Merge branch 'dygraph' of https://github.com/PaddlePaddle/PaddleOCR into paddle2onnx
Showing
{kind=link}
{kind=link}

| W: | H:

| W: | H:
test_tipc/docs/lite_auto_log.png
0 → 100644
{kind=link}
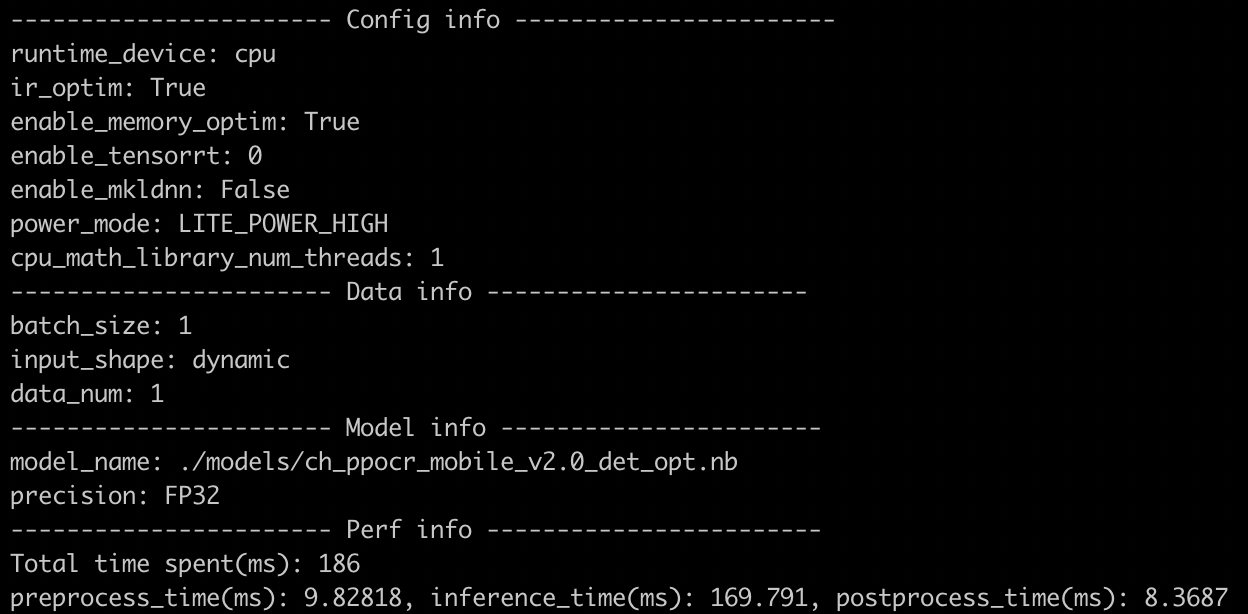
289.9 KB
test_tipc/docs/lite_log.png
0 → 100644
{kind=link}
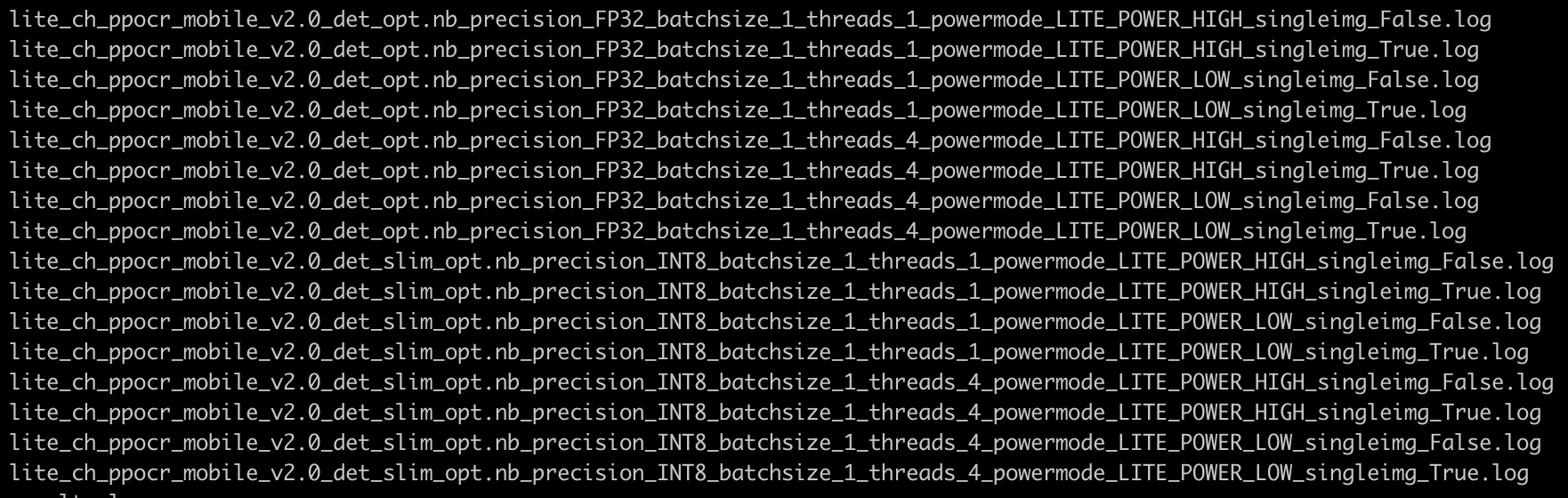
775.5 KB
test_tipc/docs/ssh_termux_ls.png
0 → 100644
{kind=link}

31.6 KB
test_tipc/docs/termux.jpg
0 → 100644
{kind=link}
74.1 KB
test_tipc/docs/test_lite.md
0 → 100644