Merge pull request #12497 from taosdata/docs/wade-20220515-3
docs: resolve missing png in 01-arch.md
Showing
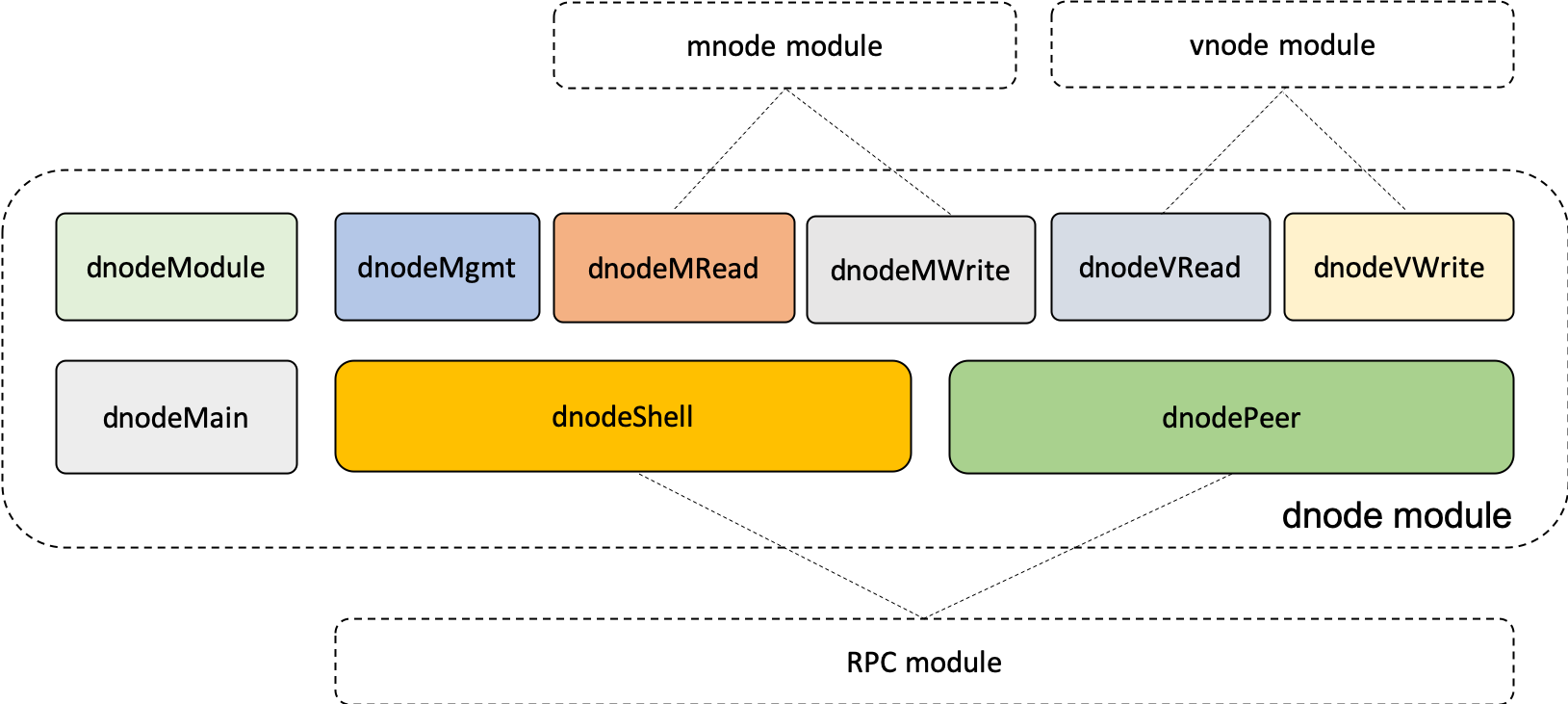
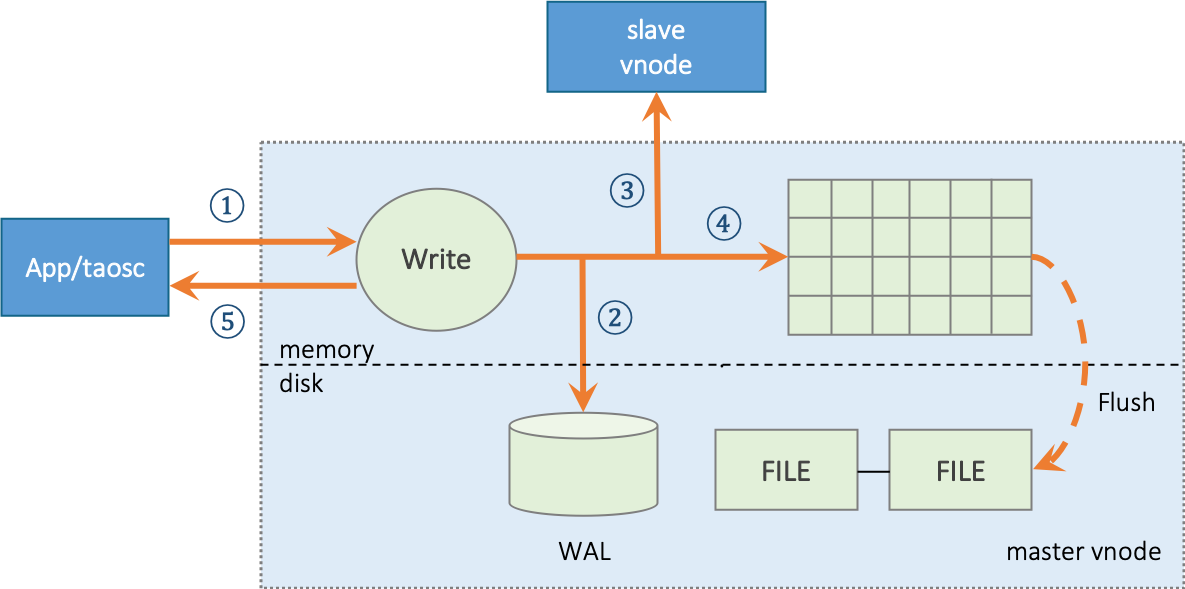
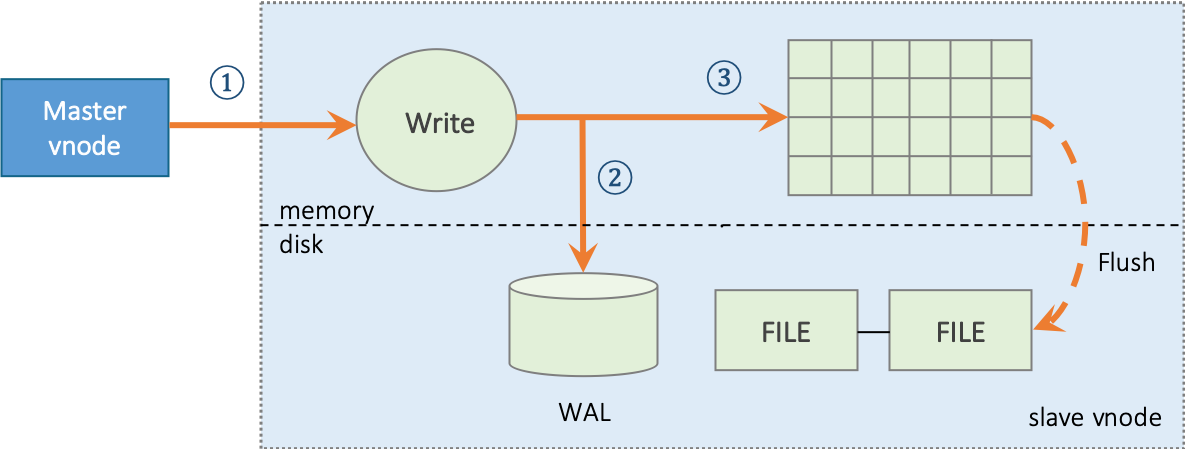
docs-en/21-tdinternal/dnode.png
0 → 100644
{kind=link}
96.9 KB
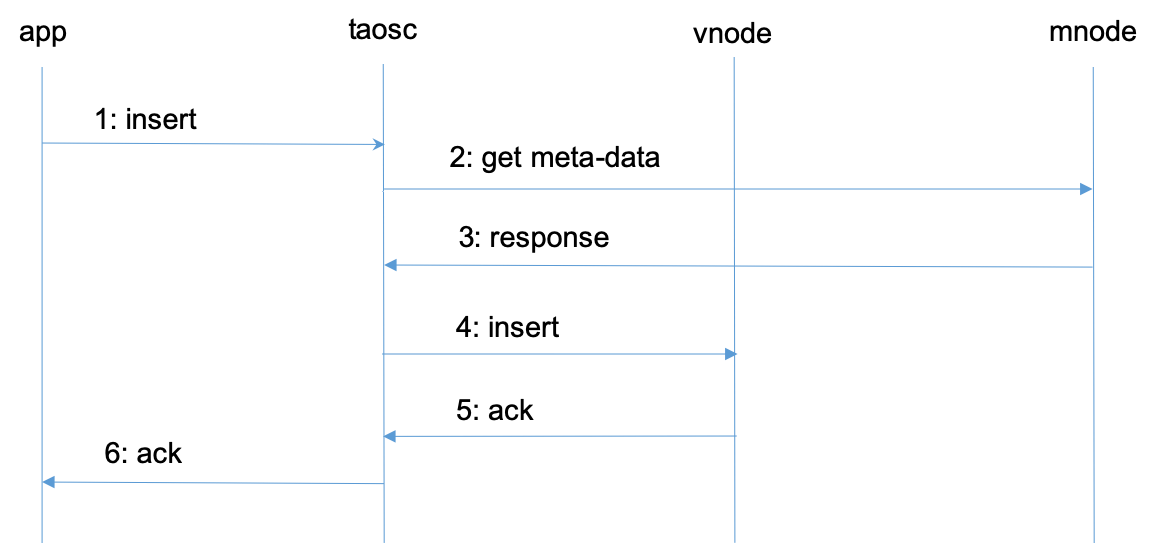
docs-en/21-tdinternal/message.png
0 → 100644
{kind=link}
43.2 KB
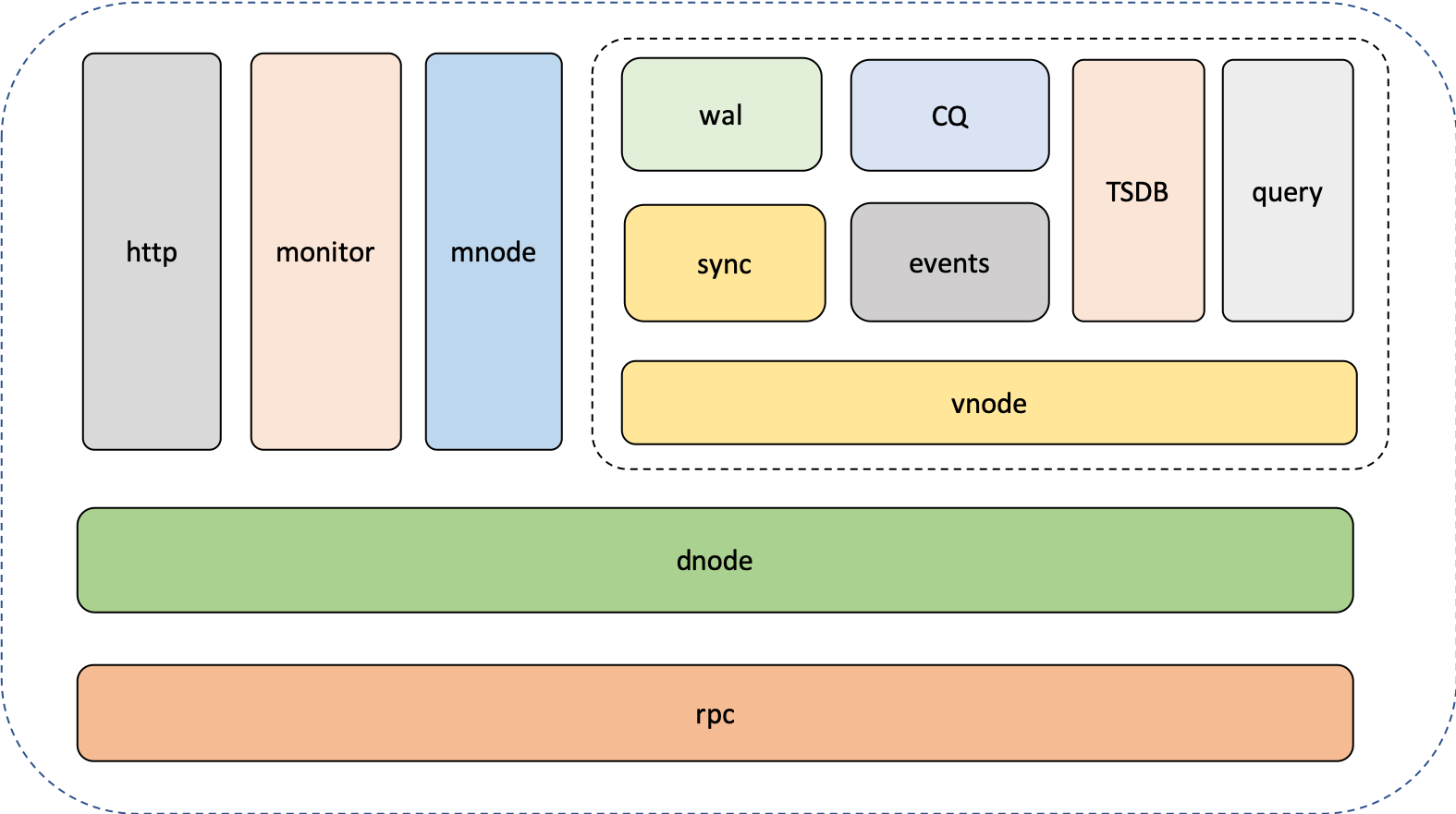
docs-en/21-tdinternal/modules.png
0 → 100644
{kind=link}
86.9 KB
{kind=link}
65.7 KB
{kind=link}
36.6 KB
{kind=link}
114.5 KB
{kind=link}
91.1 KB
{kind=link}
92.3 KB
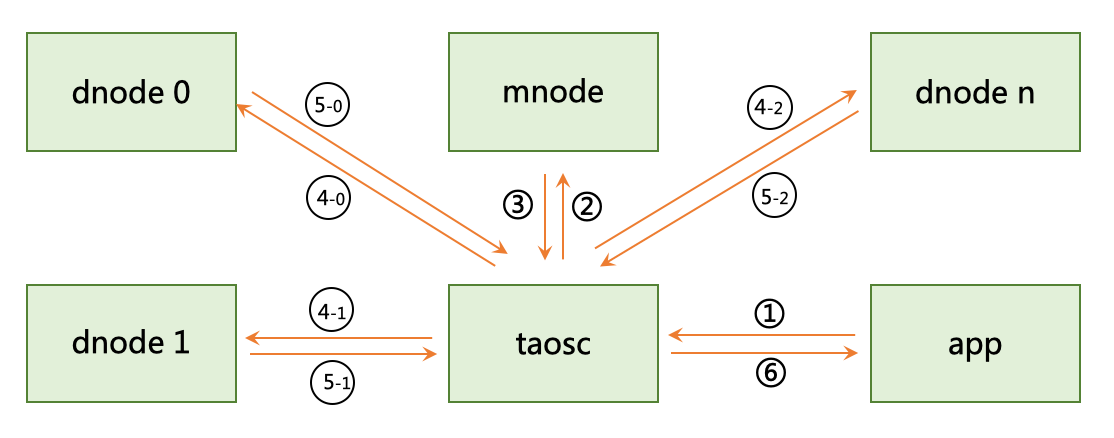
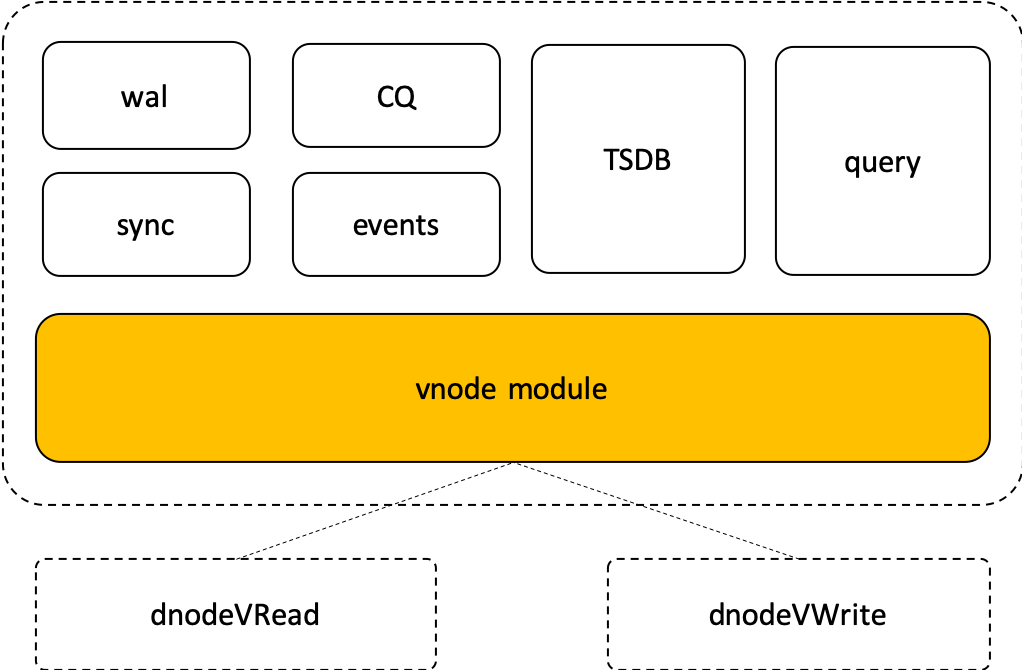
docs-en/21-tdinternal/vnode.png
0 → 100644
{kind=link}
54.3 KB
{kind=link}
70.8 KB
{kind=link}
56.3 KB