Merge remote-tracking branch 'upstream/develop' into doc
Showing
cmake/external/cares.cmake
0 → 100644
cmake/external/grpc.cmake
0 → 100644
{kind=link}
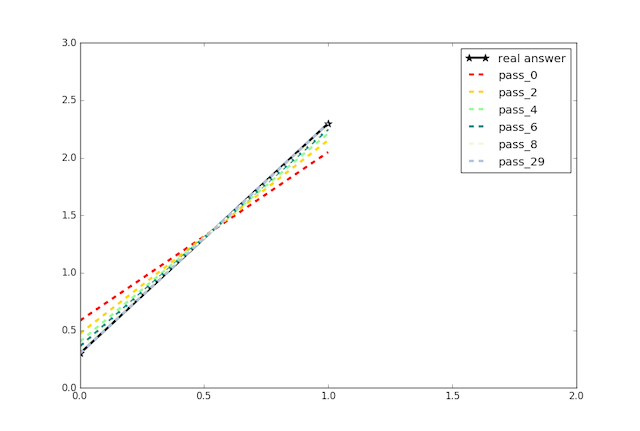
43.4 KB
{kind=link}
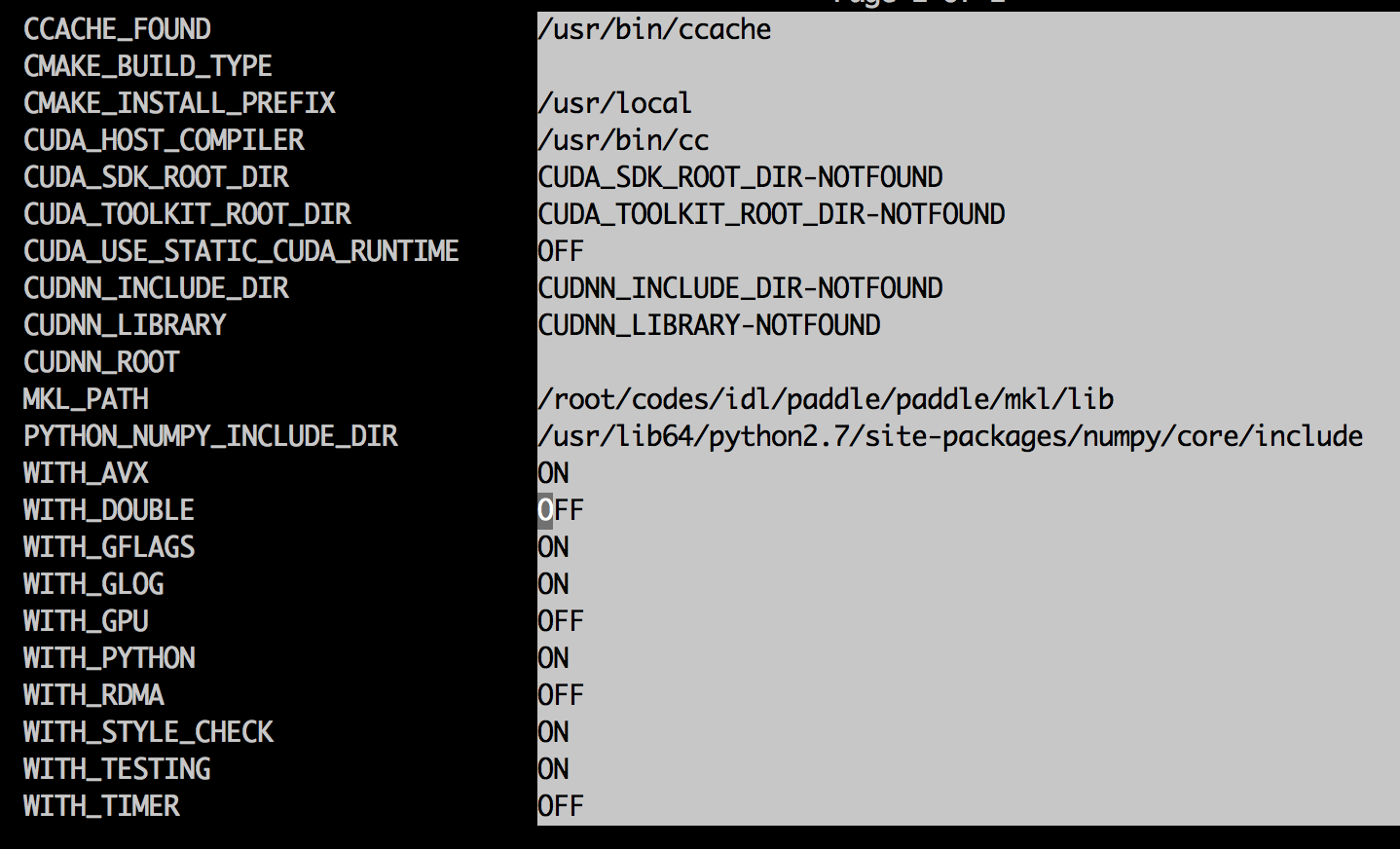
179.1 KB
{kind=link}
39.3 KB
{kind=link}
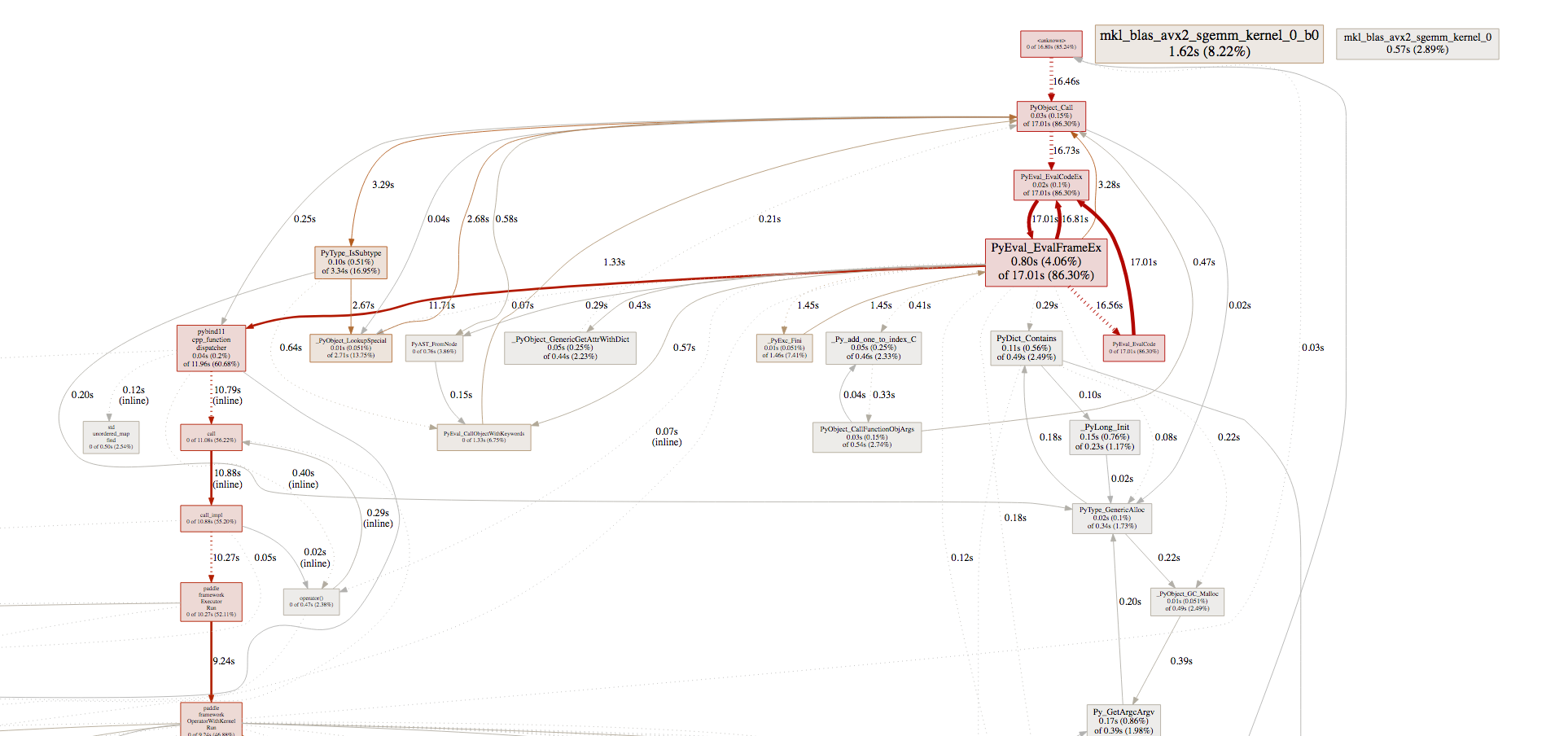
344.4 KB
{kind=link}

189.5 KB
paddle/framework/tensor_util.h
0 → 100644
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
paddle/operators/log_loss_op.cc
0 → 100644
此差异已折叠。
paddle/operators/log_loss_op.cu
0 → 100644
此差异已折叠。
paddle/operators/log_loss_op.h
0 → 100644
此差异已折叠。
此差异已折叠。
此差异已折叠。
paddle/operators/math/unpooling.h
0 → 100644
此差异已折叠。
此差异已折叠。
paddle/operators/recv_op.cc
0 → 100644
此差异已折叠。
此差异已折叠。
此差异已折叠。
paddle/operators/roi_pool_op.cc
100755 → 100644
此差异已折叠。
paddle/operators/roi_pool_op.cu
100755 → 100644
此差异已折叠。
paddle/operators/roi_pool_op.h
100755 → 100644
此差异已折叠。
paddle/operators/send_op.cc
0 → 100644
此差异已折叠。
此差异已折叠。
paddle/operators/sequence_slice_op.cc
100755 → 100644
此差异已折叠。
paddle/operators/sequence_slice_op.h
100755 → 100644
此差异已折叠。
paddle/operators/tensor.save
0 → 100644
此差异已折叠。
paddle/operators/unpool_op.cc
0 → 100644
此差异已折叠。
paddle/operators/unpool_op.cu.cc
0 → 100644
此差异已折叠。
paddle/operators/unpool_op.h
0 → 100644
此差异已折叠。
paddle/platform/cuda_profiler.h
0 → 100644
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。