Skip to content
体验新版
项目
组织
正在加载...
登录
切换导航
打开侧边栏
s920243400
PaddleDetection
提交
965a55ce
P
PaddleDetection
项目概览
s920243400
/
PaddleDetection
与 Fork 源项目一致
Fork自
PaddlePaddle / PaddleDetection
通知
2
Star
0
Fork
0
代码
文件
提交
分支
Tags
贡献者
分支图
Diff
Issue
0
列表
看板
标记
里程碑
合并请求
0
Wiki
0
Wiki
分析
仓库
DevOps
项目成员
Pages
P
PaddleDetection
项目概览
项目概览
详情
发布
仓库
仓库
文件
提交
分支
标签
贡献者
分支图
比较
Issue
0
Issue
0
列表
看板
标记
里程碑
合并请求
0
合并请求
0
Pages
分析
分析
仓库分析
DevOps
Wiki
0
Wiki
成员
成员
收起侧边栏
关闭侧边栏
动态
分支图
创建新Issue
提交
Issue看板
未验证
提交
965a55ce
编写于
3月 20, 2021
作者:
C
cnn
提交者:
GitHub
3月 20, 2021
浏览文件
操作
浏览文件
下载
电子邮件补丁
差异文件
[deploy] support dynamic_shape and add tensorrt tutorial (#2367) (#2392)
* TensorRT support dynamic shape
上级
98f9d462
变更
10
隐藏空白更改
内联
并排
Showing
10 changed file
with
534 addition
and
45 deletion
+534
-45
dygraph/deploy/cpp/include/object_detector.h
dygraph/deploy/cpp/include/object_detector.h
+12
-3
dygraph/deploy/cpp/include/preprocess_op.h
dygraph/deploy/cpp/include/preprocess_op.h
+4
-4
dygraph/deploy/cpp/scripts/build.sh
dygraph/deploy/cpp/scripts/build.sh
+3
-3
dygraph/deploy/cpp/src/main.cc
dygraph/deploy/cpp/src/main.cc
+12
-5
dygraph/deploy/cpp/src/object_detector.cc
dygraph/deploy/cpp/src/object_detector.cc
+39
-13
dygraph/deploy/cpp/src/preprocess_op.cc
dygraph/deploy/cpp/src/preprocess_op.cc
+7
-3
dygraph/deploy/python/infer.py
dygraph/deploy/python/infer.py
+81
-14
dygraph/deploy/python/trt_int8_calib.py
dygraph/deploy/python/trt_int8_calib.py
+300
-0
dygraph/deploy/tensorrt/README.md
dygraph/deploy/tensorrt/README.md
+76
-0
dygraph/deploy/tensorrt/imgs/input_shape.png
dygraph/deploy/tensorrt/imgs/input_shape.png
+0
-0
未找到文件。
dygraph/deploy/cpp/include/object_detector.h
浏览文件 @
965a55ce
...
...
@@ -59,12 +59,17 @@ class ObjectDetector {
explicit
ObjectDetector
(
const
std
::
string
&
model_dir
,
bool
use_gpu
=
false
,
const
std
::
string
&
run_mode
=
"fluid"
,
const
int
gpu_id
=
0
)
{
const
int
gpu_id
=
0
,
bool
use_dynamic_shape
=
false
,
const
int
trt_min_shape
=
1
,
const
int
trt_max_shape
=
1280
,
const
int
trt_opt_shape
=
640
)
{
config_
.
load_config
(
model_dir
);
threshold_
=
config_
.
draw_threshold_
;
image_shape_
=
config_
.
image_shape_
;
preprocessor_
.
Init
(
config_
.
preprocess_info_
,
image_shape_
);
LoadModel
(
model_dir
,
use_gpu
,
config_
.
min_subgraph_size_
,
1
,
run_mode
,
gpu_id
);
LoadModel
(
model_dir
,
use_gpu
,
config_
.
min_subgraph_size_
,
1
,
run_mode
,
gpu_id
,
use_dynamic_shape
,
trt_min_shape
,
trt_max_shape
,
trt_opt_shape
);
}
// Load Paddle inference model
...
...
@@ -74,7 +79,11 @@ class ObjectDetector {
const
int
min_subgraph_size
,
const
int
batch_size
=
1
,
const
std
::
string
&
run_mode
=
"fluid"
,
const
int
gpu_id
=
0
);
const
int
gpu_id
=
0
,
bool
use_dynamic_shape
=
false
,
const
int
trt_min_shape
=
1
,
const
int
trt_max_shape
=
1280
,
const
int
trt_opt_shape
=
640
);
// Run predictor
void
Predict
(
const
cv
::
Mat
&
im
,
...
...
dygraph/deploy/cpp/include/preprocess_op.h
浏览文件 @
965a55ce
...
...
@@ -37,8 +37,8 @@ class ImageBlob {
std
::
vector
<
float
>
im_shape_
;
// Buffer for image data after preprocessing
std
::
vector
<
float
>
im_data_
;
// in
put image width, height
std
::
vector
<
int
>
in
pu
t_shape_
;
// in
net data shape(after pad)
std
::
vector
<
int
>
in
_ne
t_shape_
;
// Evaluation image width and height
//std::vector<float> eval_im_size_f_;
// Scale factor for image size to origin image size
...
...
@@ -90,7 +90,7 @@ class Resize : public PreprocessOp {
keep_ratio_
=
item
[
"keep_ratio"
].
as
<
bool
>
();
target_size_
=
item
[
"target_size"
].
as
<
std
::
vector
<
int
>>
();
if
(
item
[
"keep_ratio"
])
{
in
pu
t_shape_
=
image_shape
;
in
_ne
t_shape_
=
image_shape
;
}
}
...
...
@@ -103,7 +103,7 @@ class Resize : public PreprocessOp {
int
interp_
;
bool
keep_ratio_
;
std
::
vector
<
int
>
target_size_
;
std
::
vector
<
int
>
in
pu
t_shape_
;
std
::
vector
<
int
>
in
_ne
t_shape_
;
};
// Models with FPN need input shape % stride == 0
...
...
dygraph/deploy/cpp/scripts/build.sh
浏览文件 @
965a55ce
...
...
@@ -35,11 +35,11 @@ then
echo
"set OPENCV_DIR for x86_64"
# linux系统通过以下命令下载预编译的opencv
mkdir
-p
$(
pwd
)
/deps
&&
cd
$(
pwd
)
/deps
wget
-c
https://
bj.bcebos.com/paddleseg/deploy/opencv3.4.6gcc4.8ffmpeg.tar.gz2
tar
xvfj opencv3.4.6gcc4.8ffmpeg.tar.gz2
&&
cd
..
wget
-c
https://
paddledet.bj.bcebos.com/data/opencv3.4.6gcc8.2ffmpeg.zip
unzip opencv3.4.6gcc8.2ffmpeg.zip
&&
cd
..
# set OPENCV_DIR
OPENCV_DIR
=
$(
pwd
)
/deps/opencv3.4.6gcc
4.8ffmpeg/
OPENCV_DIR
=
$(
pwd
)
/deps/opencv3.4.6gcc
8.2ffmpeg
elif
[
"
$MACHINE_TYPE
"
=
"aarch64"
]
then
...
...
dygraph/deploy/cpp/src/main.cc
浏览文件 @
965a55ce
...
...
@@ -42,6 +42,10 @@ DEFINE_int32(camera_id, -1, "Device id of camera to predict");
DEFINE_bool
(
run_benchmark
,
false
,
"Whether to predict a image_file repeatedly for benchmark"
);
DEFINE_double
(
threshold
,
0.5
,
"Threshold of score."
);
DEFINE_string
(
output_dir
,
"output"
,
"Directory of output visualization files."
);
DEFINE_bool
(
use_dynamic_shape
,
false
,
"Trt use dynamic shape or not"
);
DEFINE_int32
(
trt_min_shape
,
1
,
"Min shape of TRT DynamicShapeI"
);
DEFINE_int32
(
trt_max_shape
,
1280
,
"Max shape of TRT DynamicShapeI"
);
DEFINE_int32
(
trt_opt_shape
,
640
,
"Opt shape of TRT DynamicShapeI"
);
static
std
::
string
DirName
(
const
std
::
string
&
filepath
)
{
auto
pos
=
filepath
.
rfind
(
OS_PATH_SEP
);
...
...
@@ -198,14 +202,17 @@ int main(int argc, char** argv) {
return
-
1
;
}
if
(
!
(
FLAGS_run_mode
==
"fluid"
||
FLAGS_run_mode
==
"trt_fp32"
||
FLAGS_run_mode
==
"trt_fp16"
))
{
std
::
cout
<<
"run_mode should be 'fluid', 'trt_fp32'
or 'trt_fp16
'."
;
||
FLAGS_run_mode
==
"trt_fp16"
||
FLAGS_run_mode
==
"trt_int8"
))
{
std
::
cout
<<
"run_mode should be 'fluid', 'trt_fp32'
, 'trt_fp16' or 'trt_int8
'."
;
return
-
1
;
}
// Load model and create a object detector
PaddleDetection
::
ObjectDetector
det
(
FLAGS_model_dir
,
FLAGS_use_gpu
,
FLAGS_run_mode
,
FLAGS_gpu_id
);
const
std
::
vector
<
int
>
trt_min_shape
=
{
1
,
FLAGS_trt_min_shape
,
FLAGS_trt_min_shape
};
const
std
::
vector
<
int
>
trt_max_shape
=
{
1
,
FLAGS_trt_max_shape
,
FLAGS_trt_max_shape
};
const
std
::
vector
<
int
>
trt_opt_shape
=
{
1
,
FLAGS_trt_opt_shape
,
FLAGS_trt_opt_shape
};
PaddleDetection
::
ObjectDetector
det
(
FLAGS_model_dir
,
FLAGS_use_gpu
,
FLAGS_run_mode
,
FLAGS_gpu_id
,
FLAGS_use_dynamic_shape
,
FLAGS_trt_min_shape
,
FLAGS_trt_max_shape
,
FLAGS_trt_opt_shape
);
// Do inference on input video or image
if
(
!
FLAGS_video_path
.
empty
()
||
FLAGS_use_camera
)
{
PredictVideo
(
FLAGS_video_path
,
&
det
);
...
...
dygraph/deploy/cpp/src/object_detector.cc
浏览文件 @
965a55ce
...
...
@@ -27,7 +27,11 @@ void ObjectDetector::LoadModel(const std::string& model_dir,
const
int
min_subgraph_size
,
const
int
batch_size
,
const
std
::
string
&
run_mode
,
const
int
gpu_id
)
{
const
int
gpu_id
,
bool
use_dynamic_shape
,
const
int
trt_min_shape
,
const
int
trt_max_shape
,
const
int
trt_opt_shape
)
{
paddle_infer
::
Config
config
;
std
::
string
prog_file
=
model_dir
+
OS_PATH_SEP
+
"model.pdmodel"
;
std
::
string
params_file
=
model_dir
+
OS_PATH_SEP
+
"model.pdiparams"
;
...
...
@@ -35,26 +39,48 @@ void ObjectDetector::LoadModel(const std::string& model_dir,
if
(
use_gpu
)
{
config
.
EnableUseGpu
(
200
,
gpu_id
);
config
.
SwitchIrOptim
(
true
);
// use tensorrt
bool
use_calib_mode
=
false
;
if
(
run_mode
!=
"fluid"
)
{
auto
precision
=
paddle_infer
::
Config
::
Precision
::
kFloat32
;
if
(
run_mode
==
"trt_fp16"
)
{
if
(
run_mode
==
"trt_fp32"
)
{
precision
=
paddle_infer
::
Config
::
Precision
::
kFloat32
;
}
else
if
(
run_mode
==
"trt_fp16"
)
{
precision
=
paddle_infer
::
Config
::
Precision
::
kHalf
;
}
else
if
(
run_mode
==
"trt_int8"
)
{
printf
(
"TensorRT int8 mode is not supported now, "
"please use 'trt_fp32' or 'trt_fp16' instead"
);
}
else
if
(
run_mode
==
"trt_int8"
)
{
precision
=
paddle_infer
::
Config
::
Precision
::
kInt8
;
use_calib_mode
=
true
;
}
else
{
if
(
run_mode
!=
"trt_fp32"
)
{
printf
(
"run_mode should be 'fluid', 'trt_fp32' or 'trt_fp16'"
);
}
printf
(
"run_mode should be 'fluid', 'trt_fp32', 'trt_fp16' or 'trt_int8'"
);
}
// set tensorrt
config
.
EnableTensorRtEngine
(
1
<<
1
0
,
1
<<
3
0
,
batch_size
,
min_subgraph_size
,
precision
,
false
,
false
);
}
use_calib_mode
);
// set use dynamic shape
if
(
use_dynamic_shape
)
{
// set DynamicShsape for image tensor
const
std
::
vector
<
int
>
min_input_shape
=
{
1
,
trt_min_shape
,
trt_min_shape
};
const
std
::
vector
<
int
>
max_input_shape
=
{
1
,
trt_max_shape
,
trt_max_shape
};
const
std
::
vector
<
int
>
opt_input_shape
=
{
1
,
trt_opt_shape
,
trt_opt_shape
};
const
std
::
map
<
std
::
string
,
std
::
vector
<
int
>>
map_min_input_shape
=
{{
"image"
,
min_input_shape
}};
const
std
::
map
<
std
::
string
,
std
::
vector
<
int
>>
map_max_input_shape
=
{{
"image"
,
max_input_shape
}};
const
std
::
map
<
std
::
string
,
std
::
vector
<
int
>>
map_opt_input_shape
=
{{
"image"
,
opt_input_shape
}};
config
.
SetTRTDynamicShapeInfo
(
map_min_input_shape
,
map_max_input_shape
,
map_opt_input_shape
);
std
::
cout
<<
"TensorRT dynamic shape enabled"
<<
std
::
endl
;
}
}
}
else
{
config
.
DisableGpu
();
}
...
...
@@ -171,8 +197,8 @@ void ObjectDetector::Predict(const cv::Mat& im,
for
(
const
auto
&
tensor_name
:
input_names
)
{
auto
in_tensor
=
predictor_
->
GetInputHandle
(
tensor_name
);
if
(
tensor_name
==
"image"
)
{
int
rh
=
inputs_
.
in
pu
t_shape_
[
0
];
int
rw
=
inputs_
.
in
pu
t_shape_
[
1
];
int
rh
=
inputs_
.
in
_ne
t_shape_
[
0
];
int
rw
=
inputs_
.
in
_ne
t_shape_
[
1
];
in_tensor
->
Reshape
({
1
,
3
,
rh
,
rw
});
in_tensor
->
CopyFromCpu
(
inputs_
.
im_data_
.
data
());
}
else
if
(
tensor_name
==
"im_shape"
)
{
...
...
dygraph/deploy/cpp/src/preprocess_op.cc
浏览文件 @
965a55ce
...
...
@@ -25,7 +25,7 @@ void InitInfo::Run(cv::Mat* im, ImageBlob* data) {
static_cast
<
float
>
(
im
->
cols
)
};
data
->
scale_factor_
=
{
1.
,
1.
};
data
->
in
pu
t_shape_
=
{
data
->
in
_ne
t_shape_
=
{
static_cast
<
int
>
(
im
->
rows
),
static_cast
<
int
>
(
im
->
cols
)
};
...
...
@@ -62,7 +62,11 @@ void Permute::Run(cv::Mat* im, ImageBlob* data) {
void
Resize
::
Run
(
cv
::
Mat
*
im
,
ImageBlob
*
data
)
{
auto
resize_scale
=
GenerateScale
(
*
im
);
data
->
input_shape_
=
{
data
->
im_shape_
=
{
static_cast
<
int
>
(
im
->
cols
*
resize_scale
.
first
),
static_cast
<
int
>
(
im
->
rows
*
resize_scale
.
second
)
};
data
->
in_net_shape_
=
{
static_cast
<
int
>
(
im
->
cols
*
resize_scale
.
first
),
static_cast
<
int
>
(
im
->
rows
*
resize_scale
.
second
)
};
...
...
@@ -121,7 +125,7 @@ void PadStride::Run(cv::Mat* im, ImageBlob* data) {
nw
-
rw
,
cv
::
BORDER_CONSTANT
,
cv
::
Scalar
(
0
));
data
->
in
pu
t_shape_
=
{
data
->
in
_ne
t_shape_
=
{
static_cast
<
int
>
(
im
->
rows
),
static_cast
<
int
>
(
im
->
cols
),
};
...
...
dygraph/deploy/python/infer.py
浏览文件 @
965a55ce
...
...
@@ -46,6 +46,11 @@ class Detector(object):
model_dir (str): root path of model.pdiparams, model.pdmodel and infer_cfg.yml
use_gpu (bool): whether use gpu
run_mode (str): mode of running(fluid/trt_fp32/trt_fp16)
use_dynamic_shape (bool): use dynamic shape or not
trt_min_shape (int): min shape for dynamic shape in trt
trt_max_shape (int): max shape for dynamic shape in trt
trt_opt_shape (int): opt shape for dynamic shape in trt
run_mode (str): mode of running(fluid/trt_fp32/trt_fp16)
threshold (float): threshold to reserve the result for output.
"""
...
...
@@ -54,13 +59,21 @@ class Detector(object):
model_dir
,
use_gpu
=
False
,
run_mode
=
'fluid'
,
use_dynamic_shape
=
False
,
trt_min_shape
=
1
,
trt_max_shape
=
1280
,
trt_opt_shape
=
640
,
threshold
=
0.5
):
self
.
pred_config
=
pred_config
self
.
predictor
=
load_predictor
(
model_dir
,
run_mode
=
run_mode
,
min_subgraph_size
=
self
.
pred_config
.
min_subgraph_size
,
use_gpu
=
use_gpu
)
use_gpu
=
use_gpu
,
use_dynamic_shape
=
use_dynamic_shape
,
trt_min_shape
=
trt_min_shape
,
trt_max_shape
=
trt_max_shape
,
trt_opt_shape
=
trt_opt_shape
)
def
preprocess
(
self
,
im
):
preprocess_ops
=
[]
...
...
@@ -154,6 +167,10 @@ class DetectorSOLOv2(Detector):
model_dir (str): root path of model.pdiparams, model.pdmodel and infer_cfg.yml
use_gpu (bool): whether use gpu
run_mode (str): mode of running(fluid/trt_fp32/trt_fp16)
use_dynamic_shape (bool): use dynamic shape or not
trt_min_shape (int): min shape for dynamic shape in trt
trt_max_shape (int): max shape for dynamic shape in trt
trt_opt_shape (int): opt shape for dynamic shape in trt
threshold (float): threshold to reserve the result for output.
"""
...
...
@@ -162,13 +179,21 @@ class DetectorSOLOv2(Detector):
model_dir
,
use_gpu
=
False
,
run_mode
=
'fluid'
,
use_dynamic_shape
=
False
,
trt_min_shape
=
1
,
trt_max_shape
=
1280
,
trt_opt_shape
=
640
,
threshold
=
0.5
):
self
.
pred_config
=
pred_config
self
.
predictor
=
load_predictor
(
model_dir
,
run_mode
=
run_mode
,
min_subgraph_size
=
self
.
pred_config
.
min_subgraph_size
,
use_gpu
=
use_gpu
)
use_gpu
=
use_gpu
,
use_dynamic_shape
=
use_dynamic_shape
,
trt_min_shape
=
trt_min_shape
,
trt_max_shape
=
trt_max_shape
,
trt_opt_shape
=
trt_opt_shape
)
def
predict
(
self
,
image
,
...
...
@@ -287,11 +312,20 @@ def load_predictor(model_dir,
run_mode
=
'fluid'
,
batch_size
=
1
,
use_gpu
=
False
,
min_subgraph_size
=
3
):
min_subgraph_size
=
3
,
use_dynamic_shape
=
False
,
trt_min_shape
=
1
,
trt_max_shape
=
1280
,
trt_opt_shape
=
640
):
"""set AnalysisConfig, generate AnalysisPredictor
Args:
model_dir (str): root path of __model__ and __params__
use_gpu (bool): whether use gpu
run_mode (str): mode of running(fluid/trt_fp32/trt_fp16)
use_dynamic_shape (bool): use dynamic shape or not
trt_min_shape (int): min shape for dynamic shape in trt
trt_max_shape (int): max shape for dynamic shape in trt
trt_opt_shape (int): opt shape for dynamic shape in trt
Returns:
predictor (PaddlePredictor): AnalysisPredictor
Raises:
...
...
@@ -301,9 +335,12 @@ def load_predictor(model_dir,
raise
ValueError
(
"Predict by TensorRT mode: {}, expect use_gpu==True, but use_gpu == {}"
.
format
(
run_mode
,
use_gpu
))
if
run_mode
==
'trt_int8'
:
raise
ValueError
(
"TensorRT int8 mode is not supported now, "
"please use trt_fp32 or trt_fp16 instead."
)
if
run_mode
==
'trt_int8'
and
not
os
.
path
.
exists
(
os
.
path
.
join
(
model_dir
,
'_opt_cache'
)):
raise
ValueError
(
"TensorRT int8 must calibration first, and model_dir must has _opt_cache dir"
)
use_calib_mode
=
True
if
run_mode
==
'trt_int8'
else
False
config
=
Config
(
os
.
path
.
join
(
model_dir
,
'model.pdmodel'
),
os
.
path
.
join
(
model_dir
,
'model.pdiparams'
))
...
...
@@ -316,11 +353,7 @@ def load_predictor(model_dir,
# initial GPU memory(M), device ID
config
.
enable_use_gpu
(
200
,
0
)
# optimize graph and fuse op
# FIXME(dkp): ir optimize may prune variable inside graph
# and incur error in Paddle 2.0, e.g. in SSDLite
# FCOS model, set as False currently and should
# be set as True after switch_ir_optim fixed
config
.
switch_ir_optim
(
False
)
config
.
switch_ir_optim
(
True
)
else
:
config
.
disable_gpu
()
...
...
@@ -331,7 +364,16 @@ def load_predictor(model_dir,
min_subgraph_size
=
min_subgraph_size
,
precision_mode
=
precision_map
[
run_mode
],
use_static
=
False
,
use_calib_mode
=
False
)
use_calib_mode
=
use_calib_mode
)
if
use_dynamic_shape
:
print
(
'use_dynamic_shape'
)
min_input_shape
=
{
'image'
:
[
1
,
3
,
trt_min_shape
,
trt_min_shape
]}
max_input_shape
=
{
'image'
:
[
1
,
3
,
trt_max_shape
,
trt_max_shape
]}
opt_input_shape
=
{
'image'
:
[
1
,
3
,
trt_opt_shape
,
trt_opt_shape
]}
config
.
set_trt_dynamic_shape_info
(
min_input_shape
,
max_input_shape
,
opt_input_shape
)
print
(
'trt set dynamic shape done!'
)
# disable print log when predict
config
.
disable_glog_info
()
...
...
@@ -424,13 +466,21 @@ def main():
pred_config
,
FLAGS
.
model_dir
,
use_gpu
=
FLAGS
.
use_gpu
,
run_mode
=
FLAGS
.
run_mode
)
run_mode
=
FLAGS
.
run_mode
,
use_dynamic_shape
=
FLAGS
.
use_dynamic_shape
,
trt_min_shape
=
FLAGS
.
trt_min_shape
,
trt_max_shape
=
FLAGS
.
trt_max_shape
,
trt_opt_shape
=
FLAGS
.
trt_opt_shape
)
if
pred_config
.
arch
==
'SOLOv2'
:
detector
=
DetectorSOLOv2
(
pred_config
,
FLAGS
.
model_dir
,
use_gpu
=
FLAGS
.
use_gpu
,
run_mode
=
FLAGS
.
run_mode
)
run_mode
=
FLAGS
.
run_mode
,
use_dynamic_shape
=
FLAGS
.
use_dynamic_shape
,
trt_min_shape
=
FLAGS
.
trt_min_shape
,
trt_max_shape
=
FLAGS
.
trt_max_shape
,
trt_opt_shape
=
FLAGS
.
trt_opt_shape
)
# predict from image
if
FLAGS
.
image_file
!=
''
:
predict_image
(
detector
)
...
...
@@ -480,6 +530,23 @@ if __name__ == '__main__':
type
=
str
,
default
=
"output"
,
help
=
"Directory of output visualization files."
)
parser
.
add_argument
(
"--use_dynamic_shape"
,
type
=
ast
.
literal_eval
,
default
=
False
,
help
=
"Dynamic_shape for TensorRT."
)
parser
.
add_argument
(
"--trt_min_shape"
,
type
=
int
,
default
=
1
,
help
=
"min_shape for TensorRT."
)
parser
.
add_argument
(
"--trt_max_shape"
,
type
=
int
,
default
=
1280
,
help
=
"max_shape for TensorRT."
)
parser
.
add_argument
(
"--trt_opt_shape"
,
type
=
int
,
default
=
640
,
help
=
"opt_shape for TensorRT."
)
FLAGS
=
parser
.
parse_args
()
print_arguments
(
FLAGS
)
...
...
dygraph/deploy/python/trt_int8_calib.py
0 → 100644
浏览文件 @
965a55ce
# Copyright (c) 2020 PaddlePaddle Authors. All Rights Reserved.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
import
os
import
argparse
import
time
import
yaml
import
ast
from
functools
import
reduce
from
PIL
import
Image
import
cv2
import
numpy
as
np
import
glob
import
paddle
from
preprocess
import
preprocess
,
Resize
,
NormalizeImage
,
Permute
,
PadStride
from
visualize
import
visualize_box_mask
from
paddle.inference
import
Config
from
paddle.inference
import
create_predictor
# Global dictionary
SUPPORT_MODELS
=
{
'YOLO'
,
'RCNN'
,
'SSD'
,
'FCOS'
,
'SOLOv2'
,
'TTFNet'
,
}
class
Detector
(
object
):
"""
Args:
config (object): config of model, defined by `Config(model_dir)`
model_dir (str): root path of model.pdiparams, model.pdmodel and infer_cfg.yml
use_gpu (bool): whether use gpu
"""
def
__init__
(
self
,
pred_config
,
model_dir
,
use_gpu
=
False
):
self
.
pred_config
=
pred_config
self
.
predictor
=
load_predictor
(
model_dir
,
min_subgraph_size
=
self
.
pred_config
.
min_subgraph_size
,
use_gpu
=
use_gpu
)
def
preprocess
(
self
,
im
):
preprocess_ops
=
[]
for
op_info
in
self
.
pred_config
.
preprocess_infos
:
new_op_info
=
op_info
.
copy
()
op_type
=
new_op_info
.
pop
(
'type'
)
preprocess_ops
.
append
(
eval
(
op_type
)(
**
new_op_info
))
im
,
im_info
=
preprocess
(
im
,
preprocess_ops
,
self
.
pred_config
.
input_shape
)
inputs
=
create_inputs
(
im
,
im_info
)
return
inputs
def
postprocess
(
self
,
np_boxes
,
np_masks
,
inputs
,
threshold
=
0.5
):
# postprocess output of predictor
results
=
{}
if
self
.
pred_config
.
arch
in
[
'Face'
]:
h
,
w
=
inputs
[
'im_shape'
]
scale_y
,
scale_x
=
inputs
[
'scale_factor'
]
w
,
h
=
float
(
h
)
/
scale_y
,
float
(
w
)
/
scale_x
np_boxes
[:,
2
]
*=
h
np_boxes
[:,
3
]
*=
w
np_boxes
[:,
4
]
*=
h
np_boxes
[:,
5
]
*=
w
results
[
'boxes'
]
=
np_boxes
if
np_masks
is
not
None
:
results
[
'masks'
]
=
np_masks
return
results
def
predict
(
self
,
image
,
threshold
=
0.5
,
warmup
=
0
,
repeats
=
1
,
run_benchmark
=
False
):
'''
Args:
image (str/np.ndarray): path of image/ np.ndarray read by cv2
threshold (float): threshold of predicted box' score
Returns:
results (dict): include 'boxes': np.ndarray: shape:[N,6], N: number of box,
matix element:[class, score, x_min, y_min, x_max, y_max]
MaskRCNN's results include 'masks': np.ndarray:
shape: [N, im_h, im_w]
'''
inputs
=
self
.
preprocess
(
image
)
np_boxes
,
np_masks
=
None
,
None
input_names
=
self
.
predictor
.
get_input_names
()
for
i
in
range
(
len
(
input_names
)):
input_tensor
=
self
.
predictor
.
get_input_handle
(
input_names
[
i
])
input_tensor
.
copy_from_cpu
(
inputs
[
input_names
[
i
]])
for
i
in
range
(
warmup
):
self
.
predictor
.
run
()
output_names
=
self
.
predictor
.
get_output_names
()
boxes_tensor
=
self
.
predictor
.
get_output_handle
(
output_names
[
0
])
np_boxes
=
boxes_tensor
.
copy_to_cpu
()
if
self
.
pred_config
.
mask
:
masks_tensor
=
self
.
predictor
.
get_output_handle
(
output_names
[
2
])
np_masks
=
masks_tensor
.
copy_to_cpu
()
t1
=
time
.
time
()
for
i
in
range
(
repeats
):
self
.
predictor
.
run
()
output_names
=
self
.
predictor
.
get_output_names
()
boxes_tensor
=
self
.
predictor
.
get_output_handle
(
output_names
[
0
])
np_boxes
=
boxes_tensor
.
copy_to_cpu
()
if
self
.
pred_config
.
mask
:
masks_tensor
=
self
.
predictor
.
get_output_handle
(
output_names
[
2
])
np_masks
=
masks_tensor
.
copy_to_cpu
()
t2
=
time
.
time
()
ms
=
(
t2
-
t1
)
*
1000.0
/
repeats
print
(
"Inference: {} ms per batch image"
.
format
(
ms
))
# do not perform postprocess in benchmark mode
results
=
[]
if
not
run_benchmark
:
if
reduce
(
lambda
x
,
y
:
x
*
y
,
np_boxes
.
shape
)
<
6
:
print
(
'[WARNNING] No object detected.'
)
results
=
{
'boxes'
:
np
.
array
([])}
else
:
results
=
self
.
postprocess
(
np_boxes
,
np_masks
,
inputs
,
threshold
=
threshold
)
return
results
def
create_inputs
(
im
,
im_info
):
"""generate input for different model type
Args:
im (np.ndarray): image (np.ndarray)
im_info (dict): info of image
model_arch (str): model type
Returns:
inputs (dict): input of model
"""
inputs
=
{}
inputs
[
'image'
]
=
np
.
array
((
im
,
)).
astype
(
'float32'
)
inputs
[
'im_shape'
]
=
np
.
array
((
im_info
[
'im_shape'
],
)).
astype
(
'float32'
)
inputs
[
'scale_factor'
]
=
np
.
array
(
(
im_info
[
'scale_factor'
],
)).
astype
(
'float32'
)
return
inputs
class
PredictConfig
():
"""set config of preprocess, postprocess and visualize
Args:
model_dir (str): root path of model.yml
"""
def
__init__
(
self
,
model_dir
):
# parsing Yaml config for Preprocess
deploy_file
=
os
.
path
.
join
(
model_dir
,
'infer_cfg.yml'
)
with
open
(
deploy_file
)
as
f
:
yml_conf
=
yaml
.
safe_load
(
f
)
self
.
check_model
(
yml_conf
)
self
.
arch
=
yml_conf
[
'arch'
]
self
.
preprocess_infos
=
yml_conf
[
'Preprocess'
]
self
.
min_subgraph_size
=
yml_conf
[
'min_subgraph_size'
]
self
.
labels
=
yml_conf
[
'label_list'
]
self
.
mask
=
False
if
'mask'
in
yml_conf
:
self
.
mask
=
yml_conf
[
'mask'
]
self
.
input_shape
=
yml_conf
[
'image_shape'
]
self
.
print_config
()
def
check_model
(
self
,
yml_conf
):
"""
Raises:
ValueError: loaded model not in supported model type
"""
for
support_model
in
SUPPORT_MODELS
:
if
support_model
in
yml_conf
[
'arch'
]:
return
True
raise
ValueError
(
"Unsupported arch: {}, expect {}"
.
format
(
yml_conf
[
'arch'
],
SUPPORT_MODELS
))
def
print_config
(
self
):
print
(
'----------- Model Configuration -----------'
)
print
(
'%s: %s'
%
(
'Model Arch'
,
self
.
arch
))
print
(
'%s: '
%
(
'Transform Order'
))
for
op_info
in
self
.
preprocess_infos
:
print
(
'--%s: %s'
%
(
'transform op'
,
op_info
[
'type'
]))
print
(
'--------------------------------------------'
)
def
load_predictor
(
model_dir
,
batch_size
=
1
,
use_gpu
=
False
,
min_subgraph_size
=
3
):
"""set AnalysisConfig, generate AnalysisPredictor
Args:
model_dir (str): root path of __model__ and __params__
use_gpu (bool): whether use gpu
Returns:
predictor (PaddlePredictor): AnalysisPredictor
Raises:
ValueError: predict by TensorRT need use_gpu == True.
"""
run_mode
=
'trt_int8'
if
not
use_gpu
and
not
run_mode
==
'fluid'
:
raise
ValueError
(
"Predict by TensorRT mode: {}, expect use_gpu==True, but use_gpu == {}"
.
format
(
run_mode
,
use_gpu
))
config
=
Config
(
os
.
path
.
join
(
model_dir
,
'model.pdmodel'
),
os
.
path
.
join
(
model_dir
,
'model.pdiparams'
))
precision_map
=
{
'trt_int8'
:
Config
.
Precision
.
Int8
,
'trt_fp32'
:
Config
.
Precision
.
Float32
,
'trt_fp16'
:
Config
.
Precision
.
Half
}
if
use_gpu
:
# initial GPU memory(M), device ID
config
.
enable_use_gpu
(
200
,
0
)
# optimize graph and fuse op
config
.
switch_ir_optim
(
True
)
else
:
config
.
disable_gpu
()
if
run_mode
in
precision_map
.
keys
():
config
.
enable_tensorrt_engine
(
workspace_size
=
1
<<
10
,
max_batch_size
=
batch_size
,
min_subgraph_size
=
min_subgraph_size
,
precision_mode
=
precision_map
[
run_mode
],
use_static
=
False
,
use_calib_mode
=
True
)
# disable print log when predict
config
.
disable_glog_info
()
# enable shared memory
config
.
enable_memory_optim
()
# disable feed, fetch OP, needed by zero_copy_run
config
.
switch_use_feed_fetch_ops
(
False
)
predictor
=
create_predictor
(
config
)
return
predictor
def
print_arguments
(
args
):
print
(
'----------- Running Arguments -----------'
)
for
arg
,
value
in
sorted
(
vars
(
args
).
items
()):
print
(
'%s: %s'
%
(
arg
,
value
))
print
(
'------------------------------------------'
)
def
predict_image_dir
(
detector
):
for
image_file
in
glob
.
glob
(
FLAGS
.
image_dir
+
'/*.jpg'
):
print
(
'image_file is'
,
image_file
)
results
=
detector
.
predict
(
image_file
,
threshold
=
0.5
)
def
main
():
pred_config
=
PredictConfig
(
FLAGS
.
model_dir
)
detector
=
Detector
(
pred_config
,
FLAGS
.
model_dir
,
use_gpu
=
FLAGS
.
use_gpu
)
# predict from image
if
FLAGS
.
image_dir
!=
''
:
predict_image_dir
(
detector
)
if
__name__
==
'__main__'
:
paddle
.
enable_static
()
parser
=
argparse
.
ArgumentParser
(
description
=
__doc__
)
parser
.
add_argument
(
"--model_dir"
,
type
=
str
,
default
=
None
,
help
=
(
"Directory include:'model.pdiparams', 'model.pdmodel', "
"'infer_cfg.yml', created by tools/export_model.py."
),
required
=
True
)
parser
.
add_argument
(
"--image_dir"
,
type
=
str
,
default
=
''
,
help
=
"Directory of image file."
)
parser
.
add_argument
(
"--use_gpu"
,
type
=
ast
.
literal_eval
,
default
=
False
,
help
=
"Whether to predict with GPU."
)
print
(
'err?'
)
parser
.
add_argument
(
"--output_dir"
,
type
=
str
,
default
=
"output"
,
help
=
"Directory of output visualization files."
)
FLAGS
=
parser
.
parse_args
()
print_arguments
(
FLAGS
)
main
()
dygraph/deploy/tensorrt/README.md
0 → 100644
浏览文件 @
965a55ce
# TensorRT预测部署教程
TensorRT是NVIDIA提出的用于统一模型部署的加速库,可以应用于V100、JETSON Xavier等硬件,它可以极大提高预测速度。Paddle TensorRT教程请参考文档
[
使用Paddle-TensorRT库预测
](
https://paddle-inference.readthedocs.io/en/latest/optimize/paddle_trt.html#
)
## 1. 安装PaddleInference预测库
-
Python安装包,请从
[
这里
](
https://www.paddlepaddle.org.cn/documentation/docs/zh/install/Tables.html#whl-release
)
下载带有tensorrt的安装包进行安装
-
CPP预测库,请从
[
这里
](
https://www.paddlepaddle.org.cn/documentation/docs/zh/guides/05_inference_deployment/inference/build_and_install_lib_cn.html
)
下载带有TensorRT编译的预测库
-
如果Python和CPP官网没有提供已编译好的安装包或预测库,请参考
[
源码安装
](
https://www.paddlepaddle.org.cn/documentation/docs/zh/install/compile/linux-compile.html
)
自行编译
注意,您的机器上TensorRT的版本需要跟您使用的预测库中TensorRT版本保持一致。
## 2. 导出模型
模型导出具体请参考文档
[
PaddleDetection模型导出教程
](
../EXPORT_MODEL.md
)
。
## 3. 开启TensorRT加速
### 3.1 配置TensorRT
在使用Paddle预测库构建预测器配置config时,打开TensorRT引擎就可以了:
```
config->EnableUseGpu(100, 0); // 初始化100M显存,使用GPU ID为0
config->GpuDeviceId(); // 返回正在使用的GPU ID
// 开启TensorRT预测,可提升GPU预测性能,需要使用带TensorRT的预测库
config->EnableTensorRtEngine(1 << 20 /*workspace_size*/,
batch_size /*max_batch_size*/,
3 /*min_subgraph_size*/,
AnalysisConfig::Precision::kFloat32 /*precision*/,
false /*use_static*/,
false /*use_calib_mode*/);
```
### 3.2 TensorRT固定尺寸预测
TensorRT版本<=5时,使用TensorRT预测时,只支持固定尺寸输入。
在导出模型时指定模型输入尺寸,设置
`TestReader.inputs_def.image_shape=[3,640,640]`
,具体请参考
[
PaddleDetection模型导出教程
](
../EXPORT_MODEL.md
)
。
`TestReader.inputs_def.image_shape`
设置的是输入TensorRT引擎的数据尺寸(在像FasterRCNN中,
`TestReader.inputs_def.image_shape`
指定的是在
`Pad`
操作之前的图像数据尺寸)。
可以通过
[
visualdl
](
https://www.paddlepaddle.org.cn/paddle/visualdl/demo/graph
)
打开
`model.pdmodel`
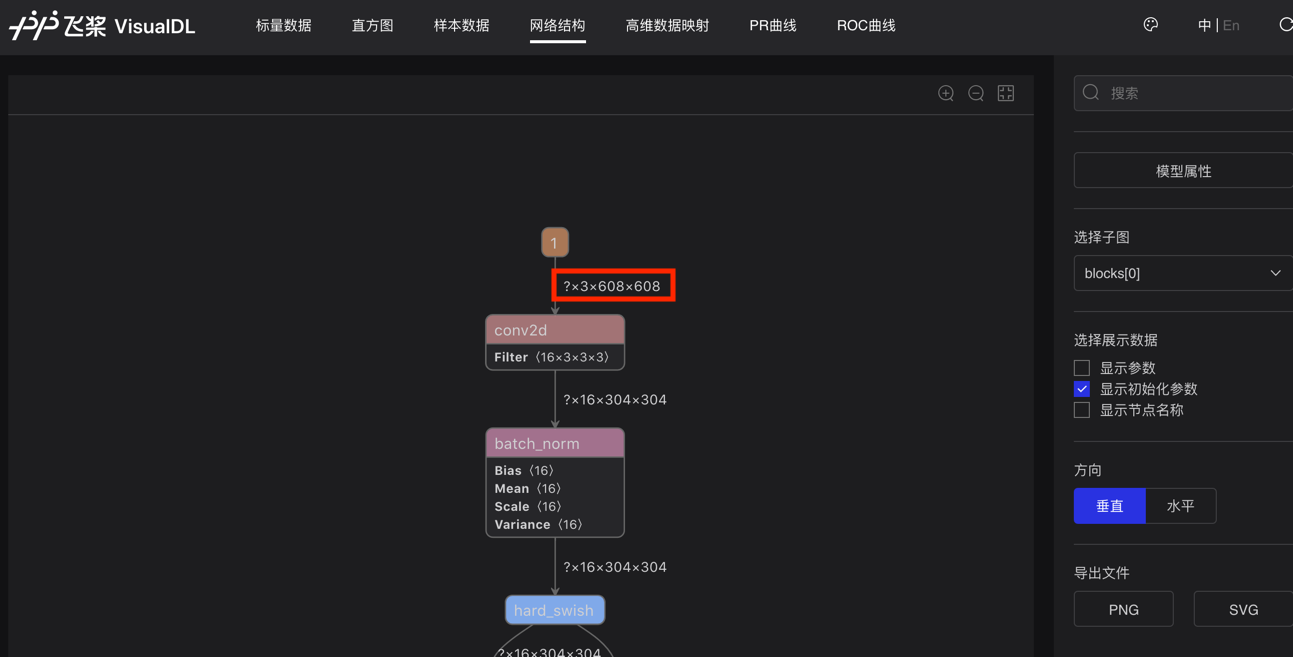
文件,查看输入的第一个Tensor尺寸是否是固定的,如果不指定,尺寸会用
`?`
表示,如下图所示:

### 3.3 TensorRT动态尺寸预测
TensorRT版本>=6时,使用TensorRT预测时,可以支持动态尺寸输入。
Paddle预测库关于动态尺寸输入请查看
[
Paddle CPP预测
](
https://www.paddlepaddle.org.cn/documentation/docs/zh/guides/05_inference_deployment/inference/native_infer.html
)
的
`SetTRTDynamicShapeInfo`
函数说明。
`python/infer.py`
设置动态尺寸输入参数说明:
-
use_dynamic_shape 用于设定TensorRT的输入尺寸是否是动态尺寸,默认值:False
-
trt_min_shape 用于设定TensorRT的输入图像height、width中的最小尺寸,默认值:1
-
trt_max_shape 用于设定TensorRT的输入图像height、width中的最大尺寸,默认值:1280
-
trt_opt_shape 用于设定TensorRT的输入图像height、width中的最优尺寸,默认值:640
**注意:`TensorRT`中动态尺寸设置是4维的,这里只设置输入图像的尺寸。**
## 4、常见问题QA
**Q:**
提示没有
`tensorrt_op`
</br>
**A:**
请检查是否使用带有TensorRT的Paddle Python包或预测库。
**Q:**
提示
`op out of memory`
</br>
**A:**
检查GPU是否是别人也在使用,请尝试使用空闲GPU
**Q:**
提示
`some trt inputs dynamic shape info not set`
</br>
**A:**
这是由于
`TensorRT`
会把网络结果划分成多个子图,我们只设置了输入数据的动态尺寸,划分的其他子图的输入并未设置动态尺寸。有两个解决方法:
-
方法一:通过增大
`min_subgraph_size`
,跳过对这些子图的优化。根据提示,设置min_subgraph_size大于并未设置动态尺寸输入的子图中OP个数即可。
`min_subgraph_size`
的意思是,在加载TensorRT引擎的时候,大于
`min_subgraph_size`
的OP才会被优化,并且这些OP是连续的且是TensorRT可以优化的。
-
方法二:找到子图的这些输入,按照上面方式也设置子图的输入动态尺寸。
**Q:**
如何打开日志
</br>
**A:**
预测库默认是打开日志的,只要注释掉
`config.disable_glog_info()`
就可以打开日志
dygraph/deploy/tensorrt/imgs/input_shape.png
0 → 100644
浏览文件 @
965a55ce
104.5 KB
编辑
预览
Markdown
is supported
0%
请重试
或
添加新附件
.
添加附件
取消
You are about to add
0
people
to the discussion. Proceed with caution.
先完成此消息的编辑!
取消
想要评论请
注册
或
登录
{kind=link}