fix all documentation (#196)
* fix all documentation * fix docs conf.py * fix some error * fix readthedocs
Showing
docs/CHANGELOG.md
0 → 100644
docs/DATA.md
已删除
100644 → 0
docs/DATA_cn.md
已删除
100644 → 0
docs/Makefile
0 → 100644
docs/advanced_tutorials/READER.md
0 → 100644
此差异已折叠。
docs/advanced_tutorials/index.rst
0 → 100644
文件已移动
docs/conf.py
0 → 100644
docs/featured_model/CONTRIB.md
0 → 100644
docs/featured_model/index.rst
0 → 100644
{kind=link}
{kind=link}
{kind=link}
文件已移动
{kind=link}
文件已移动
{kind=link}
文件已移动
{kind=link}
文件已移动
{kind=link}
文件已移动
{kind=link}
docs/images/models_figure.png
0 → 100644
{kind=link}
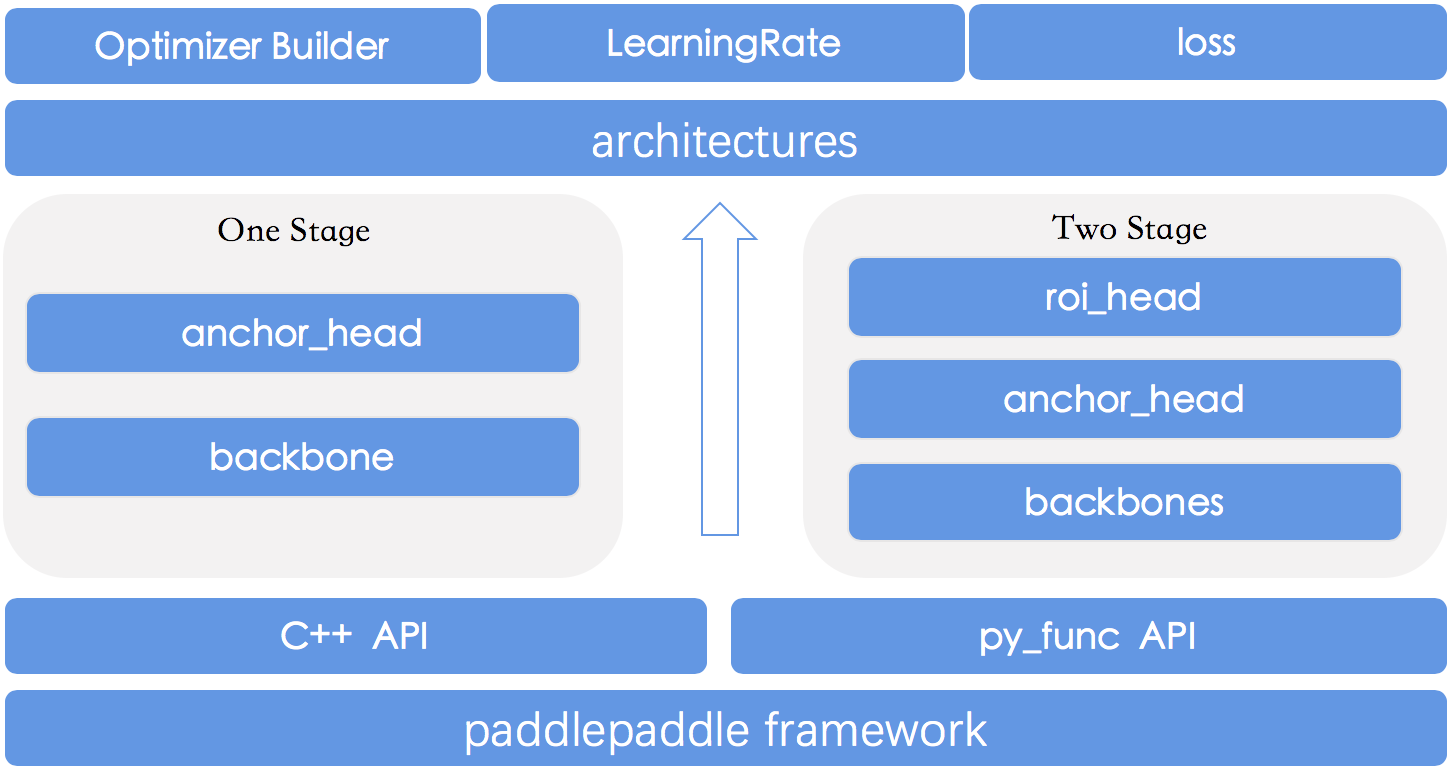
98.5 KB
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
docs/images/reader_figure.png
0 → 100644
{kind=link}
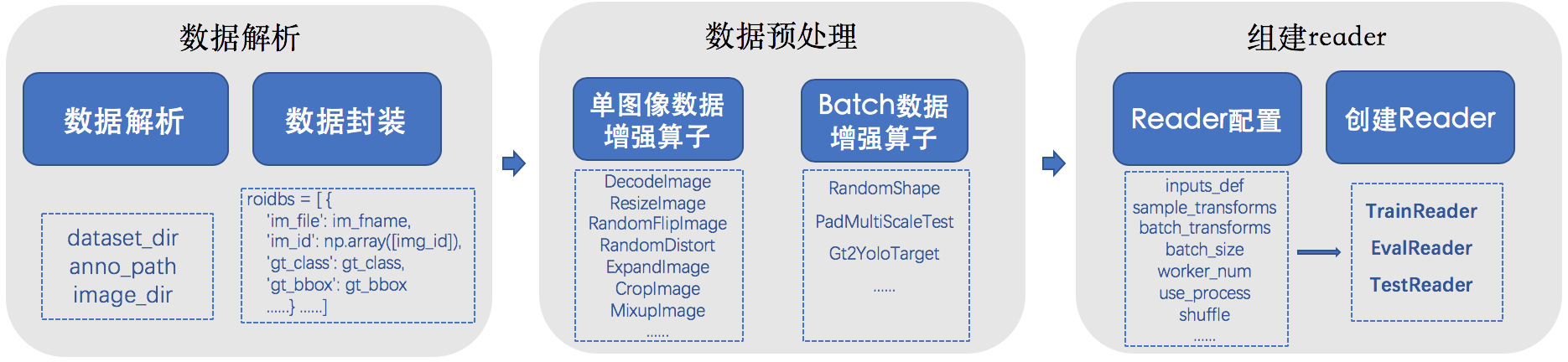
180.0 KB
{kind=link}
docs/index.rst
0 → 100644
docs/make.bat
0 → 100644
docs/requirements.txt
0 → 100644
docs/tutorials/index.rst
0 → 100644
{kind=link}

179.0 KB
此差异已折叠。