docs(stonedb ): update some docs (#254)
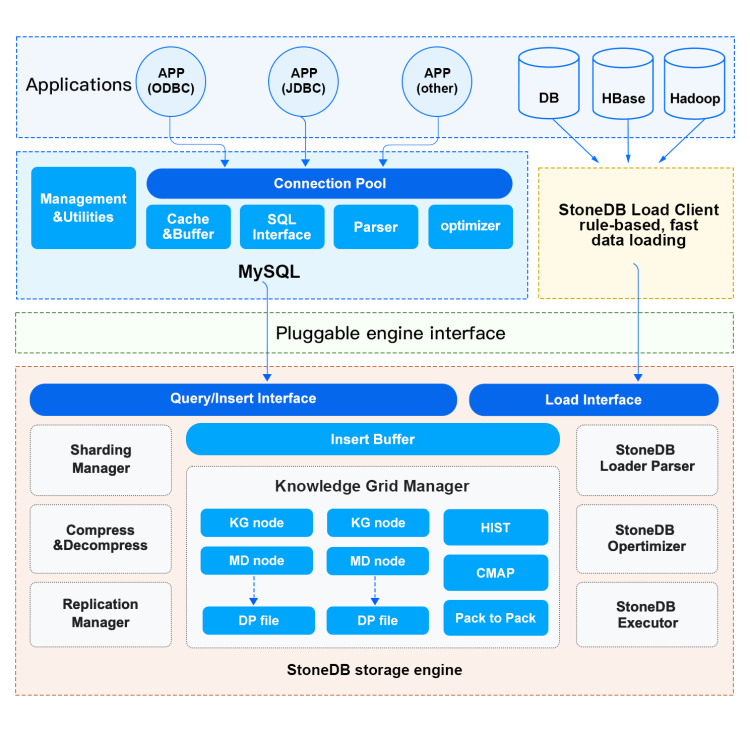
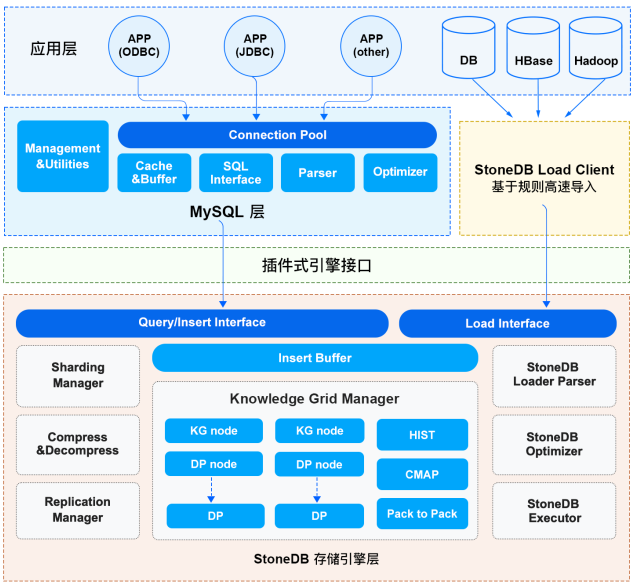
update doc of Architecture and Limits and Statements for Queries
#252
Co-authored-by: Nmergify[bot] <37929162+mergify[bot]@users.noreply.github.com>
Showing
{kind=link}
181.4 KB
{kind=link}
141.9 KB
update doc of Architecture and Limits and Statements for Queries
#252
Co-authored-by: Nmergify[bot] <37929162+mergify[bot]@users.noreply.github.com>
181.4 KB
141.9 KB