Merge branch 'd' into t46
Showing
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
documentation20/en/13.faq/docs.md
0 → 100644
此差异已折叠。
{kind=link}
96.9 KB
{kind=link}
文件已移动
{kind=link}
86.9 KB
{kind=link}
文件已移动
{kind=link}
36.6 KB
{kind=link}
114.5 KB
{kind=link}
91.1 KB
{kind=link}
文件已移动
{kind=link}
54.3 KB
{kind=link}
70.8 KB
{kind=link}
56.3 KB
{kind=link}
53.4 KB
{kind=link}
44.0 KB
{kind=link}
55.0 KB
{kind=link}
60.2 KB
{kind=link}
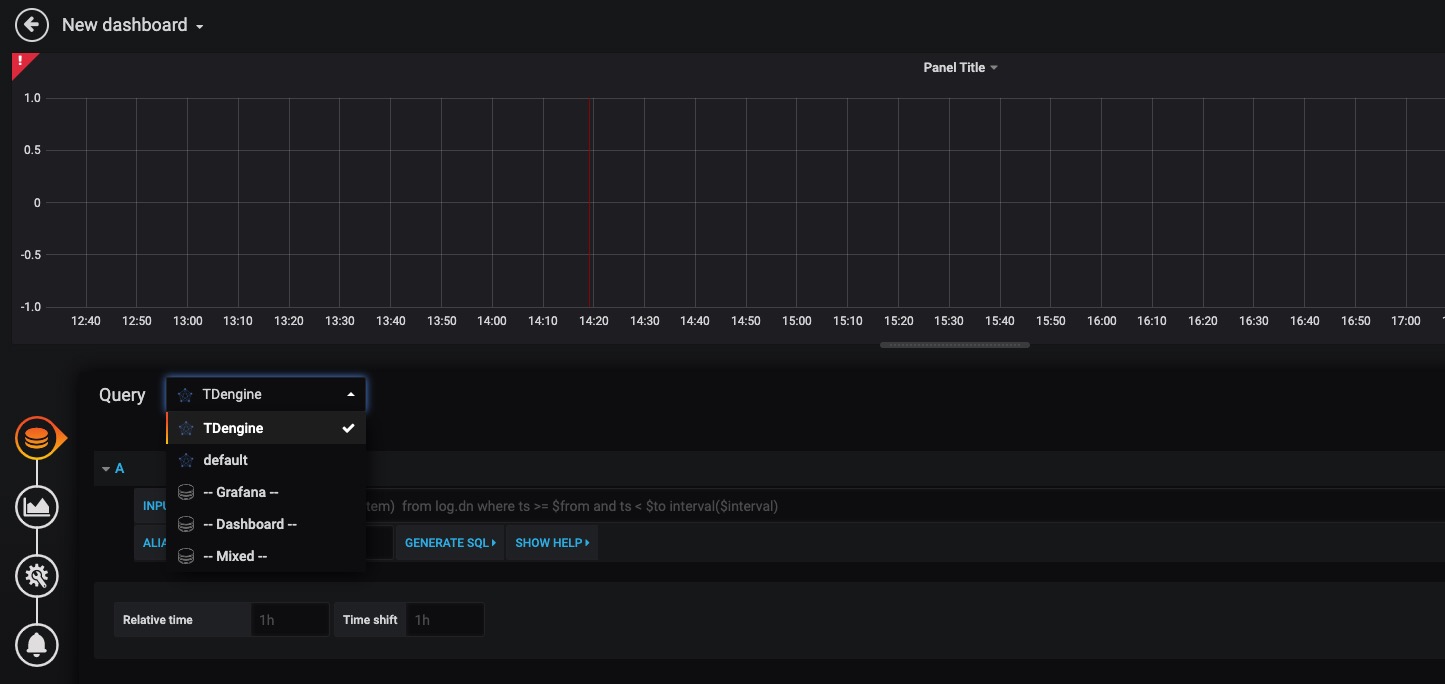
90.8 KB
{kind=link}
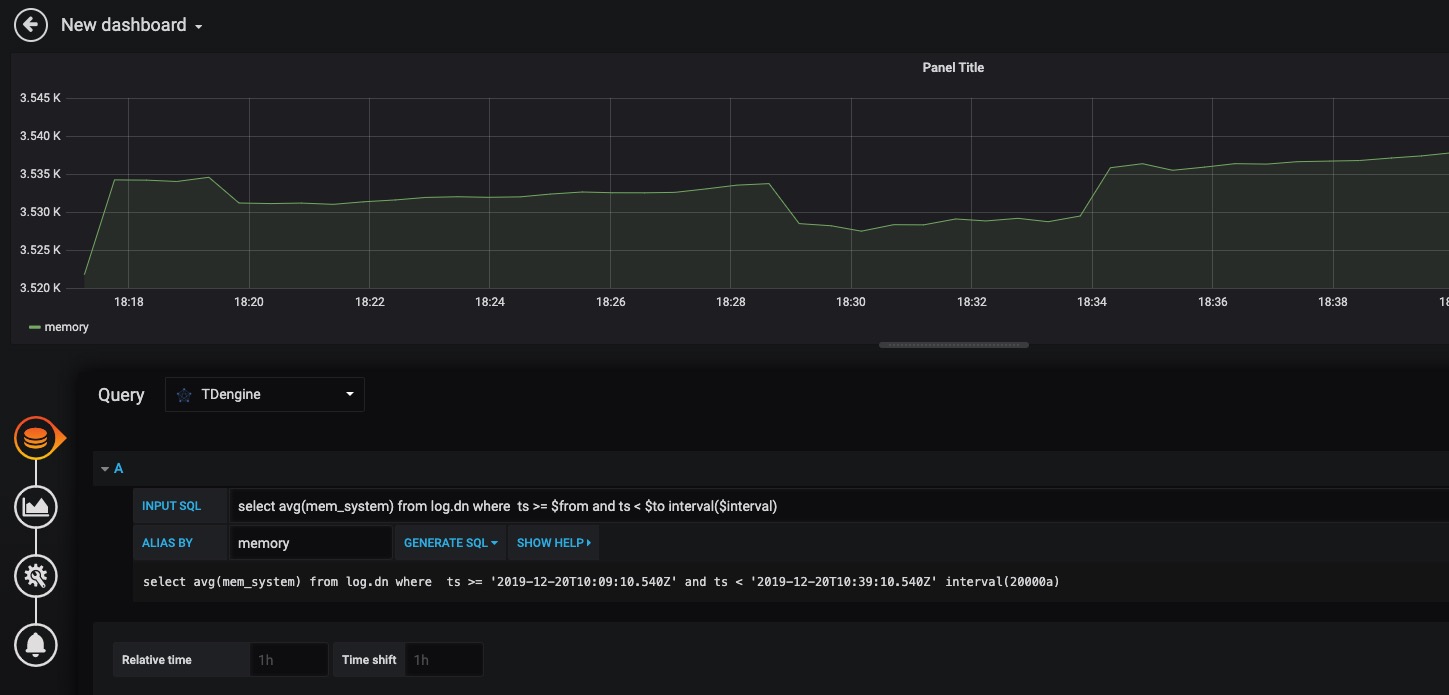
96.9 KB
{kind=link}
44.7 KB
{kind=link}
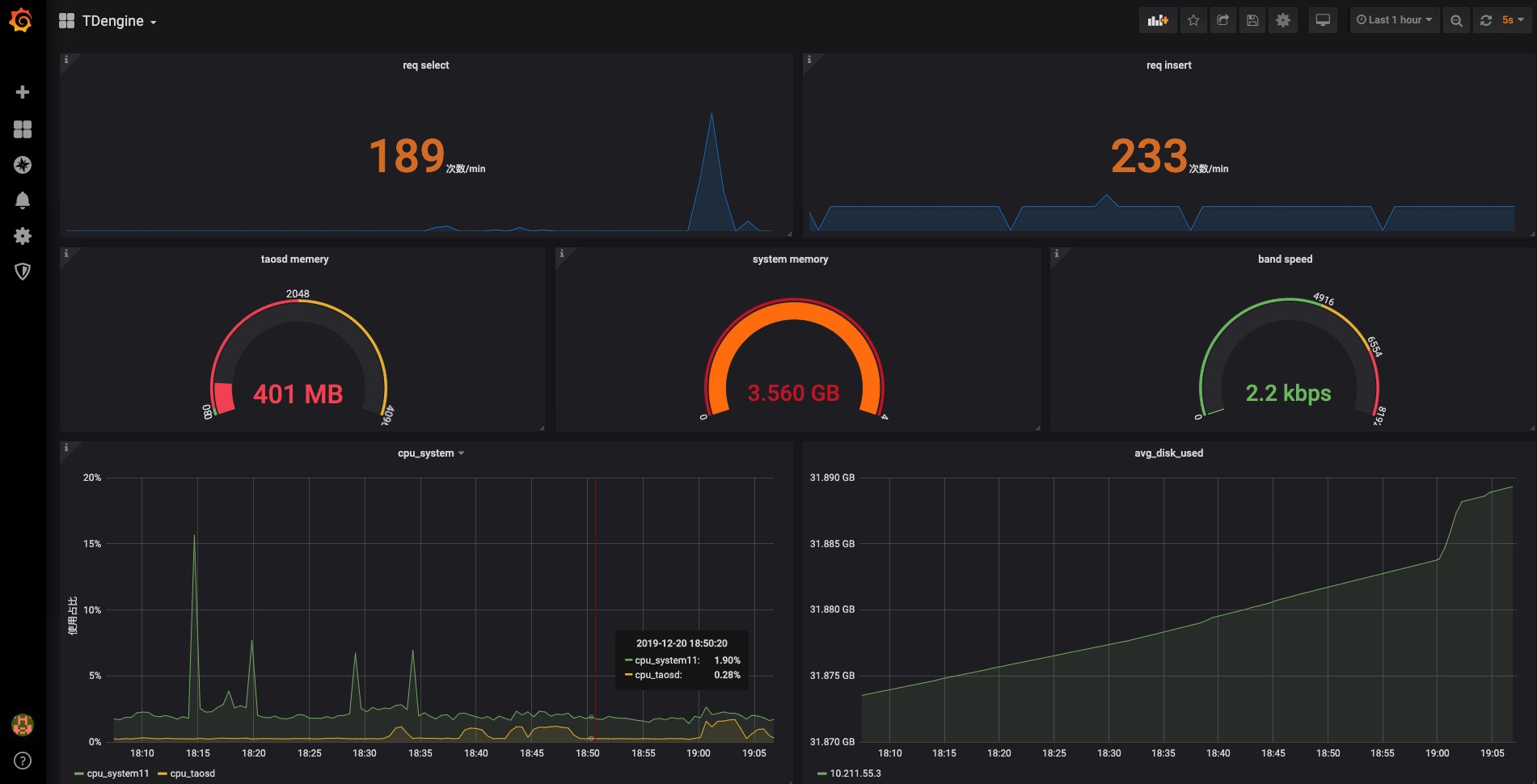
161.5 KB
{kind=link}

85.0 KB
{kind=link}
45.0 KB
{kind=link}
41.6 KB
{kind=link}
120.2 KB
{kind=link}
74.6 KB
{kind=link}
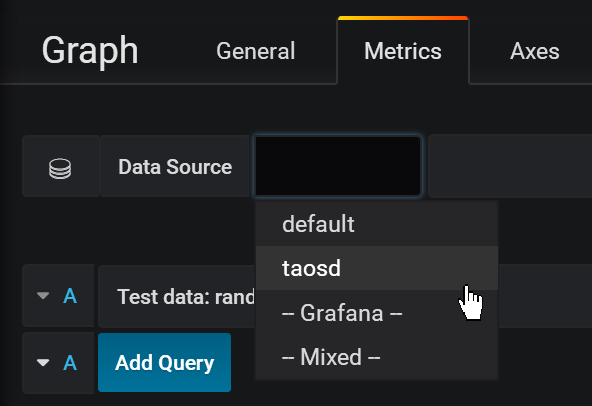
26.0 KB
{kind=link}
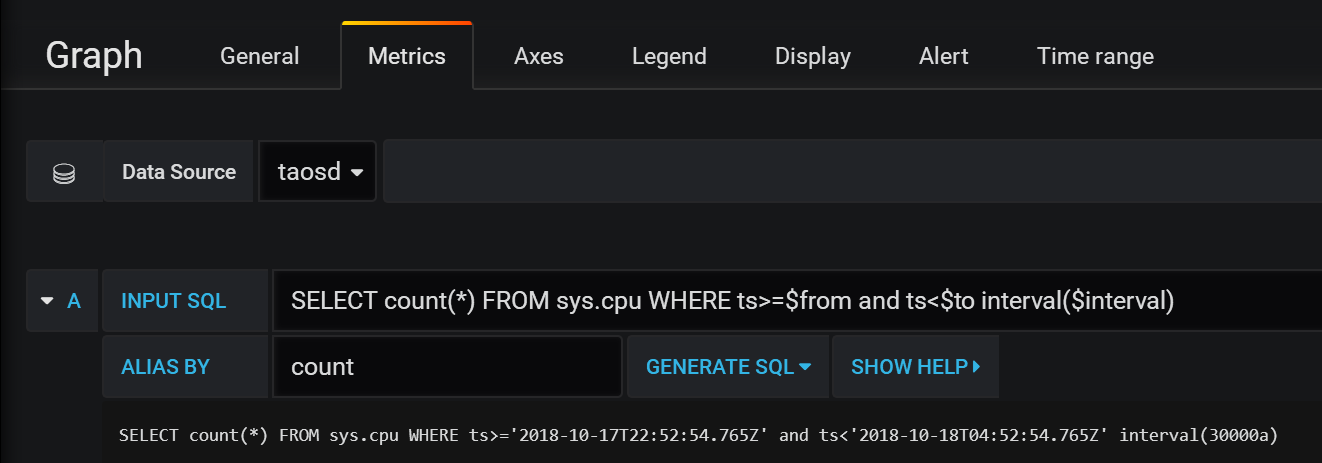
43.8 KB
{kind=link}
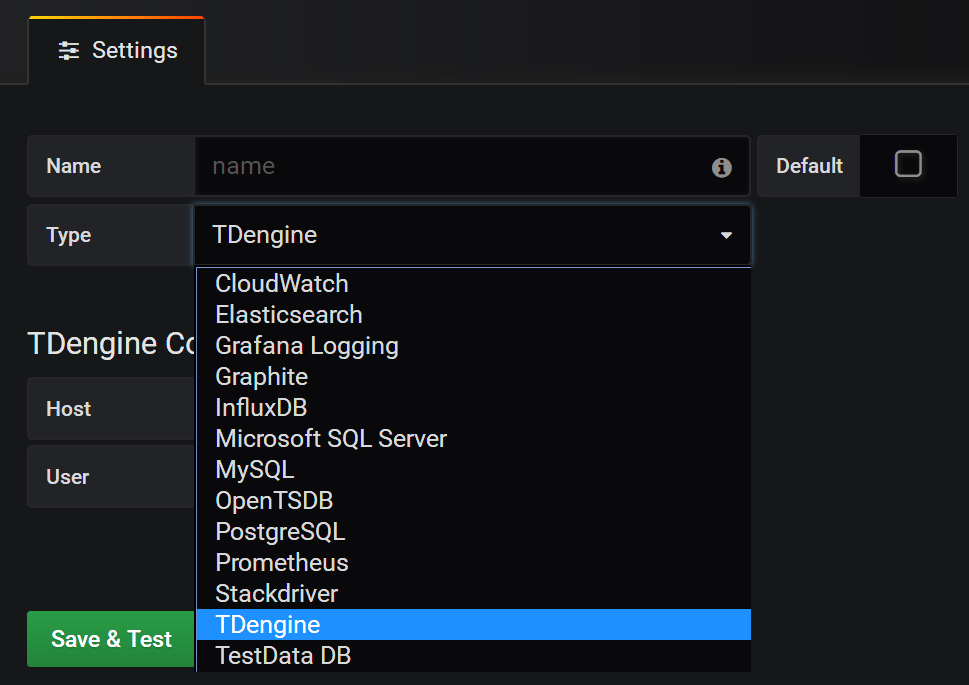
67.4 KB
{kind=link}
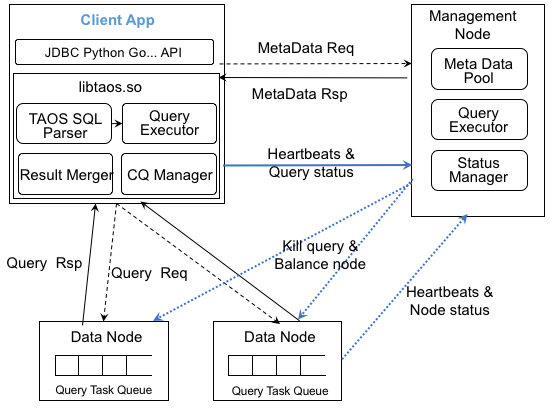
60.3 KB
{kind=link}
48.8 KB
{kind=link}
21.1 KB
{kind=link}
22.0 KB
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
tests/pytest/util/pathFinding.py
0 → 100644
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。