[td-225] merge develop.
Showing
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
documentation20/en/13.faq/docs.md
0 → 100644
此差异已折叠。
{kind=link}
96.9 KB
{kind=link}
文件已移动
{kind=link}
86.9 KB
{kind=link}
文件已移动
{kind=link}
36.6 KB
{kind=link}
114.5 KB
{kind=link}
91.1 KB
{kind=link}
文件已移动
{kind=link}
54.3 KB
{kind=link}
70.8 KB
{kind=link}
56.3 KB
{kind=link}
53.4 KB
{kind=link}
44.0 KB
{kind=link}
55.0 KB
{kind=link}
60.2 KB
{kind=link}
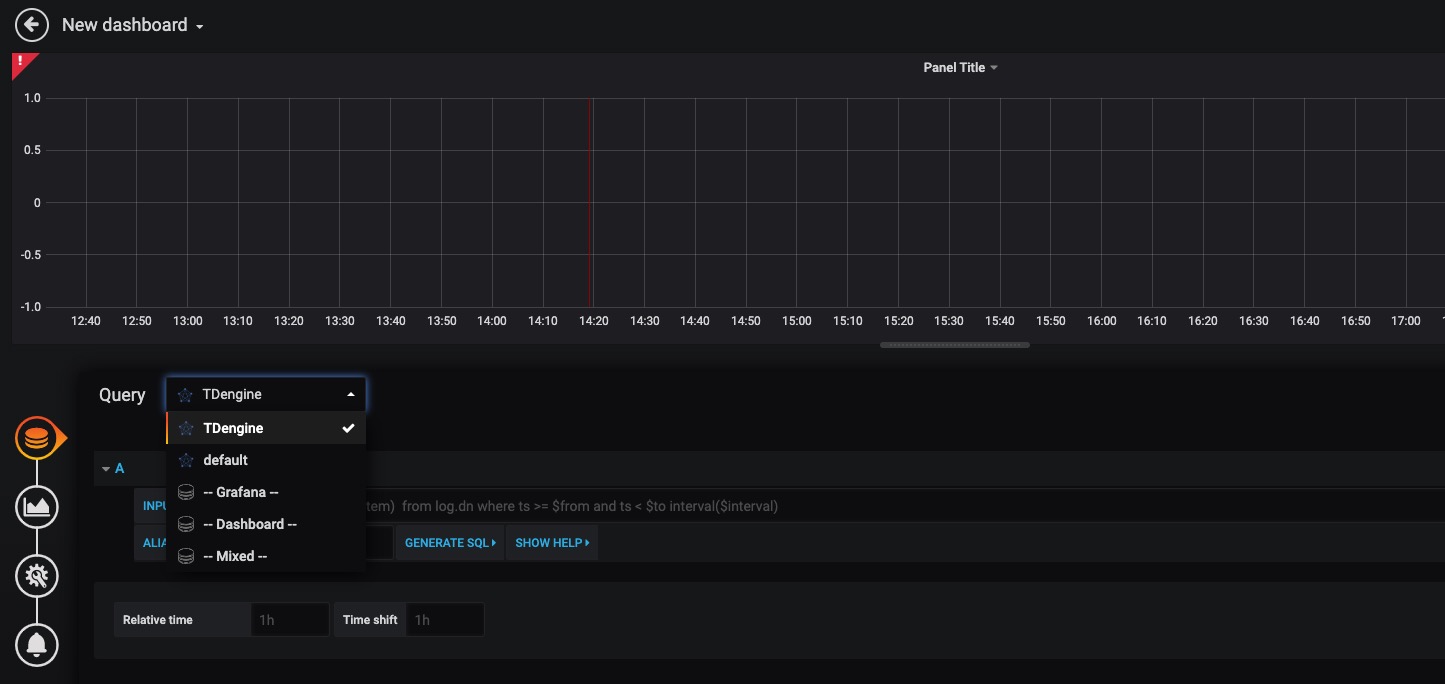
90.8 KB
{kind=link}
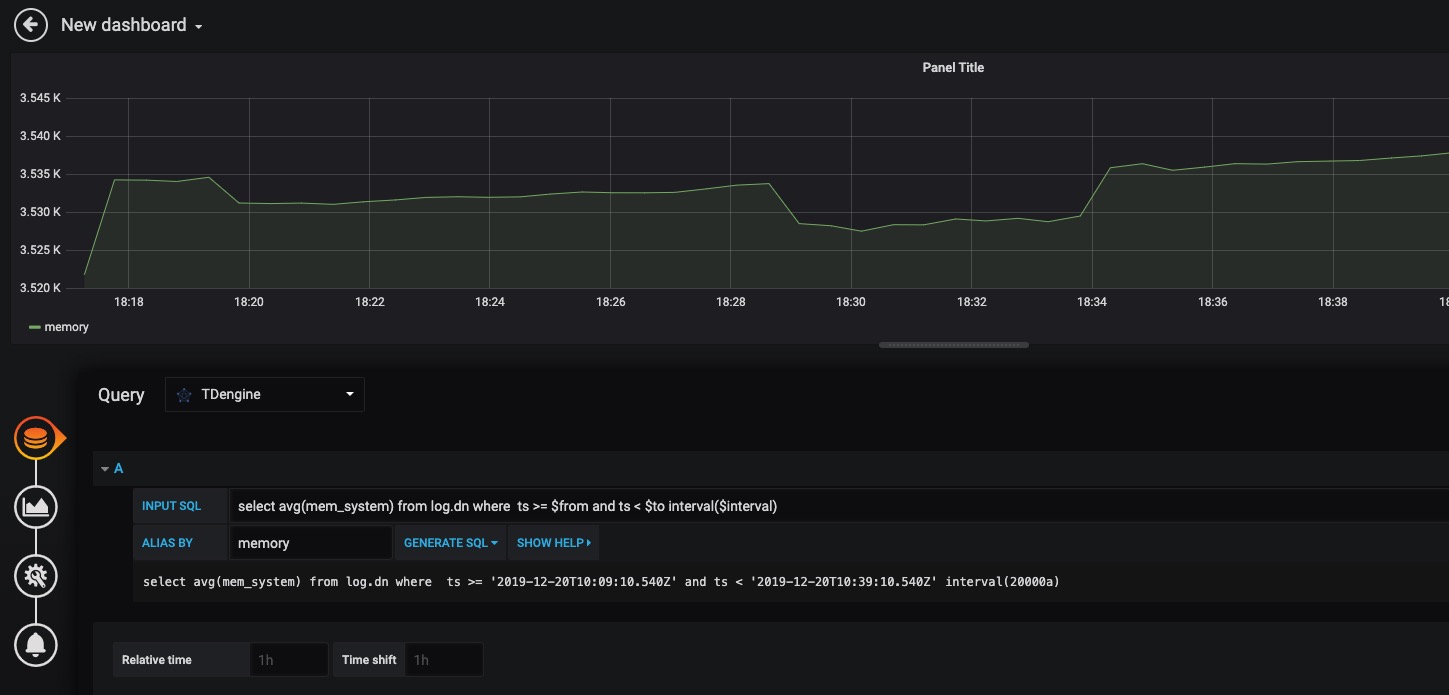
96.9 KB
{kind=link}
44.7 KB
{kind=link}
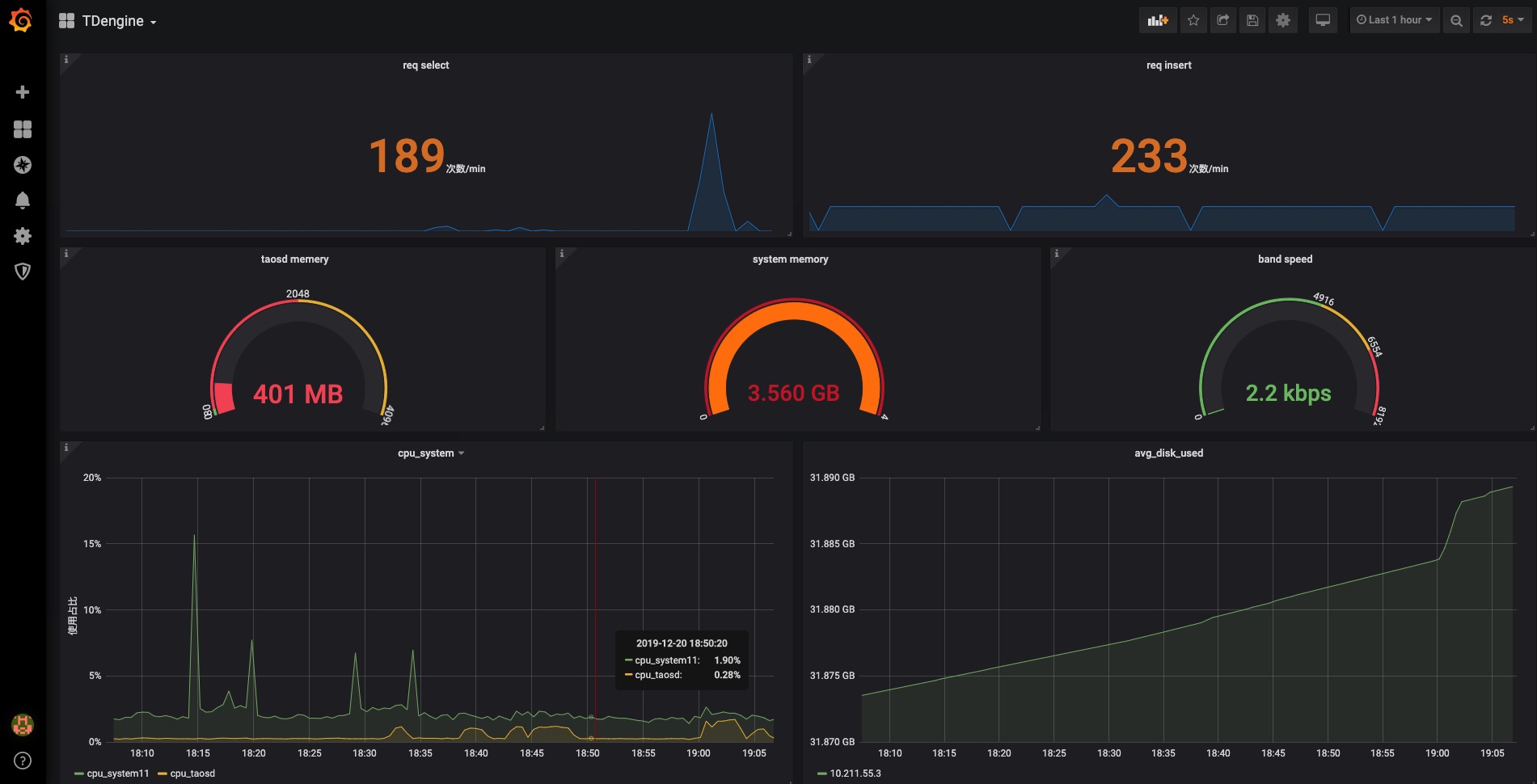
161.5 KB
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
packaging/check_package.sh
0 → 100755
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
packaging/tools/install_tq.sh
0 → 100755
此差异已折叠。
packaging/tools/makearbi_tq.sh
0 → 100755
此差异已折叠。
packaging/tools/makeclient_tq.sh
0 → 100755
此差异已折叠。
packaging/tools/makepkg_tq.sh
0 → 100755
此差异已折叠。
packaging/tools/remove_arbi_tq.sh
0 → 100755
此差异已折叠。
此差异已折叠。
packaging/tools/remove_tq.sh
0 → 100755
此差异已折叠。
packaging/tools/startPre.sh
100644 → 100755
文件模式从 100644 更改为 100755
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
src/tsdb/inc/tsdbCompact.h
0 → 100644
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。