2020-08-08 09:58:27
Showing
docs/tf-1x-dl-cookbook/00.md
0 → 100644
docs/tf-1x-dl-cookbook/01.md
0 → 100644
此差异已折叠。
docs/tf-1x-dl-cookbook/02.md
0 → 100644
此差异已折叠。
docs/tf-1x-dl-cookbook/03.md
0 → 100644
此差异已折叠。
docs/tf-1x-dl-cookbook/04.md
0 → 100644
此差异已折叠。
docs/tf-1x-dl-cookbook/05.md
0 → 100644
此差异已折叠。
docs/tf-1x-dl-cookbook/06.md
0 → 100644
此差异已折叠。
docs/tf-1x-dl-cookbook/07.md
0 → 100644
此差异已折叠。
docs/tf-1x-dl-cookbook/08.md
0 → 100644
此差异已折叠。
docs/tf-1x-dl-cookbook/09.md
0 → 100644
此差异已折叠。
docs/tf-1x-dl-cookbook/10.md
0 → 100644
此差异已折叠。
docs/tf-1x-dl-cookbook/11.md
0 → 100644
此差异已折叠。
docs/tf-1x-dl-cookbook/12.md
0 → 100644
此差异已折叠。
docs/tf-1x-dl-cookbook/13.md
0 → 100644
docs/tf-1x-dl-cookbook/14.md
0 → 100644
{kind=link}
10.5 KB
{kind=link}
114.8 KB
{kind=link}
107.6 KB
{kind=link}
12.1 KB
{kind=link}

655 字节
{kind=link}
49.9 KB
{kind=link}
5.9 KB
{kind=link}
5.1 KB
{kind=link}
2.1 KB
{kind=link}
3.8 KB
{kind=link}

8.1 KB
{kind=link}
1.8 KB
{kind=link}

47.1 KB
{kind=link}
15.6 KB
{kind=link}

1.7 KB
{kind=link}

7.3 KB
{kind=link}
20.0 KB
{kind=link}
3.4 KB
{kind=link}
4.4 KB
{kind=link}

197.0 KB
{kind=link}
60.7 KB
{kind=link}
7.5 KB
{kind=link}
1.9 KB
{kind=link}
924 字节
{kind=link}
184.6 KB
{kind=link}
14.6 KB
{kind=link}
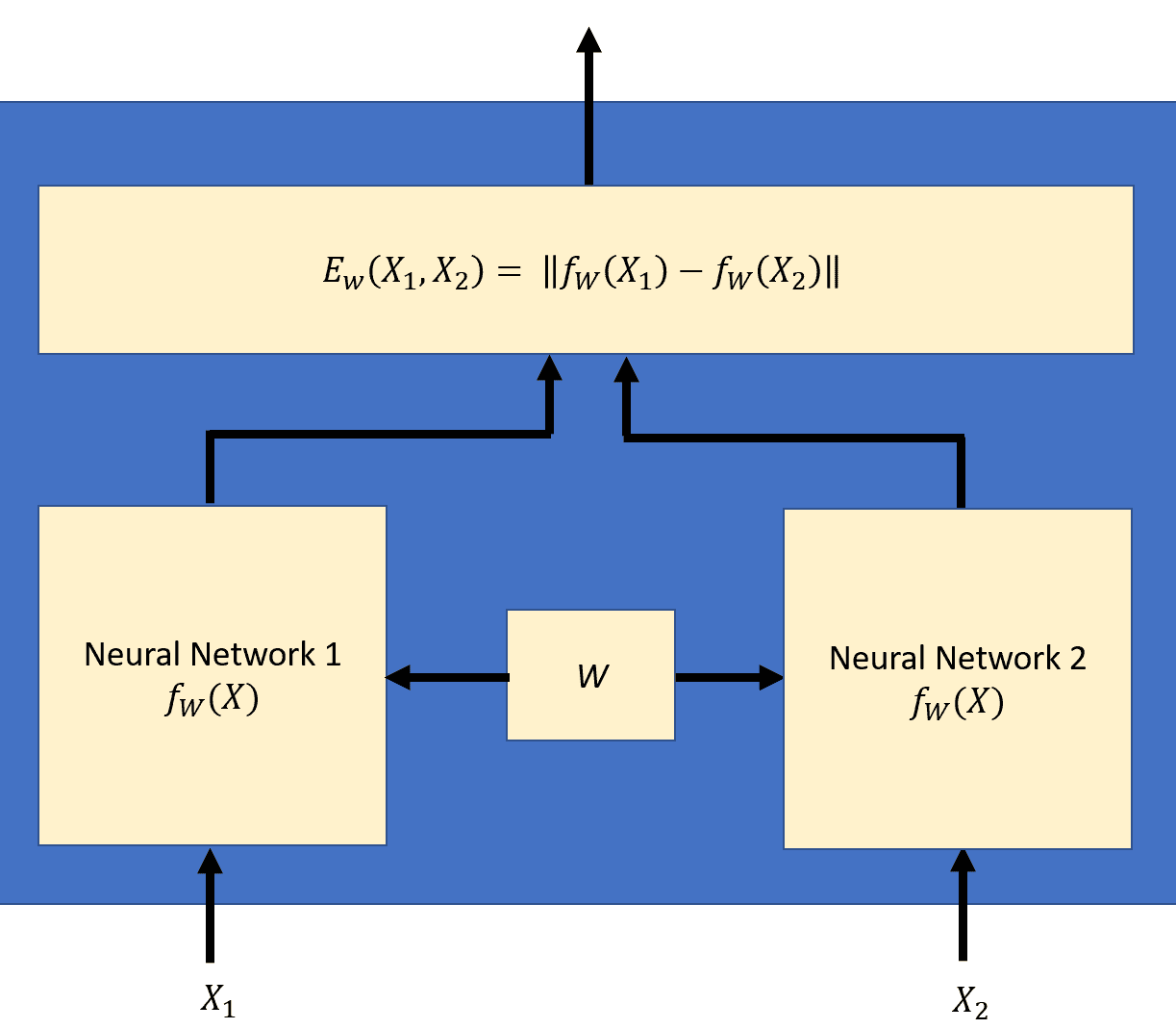
9.5 KB
{kind=link}

23.7 KB
{kind=link}
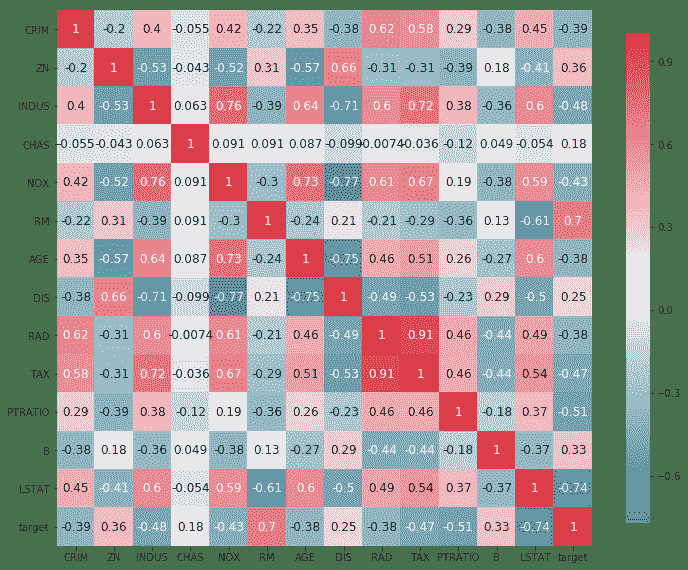
40.3 KB
{kind=link}

8.3 KB
{kind=link}
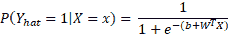
636 字节
{kind=link}
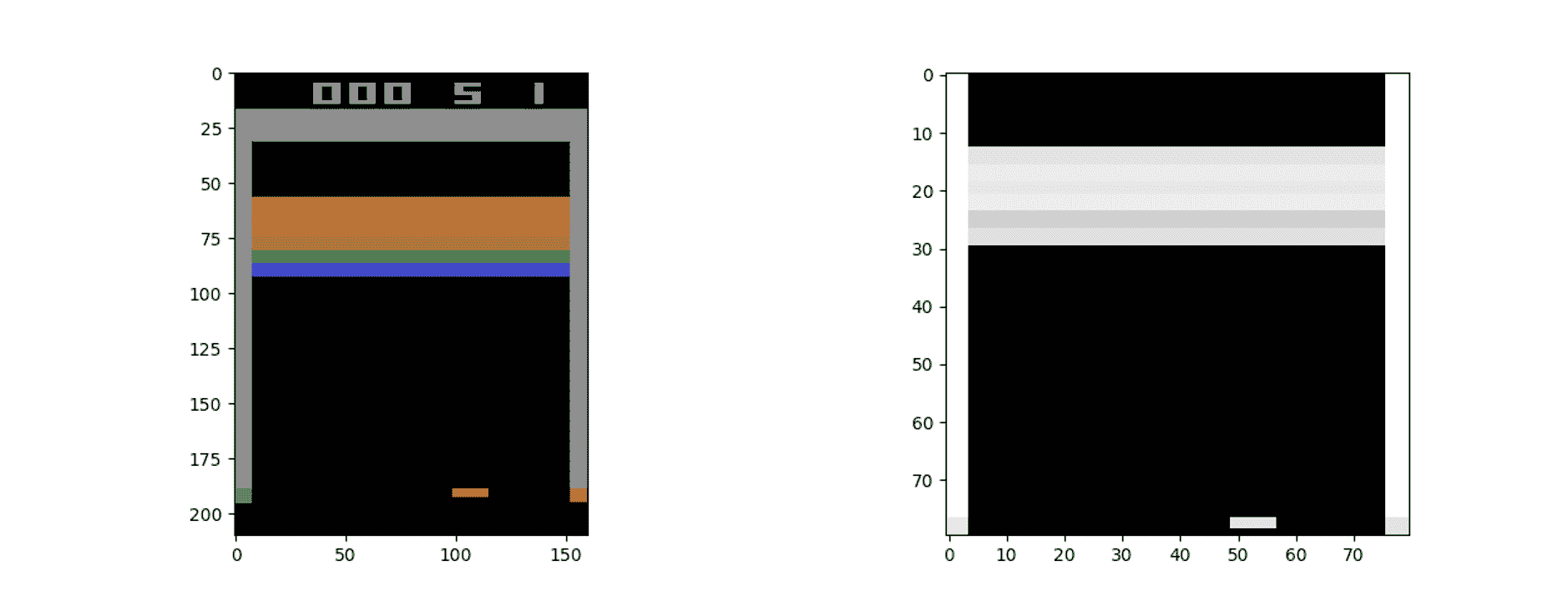
10.1 KB
{kind=link}
15.0 KB
{kind=link}
664 字节
{kind=link}
29.2 KB
{kind=link}
74.7 KB
{kind=link}
3.2 KB
{kind=link}
2.7 KB
{kind=link}
16.7 KB
{kind=link}
4.4 KB
{kind=link}

8.7 KB
{kind=link}
137.7 KB
{kind=link}
13.3 KB
{kind=link}
12.2 KB
{kind=link}
1.9 KB
{kind=link}
95.8 KB
{kind=link}
6.3 KB
{kind=link}

11.8 KB
{kind=link}
12.3 KB
{kind=link}

53.5 KB
{kind=link}
4.0 KB
{kind=link}
5.5 KB
{kind=link}
5.7 KB
{kind=link}
2.9 KB
{kind=link}

12.8 KB
{kind=link}
11.2 KB
{kind=link}

865 字节
{kind=link}
50.7 KB
{kind=link}

6.1 KB
{kind=link}
2.3 KB
{kind=link}
4.8 KB
{kind=link}

26.3 KB
{kind=link}
545 字节
{kind=link}

23.7 KB
{kind=link}
5.9 KB
{kind=link}
8.8 KB
{kind=link}
23.4 KB
{kind=link}

36.1 KB
{kind=link}

57.7 KB
{kind=link}
27.8 KB
{kind=link}
5.4 KB
{kind=link}
6.9 KB
{kind=link}

23.8 KB
{kind=link}
1.9 KB
{kind=link}
7.8 KB
{kind=link}
6.9 KB
{kind=link}

121.4 KB
{kind=link}

36.8 KB
{kind=link}
367 字节
{kind=link}
6.1 KB
{kind=link}

4.4 KB
{kind=link}
24.0 KB
{kind=link}
25.1 KB
{kind=link}
44.4 KB
{kind=link}
757 字节
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}