@@ -5,7 +5,7 @@ This document describes the RNN (Recurrent Neural Network) operator and how it i
## RNN Algorithm Implementation
<palign="center">
<imgsrc="./images/rnn.jpg"/>
<imgsrc="./rnn.jpg"/>
</p>
The above diagram shows an RNN unrolled into a full network.
...
...
@@ -22,7 +22,7 @@ There are several important concepts here:
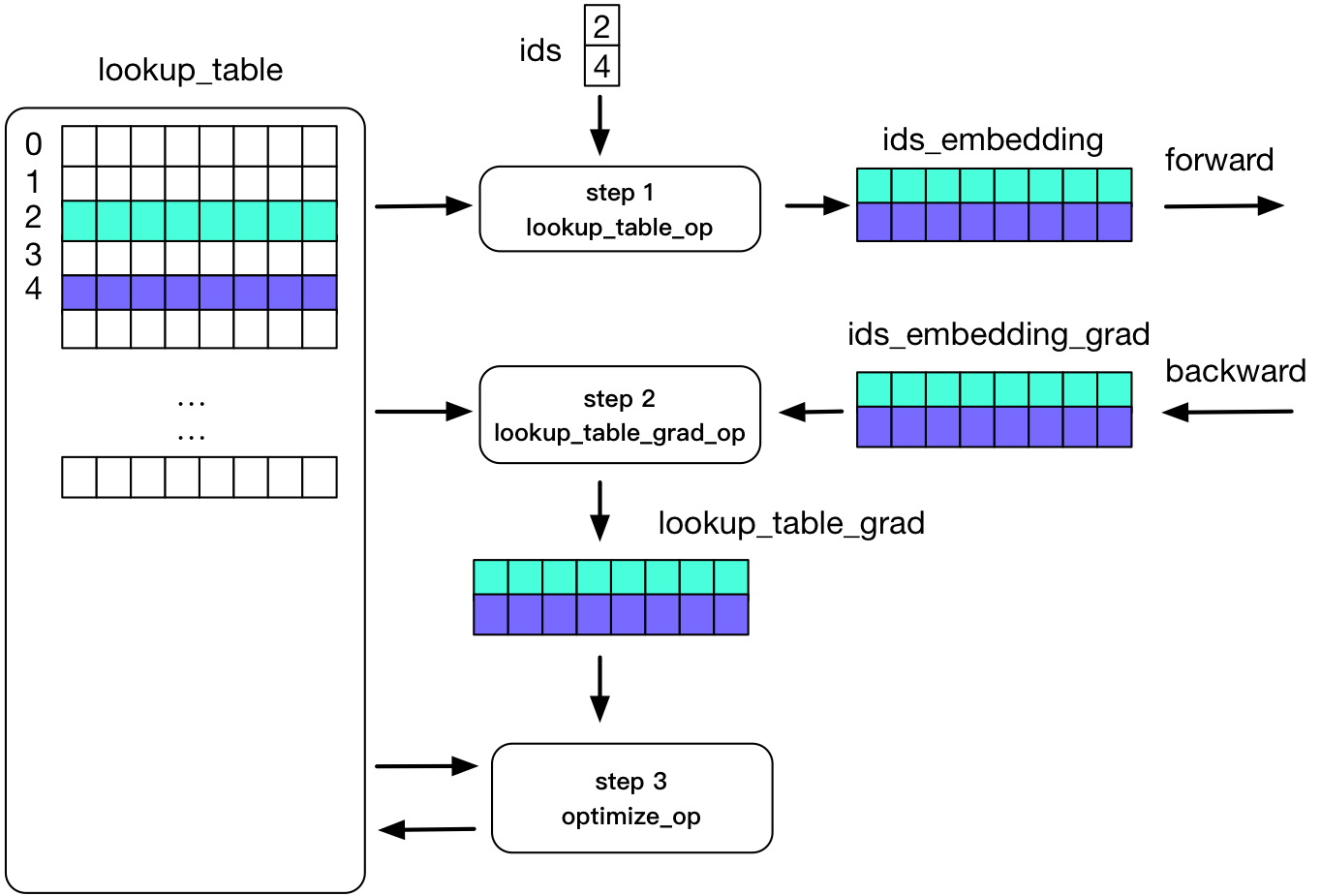
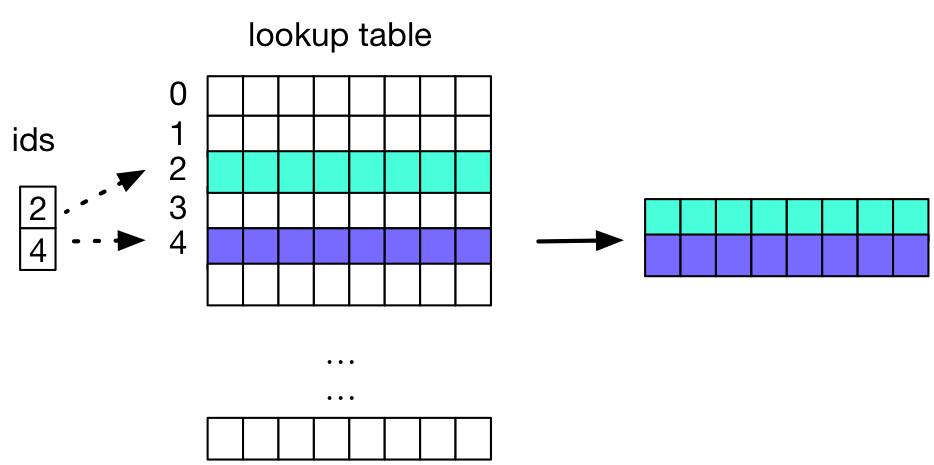
There could be local variables defined in each step-net. PaddlePaddle runtime realizes these variables in *step-scopes* which are created for each step.
<palign="center">
<imgsrc="./images/rnn.png"/><br/>
<imgsrc="./rnn.png"/><br/>
Figure 2 illustrates the RNN's data flow
</p>
...
...
@@ -49,7 +49,7 @@ or copy the memory value of the previous step to the current ex-memory variable.
### Usage in Python
For more information on Block, please refer to the [design doc](https://github.com/PaddlePaddle/Paddle/blob/develop/doc/design/block.md).
For more information on Block, please refer to the [design doc](https://github.com/PaddlePaddle/Paddle/blob/develop/doc/fluid/design/concepts/block.md).
We can define an RNN's step-net using a Block:
...
...
@@ -93,7 +93,7 @@ For example, we could have a 2-level RNN, where the top level corresponds to par
The following figure illustrates feeding in text into the lower level, one sentence at a step, and the feeding in step outputs to the top level. The final top level output is about the whole text.
<palign="center">
<imgsrc="./images/2_level_rnn.png"/>
<imgsrc="./2_level_rnn.png"/>
</p>
```python
...
...
@@ -149,5 +149,5 @@ If the `output_all_steps` is set to False, it will only output the final time st
@@ -103,7 +103,7 @@ In computability theory, a system of data-manipulation rules, such as a programm
There are two ways to execute a Fluid program. When a program is executed, it creates a protobuf message [`ProgramDesc`](https://github.com/PaddlePaddle/Paddle/blob/a91efdde6910ce92a78e3aa7157412c4c88d9ee8/paddle/framework/framework.proto#L145) that describes the process and is conceptually like an [abstract syntax tree](https://en.wikipedia.org/wiki/Abstract_syntax_tree).
There is a C++ class [`Executor`](https://github.com/PaddlePaddle/Paddle/blob/develop/paddle/framework/executor.h), which runs a `ProgramDesc`, similar to how an interpreter runs a Python program.
There is a C++ class [`Executor`](https://github.com/PaddlePaddle/Paddle/blob/develop/paddle/fluid/framework/executor.h), which runs a `ProgramDesc`, similar to how an interpreter runs a Python program.
Fluid is moving towards the direction of a compiler, which is explain in [fluid_compiler.md](fluid_compiler.md).
This document provides answers to some of the frequently asked questions about PaddlePaddle. If you have a question that is not covered here, please go to `PaddlePaddle Community <https://github.com/PaddlePaddle/Paddle/issues>`_ , to find an answer or submit new `issue <https://github.com/PaddlePaddle/Paddle/issues/new>`_ , we will reply in time.
The effectiveness of the deep learning model is often directly related to the scale of the data: it can generally achieve better results after increasing the size of the dataset on the same model. However, it can not fit in one single computer when the amount of data increases to a certain extent. At this point, using multiple computers for distributed training is a natural solution. In distributed training, the training data is divided into multiple copies (sharding), and multiple machines participating in the training read their own data for training and collaboratively update the parameters of the overall model.
Distributed training generally has framwork as shown below:
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}