Merge pull request #5776 from typhoonzero/update_refactor_dist_train_doc
Update design of dist train refactor
Showing
文件已移动
{kind=link}
文件已移动
文件已移动
{kind=link}
文件已移动
{kind=link}
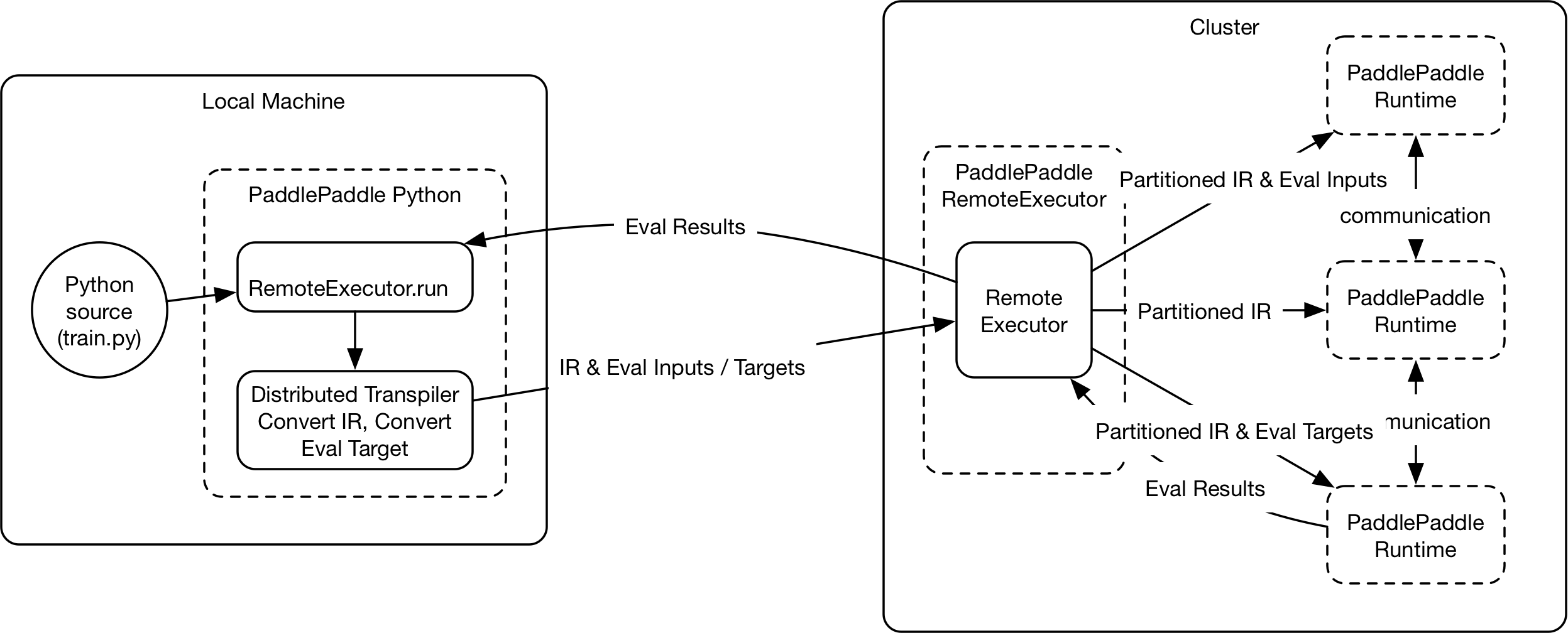
189.2 KB
文件已移动
{kind=link}
文件已移动
文件已添加
{kind=link}
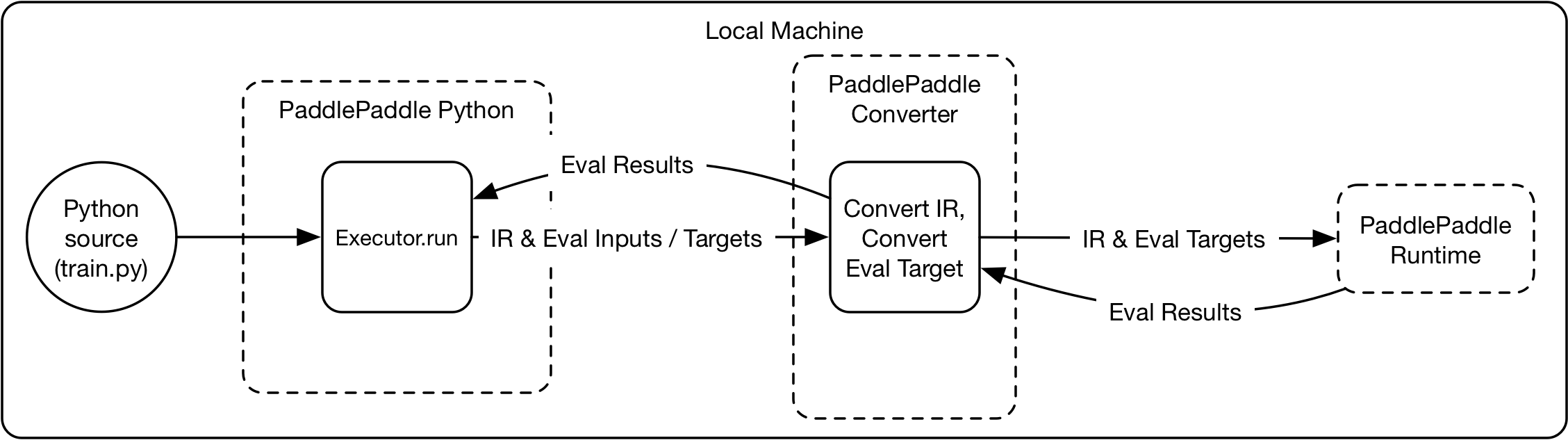
102.5 KB
文件已移动
{kind=link}
文件已移动
{kind=link}
文件已移动
文件已移动
{kind=link}
文件已移动
文件已添加
{kind=link}
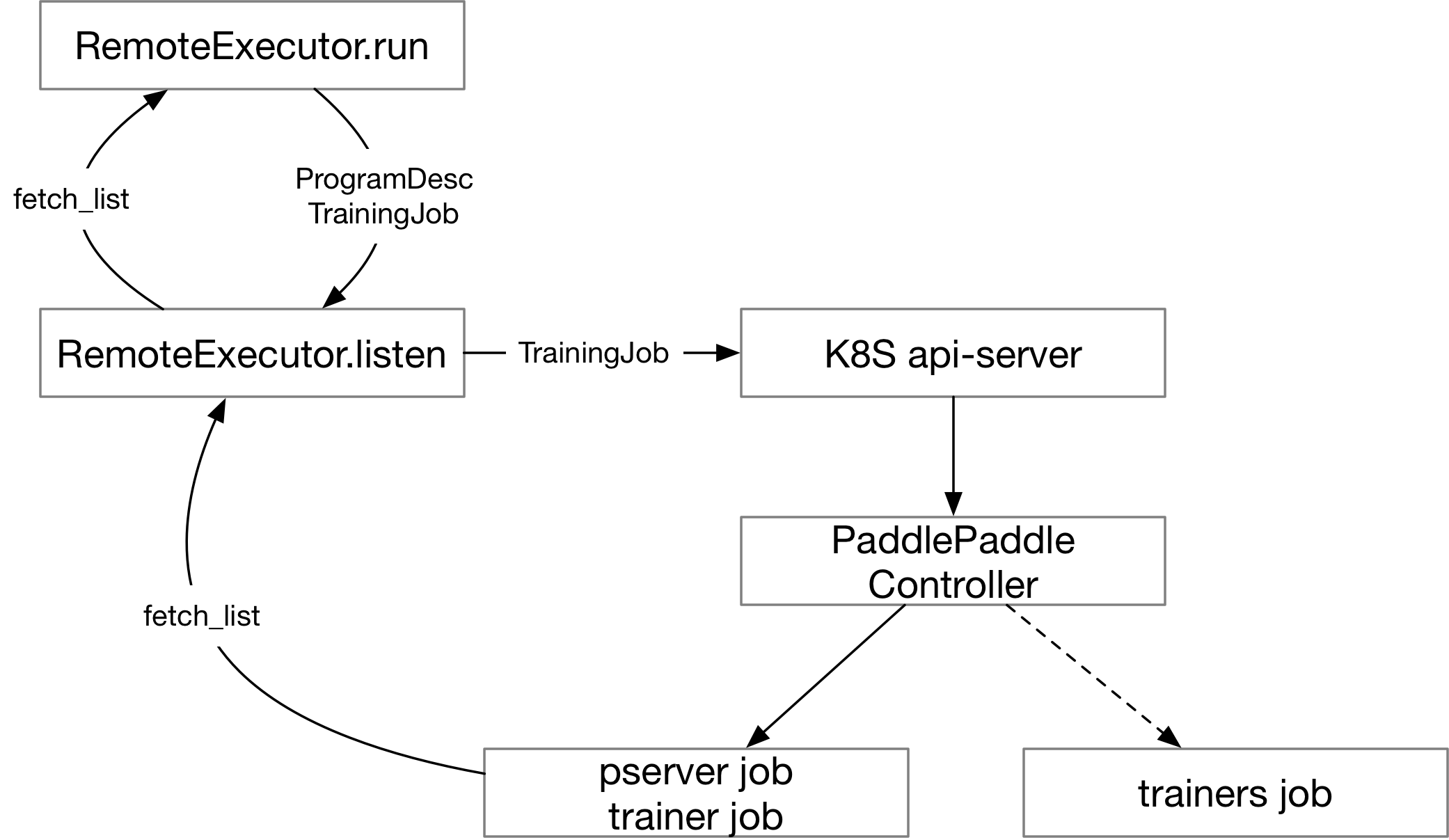
134.5 KB
{kind=link}
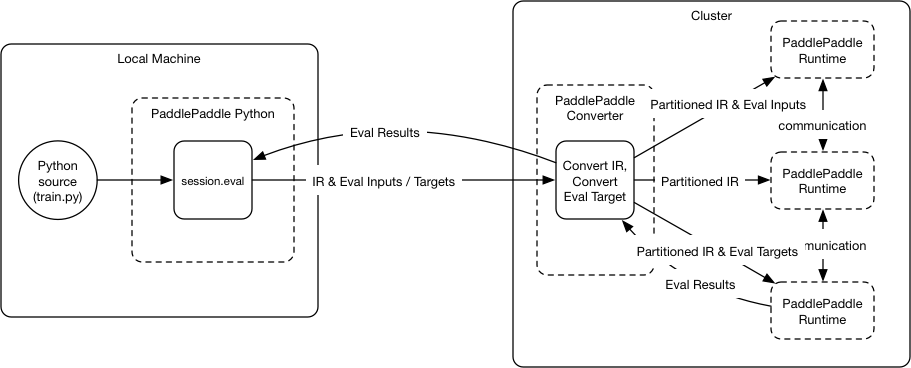
46.5 KB
文件已删除
{kind=link}
28.3 KB