You need to sign in or sign up before continuing.
Merge remote-tracking branch 'origin/dygraph' into dygraph
Showing
{kind=link}
{kind=link}
| W: | H:
| W: | H:
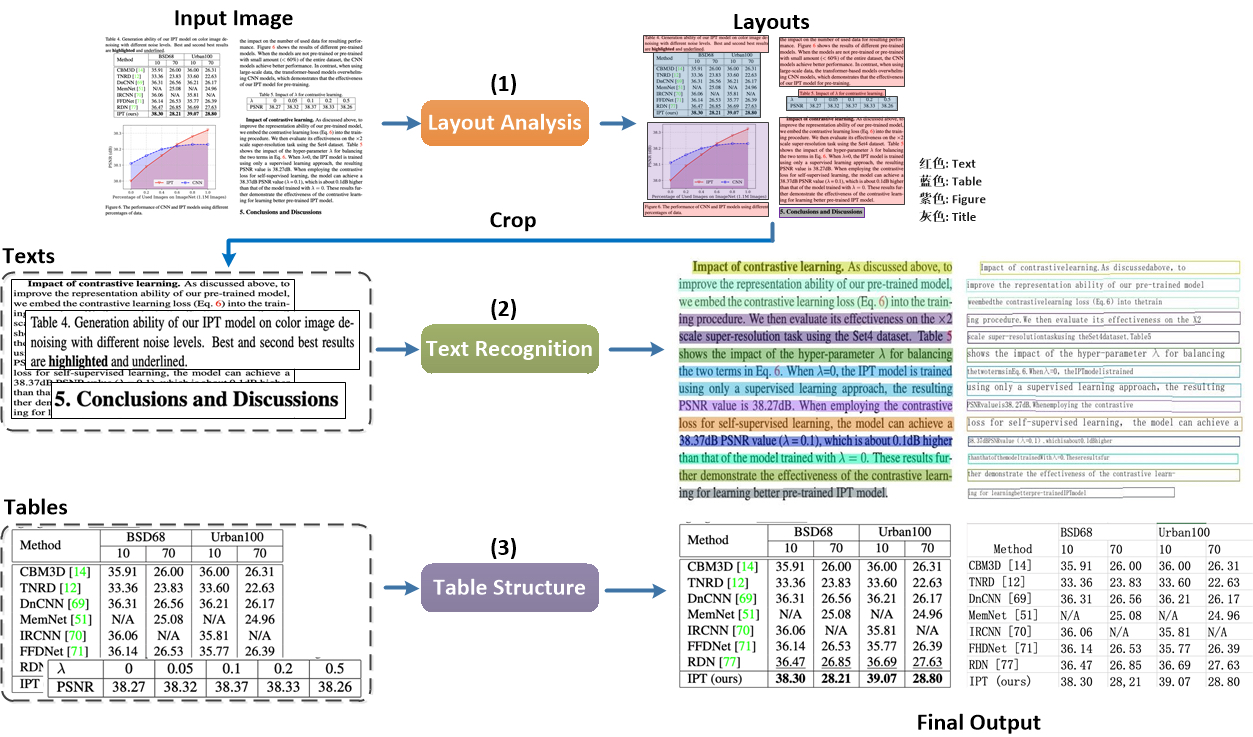
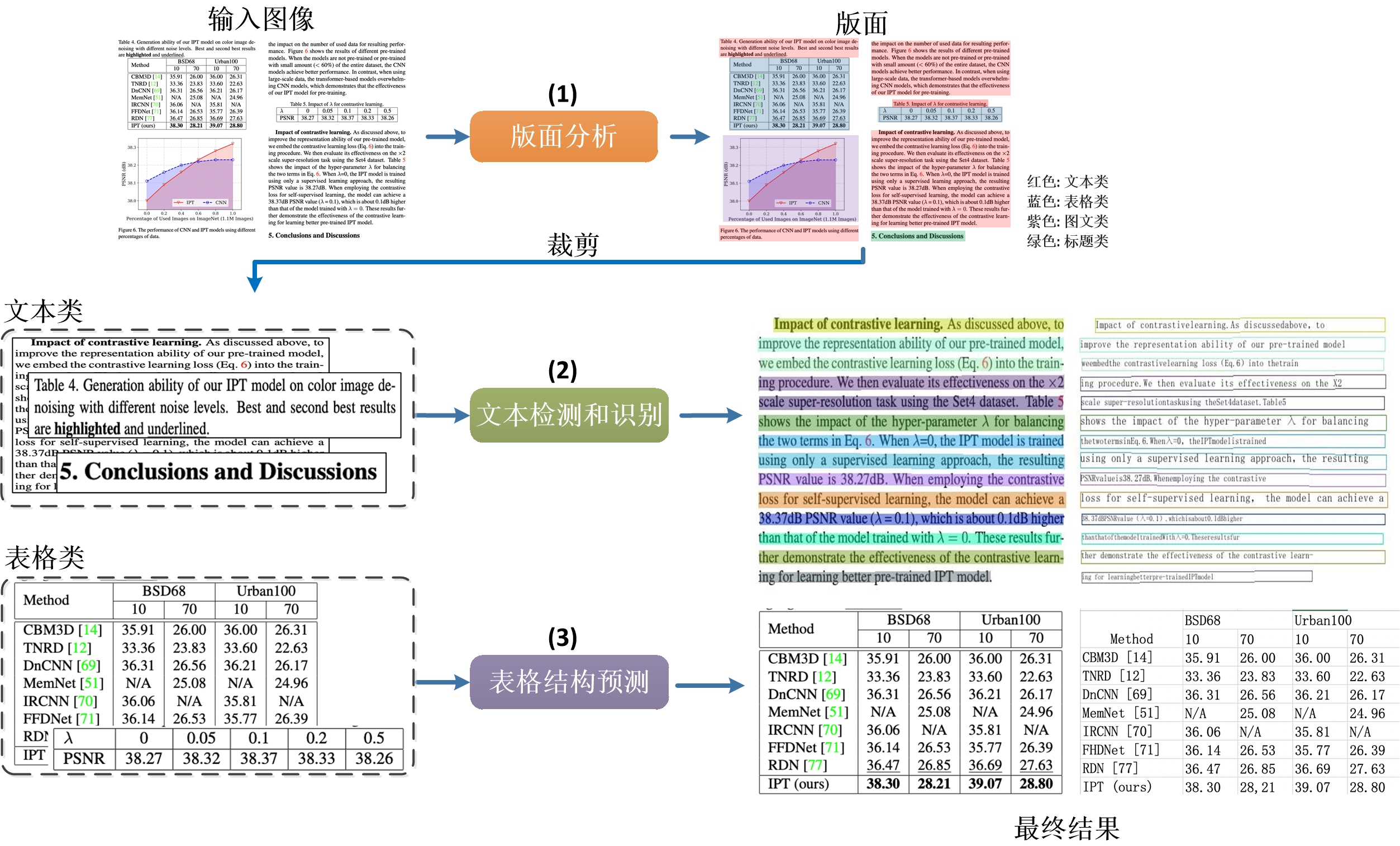
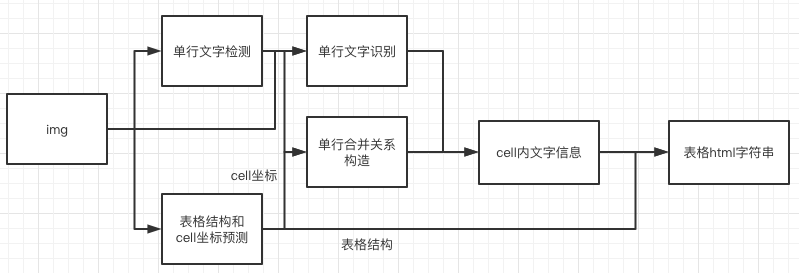
doc/table/pipeline_en.jpg
0 → 100644
{kind=link}
1.4 MB
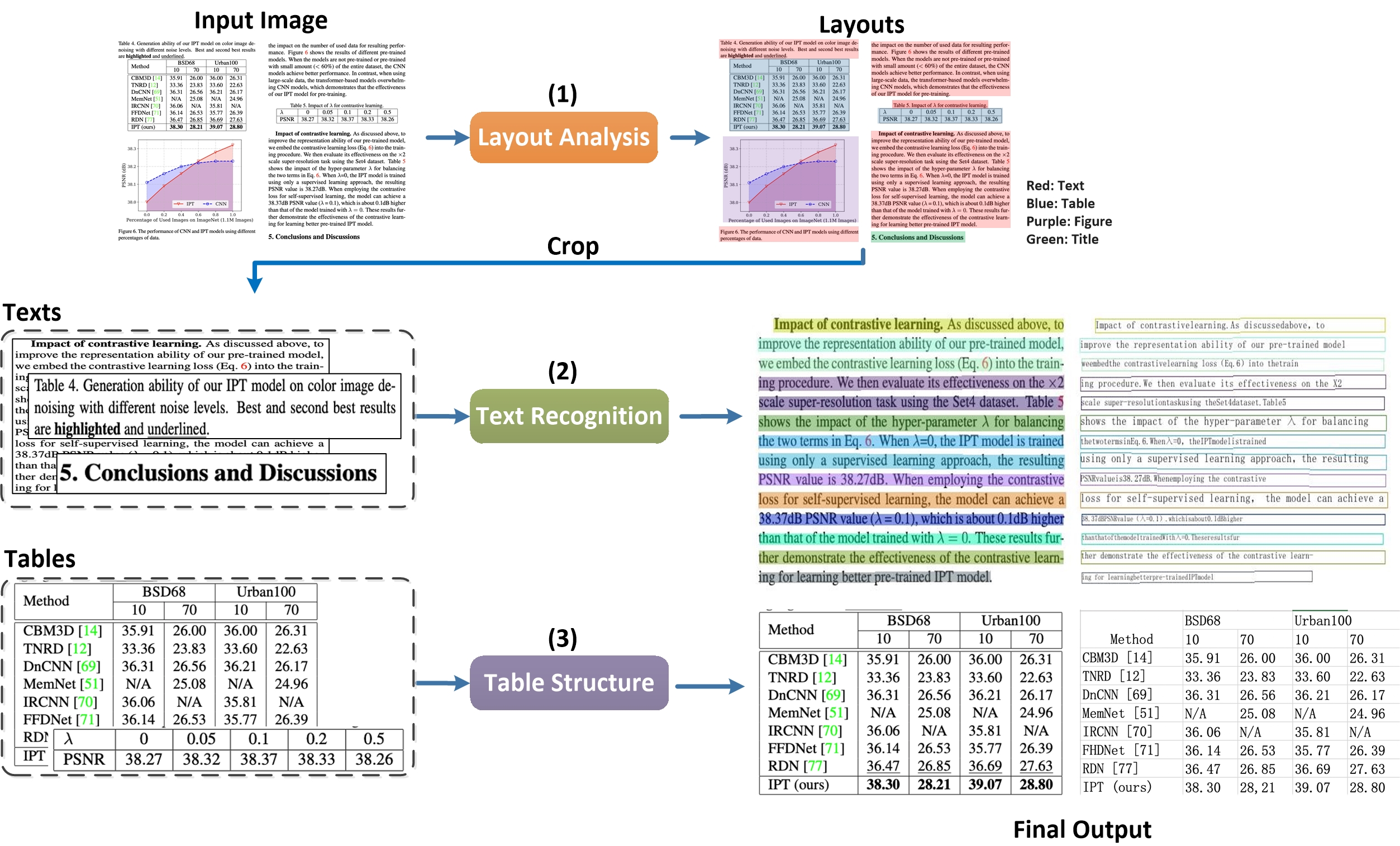
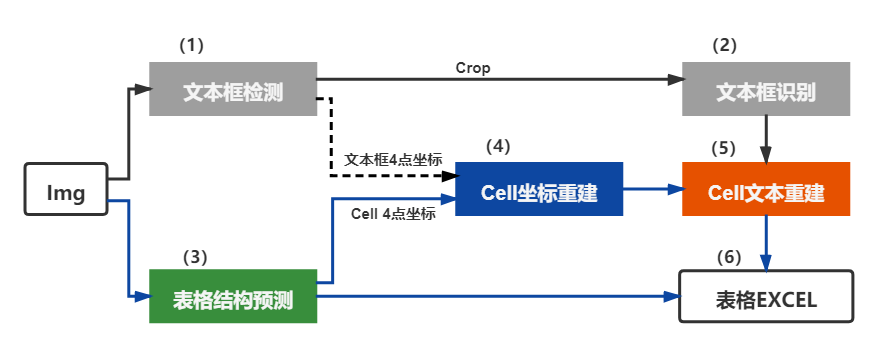
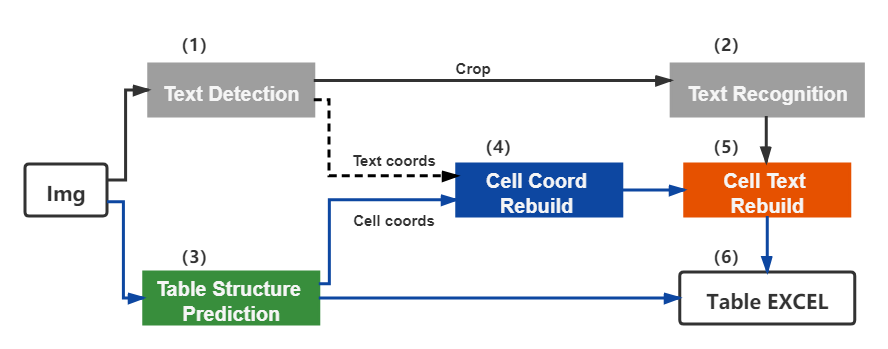
doc/table/tableocr_pipeline.jpg
0 → 100644
{kind=link}
24.5 KB
{kind=link}
26.1 KB
{kind=link}
19.4 KB