Merge pull request #2081 from PaddlePaddle/release/0.10.0
Release/0.10.0
Showing
.dockerignore
0 → 100644
CONTRIBUTING.md
0 → 100644
Dockerfile
0 → 100644
RELEASE.cn.md
0 → 100755
benchmark/.gitignore
0 → 100644
benchmark/README.md
0 → 100644
此差异已折叠。
benchmark/caffe/image/run.sh
0 → 100755
benchmark/figs/alexnet-4gpu.png
0 → 100644
{kind=link}
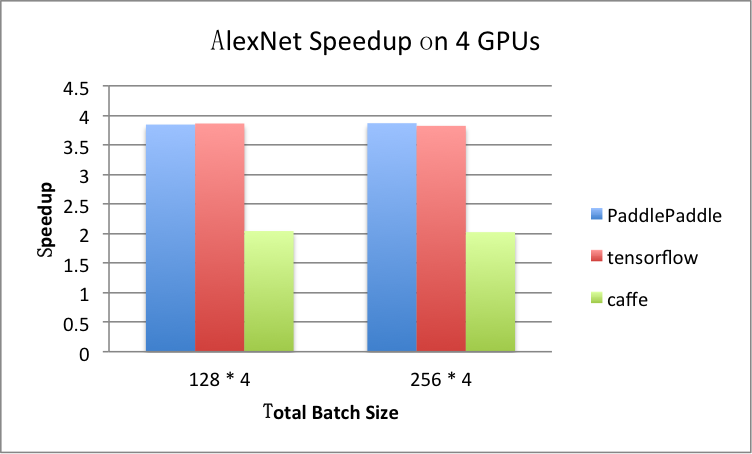
81.8 KB
benchmark/figs/googlenet-4gpu.png
0 → 100644
{kind=link}
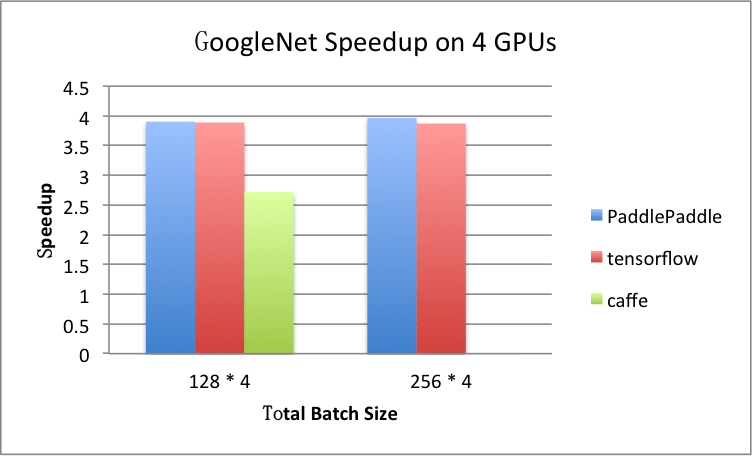
81.8 KB
benchmark/figs/rnn_lstm_4gpus.png
0 → 100644
{kind=link}
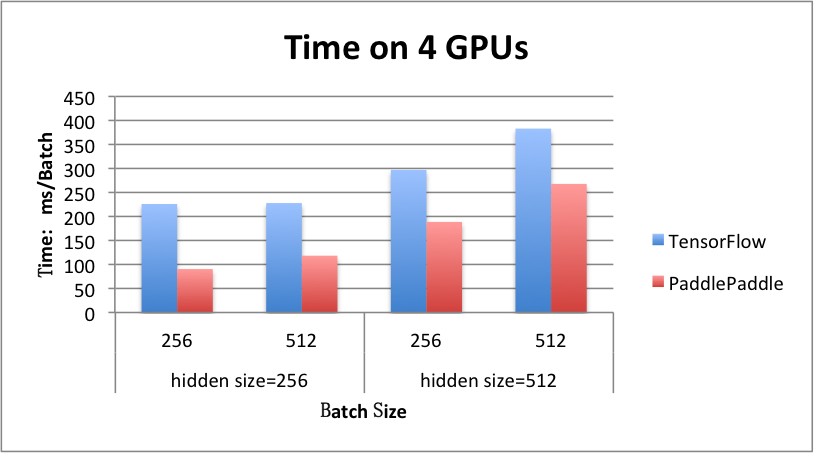
71.5 KB
benchmark/figs/rnn_lstm_cls.png
0 → 100644
{kind=link}
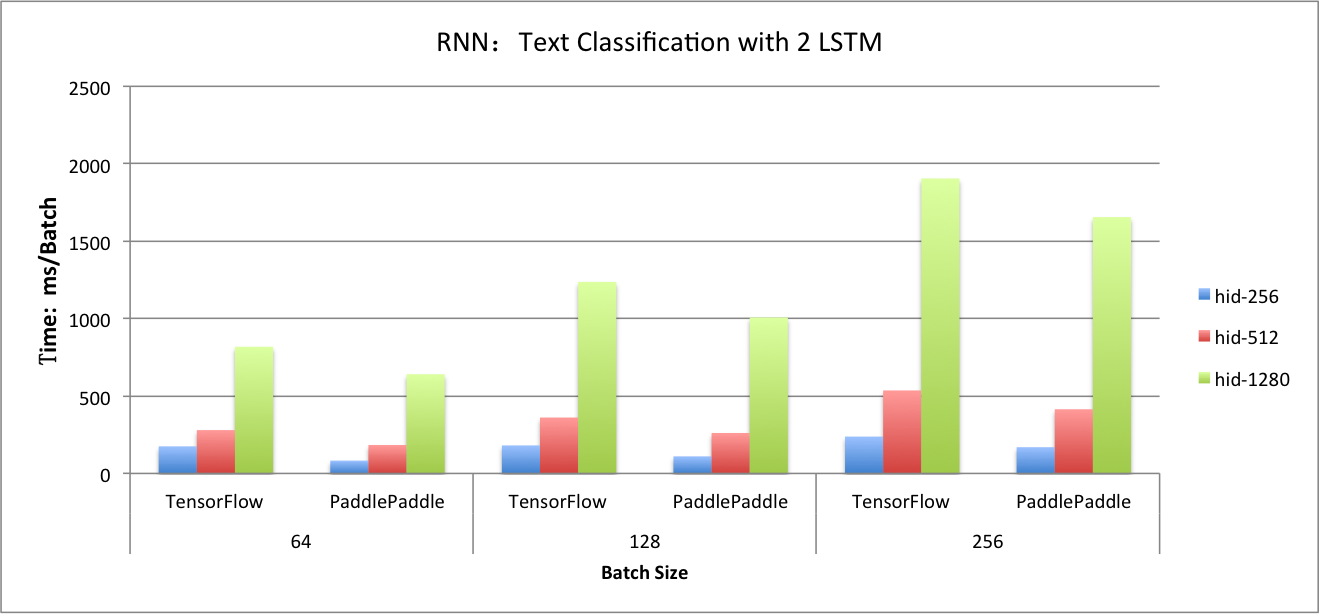
114.9 KB
benchmark/paddle/image/alexnet.py
0 → 100644
benchmark/paddle/image/run.sh
0 → 100755
benchmark/paddle/rnn/imdb.py
0 → 100755
benchmark/paddle/rnn/provider.py
0 → 100644
benchmark/paddle/rnn/rnn.py
0 → 100755
benchmark/paddle/rnn/run.sh
0 → 100755
此差异已折叠。
此差异已折叠。
此差异已折叠。
benchmark/tensorflow/image/run.sh
0 → 100755
此差异已折叠。
此差异已折叠。
benchmark/tensorflow/rnn/rnn.py
0 → 100755
此差异已折叠。
此差异已折叠。
benchmark/tensorflow/rnn/run.sh
0 → 100755
此差异已折叠。
此差异已折叠。
cmake/check_packages.cmake
已删除
100644 → 0
此差异已折叠。
cmake/configure.cmake
0 → 100644
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
cmake/enableCXX11.cmake
已删除
100644 → 0
此差异已折叠。
cmake/external/any.cmake
0 → 100644
此差异已折叠。
cmake/external/gflags.cmake
0 → 100644
此差异已折叠。
cmake/external/glog.cmake
0 → 100644
此差异已折叠。
cmake/external/gtest.cmake
0 → 100644
此差异已折叠。
cmake/external/openblas.cmake
0 → 100644
此差异已折叠。
cmake/external/protobuf.cmake
0 → 100644
此差异已折叠。
cmake/external/python.cmake
0 → 100644
此差异已折叠。
cmake/external/swig.cmake
0 → 100644
此差异已折叠。
cmake/external/warpctc.cmake
0 → 100644
此差异已折叠。
cmake/external/zlib.cmake
0 → 100644
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
cmake/swig.cmake
已删除
100644 → 0
此差异已折叠。
cmake/system.cmake
0 → 100644
此差异已折叠。
此差异已折叠。
cmake/version.cmake
0 → 100644
此差异已折叠。
demo/gan/.gitignore
0 → 100644
此差异已折叠。
demo/gan/README.md
0 → 100644
此差异已折叠。
demo/gan/data/download_cifar.sh
0 → 100755
此差异已折叠。
demo/gan/data/get_mnist_data.sh
0 → 100755
此差异已折叠。
demo/gan/gan_conf.py
0 → 100644
此差异已折叠。
demo/gan/gan_conf_image.py
0 → 100644
此差异已折叠。
demo/gan/gan_trainer.py
0 → 100644
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
demo/image_classification/predict.sh
100644 → 100755
此差异已折叠。
demo/introduction/.gitignore
0 → 100644
此差异已折叠。
demo/introduction/api_train_v2.py
0 → 100644
此差异已折叠。
此差异已折叠。
demo/mnist/api_train.py
0 → 100644
此差异已折叠。
demo/mnist/api_train_v2.py
0 → 100644
此差异已折叠。
demo/mnist/mnist_util.py
0 → 100644
此差异已折叠。
此差异已折叠。
demo/quick_start/api_predict.py
0 → 100755
此差异已折叠。
demo/quick_start/api_predict.sh
0 → 100755
此差异已折叠。
此差异已折叠。
demo/quick_start/cluster/env.sh
0 → 100644
此差异已折叠。
此差异已折叠。
demo/quick_start/data/README.md
0 → 100644
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
demo/recommendation/evaluate.py
0 → 100755
此差异已折叠。
此差异已折叠。
demo/semantic_role_labeling/data/get_data.sh
100644 → 100755
此差异已折叠。
demo/semantic_role_labeling/predict.sh
100644 → 100755
此差异已折叠。
demo/semantic_role_labeling/test.sh
100644 → 100755
此差异已折叠。
demo/semantic_role_labeling/train.sh
100644 → 100755
此差异已折叠。
demo/sentiment/train_v2.py
0 → 100644
此差异已折叠。
demo/seqToseq/api_train_v2.py
0 → 100644
此差异已折叠。
demo/traffic_prediction/README
0 → 100644
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
demo/traffic_prediction/train.sh
0 → 100755
此差异已折叠。
此差异已折叠。
demo/word2vec/train_v2.py
0 → 100644
此差异已折叠。
此差异已折叠。
doc/Doxyfile.in
已删除
100644 → 0
此差异已折叠。
doc/about/index_cn.md
0 → 100644
此差异已折叠。
doc/about/index_en.rst
0 → 100644
此差异已折叠。
doc/algorithm/rnn/bi_lstm.jpg
已删除
120000 → 0
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
doc/api/index_cn.rst
0 → 100644
此差异已折叠。
doc/api/index_en.rst
0 → 100644
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
文件已移动
文件已移动
文件已移动
此差异已折叠。
文件已移动
doc/api/v1/index_cn.rst
0 → 100644
此差异已折叠。
doc/api/v1/index_en.rst
0 → 100644
此差异已折叠。
此差异已折叠。
此差异已折叠。
文件已移动
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
文件已移动
doc/api/v2/config/activation.rst
0 → 100644
此差异已折叠。
doc/api/v2/config/attr.rst
0 → 100644
此差异已折叠。
doc/api/v2/config/layer.rst
0 → 100644
此差异已折叠。
doc/api/v2/config/networks.rst
0 → 100644
此差异已折叠。
doc/api/v2/config/optimizer.rst
0 → 100644
此差异已折叠。
doc/api/v2/config/pooling.rst
0 → 100644
此差异已折叠。
doc/api/v2/data.rst
0 → 100644
此差异已折叠。
doc/api/v2/model_configs.rst
0 → 100644
此差异已折叠。
doc/api/v2/run_logic.rst
0 → 100644
此差异已折叠。
doc/build/docker_install.rst
已删除
100644 → 0
此差异已折叠。
doc/cluster/index.rst
已删除
100644 → 0
此差异已折叠。
此差异已折叠。
doc/demo/index.md
已删除
100644 → 0
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
doc/design/api.md
0 → 100644
此差异已折叠。
doc/design/dist/README.md
0 → 100644
此差异已折叠。
此差异已折叠。
{kind=link}
此差异已折叠。
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
此差异已折叠。
此差异已折叠。
{kind=link}
此差异已折叠。
此差异已折叠。
{kind=link}
此差异已折叠。
此差异已折叠。
doc/design/reader/README.md
0 → 100644
此差异已折叠。
doc/dev/new_layer/index.rst
已删除
100644 → 0
此差异已折叠。
此差异已折叠。
{kind=link}
文件已移动
此差异已折叠。
{kind=link}
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
文件已移动
此差异已折叠。
此差异已折叠。
doc/getstarted/index_cn.rst
0 → 100644
此差异已折叠。
doc/getstarted/index_en.rst
0 → 100644
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
{kind=link}
此差异已折叠。
此差异已折叠。
doc/howto/dev/new_layer_cn.rst
0 → 100644
此差异已折叠。
doc/howto/index_cn.rst
0 → 100644
此差异已折叠。
doc/howto/index_en.rst
0 → 100644
此差异已折叠。
此差异已折叠。
此差异已折叠。
doc/howto/optimization/nvvp1.png
0 → 100644
{kind=link}
此差异已折叠。
doc/howto/optimization/nvvp2.png
0 → 100644
{kind=link}
此差异已折叠。
doc/howto/optimization/nvvp3.png
0 → 100644
{kind=link}
此差异已折叠。
doc/howto/optimization/nvvp4.png
0 → 100644
{kind=link}
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
doc/howto/usage/k8s/k8s_aws_en.md
0 → 100644
此差异已折叠。
此差异已折叠。
doc/howto/usage/k8s/k8s_cn.md
0 → 100644
此差异已折叠。
此差异已折叠。
doc/howto/usage/k8s/k8s_en.md
0 → 100644
此差异已折叠。
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
doc/index.md
已删除
100644 → 0
此差异已折叠。
doc/index_cn.rst
0 → 100644
此差异已折叠。
doc/index_en.rst
0 → 100644
此差异已折叠。
{kind=link}
此差异已折叠。
doc/layer.md
已删除
100644 → 0
此差异已折叠。
doc/source/api/api.rst
已删除
100644 → 0
此差异已折叠。
doc/source/cuda/cuda/cuda.rst
已删除
100644 → 0
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
doc/source/cuda/rnn/index.rst
已删除
100644 → 0
此差异已折叠。
doc/source/cuda/rnn/rnn.rst
已删除
100644 → 0
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
doc/source/index.md
已删除
100644 → 0
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
doc/source/utils/enum.rst
已删除
100644 → 0
此差异已折叠。
doc/source/utils/lock.rst
已删除
100644 → 0
此差异已折叠。
doc/source/utils/queue.rst
已删除
100644 → 0
此差异已折叠。
doc/source/utils/thread.rst
已删除
100644 → 0
此差异已折叠。
此差异已折叠。
此差异已折叠。
{kind=link}
文件已移动
doc/tutorials/gan/gan.png
0 → 100644
{kind=link}
此差异已折叠。
doc/tutorials/gan/index_en.md
0 → 100644
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
文件已移动
{kind=link}
文件已移动
此差异已折叠。
此差异已折叠。
{kind=link}
文件已移动
{kind=link}
文件已移动
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
文件已移动
此差异已折叠。
此差异已折叠。
doc/tutorials/index_cn.md
0 → 100644
此差异已折叠。
doc/tutorials/index_en.md
0 → 100644
此差异已折叠。
此差异已折叠。
{kind=link}
文件已移动
{kind=link}
文件已移动
{kind=link}
文件已移动
{kind=link}
文件已移动
{kind=link}
文件已移动
{kind=link}
文件已移动
{kind=link}
文件已移动
{kind=link}
文件已移动
{kind=link}
文件已移动
{kind=link}
文件已移动
{kind=link}
文件已移动
{kind=link}
文件已移动
{kind=link}
文件已移动
{kind=link}
文件已移动
{kind=link}
文件已移动
{kind=link}
文件已移动
此差异已折叠。
此差异已折叠。
{kind=link}
文件已移动
{kind=link}
文件已移动
此差异已折叠。
此差异已折叠。
{kind=link}
文件已移动
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
文件已移动
此差异已折叠。
此差异已折叠。
{kind=link}
文件已移动
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
文件已移动
{kind=link}
此差异已折叠。
{kind=link}
文件已移动
此差异已折叠。
此差异已折叠。
此差异已折叠。
doc/ui/index.md
已删除
100644 → 0
此差异已折叠。
doc_cn/CMakeLists.txt
已删除
100644 → 0
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
doc_cn/cluster/index.rst
已删除
100644 → 0
此差异已折叠。
doc_cn/concepts/nn.rst
已删除
100644 → 0
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
doc_cn/demo/index.rst
已删除
100644 → 0
此差异已折叠。
此差异已折叠。
doc_cn/index.rst
已删除
100644 → 0
此差异已折叠。
doc_cn/introduction/index.md
已删除
100644 → 0
此差异已折叠。
doc_cn/ui/cmd/index.rst
已删除
100644 → 0
此差异已折叠。
doc_cn/ui/cmd/merge_model.rst
已删除
100644 → 0
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
doc_cn/ui/index.rst
已删除
100644 → 0
此差异已折叠。
此差异已折叠。
doc_theme/static/css/override.css
0 → 100644
此差异已折叠。
doc_theme/static/images/PP_w.png
0 → 100644
{kind=link}
此差异已折叠。
此差异已折叠。
此差异已折叠。
doc_theme/templates/layout.html
0 → 100644
此差异已折叠。
doc_theme/templates/search.html
0 → 100644
此差异已折叠。
此差异已折叠。
此差异已折叠。
paddle/api/Evaluator.cpp
0 → 100644
此差异已折叠。
此差异已折叠。
此差异已折叠。
paddle/api/ParameterUpdater.cpp
0 → 100644
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
paddle/api/paddle_ld_flags.py
已删除
100644 → 0
此差异已折叠。
paddle/api/test/.gitignore
0 → 100644
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
paddle/function/BufferArg.cpp
0 → 100644
此差异已折叠。
paddle/function/BufferArg.h
0 → 100644
此差异已折叠。
paddle/function/BufferArgTest.cpp
0 → 100644
此差异已折叠。
paddle/function/CMakeLists.txt
0 → 100644
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
paddle/function/CosSimOp.cpp
0 → 100644
此差异已折叠。
paddle/function/CosSimOp.h
0 → 100644
此差异已折叠。
paddle/function/CosSimOpGpu.cu
0 → 100644
此差异已折叠。
paddle/function/CosSimOpTest.cpp
0 → 100644
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
paddle/function/Function.cpp
0 → 100644
此差异已折叠。
paddle/function/Function.h
0 → 100644
此差异已折叠。
paddle/function/FunctionTest.cpp
0 → 100644
此差异已折叠。
paddle/function/FunctionTest.h
0 → 100644
此差异已折叠。
paddle/function/MulOp.cpp
0 → 100644
此差异已折叠。
paddle/function/MulOp.h
0 → 100644
此差异已折叠。
paddle/function/MulOpGpu.cu
0 → 100644
此差异已折叠。
paddle/function/MulOpTest.cpp
0 → 100644
此差异已折叠。
paddle/function/PadOp.cpp
0 → 100644
此差异已折叠。
paddle/function/PadOp.h
0 → 100644
此差异已折叠。
paddle/function/PadOpGpu.cu
0 → 100644
此差异已折叠。
paddle/function/PadOpTest.cpp
0 → 100644
此差异已折叠。
paddle/function/TensorShape.h
0 → 100644
此差异已折叠。
此差异已折叠。
paddle/function/TensorType.h
0 → 100644
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
paddle/gserver/layers/PadLayer.h
0 → 100644
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
paddle/math/RowBuffer.h
0 → 100644
此差异已折叠。
此差异已折叠。
paddle/math/TensorApply.h
0 → 100644
此差异已折叠。
paddle/math/TensorAssign.h
0 → 100644
此差异已折叠。
paddle/math/TensorEvaluate.h
0 → 100644
此差异已折叠。
paddle/math/TensorExpression.h
0 → 100644
此差异已折叠。
此差异已折叠。
paddle/math/TrainingAlgorithmOp.h
0 → 100644
此差异已折叠。
此差异已折叠。
此差异已折叠。
paddle/math/tests/PerfUtils.h
0 → 100644
此差异已折叠。
paddle/math/tests/TensorCheck.h
0 → 100644
此差异已折叠。
paddle/math/tests/TestUtils.h
0 → 100644
此差异已折叠。
此差异已折叠。
此差异已折叠。
paddle/math/tests/test_Matrix.cpp
0 → 100644
此差异已折叠。
此差异已折叠。
paddle/math/tests/test_Tensor.cu
0 → 100644
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。