docs(stonedb): Update the latest documents(#409) (#410)
* docs(stonedb): Update the latest documents(#409) * Update compile-using-centos7.md * Delete use-mydumper-full-backup.md The current topic is the latest. * Delete use-mysqldump-backup-and-restore.md The current topic online is the latest. * Update use-navicat.md changed the No. of steps. * Delete use-mydumper-full-backup.md The current topic online is the latest. * Delete regular-change-operations.md The current topic online is the latest. Co-authored-by: Nhaitaoguan <105625912+haitaoguan@users.noreply.github.com> Co-authored-by: Nxuejiao-joy <107540910+xuejiao-joy@users.noreply.github.com>
Showing
| W: | H:
| W: | H:
238.3 KB
92.1 KB
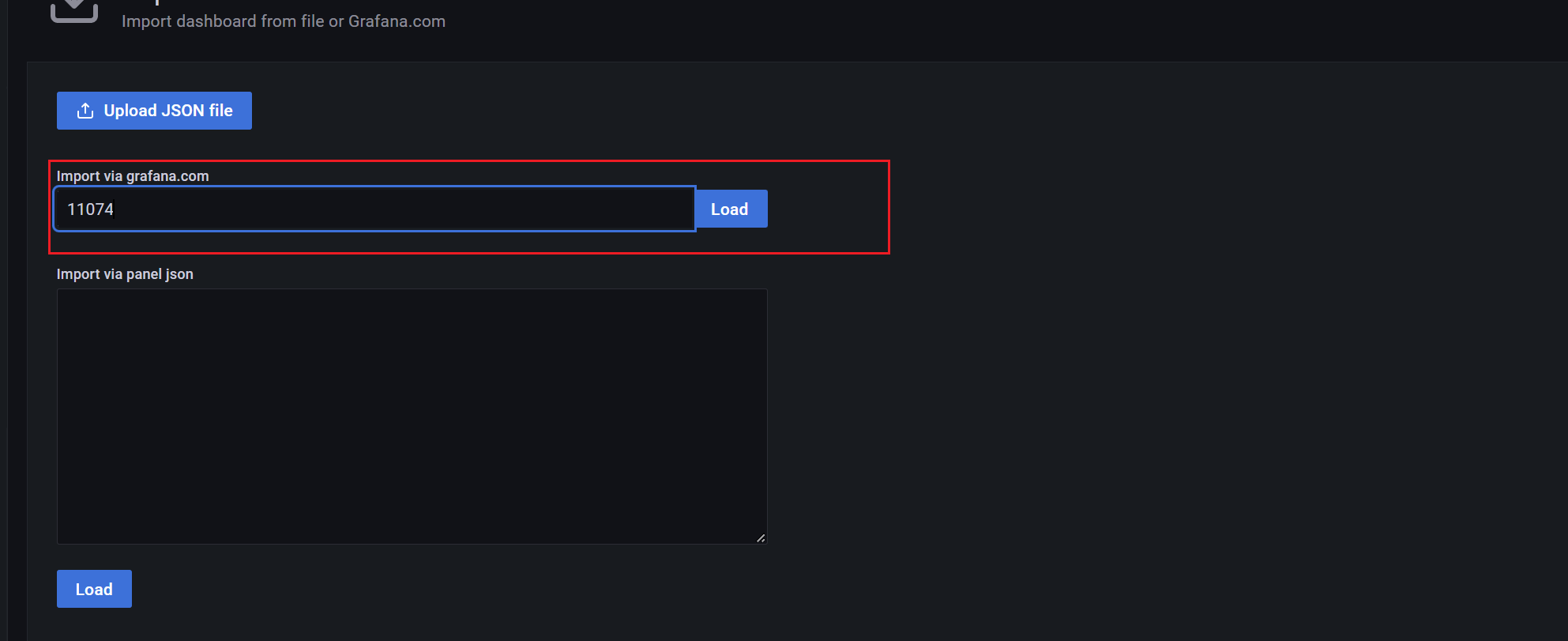
28.3 KB
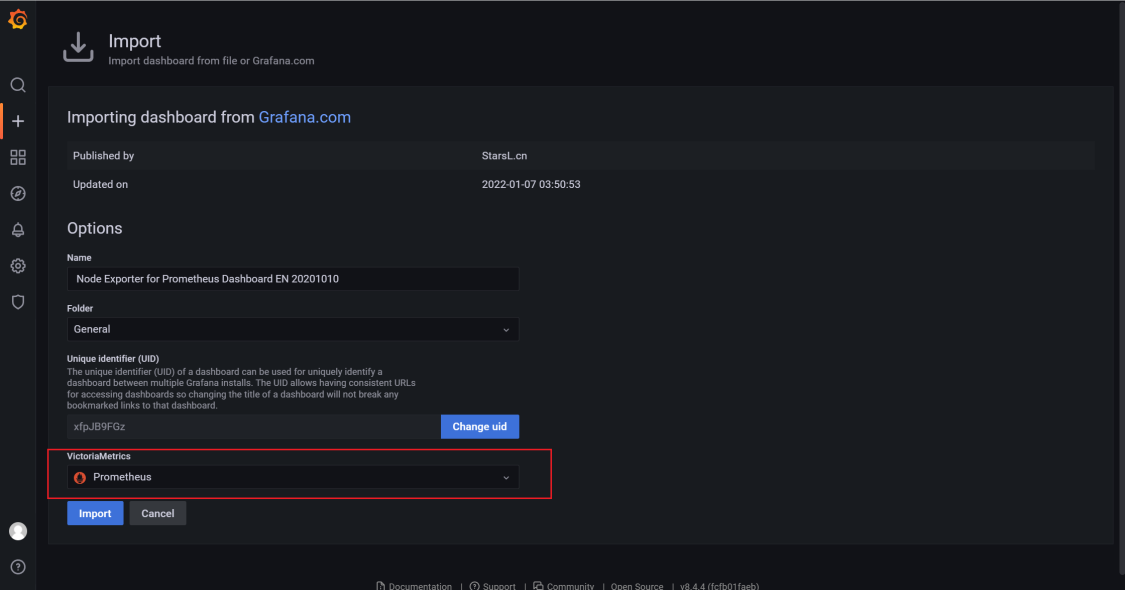
75.2 KB
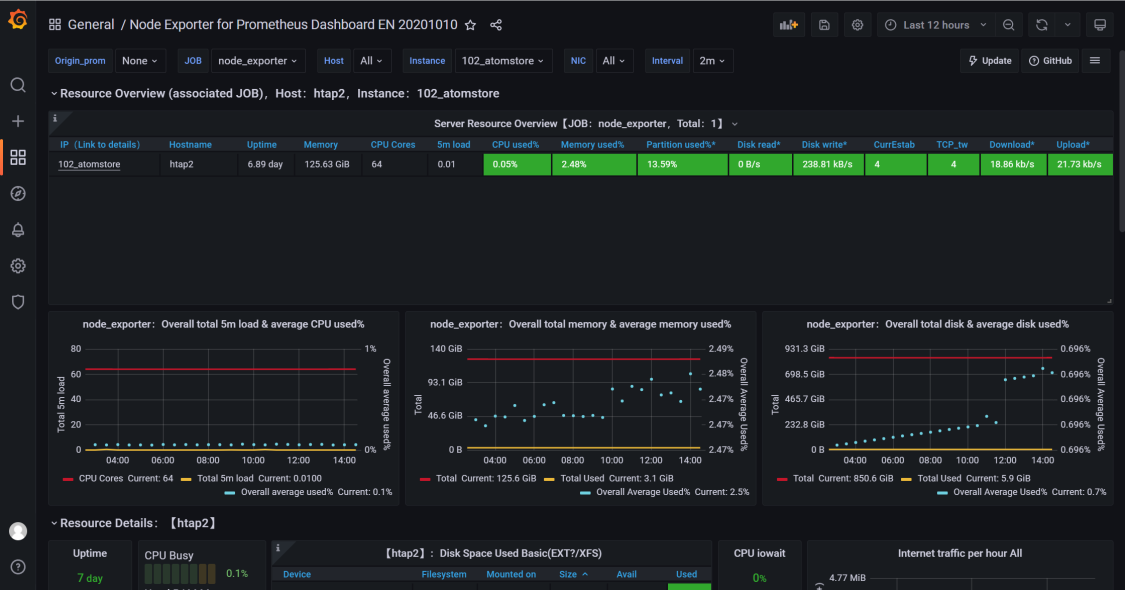
183.4 KB
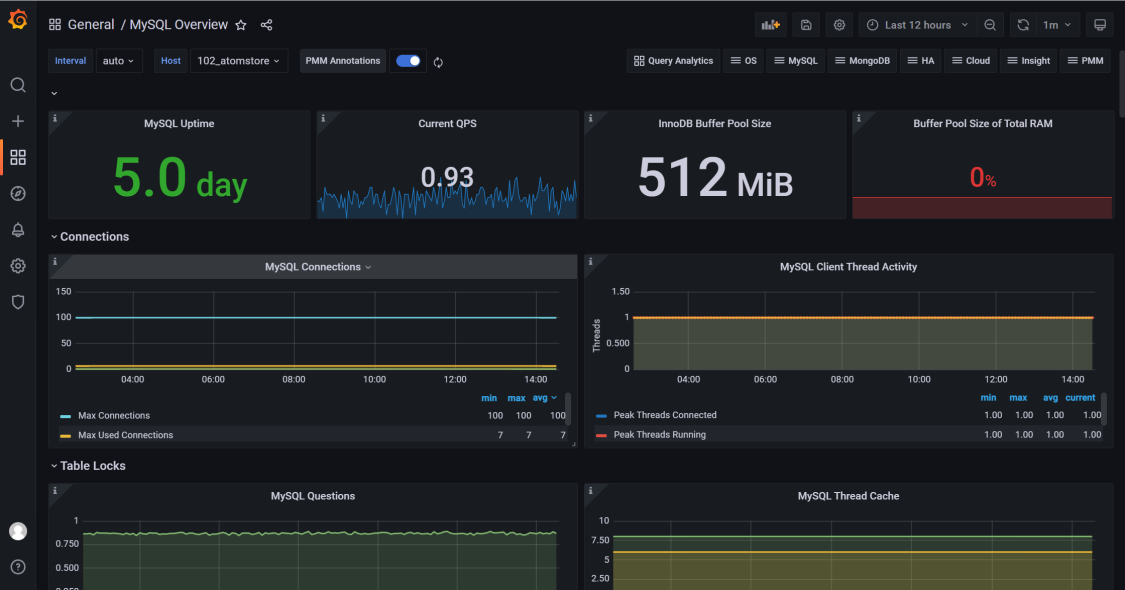
122.2 KB
20.2 KB
124.3 KB
124.1 KB
277.3 KB
21.4 KB
98.0 KB
此差异已折叠。
文件已移动
文件已移动
文件已移动
31.6 KB
24.3 KB
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
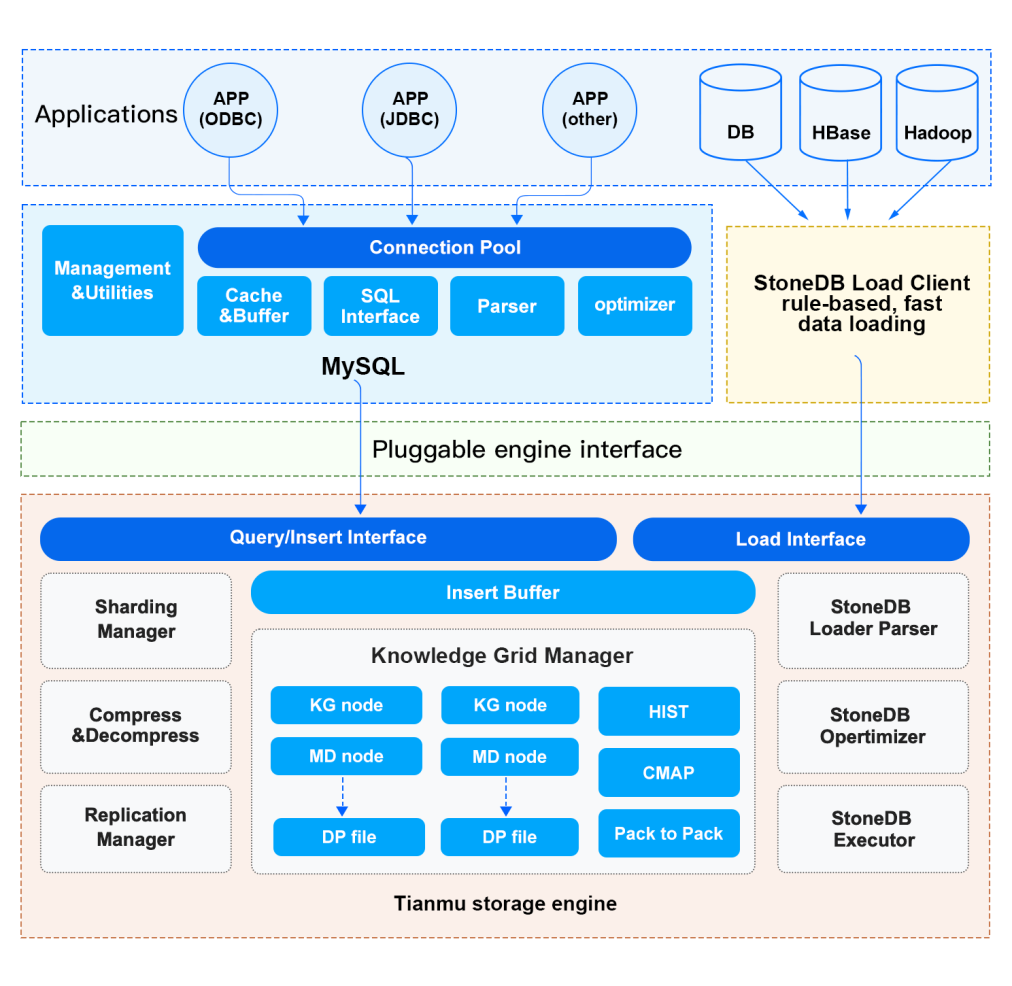
| W: | H:
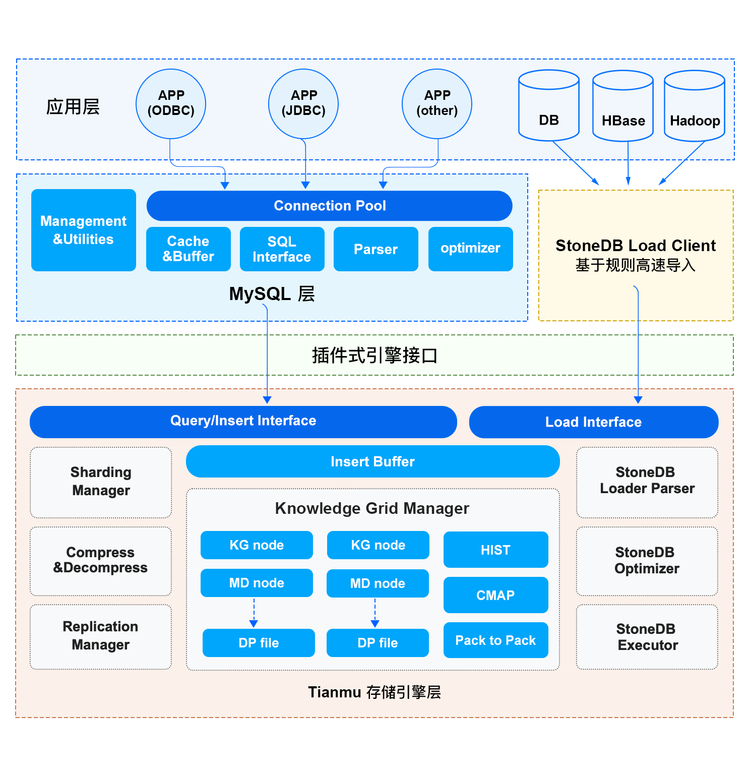
| W: | H:
{kind=link}
{kind=link}
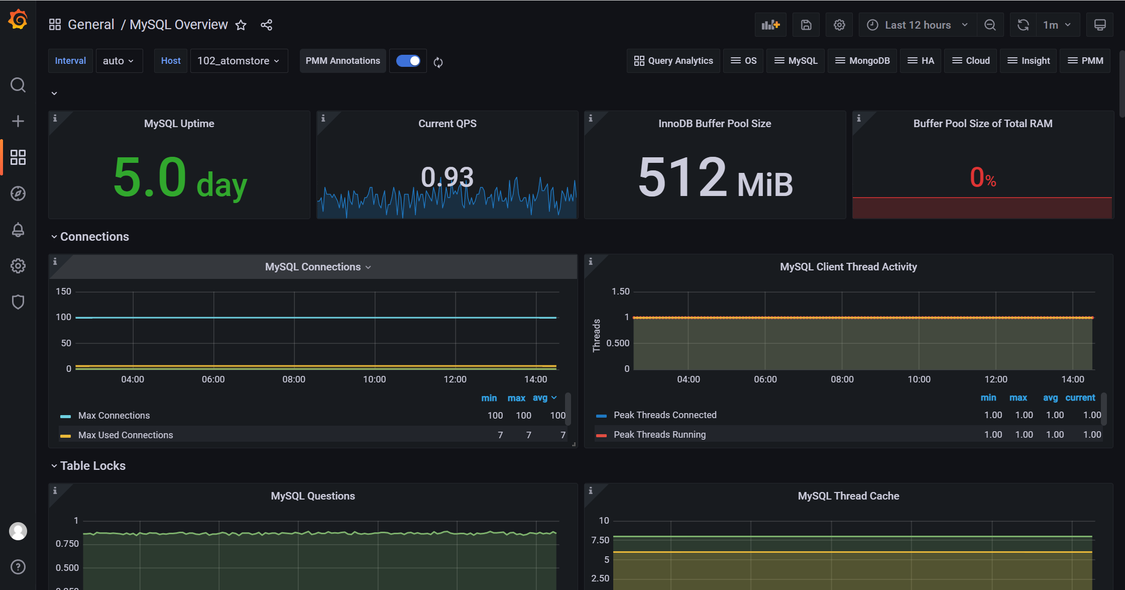
| W: | H:
| W: | H:
{kind=link}
{kind=link}
| W: | H:
| W: | H:
{kind=link}
{kind=link}
| W: | H:
| W: | H:
此差异已折叠。