Add fluid.md (#6547)
* Add fluid.md * in response to comments from Tony and Abhinav
Showing
doc/design/fluid-compiler.graffle
0 → 100644
文件已添加
doc/design/fluid-compiler.png
0 → 100644
{kind=link}
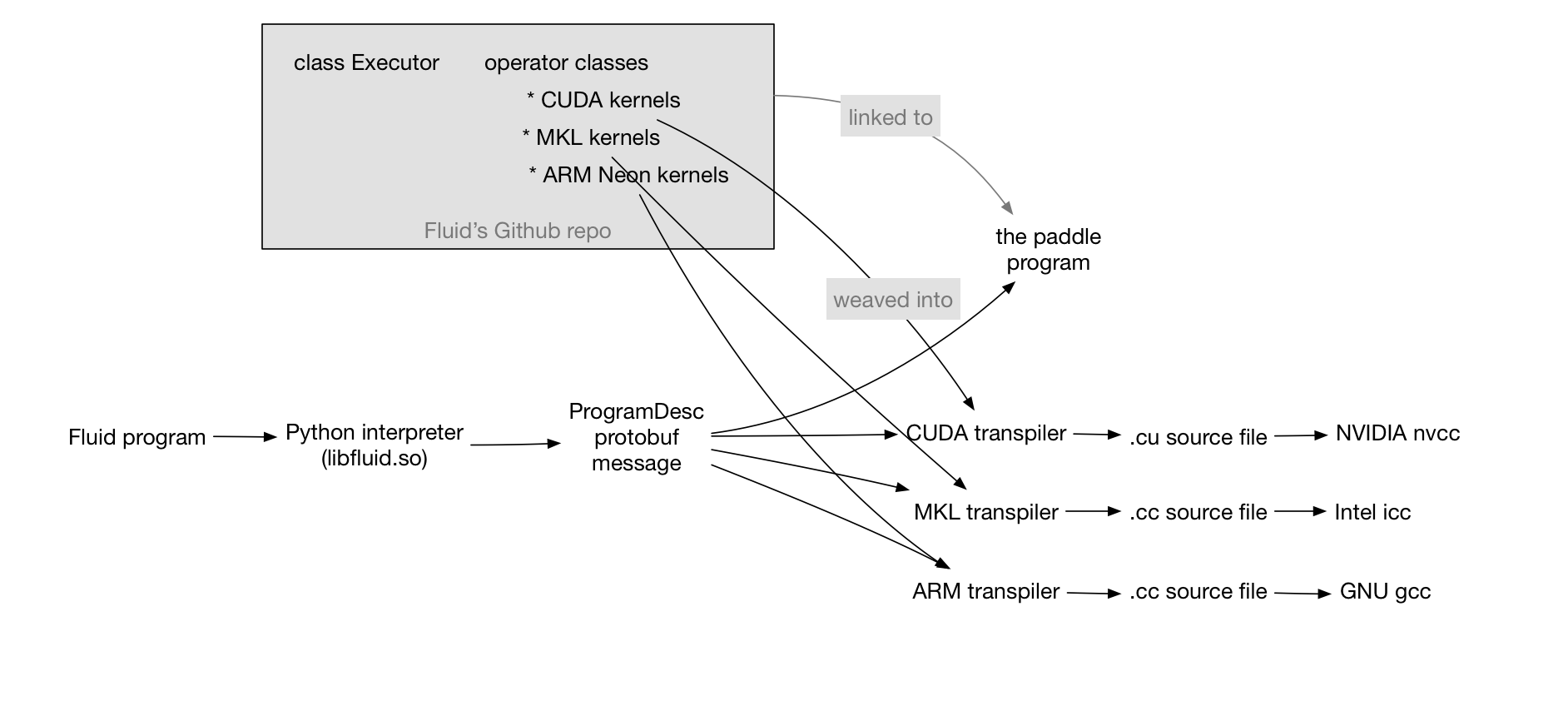
121.2 KB
doc/design/fluid.md
0 → 100644