Support finetune by custom dataset (#3195)
* Support finetune by custom dataset * add finetune args * add load finetune * reconstruct load * add transfer learning doc * add fruit demo * add quick start * add data preprocessing FAQ
Showing
dataset/fruit/download.sh
0 → 100644
demo/orange_71.jpg
0 → 100644
{kind=link}

225.2 KB
demo/orange_71_detection.jpg
0 → 100644
{kind=link}

223.4 KB
demo/tensorboard_fruit.jpg
0 → 100644
{kind=link}
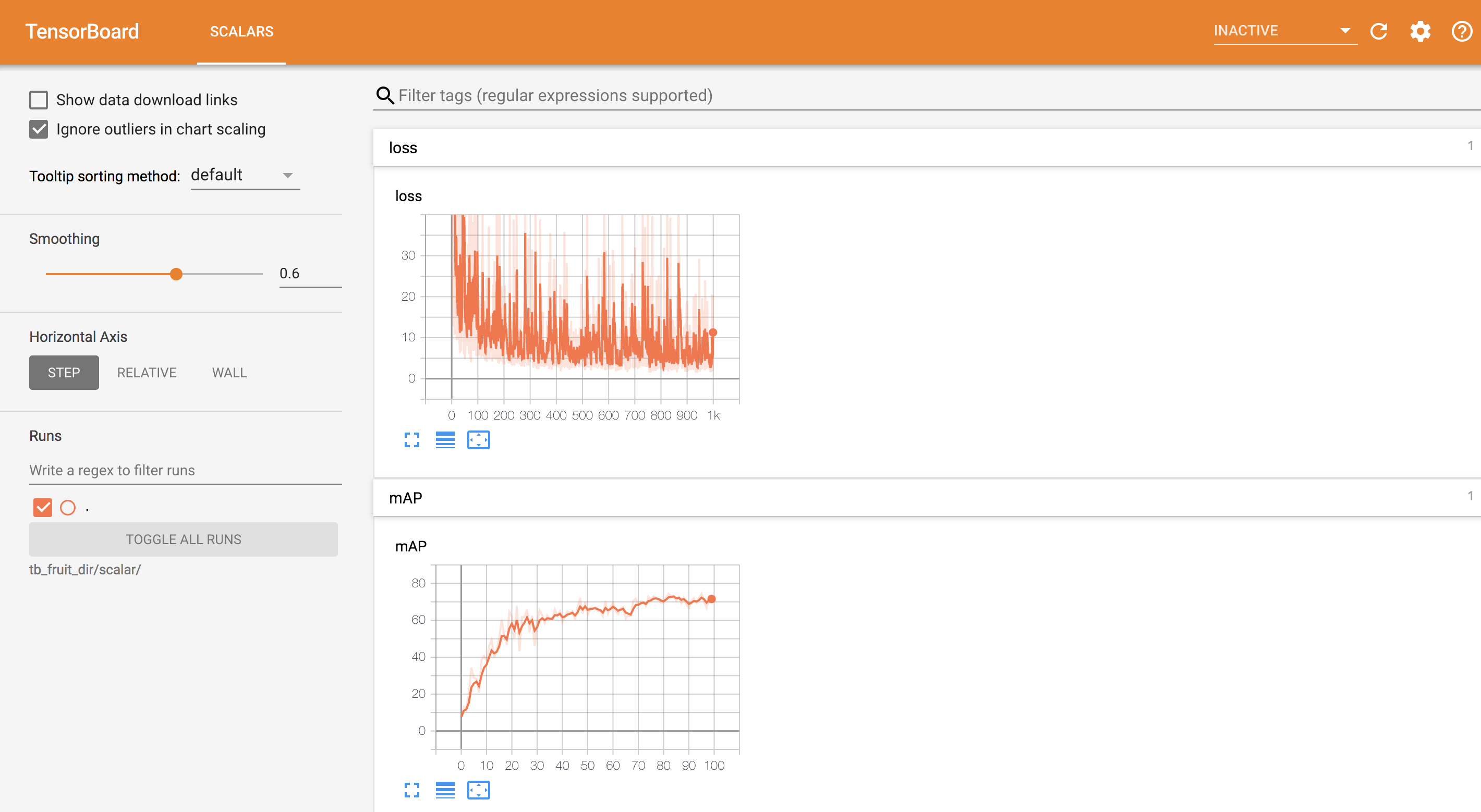
255.8 KB
docs/QUICK_STARTED.md
0 → 100644
docs/QUICK_STARTED_cn.md
0 → 100644
docs/TRANSFER_LEARNING.md
0 → 100644
docs/TRANSFER_LEARNING_cn.md
0 → 100644