Merge pull request #3896 from Evezerest/dygraph
Upgrade document structure
Showing
doc/PaddleOCR_log.png
0 → 100644
{kind=link}

75.5 KB
doc/doc_ch/environment.md
0 → 100644
doc/doc_ch/models_and_config.md
0 → 100644
doc/doc_ch/paddleOCR_overview.md
0 → 100644
doc/doc_ch/training.md
0 → 100644
doc/doc_en/environment_en.md
0 → 100644
doc/doc_en/training_en.md
0 → 100644
{kind=link}
70.9 KB
{kind=link}
48.1 KB
{kind=link}
140.7 KB
{kind=link}

84.5 KB
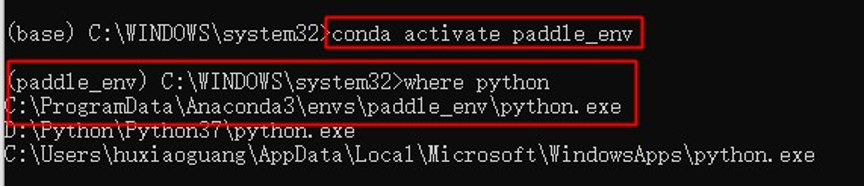
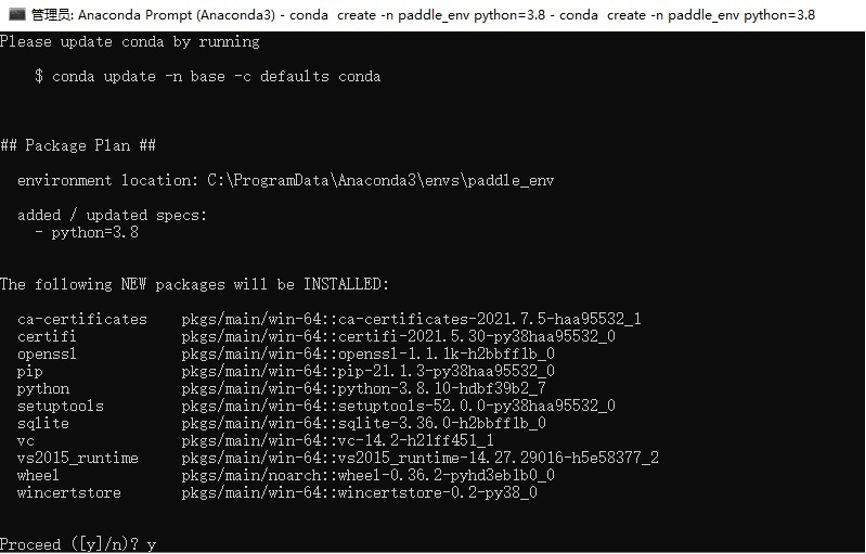
doc/install/mac/conda_create.png
0 → 100755
{kind=link}
71.6 KB
{kind=link}
173.2 KB
{kind=link}
124.7 KB
{kind=link}
73.8 KB
{kind=link}
321.2 KB
{kind=link}
134.9 KB
{kind=link}
231.4 KB