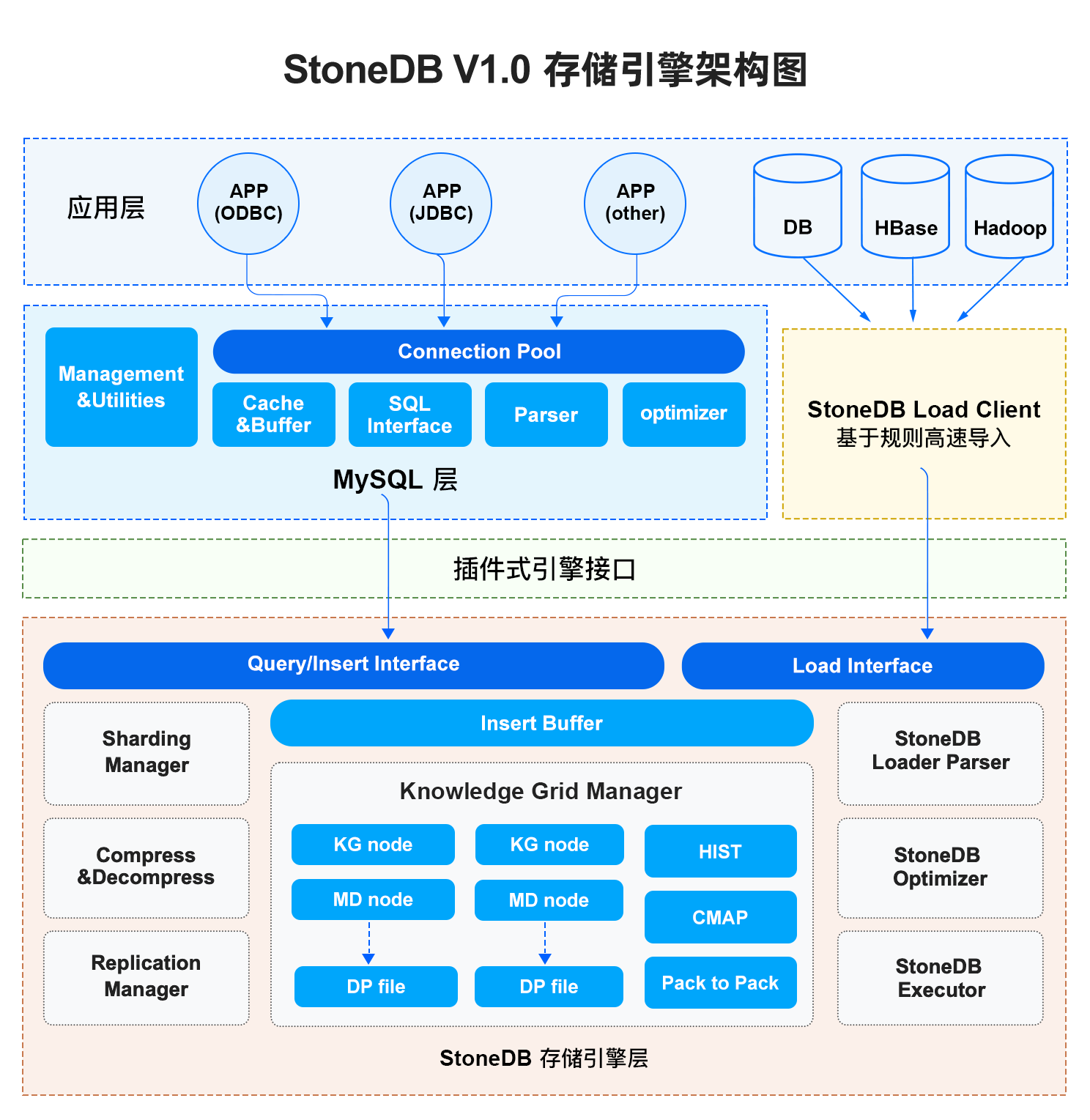
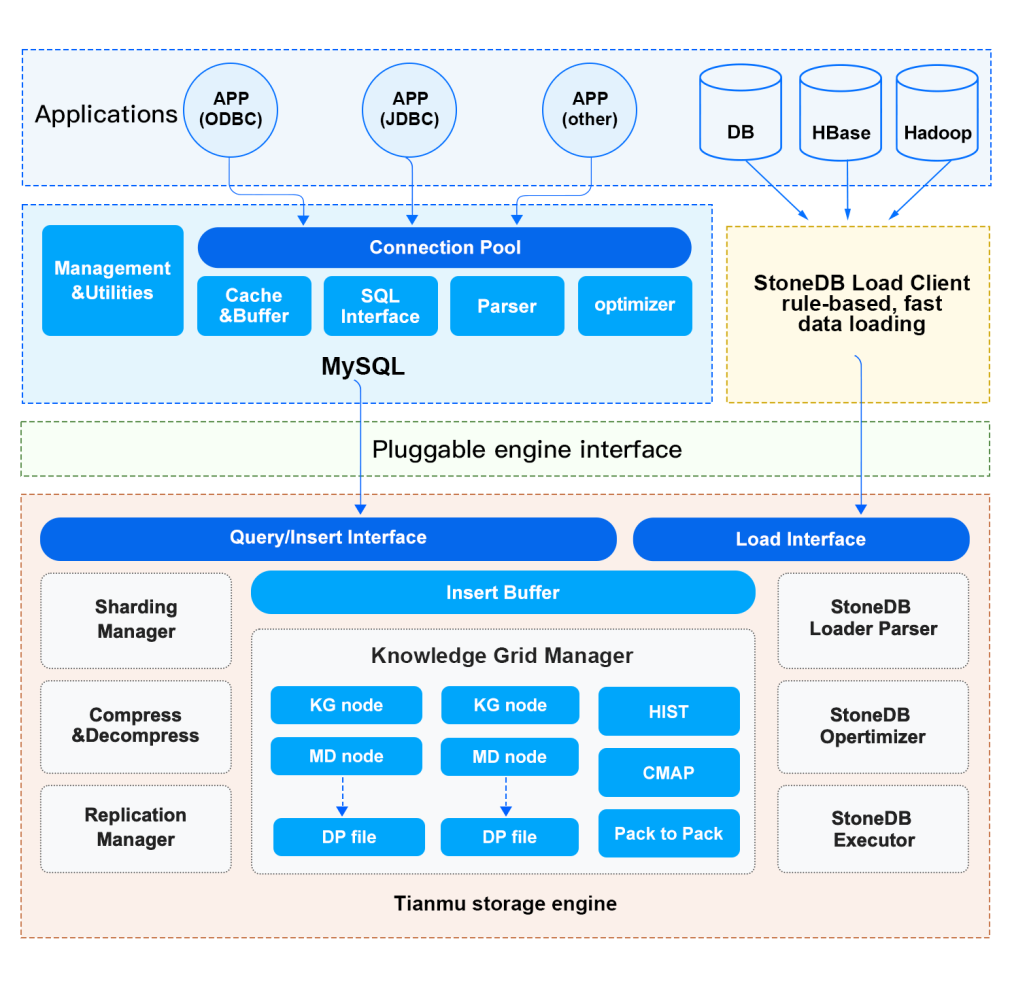
docs(stonedb): update the latest docs(#391) (#392)
* docs(stonedb): update the latest docs(#391) * docs(stonedb): update the docs of Architechure and Limits
Showing
{kind=link}
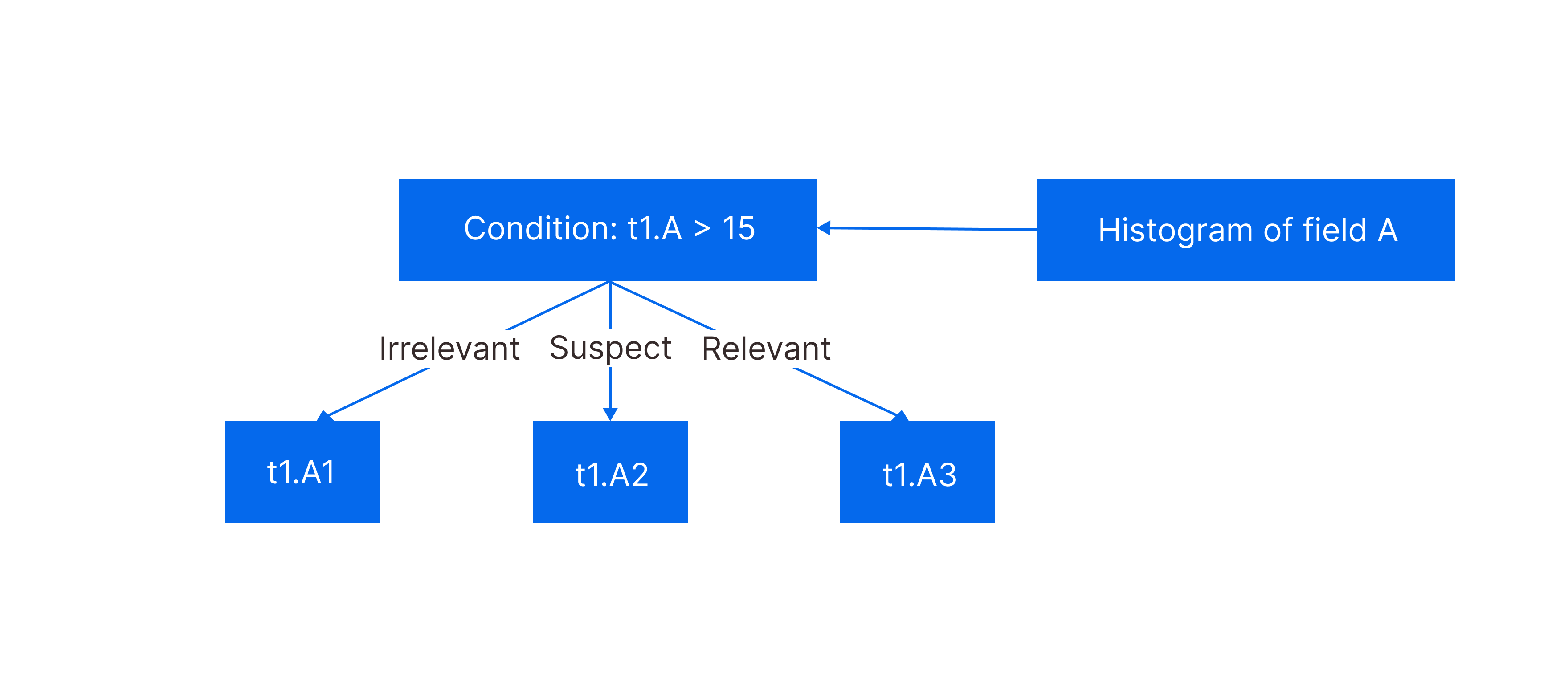
67.8 KB
{kind=link}
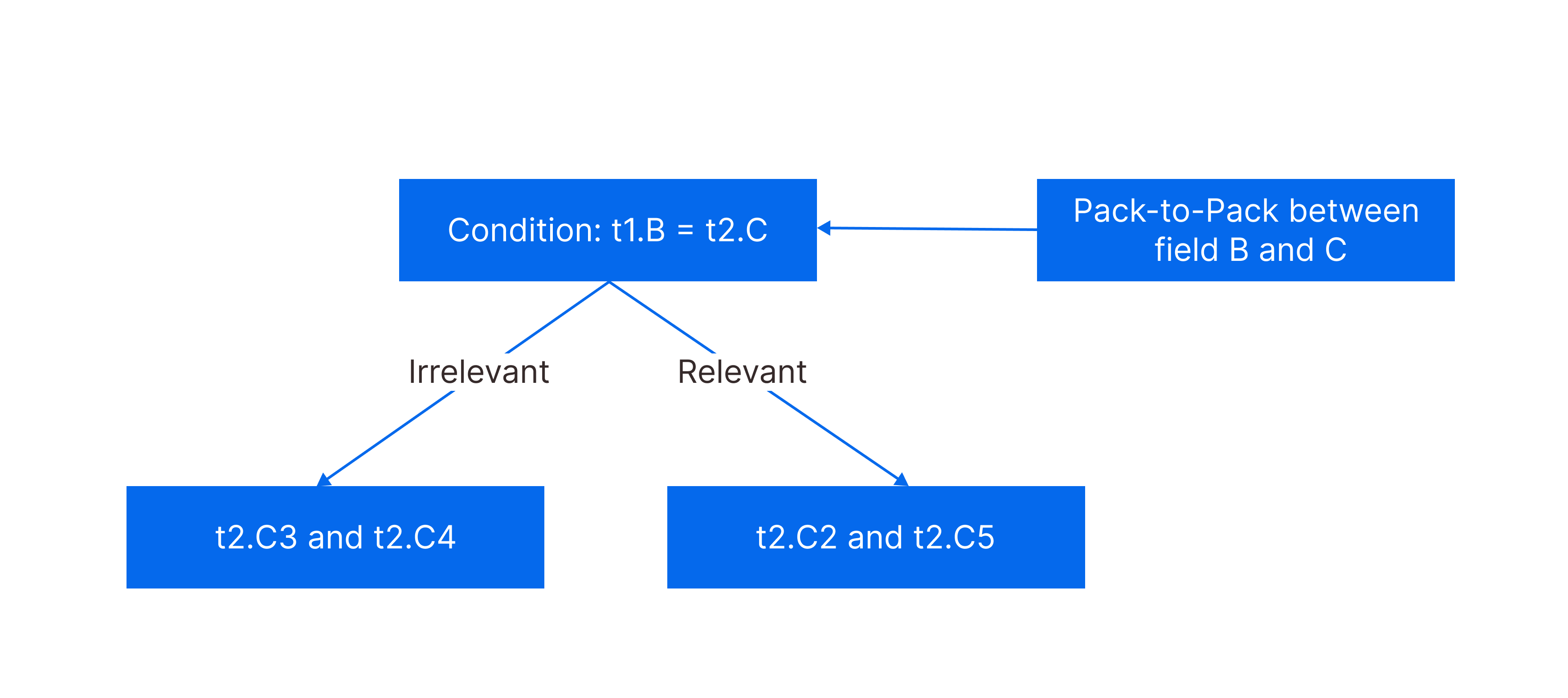
85.4 KB
{kind=link}
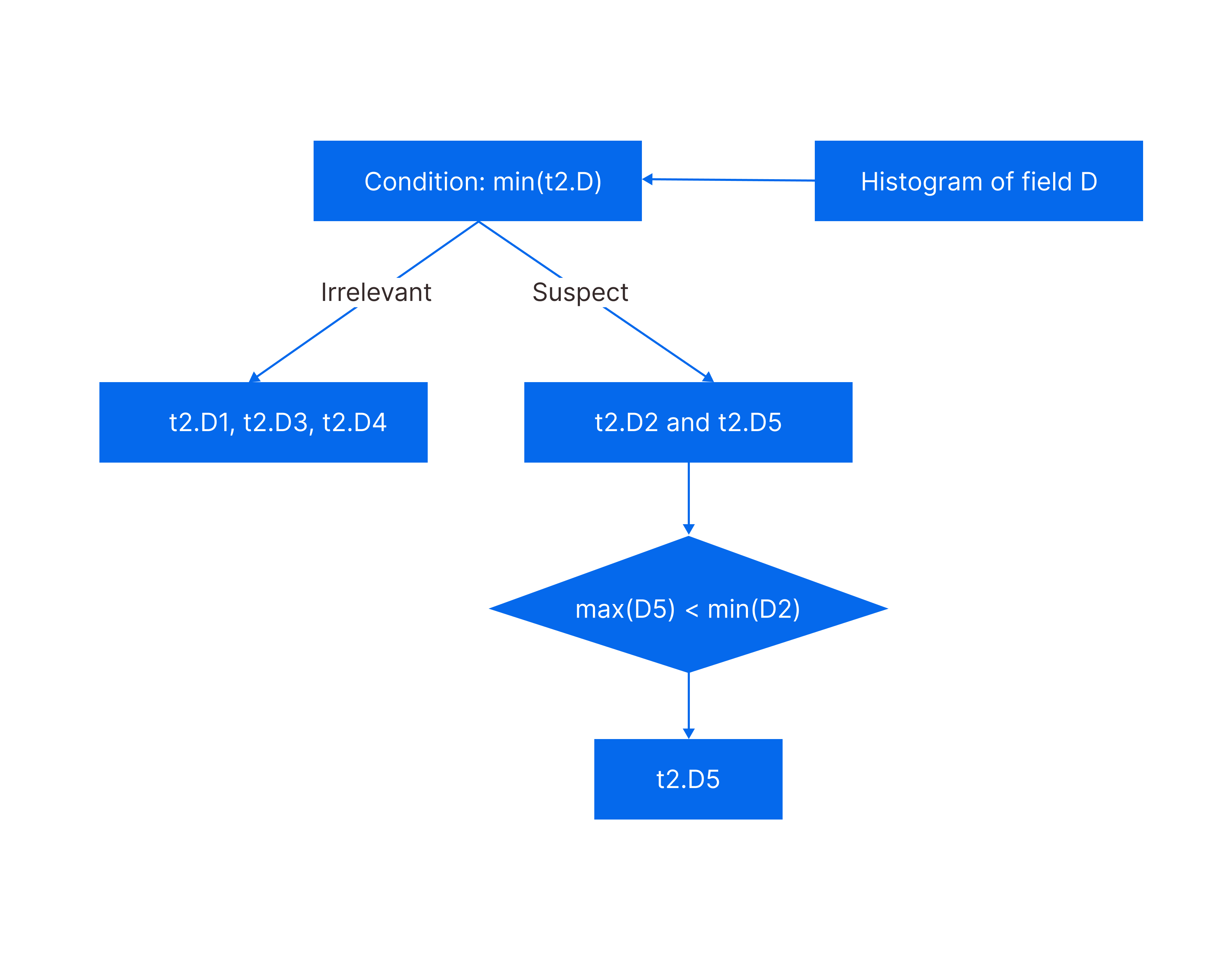
117.9 KB
{kind=link}
{kind=link}
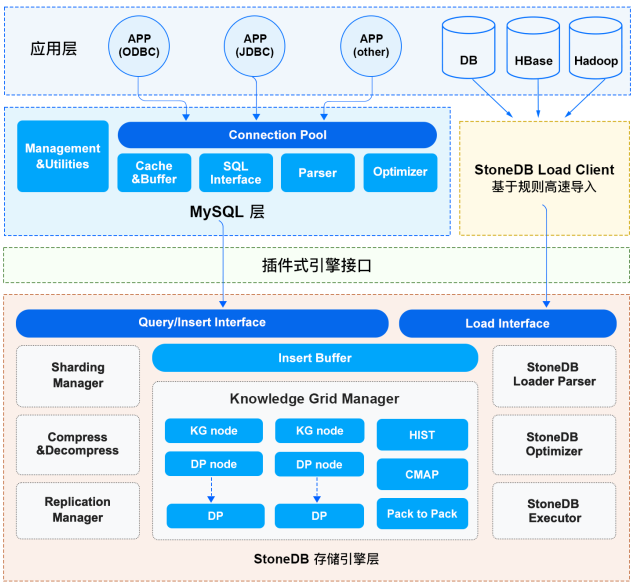
| W: | H:
| W: | H:
{kind=link}
10.7 KB
{kind=link}
10.7 KB
{kind=link}
18.2 KB
此差异已折叠。
{kind=link}
{kind=link}
| W: | H:
| W: | H: