The effectiveness of the deep learning model is often directly related to the scale of the data: it can generally achieve better results after increasing the size of the dataset on the same model. However, it can not fit in one single computer when the amount of data increases to a certain extent. At this point, using multiple computers for distributed training is a natural solution. In distributed training, the training data is divided into multiple copies (sharding), and multiple machines participating in the training read their own data for training and collaboratively update the parameters of the overall model.
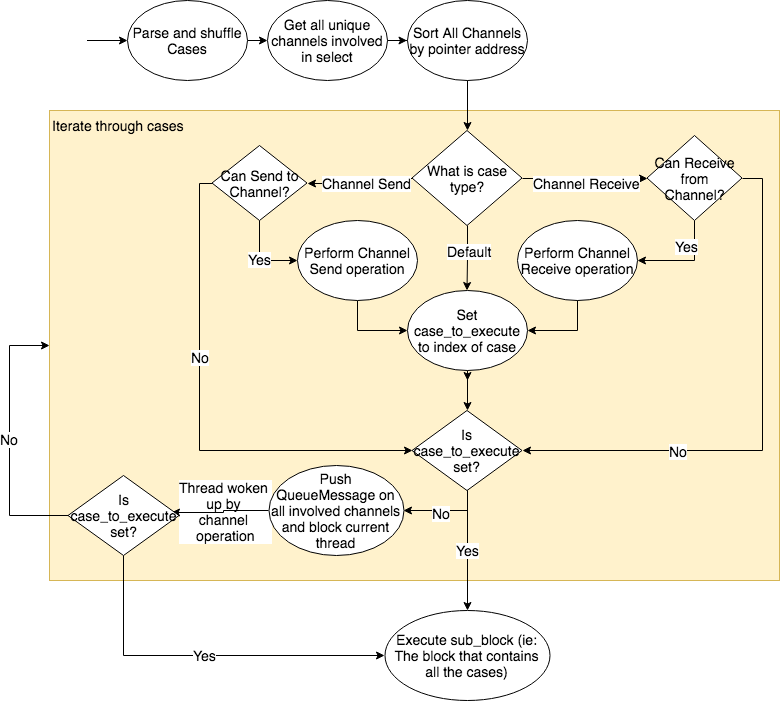
Distributed training generally has framwork as shown below:
{kind=link}