Merge branch 'dygraph' into android_demo
Showing
configs/e2e/e2e_r50_vd_pg.yml
0 → 100644
deploy/pdserving/README.md
0 → 100644
deploy/pdserving/README_CN.md
0 → 100644
deploy/pdserving/__init__.py
0 → 100644
deploy/pdserving/config.yml
0 → 100644
{kind=link}
文件已移动
{kind=link}
deploy/pdserving/imgs/results.png
0 → 100644
{kind=link}

119.4 KB
{kind=link}
194.6 KB
deploy/pdserving/ocr_reader.py
0 → 100644
deploy/pdserving/web_service.py
0 → 100644
deploy/slim/prune/README.md
0 → 100644
deploy/slim/prune/README_en.md
0 → 100644
doc/doc_ch/pgnet.md
0 → 100644
{kind=link}

60.6 KB
{kind=link}

662.8 KB
{kind=link}

466.8 KB
{kind=link}

133.6 KB
{kind=link}

337.2 KB
{kind=link}
{kind=link}

| W: | H:

| W: | H:
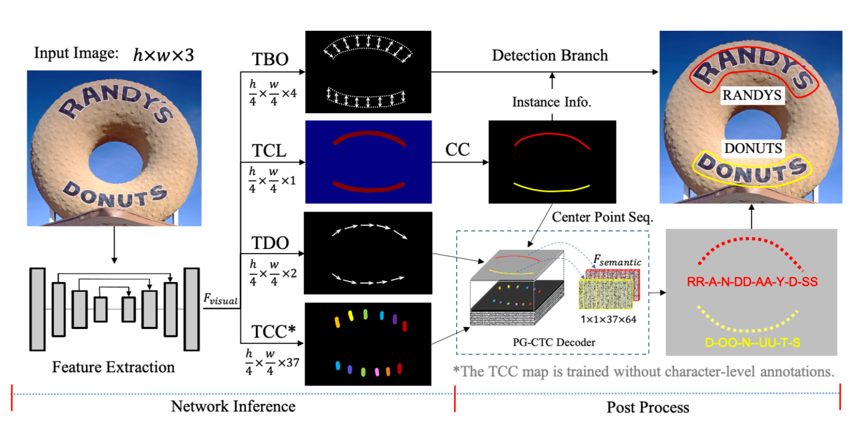
doc/pgnet_framework.png
0 → 100644
{kind=link}
241.7 KB
ppocr/data/imaug/pg_process.py
0 → 100644
此差异已折叠。
ppocr/data/pgnet_dataset.py
0 → 100644
ppocr/losses/e2e_pg_loss.py
0 → 100644
ppocr/metrics/e2e_metric.py
0 → 100644
此差异已折叠。
此差异已折叠。
此差异已折叠。
ppocr/modeling/necks/pg_fpn.py
0 → 100644
此差异已折叠。
此差异已折叠。
ppocr/utils/e2e_metric/Deteval.py
0 → 100755
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
ppocr/utils/e2e_utils/visual.py
0 → 100644
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
tools/infer/predict_e2e.py
0 → 100755
此差异已折叠。
此差异已折叠。
tools/infer_e2e.py
0 → 100755
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。