Merge branch 'develop' of https://github.com/PaddlePaddle/Paddle into lstm
Showing
{kind=link}
{kind=link}
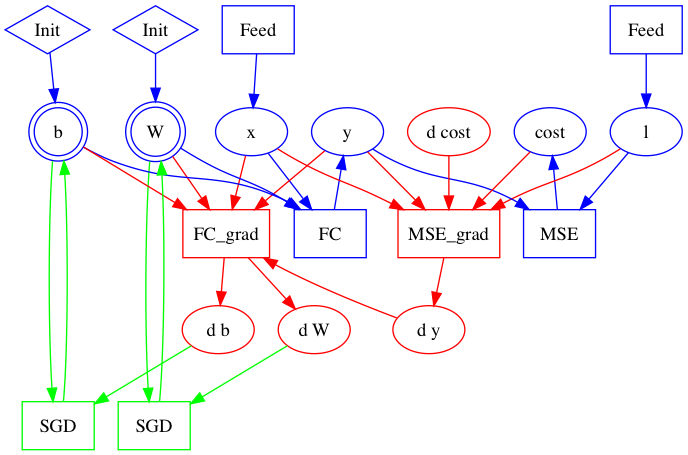
| W: | H:
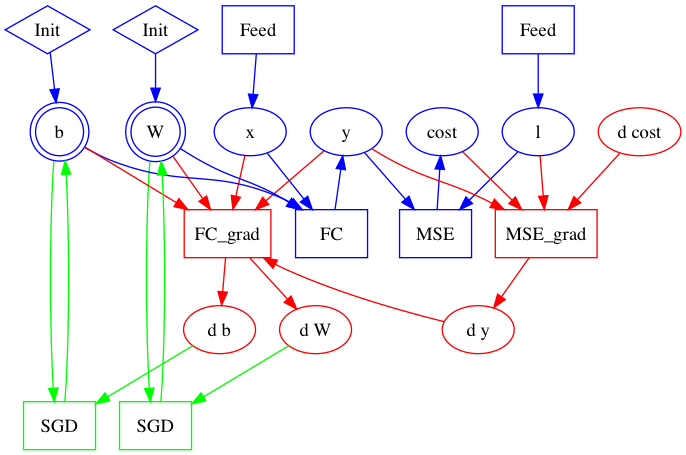
| W: | H:
{kind=link}
{kind=link}
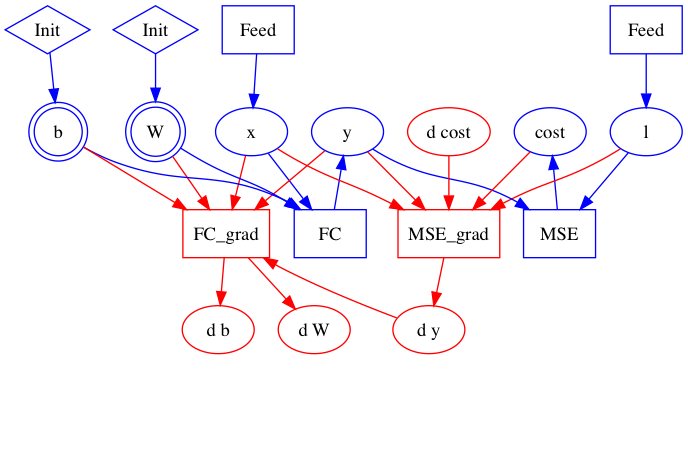
| W: | H:
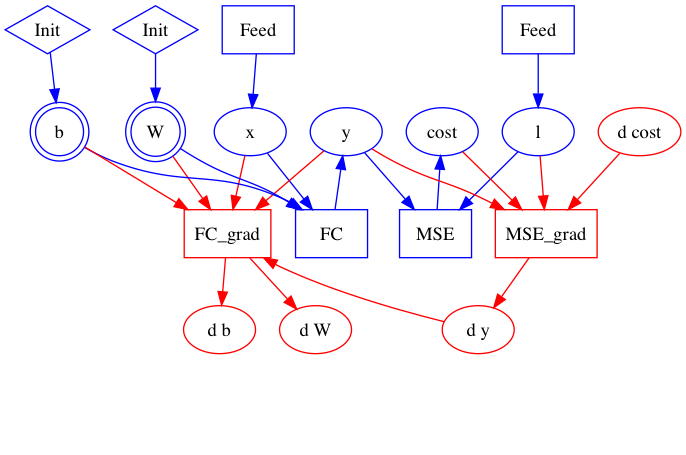
| W: | H:
{kind=link}
{kind=link}
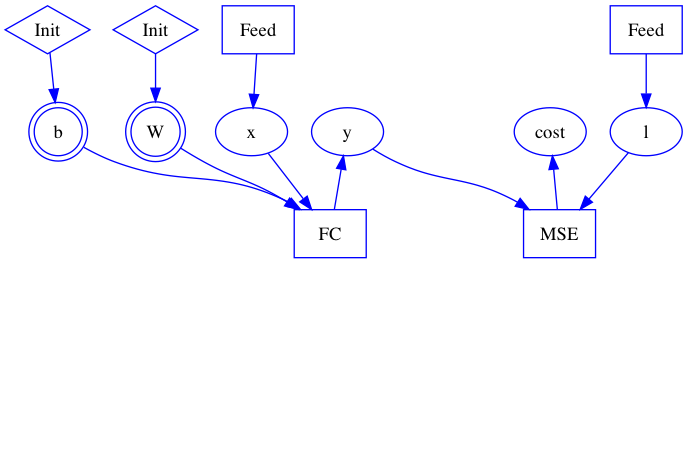
| W: | H:
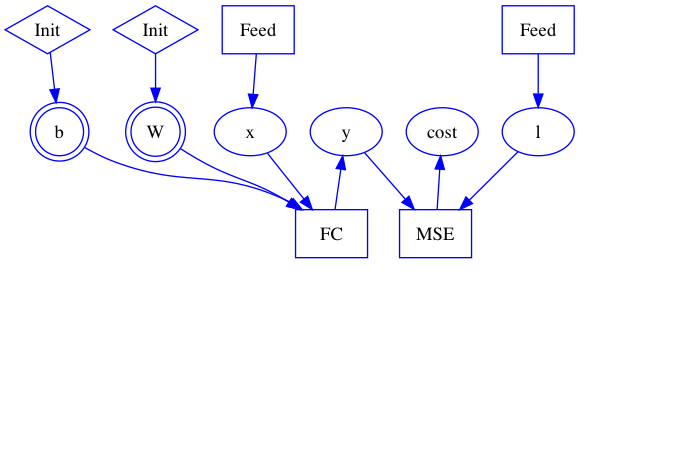
| W: | H:
paddle/framework/selected_rows.cc
0 → 100644
paddle/framework/selected_rows.h
0 → 100644
paddle/operators/adam_op.cc
0 → 100644
paddle/operators/adam_op.cu
0 → 100644
paddle/operators/adam_op.h
0 → 100644
paddle/operators/conv_cudnn_op.cc
0 → 100644
paddle/operators/conv_cudnn_op.cu
0 → 100644
paddle/operators/gru_unit_op.cc
0 → 100644
paddle/operators/gru_unit_op.cu
0 → 100644
paddle/operators/gru_unit_op.h
0 → 100644
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。