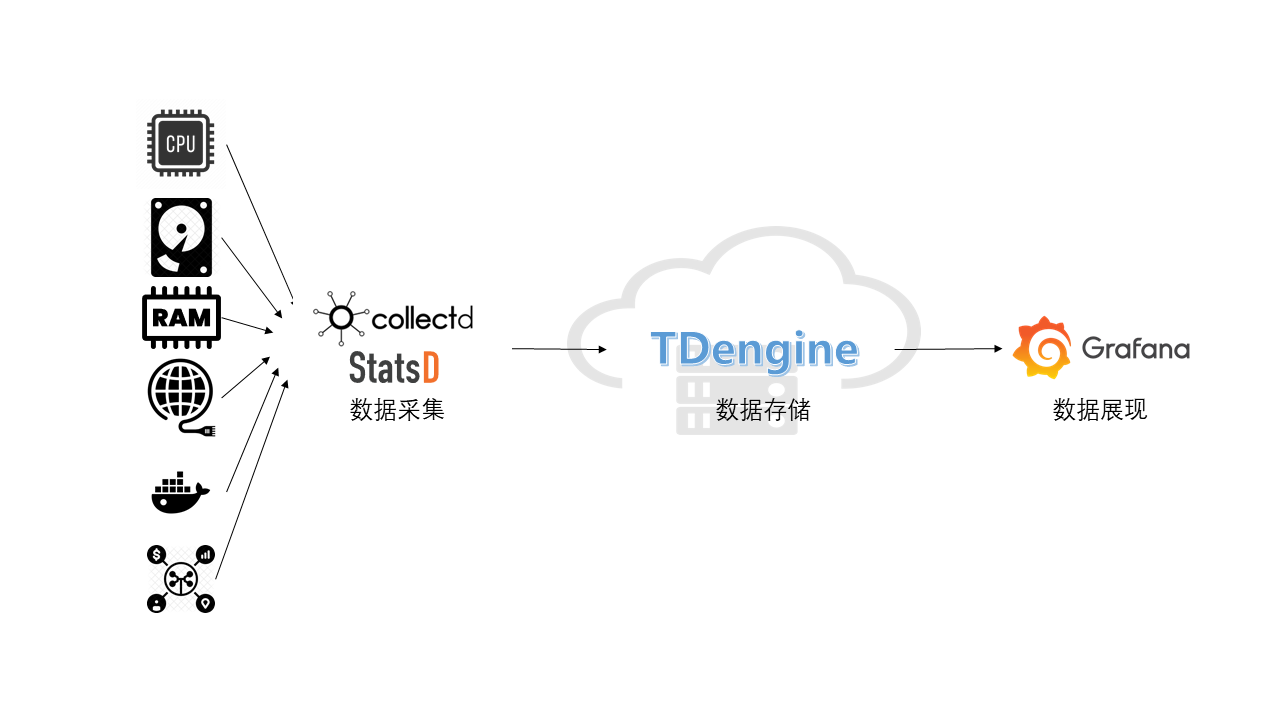
A mainstream IT DevOps system generally includes a data-collection module, a data persistent module, and a visualization module. Telegraf and Grafana are some of the most popular data-collection and visualization modules. But data persistent module can be varied. OpenTSDB and InfluxDB are some prominent from others. In recent times, TDengine, as emerged time-series data platform provides more advantages including high performance, high reliability, easier management, easier maintenance.
Here we introduce a way to build an IT DevOps system with TDengine, Telegraf, and Grafana. Even no need one line program code but just modify a few lines of configuration files.
Please add few lines in /etc/telegraf/telegraf.conf as below. Please fill database name for what you desire to save Telegraf's data in TDengine. Please specify the correct value for the hostname of the TDengine server/cluster, username, and password:
Use your Web browser to access IP:3000 to log in to the Grafana management interface. The default username and password are admin/admin。
Click the 'gear' icon from the left bar to select 'Plugins'. You could find the icon of the TDengine data source plugin.
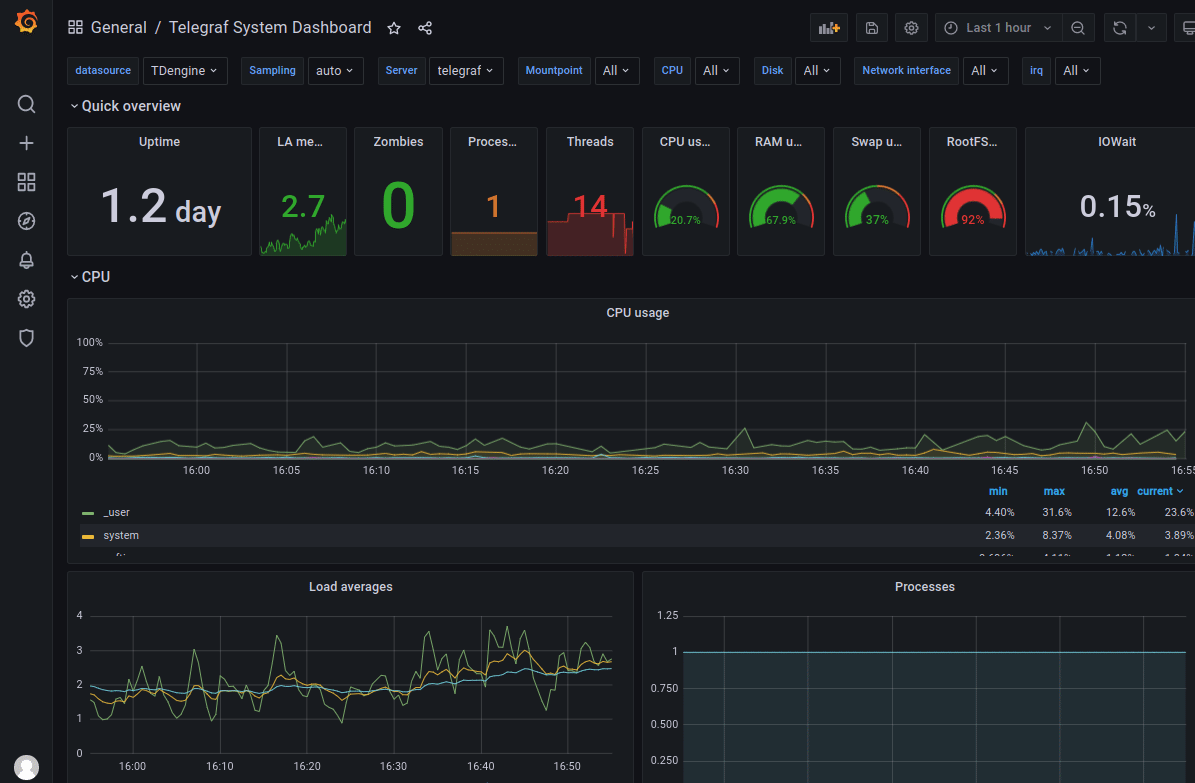
Click the 'plus' icon from the left bar to select 'Import'. You can download the dashboard JSON file from https://github.com/taosdata/grafanaplugin/blob/master/examples/telegraf/grafana/dashboards/telegraf-dashboard-v0.1.0.json then import it to the Grafana. After that, you should see the interface like:
We demonstrated how to build a full-function IT DevOps system with TDengine, Telegraf, and Grafana. TDengine supports schemaless protocol data insertion capability from 2.3.0.0. Based on TDengine's powerful ecosystem software integration capability, the user can build a high efficient and easy-to-maintain IT DevOps system in a few minutes. Please find more detailed documentation about TDengine high-performance data insertion/query functions and more use cases from TAOS Data's official website.
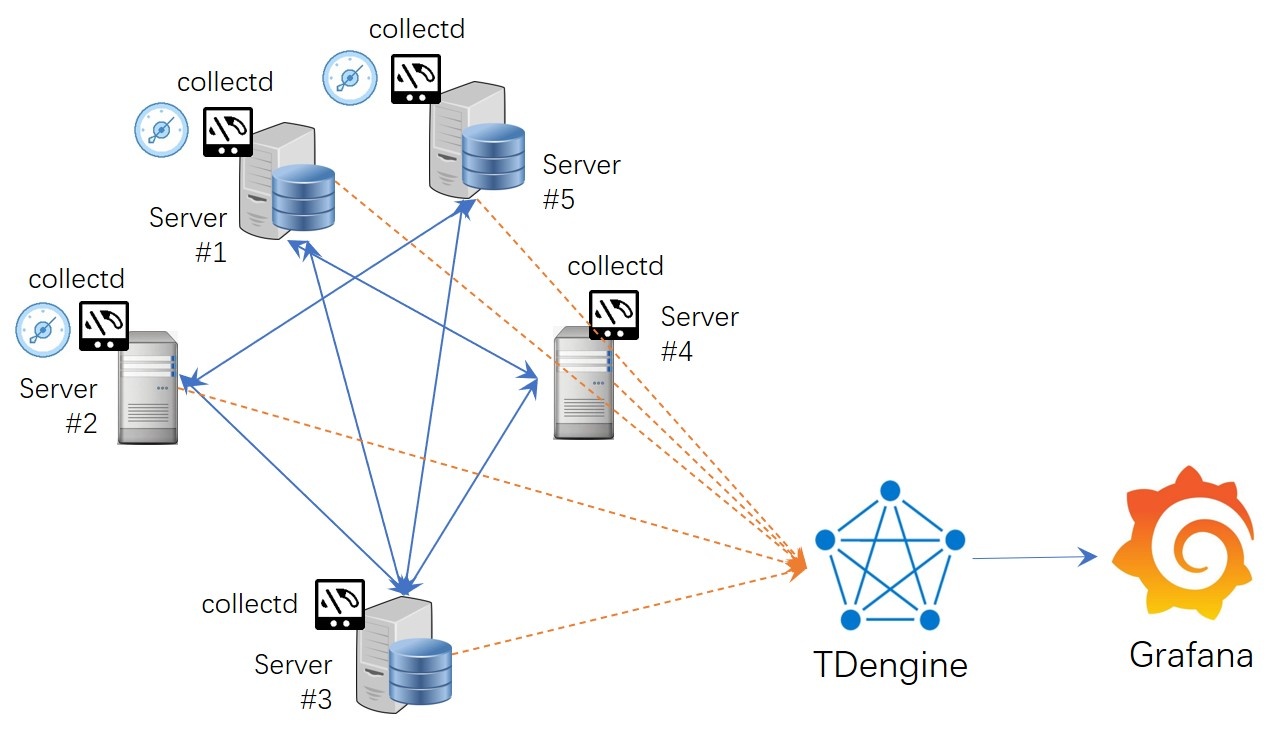
# Rapidly build a IT DevOps system with TDengine + collectd/StatsD + Grafana
## Background
TDengine is an open-source big data platform designed and optimized for Internet of Things (IoT), Connected Vehicles, and Industrial IoT. Besides the 10x faster time-series database, it provides caching, stream computing, message queuing and other functionalities to reduce the complexity and costs of development and operations.
There are a lot of time-series data in the IT DevOps scenario, for example:
- Metrics of system resource: CPU, memory, IO and network status, etc.
- Metrics for software system: service status, number of connections, number of requests, number of the timeout, number of errors, response time, service type, and other metrics related to the specific business.
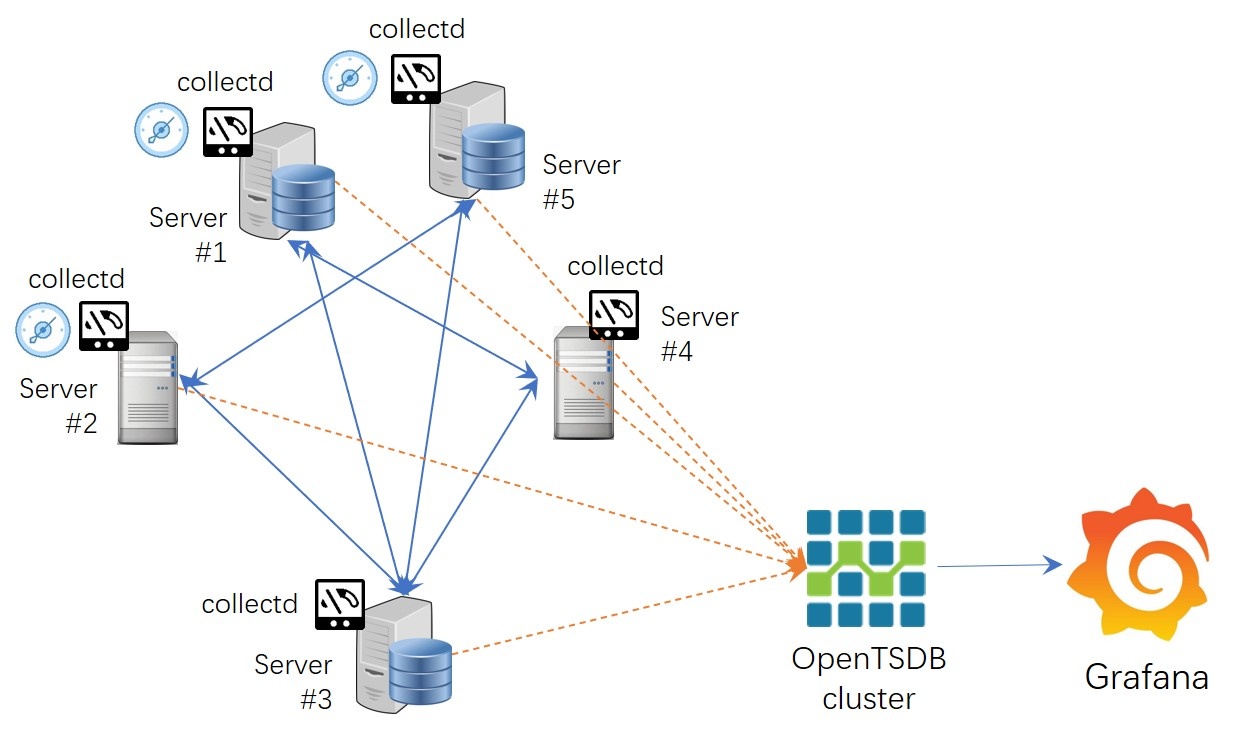
A mainstream IT DevOps system generally includes a data-collection module, a data persistent module, and a visualization module. Telegraf and Grafana are some of the most popular data-collection and visualization modules. But data persistent module can be varied. OpenTSDB and InfluxDB are some prominent from others. In recent times, TDengine, as emerged time-series data platform provides more advantages including high performance, high reliability, easier management, easier maintenance.
Here we introduce a way to build an IT DevOps system with TDengine, collectd/statsD, and Grafana. Even no need one line program code but just modify a few lines of configuration files.
Please add a few lines in /etc/collectd/collectd.conf as below. Please specify the correct value for hostname and the port number:
```
LoadPlugin network
<Plugin network>
Server "<TDengine cluster/server host>" "<port for collectd>"
</Plugin>
sudo systemctl start collectd
```
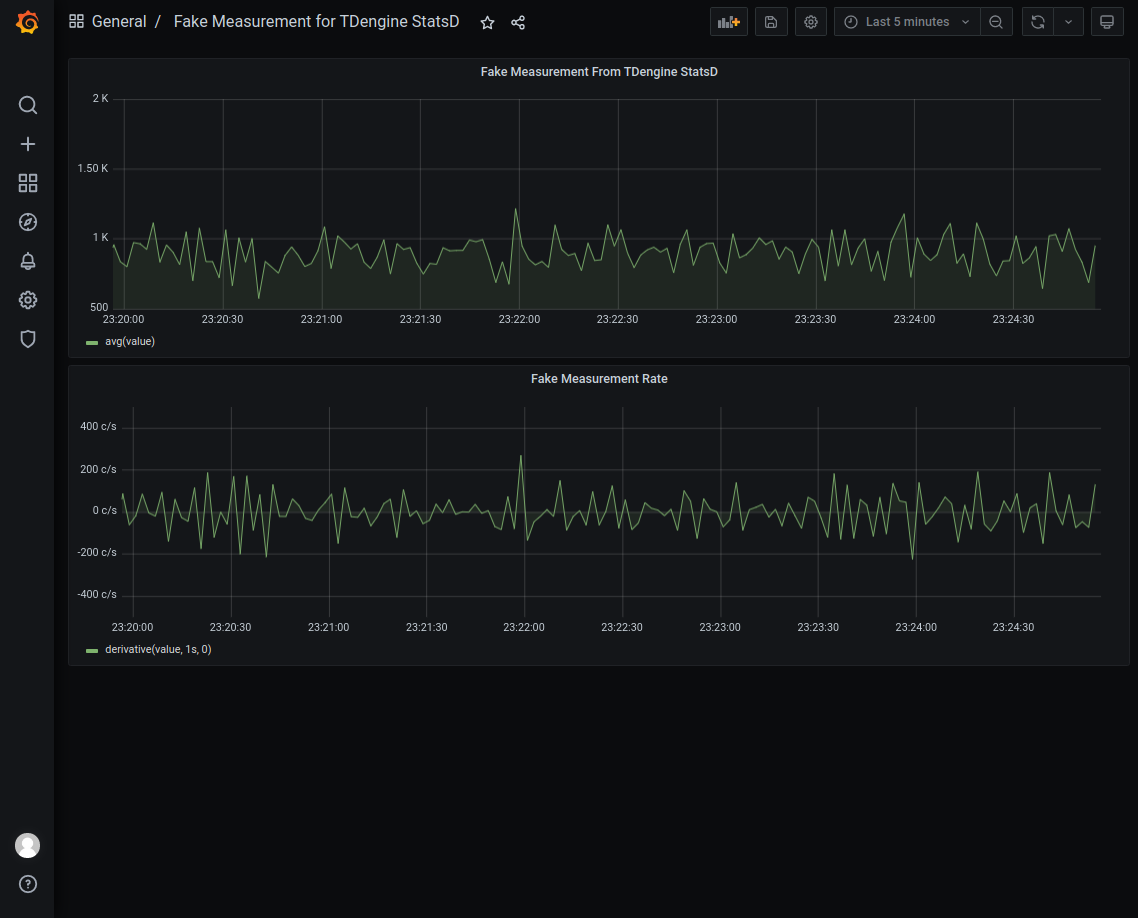
### To configure StatsD
Please add a few lines in the config.js file then restart StatsD. Please use the correct hostname and port number of TDengine and taosAdapter:
```
fill backends section with "./backends/repeater"
fill repeater section with { host:'<TDengine server/cluster host>', port: <port for StatsD>}
```
### Import dashboard
Use your Web browser to access IP:3000 to log in to the Grafana management interface. The default username and password are admin/admin。
Click the gear icon from the left bar to select 'Plugins'. You could find the icon of the TDengine data source plugin.
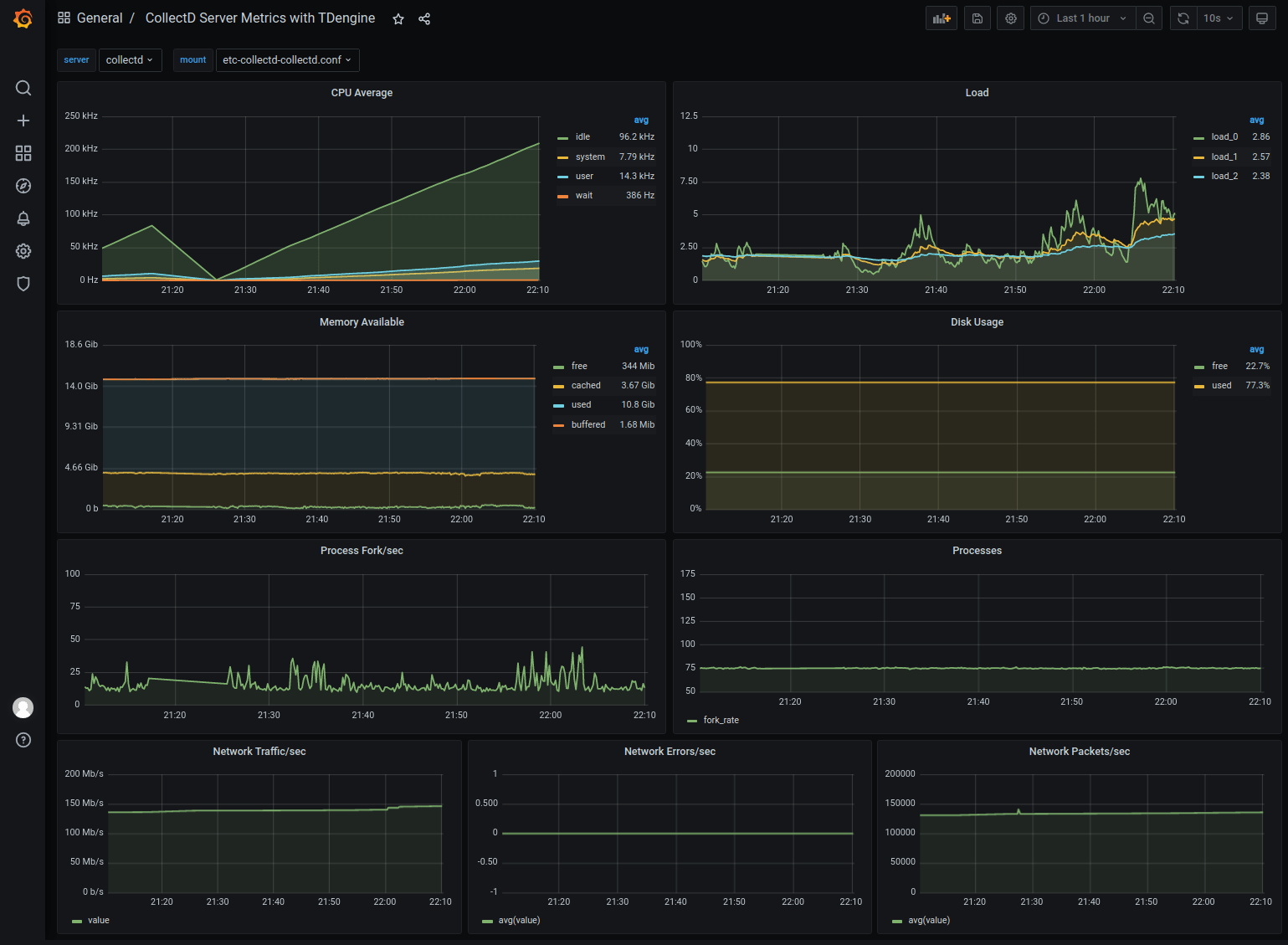
#### Import collectd dashboard
Please download the dashboard JSON file from https://github.com/taosdata/grafanaplugin/blob/master/examples/collectd/grafana/dashboards/collect-metrics-with-tdengine-v0.1.0.json.
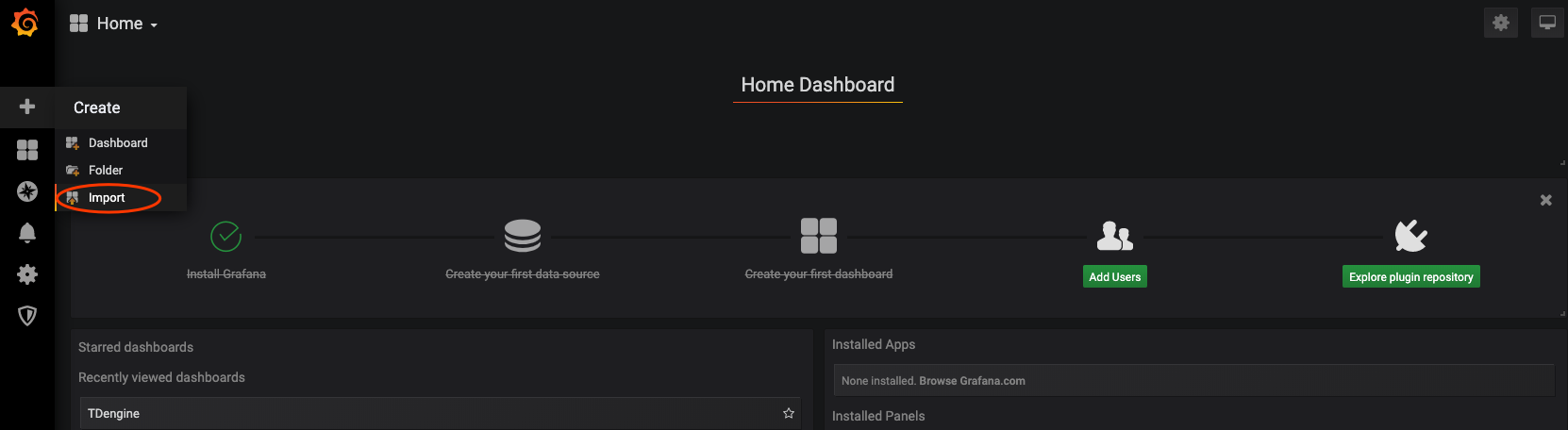
Click the 'plus' icon from the left bar to select 'Import'. Then you should see the interface like:
We demonstrated how to build a full-function IT DevOps system with TDengine, collectd, StatsD, and Grafana. TDengine supports schemaless protocol data insertion capability from 2.3.0.0. Based on TDengine's powerful ecosystem software integration capability, the user can build a high efficient and easy-to-maintain IT DevOps system in few minutes. Please find more detailed documentation about TDengine high-performance data insertion/query functions and more use cases from TAOS Data's official website.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}