Skip to content
体验新版
项目
组织
正在加载...
登录
切换导航
打开侧边栏
月凉、
JavaGuide
提交
2c1d1704
J
JavaGuide
项目概览
月凉、
/
JavaGuide
与 Fork 源项目一致
从无法访问的项目Fork
通知
1
Star
1
Fork
0
代码
文件
提交
分支
Tags
贡献者
分支图
Diff
Issue
1
列表
看板
标记
里程碑
合并请求
0
Wiki
0
Wiki
分析
仓库
DevOps
项目成员
Pages
J
JavaGuide
项目概览
项目概览
详情
发布
仓库
仓库
文件
提交
分支
标签
贡献者
分支图
比较
Issue
1
Issue
1
列表
看板
标记
里程碑
合并请求
0
合并请求
0
Pages
分析
分析
仓库分析
DevOps
Wiki
0
Wiki
成员
成员
收起侧边栏
关闭侧边栏
动态
分支图
创建新Issue
提交
Issue看板
体验新版 GitCode,发现更多精彩内容 >>
提交
2c1d1704
编写于
9月 23, 2021
作者:
G
guide
浏览文件
操作
浏览文件
下载
电子邮件补丁
差异文件
[feat]Java内存区域内容完善补充
上级
1bbe22b1
变更
1
隐藏空白更改
内联
并排
Showing
1 changed file
with
211 addition
and
79 deletion
+211
-79
docs/java/jvm/Java内存区域.md
docs/java/jvm/Java内存区域.md
+211
-79
未找到文件。
docs/java/jvm/Java内存区域.md
浏览文件 @
2c1d1704
...
...
@@ -217,7 +217,7 @@ JDK 1.8 的时候,方法区(HotSpot 的永久代)被彻底移除了(JDK1

1.
整个永久代有一个 JVM 本身设置的固定大小上限,无法进行调整,而元空间使用的是直接内存,受本机可用内存的限制,虽然元空间仍旧可能溢出,但是比原来出现的几率会更小。
> 当元空间溢出时会得到如下错误: `java.lang.OutOfMemoryError: MetaSpace`
你可以使用
`-XX:MaxMetaspaceSize`
标志设置最大元空间大小,默认值为 unlimited,这意味着它只受系统内存的限制。
`-XX:MetaspaceSize`
调整标志定义元空间的初始大小如果未指定此标志,则 Metaspace 将根据运行时的应用程序需求动态地重新调整大小。
...
...
@@ -318,66 +318,183 @@ JDK1.4 中新加入的 **NIO(New Input/Output) 类**,引入了一种基于**
## 四 重点补充内容
### 4.1 String 类和常量池
### 4.1 字符串常量池常见问题
我们先来看一个非常常见的面试题:
**String 类型的变量和常量做“+”运算时发生了什么?**
。
**String 对象的两种创建方式:**
先来看字符串不加
`final`
关键字拼接的情况(JDK1.8):
```
java
String
str1
=
"abcd"
;
//先检查字符串常量池中有没有"abcd",如果字符串常量池中没有,则创建一个,然后 str1 指向字符串常量池中的对象,如果有,则直接将 str1 指向"abcd"";
String
str2
=
new
String
(
"abcd"
);
//堆中创建一个新的对象
String
str3
=
new
String
(
"abcd"
);
//堆中创建一个新的对象
System
.
out
.
println
(
str1
==
str2
);
//false
System
.
out
.
println
(
str2
==
str3
);
//false
String
str1
=
"str"
;
String
str2
=
"ing"
;
String
str3
=
"str"
+
"ing"
;
//常量池中的对象
String
str4
=
str1
+
str2
;
//在堆上创建的新的对象
String
str5
=
"string"
;
//常量池中的对象
System
.
out
.
println
(
str3
==
str4
);
//false
System
.
out
.
println
(
str3
==
str5
);
//true
System
.
out
.
println
(
str4
==
str5
);
//false
```
这两种不同的创建方法是有差别的
。
> **注意** :比较 String 字符串的值是否相等,可以使用 `equals()` 方法。 `String` 中的 `equals` 方法是被重写过的。 `Object` 的 `equals` 方法是比较的对象的内存地址,而 `String` 的 `equals` 方法比较的是字符串的值是否相等。如果你使用 `==` 比较两个字符串是否相等的话,IDEA 还是提示你使用 `equals()` 方法替换
。
-
第一种方式是在常量池中拿对象;
-
第二种方式是直接在堆内存空间创建一个新的对象。
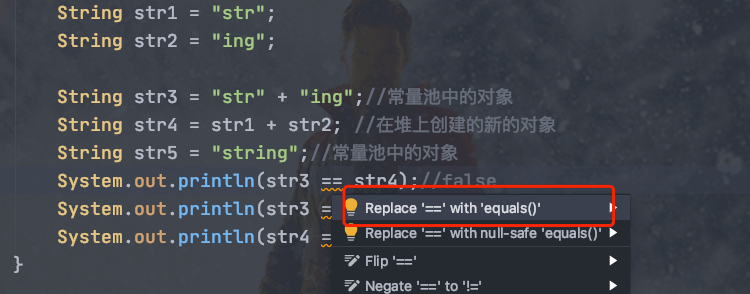
记住一点:
**只要使用 new 方法,便需要创建新的对象。**
> 对于基本数据类型来说,== 比较的是值。对于引用数据类型来说,==比较的是对象的内存地址。
再给大家一个图应该更容易理解,图片来源:
<https://www.journaldev.com/797/what-is-java-string-pool>
:
对于编译期可以确定值的字符串,也就是常量字符串 ,jvm 会将其存入字符串常量池。

> **字符串常量池** 是 JVM 为了提升性能和减少内存消耗针为字符串(String 类)专门开辟的一块区域,主要目的是为了避免字符串的重复创建。
>
> ```java
> String aa = "ab"; // 放在常量池中
> String bb = "ab"; // 从常量池中查找
> System.out.println("aa==bb");// true
> ```
>
> JDK1.7 之前运行时常量池逻辑包含字符串常量池存放在方法区。JDK1.7 的时候,字符串常量池被从方法区拿到了堆中。
**String 类型的常量池比较特殊。它的主要使用方法有两种:**
并且,字符串常量拼接得到的字符串常量在编译阶段就已经被存放字符串常量池,这个得益于编译器的优化。
1.
直接使用双引号声明出来的 String 对象会直接存储在常量池中。
2.
如果不是用双引号声明的 String 对象,可以使用 String 提供的
`intern()`
方法。
`String.intern()`
是一个 Native 方法,它的作用是:如果运行时常量池中已经包含一个等于此 String 对象内容的字符串,则返回常量池中该字符串的引用;如果没有,JDK1.7 之前(不包含 1.7)的处理方式是在常量池中创建与此 String 内容相同的字符串,并返回常量池中创建的字符串的引用,JDK1.7 以及之后的处理方式是在常量池中记录此字符串的引用,并返回该引用。
> 在编译过程中,Javac 编译器(下文中统称为编译器)会进行一个叫做 **常量折叠(Constant Folding)** 的代码优化。《深入理解 Java 虚拟机》中是也有介绍到:
>
> 
>
> 常量折叠会把常量表达式的值求出来作为常量嵌在最终生成的代码中,这是 Javac 编译器会对源代码做的极少量优化措施之一(代码优化几乎都在即时编译器中进行)。
>
> 对于 `String str3 = "str" + "ing";` 编译器会给你优化成 `String str3 = "string";` 。
>
> 并不是所有的常量都会进行折叠,只有编译器在程序编译期就可以确定值的常量才可以:
>
> 1. 基本数据类型(byte、boolean、short、char、int、float、long、double)以及字符串常量
> 2. `final` 修饰的基本数据类型和字符串变量
> 3. 字符串通过 “+”拼接得到的字符串、基本数据类型之间算数运算(加减乘除)、基本数据类型的位运算(<<、\>>、\>>> )
因此,
`str1`
、
`str2`
、
`str3`
都属于字符串常量池中的对象。
引用的值在程序编译期是无法确定的,编译器无法对其进行优化。
JDK8 :
对象引用和“+”的字符串拼接方式,实际上是通过
`StringBuilder`
调用
`append()`
方法实现的,拼接完成之后调用
`toString()`
得到一个
`String`
对象 。
```
java
String
s1
=
"计算机"
;
String
s2
=
s1
.
intern
();
String
s3
=
"计算机"
;
System
.
out
.
println
(
s2
);
//计算机
System
.
out
.
println
(
s1
==
s2
);
//true
System
.
out
.
println
(
s3
==
s2
);
//true,因为两个都是常量池中的 String 对象
String
str4
=
new
StringBuilder
().
append
(
str1
).
append
(
str2
).
toString
();
```
**字符串拼接:**
因此,
`str4`
并不是字符串常量池中存在的对象,属于堆上的新对象。
我画了一个图帮助理解:

我们在平时写代码的时候,尽量避免多个字符串对象拼接,因为这样会重新创建对象。如果需要改变字符串的话,可以使用
`StringBuilder`
或者
`StringBuffer`
。
不过,字符串使用
`final`
关键字声明之后,可以让编译器当做常量来处理。
```
java
String
str1
=
"str"
;
String
str2
=
"ing"
;
final
String
str1
=
"str"
;
final
String
str2
=
"ing"
;
// 下面两个表达式其实是等价的
String
c
=
"str"
+
"str2"
;
// 常量池中的对象
String
d
=
str1
+
str2
;
// 常量池中的对象
System
.
out
.
println
(
c
==
d
);
// true
```
String
str3
=
"str"
+
"ing"
;
//常量池中的对象
String
str4
=
str1
+
str2
;
//在堆上创建的新的对象
String
str5
=
"string"
;
//常量池中的对象
System
.
out
.
println
(
str3
==
str4
);
//false
System
.
out
.
println
(
str3
==
str5
);
//true
System
.
out
.
println
(
str4
==
str5
);
//false
被
`final`
关键字修改之后的
`String`
会被编译器当做常量来处理,编译器在程序编译期就可以确定它的值,其效果就想到于访问常量。
如果 ,编译器在运行时才能知道其确切值的话,就无法对其优化。
示例代码如下(
`str2`
在运行时才能确定其值):
```
java
final
String
str1
=
"str"
;
final
String
str2
=
getStr
();
String
c
=
"str"
+
"str2"
;
// 常量池中的对象
String
d
=
str1
+
str2
;
// 常量池中的对象
System
.
out
.
println
(
c
==
d
);
// false
public
static
String
getStr
()
{
return
"ing"
;
}
```
**我们再来看一个类似的问题!**
```
java
String
str1
=
"abcd"
;
String
str2
=
new
String
(
"abcd"
);
String
str3
=
new
String
(
"abcd"
);
System
.
out
.
println
(
str1
==
str2
);
System
.
out
.
println
(
str2
==
str3
);
```
上面的代码运行之后会输出什么呢?
答案是:
```
false
false
```
**这是为什么呢?**
我们先来看下面这种创建字符串对象的方式:
```
java
// 从字符串常量池中拿对象
String
str1
=
"abcd"
;
```
这种情况下,jvm 会先检查字符串常量池中有没有"abcd",如果字符串常量池中没有,则创建一个,然后 str1 指向字符串常量池中的对象,如果有,则直接将 str1 指向"abcd"";
因此,
`str1`
指向的是字符串常量池的对象。
我们再来看下面这种创建字符串对象的方式:
```
java
// 直接在堆内存空间创建一个新的对象。
String
str2
=
new
String
(
"abcd"
);
String
str3
=
new
String
(
"abcd"
);
```

**只要使用 new 的方式创建对象,便需要创建新的对象**
。
尽量避免多个字符串拼接,因为这样会重新创建对象。如果需要改变字符串的话,可以使用 StringBuilder 或者 StringBuffer。
使用 new 的方式创建对象的方式如下,可以简单概括为 3 步:
1.
在堆中创建一个字符串对象
2.
检查字符串常量池中是否有和 new 的字符串值相等的字符串常量
3.
如果没有的话需要在字符串常量池中也创建一个值相等的字符串常量,如果有的话,就直接返回堆中的字符串实例对象地址。
因此,
`str2`
和
`str3`
都是在堆中新创建的对象。
**字符串常量池比较特殊,它的主要使用方法有两种:**
1.
直接使用双引号声明出来的
`String`
对象会直接存储在常量池中。
2.
如果不是用双引号声明的
`String`
对象,使用
`String`
提供的
`intern()`
方法也有同样的效果。
`String.intern()`
是一个 Native 方法,它的作用是:如果运行时常量池中已经包含一个等于此 String 对象内容的字符串,则返回常量池中该字符串的引用;如果没有,JDK1.7 之前(不包含 1.7)的处理方式是在常量池中创建与此
`String`
内容相同的字符串,并返回常量池中创建的字符串的引用,JDK1.7 以及之后,字符串常量池被从方法区拿到了堆中,jvm 不会在常量池中创建该对象,而是将堆中这个对象的引用直接放到常量池中,减少不必要的内存开销。
示例代码如下(JDK 1.8) :
```
java
String
s1
=
"Javatpoint"
;
String
s2
=
s1
.
intern
();
String
s3
=
new
String
(
"Javatpoint"
);
String
s4
=
s3
.
intern
();
System
.
out
.
println
(
s1
==
s2
);
// True
System
.
out
.
println
(
s1
==
s3
);
// False
System
.
out
.
println
(
s1
==
s4
);
// True
System
.
out
.
println
(
s2
==
s3
);
// False
System
.
out
.
println
(
s2
==
s4
);
// True
System
.
out
.
println
(
s3
==
s4
);
// False
```
**总结**
:
1.
对于基本数据类型来说,==比较的是值。对于引用数据类型来说,==比较的是对象的内存地址。
2.
在编译过程中,Javac 编译器(下文中统称为编译器)会进行一个叫做
**常量折叠(Constant Folding)**
的代码优化。常量折叠会把常量表达式的值求出来作为常量嵌在最终生成的代码中,这是 Javac 编译器会对源代码做的极少量优化措施之一(代码优化几乎都在即时编译器中进行)。
3.
一般来说,我们要尽量避免通过 new 的方式创建字符串。使用双引号声明的
`String`
对象(
`String s1 = "java"`
)更利于让编译器有机会优化我们的代码,同时也更易于阅读。
4.
被
`final`
关键字修改之后的
`String`
会被编译器当做常量来处理,编译器程序编译期就可以确定它的值,其效果就想到于访问常量。
### 4.2 String s1 = new String("abc");这句话创建了几个字符串对象?
**将创建 1 或 2 个字符串。如果池中已存在字符串常量“abc”,则只会在堆空间创建一个字符串常量“abc”。如果池中没有字符串常量“abc”,那么它将首先在池中创建,然后在堆空间中创建,因此将创建总共 2 个字符串对象。**
将创建 1 或 2 个字符串。如果池中已存在字符串常量“abc”,则只会在堆空间创建一个字符串常量“abc”。如果池中没有字符串常量“abc”,那么它将首先在池中创建,然后在堆空间中创建,因此将创建总共 2 个字符串对象。
**验证:**
...
...
@@ -397,27 +514,11 @@ true
### 4.3 8 种基本类型的包装类和常量池
**Java 基本类型的包装类的大部分都实现了常量池技术,即 Byte,Short,Integer,Long,Character,Boolean;前面 4 种包装类默认创建了数值[-128,127] 的相应类型的缓存数据,Character 创建了数值在[0,127]范围的缓存数据,Boolean 直接返回 True Or False。如果超出对应范围仍然会去创建新的对象。**
为啥把缓存设置为
[
-128,127]区间?([参见 issue/461
](
https://github.com/Snailclimb/JavaGuide/issues/461
)
)性能和资源之间的权衡。
```
java
public
static
Boolean
valueOf
(
boolean
b
)
{
return
(
b
?
TRUE
:
FALSE
);
}
```
```
java
private
static
class
CharacterCache
{
private
CharacterCache
(){}
Java 基本类型的包装类的大部分都实现了常量池技术。
static
final
Character
cache
[]
=
new
Character
[
127
+
1
];
static
{
for
(
int
i
=
0
;
i
<
cache
.
length
;
i
++)
cache
[
i
]
=
new
Character
((
char
)
i
);
}
}
```
`Byte`
,
`Short`
,
`Integer`
,
`Long`
这 4 种包装类默认创建了数值
**[-128,127]**
的相应类型的缓存数据,
`Character`
创建了数值在
**[0,127]**
范围的缓存数据,
`Boolean`
直接返回
`True`
Or
`False`
。
两种浮点数类型的包装类
Float,Double
并没有实现常量池技术。
两种浮点数类型的包装类
`Float`
,
`Double`
并没有实现常量池技术。
```
java
Integer
i1
=
33
;
...
...
@@ -439,22 +540,63 @@ System.out.println(i3 == i4);// 输出 false
*/
public
static
Integer
valueOf
(
int
i
)
{
if
(
i
>=
IntegerCache
.
low
&&
i
<=
IntegerCache
.
high
)
return
IntegerCache
.
cache
[
i
+
(-
IntegerCache
.
low
)];
return
IntegerCache
.
cache
[
i
+
(-
IntegerCache
.
low
)];
return
new
Integer
(
i
);
}
private
static
class
IntegerCache
{
static
final
int
low
=
-
128
;
static
final
int
high
;
static
final
Integer
cache
[];
}
```
**`Character` 缓存源码:**
```
java
public
static
Character
valueOf
(
char
c
)
{
if
(
c
<=
127
)
{
// must cache
return
CharacterCache
.
cache
[(
int
)
c
];
}
return
new
Character
(
c
);
}
private
static
class
CharacterCache
{
private
CharacterCache
(){}
static
final
Character
cache
[]
=
new
Character
[
127
+
1
];
static
{
for
(
int
i
=
0
;
i
<
cache
.
length
;
i
++)
cache
[
i
]
=
new
Character
((
char
)
i
);
}
}
```
**
应用场景
:**
**
`Boolean` 缓存源码
:**
1.
Integer i1=40;Java 在编译的时候会直接将代码封装成 Integer i1=Integer.valueOf(40);,从而使用常量池中的对象。
2.
Integer i1 = new Integer(40);这种情况下会创建新的对象。
```
java
public
static
Boolean
valueOf
(
boolean
b
)
{
return
(
b
?
TRUE
:
FALSE
);
}
```
如果超出对应范围仍然会去创建新的对象,缓存的范围区间的大小只是在性能和资源之间的权衡。
下面我们来看一下问题。下面的代码的输出结果是
`true`
还是
`flase`
呢?
```
java
Integer
i1
=
40
;
Integer
i2
=
new
Integer
(
40
);
System
.
out
.
println
(
i1
==
i2
);
//输出 false
System
.
out
.
println
(
i1
==
i2
);
```
`Integer i1=40`
这一行代码会发生拆箱,也就是说这行代码等价于
`Integer i1=Integer.valueOf(40)`
。因此,
`i1`
直接使用的是常量池中的对象。而
`Integer i1 = new Integer(40)`
会直接创建新的对象。
因此,答案是
`false`
。你答对了吗?
记住:
**所有整型包装类对象之间值的比较,全部使用 equals 方法比较**
。

**Integer 比较更丰富的一个例子:**
```
java
...
...
@@ -465,28 +607,17 @@ Integer i4 = new Integer(40);
Integer
i5
=
new
Integer
(
40
);
Integer
i6
=
new
Integer
(
0
);
System
.
out
.
println
(
"i1=i2 "
+
(
i1
==
i2
));
System
.
out
.
println
(
"i1=i2+i3 "
+
(
i1
==
i2
+
i3
));
System
.
out
.
println
(
"i1=i4 "
+
(
i1
==
i4
));
System
.
out
.
println
(
"i4=i5 "
+
(
i4
==
i5
));
System
.
out
.
println
(
"i4=i5+i6 "
+
(
i4
==
i5
+
i6
));
System
.
out
.
println
(
"40=i5+i6 "
+
(
40
==
i5
+
i6
));
```
结果:
```
i1=i2 true
i1=i2+i3 true
i1=i4 false
i4=i5 false
i4=i5+i6 true
40=i5+i6 true
System
.
out
.
println
(
i1
==
i2
);
// true
System
.
out
.
println
(
i1
==
i2
+
i3
);
//true
System
.
out
.
println
(
i1
==
i4
);
// false
System
.
out
.
println
(
i4
==
i5
);
// false
System
.
out
.
println
(
i4
==
i5
+
i6
);
// true
System
.
out
.
println
(
40
==
i5
+
i6
);
// true
```
解释:
`i1`
,
`i2 `
,
`i3`
都是常量池中的对象,
`i4`
,
`i5`
,
`i6`
是堆中的对象。
语句 i4 == i5 + i6,因为+这个操作符不适用于 Integer 对象,首先 i5 和 i6 进行自动拆箱操作,进行数值相加,即 i4 == 40。然后 Integer 对象无法与数值进行直接比较,所以 i4 自动拆箱转为 int 值 40,最终这条语句转为 40 == 40
进行数值比较。
`i4 == i5 + i6`
为什么是 true 呢?因为,
`i5`
和
`i6`
会进行自动拆箱操作,进行数值相加,即
`i4 == 40`
。
`Integer`
对象无法与数值进行直接比较,所以
`i4`
自动拆箱转为 int 值 40,最终这条语句转为
`40 == 40`
进行数值比较。
## 参考
...
...
@@ -497,3 +628,4 @@ i4=i5+i6 true
-
<https://dzone.com/articles/jvm-permgen-%E2%80%93-where-art-thou>
-
<https://stackoverflow.com/questions/9095748/method-area-and-permgen>
-
深入解析 String#intern
<https://tech.meituan.com/2014/03/06/in-depth-understanding-string-intern.html>
-
R 大(RednaxelaFX)关于常量折叠的回答:https://www.zhihu.com/question/55976094/answer/147302764
编辑
预览
Markdown
is supported
0%
请重试
或
添加新附件
.
添加附件
取消
You are about to add
0
people
to the discussion. Proceed with caution.
先完成此消息的编辑!
取消
想要评论请
注册
或
登录