Skip to content
体验新版
项目
组织
正在加载...
登录
切换导航
打开侧边栏
别团等shy哥发育
Tensorflow Deep Learning
提交
c866cb78
T
Tensorflow Deep Learning
项目概览
别团等shy哥发育
/
Tensorflow Deep Learning
9 个月 前同步成功
通知
1
Star
1
Fork
0
代码
文件
提交
分支
Tags
贡献者
分支图
Diff
Issue
0
列表
看板
标记
里程碑
合并请求
0
DevOps
流水线
流水线任务
计划
Wiki
0
Wiki
分析
仓库
DevOps
项目成员
Pages
T
Tensorflow Deep Learning
项目概览
项目概览
详情
发布
仓库
仓库
文件
提交
分支
标签
贡献者
分支图
比较
Issue
0
Issue
0
列表
看板
标记
里程碑
合并请求
0
合并请求
0
Pages
DevOps
DevOps
流水线
流水线任务
计划
分析
分析
仓库分析
DevOps
Wiki
0
Wiki
成员
成员
收起侧边栏
关闭侧边栏
动态
分支图
创建新Issue
流水线任务
提交
Issue看板
前往新版Gitcode,体验更适合开发者的 AI 搜索 >>
提交
c866cb78
编写于
9月 04, 2022
作者:
别团等shy哥发育
浏览文件
操作
浏览文件
下载
电子邮件补丁
差异文件
RegNetX架构复现--CVPR2020
上级
be51173c
变更
4
隐藏空白更改
内联
并排
Showing
4 changed file
with
420 addition
and
37 deletion
+420
-37
图像识别/03 多分类案例 CIFAR10/CIFAR10 案例 个人实现.ipynb
图像识别/03 多分类案例 CIFAR10/CIFAR10 案例 个人实现.ipynb
+0
-0
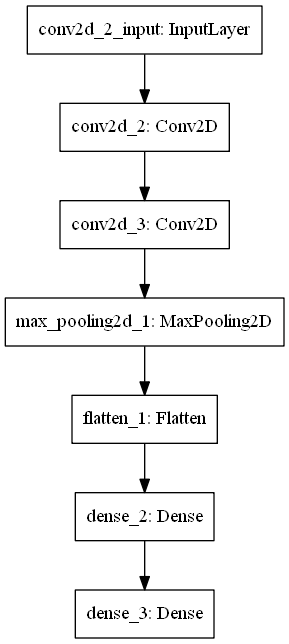
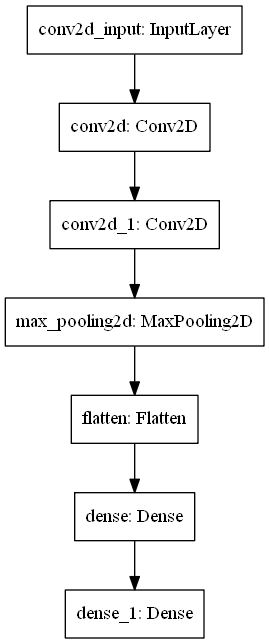
图像识别/03 多分类案例 CIFAR10/model_1.png
图像识别/03 多分类案例 CIFAR10/model_1.png
+0
-0
图像识别/adidas and nike二分类/鞋子识别.py
图像识别/adidas and nike二分类/鞋子识别.py
+52
-37
经典网络/RegNet--CVPR2020/RegNet.py
经典网络/RegNet--CVPR2020/RegNet.py
+368
-0
未找到文件。
图像识别/03 多分类案例 CIFAR10/CIFAR10 案例 个人实现.ipynb
浏览文件 @
c866cb78
因为 它太大了无法显示 source diff 。你可以改为
查看blob
。
图像识别/03 多分类案例 CIFAR10/model_1.png
查看替换文件 @
be51173c
浏览文件 @
c866cb78
12.8 KB
|
W:
|
H:
12.2 KB
|
W:
|
H:
2-up
Swipe
Onion skin
图像识别/adidas and nike二分类/鞋子识别.py
浏览文件 @
c866cb78
...
...
@@ -3,8 +3,10 @@ import tensorflow as tf
import
os
import
datetime
from
tensorflow.keras.preprocessing.image
import
ImageDataGenerator
from
tensorflow.keras.applications
import
MobileNet
from
tensorflow.keras.utils
import
to_categorical
from
tensorflow.keras.models
import
Sequential
from
tensorflow.keras
import
layers
from
tensorflow.keras.layers
import
Dense
,
Dropout
,
Conv2D
,
MaxPool2D
,
Flatten
from
tensorflow.keras.optimizers
import
Adam
# 设置GPU显存按需申请
...
...
@@ -40,7 +42,15 @@ train_datagen = ImageDataGenerator(
)
# 验证集数据只需要归一化就可以
val_datagen
=
ImageDataGenerator
(
rotation_range
=
20
,
# 随机旋转度数
width_shift_range
=
0.1
,
# 随机水平平移
height_shift_range
=
0.1
,
# 随机竖直平移
rescale
=
1
/
255
,
# 数据归一化
shear_range
=
10
,
# 随机错切变换
zoom_range
=
0.1
,
# 随机放大
horizontal_flip
=
True
,
# 水平翻转
brightness_range
=
(
0.7
,
1.3
),
# 亮度变化
fill_mode
=
'nearest'
,
# 填充方式
)
# 测试集数据只需要归一化就可以
test_datagen
=
ImageDataGenerator
(
...
...
@@ -73,27 +83,38 @@ print(train_generator.class_indices)
# # x_train,y_train=next(it)
# # y_train
# AlexNet
model
=
Sequential
()
# 卷积层
model
.
add
(
Conv2D
(
filters
=
96
,
kernel_size
=
(
11
,
11
),
strides
=
(
4
,
4
),
padding
=
'valid'
,
input_shape
=
(
image_size
,
image_size
,
3
),
activation
=
'relu'
))
model
.
add
(
MaxPool2D
(
pool_size
=
(
3
,
3
),
strides
=
(
2
,
2
),
padding
=
'valid'
))
model
.
add
(
Conv2D
(
filters
=
256
,
kernel_size
=
(
5
,
5
),
strides
=
(
1
,
1
),
padding
=
'same'
,
activation
=
'relu'
))
model
.
add
(
MaxPool2D
(
pool_size
=
(
3
,
3
),
strides
=
(
2
,
2
),
padding
=
'valid'
))
model
.
add
(
Conv2D
(
filters
=
384
,
kernel_size
=
(
3
,
3
),
strides
=
(
1
,
1
),
padding
=
'same'
,
activation
=
'relu'
))
model
.
add
(
Conv2D
(
filters
=
384
,
kernel_size
=
(
3
,
3
),
strides
=
(
1
,
1
),
padding
=
'same'
,
activation
=
'relu'
))
model
.
add
(
Conv2D
(
filters
=
256
,
kernel_size
=
(
3
,
3
),
strides
=
(
1
,
1
),
padding
=
'same'
,
activation
=
'relu'
))
model
.
add
(
MaxPool2D
(
pool_size
=
(
3
,
3
),
strides
=
(
2
,
2
),
padding
=
'valid'
))
# 全连接层
model
.
add
(
Flatten
())
model
.
add
(
Dense
(
4096
,
activation
=
'relu'
))
model
.
add
(
Dropout
(
0.5
))
model
.
add
(
Dense
(
4096
,
activation
=
'relu'
))
model
.
add
(
Dropout
(
0.5
))
model
.
add
(
Dense
(
num_classes
,
activation
=
'softmax'
))
# model = Sequential()
# # 卷积层
# model.add(
# Conv2D(filters=96, kernel_size=(11, 11), strides=(4, 4), padding='valid', input_shape=(image_size, image_size, 3),
# activation='relu'))
# model.add(MaxPool2D(pool_size=(3, 3), strides=(2, 2), padding='valid'))
# model.add(Conv2D(filters=256, kernel_size=(5, 5), strides=(1, 1), padding='same', activation='relu'))
# model.add(MaxPool2D(pool_size=(3, 3), strides=(2, 2), padding='valid'))
# model.add(Conv2D(filters=384, kernel_size=(3, 3), strides=(1, 1), padding='same', activation='relu'))
# model.add(Conv2D(filters=384, kernel_size=(3, 3), strides=(1, 1), padding='same', activation='relu'))
# model.add(Conv2D(filters=256, kernel_size=(3, 3), strides=(1, 1), padding='same', activation='relu'))
# model.add(MaxPool2D(pool_size=(3, 3), strides=(2, 2), padding='valid'))
# # 全连接层
# model.add(Flatten())
# model.add(Dense(4096, activation='relu'))
# model.add(Dropout(0.5))
# model.add(Dense(4096, activation='relu'))
# model.add(Dropout(0.5))
# model.add(Dense(num_classes, activation='softmax'))
model
=
MobileNet
(
input_shape
=
(
224
,
224
,
3
),
alpha
=
1.0
,
depth_multiplier
=
1
,
dropout
=
0.001
,
include_top
=
False
,
weights
=
'imagenet'
,
input_tensor
=
None
,
pooling
=
None
,
classes
=
num_classes
)
model
=
Sequential
([
model
,
layers
.
GlobalAveragePooling2D
(),
Dense
(
num_classes
,
activation
=
'softmax'
)
])
# 模型概要
model
.
summary
()
# model.summary()
# plot_model(model, to_file='AlexNet—鞋子分类.png', show_shapes=True)
# 学习率调节函数,逐渐减小学习率
...
...
@@ -108,15 +129,17 @@ def adjust_learning_rate(epoch):
else
:
lr
=
1e-6
return
lr
# 定义优化器
adam
=
Adam
(
lr
=
1e-4
)
# 定义学习率衰减策略
learningRateSchedular
=
LearningRateScheduler
(
adjust_learning_rate
)
learningRateSchedular
=
LearningRateScheduler
(
adjust_learning_rate
)
# 定义TensorBoard
# 日志保存文件夹的格式
logdir
=
os
.
path
.
join
(
'logdir'
,
datetime
.
datetime
.
now
().
strftime
(
'%Y%m%d-%H%M%S'
))
tensorboar_callback
=
tf
.
keras
.
callbacks
.
TensorBoard
(
logdir
)
# 定义callback
#
logdir = os.path.join('logdir', datetime.datetime.now().strftime('%Y%m%d-%H%M%S'))
#
tensorboar_callback = tf.keras.callbacks.TensorBoard(logdir) # 定义callback
# 定义优化器,loss function,训练过程中计算准确率
model
.
compile
(
optimizer
=
adam
,
loss
=
'categorical_crossentropy'
,
metrics
=
[
'accuracy'
])
...
...
@@ -124,7 +147,7 @@ model.compile(optimizer=adam, loss='categorical_crossentropy', metrics=['accurac
history
=
model
.
fit
(
x
=
train_generator
,
epochs
=
epochs
,
validation_data
=
val_generator
,
callbacks
=
[
tensorboar_callback
,
learningRateSchedular
])
callbacks
=
[
learningRateSchedular
])
# 显示训练集和验证集的acc和loss曲线
acc
=
history
.
history
[
'accuracy'
]
...
...
@@ -145,23 +168,15 @@ plt.title('Training and Validation Loss')
plt
.
legend
()
plt
.
show
()
# 模型预测
# adidass_(28).jpg Image_190.jpg
test_img
=
tf
.
keras
.
preprocessing
.
image
.
load_img
(
'adidass_(28).jpg '
,
target_size
=
(
image_size
,
image_size
))
test_img
=
tf
.
keras
.
preprocessing
.
image
.
load_img
(
'adidass_(28).jpg '
,
target_size
=
(
image_size
,
image_size
))
print
(
test_img
)
test_img
=
tf
.
keras
.
preprocessing
.
image
.
img_to_array
(
test_img
)
# 类型变换
test_img
=
tf
.
keras
.
preprocessing
.
image
.
img_to_array
(
test_img
)
# 类型变换
print
(
test_img
.
shape
)
test_img
=
tf
.
expand_dims
(
test_img
,
0
)
# 扩充一维
test_img
=
tf
.
expand_dims
(
test_img
,
0
)
# 扩充一维
print
(
test_img
.
shape
)
preds
=
model
.
predict
(
test_img
)
# 预测
preds
=
model
.
predict
(
test_img
)
# 预测
print
(
preds
.
shape
)
print
(
'预测结果:'
,
preds
)
print
(
'预测结果:'
,
preds
)
经典网络/RegNet--CVPR2020/RegNet.py
0 → 100644
浏览文件 @
c866cb78
import
tensorflow
as
tf
from
tensorflow.keras
import
layers
from
tensorflow.keras.models
import
Model
MODEL_CONFIGS
=
{
"x002"
:
{
"depths"
:
[
1
,
1
,
4
,
7
],
"widths"
:
[
24
,
56
,
152
,
368
],
"group_width"
:
8
,
"default_size"
:
224
,
"block_type"
:
"X"
},
"x004"
:
{
"depths"
:
[
1
,
2
,
7
,
12
],
"widths"
:
[
32
,
64
,
160
,
384
],
"group_width"
:
16
,
"default_size"
:
224
,
"block_type"
:
"X"
},
"x006"
:
{
"depths"
:
[
1
,
3
,
5
,
7
],
"widths"
:
[
48
,
96
,
240
,
528
],
"group_width"
:
24
,
"default_size"
:
224
,
"block_type"
:
"X"
},
"x008"
:
{
"depths"
:
[
1
,
3
,
7
,
5
],
"widths"
:
[
64
,
128
,
288
,
672
],
"group_width"
:
16
,
"default_size"
:
224
,
"block_type"
:
"X"
},
"x016"
:
{
"depths"
:
[
2
,
4
,
10
,
2
],
"widths"
:
[
72
,
168
,
408
,
912
],
"group_width"
:
24
,
"default_size"
:
224
,
"block_type"
:
"X"
},
"x032"
:
{
"depths"
:
[
2
,
6
,
15
,
2
],
"widths"
:
[
96
,
192
,
432
,
1008
],
"group_width"
:
48
,
"default_size"
:
224
,
"block_type"
:
"X"
},
"x040"
:
{
"depths"
:
[
2
,
5
,
14
,
2
],
"widths"
:
[
80
,
240
,
560
,
1360
],
"group_width"
:
40
,
"default_size"
:
224
,
"block_type"
:
"X"
},
"x064"
:
{
"depths"
:
[
2
,
4
,
10
,
1
],
"widths"
:
[
168
,
392
,
784
,
1624
],
"group_width"
:
56
,
"default_size"
:
224
,
"block_type"
:
"X"
},
"x080"
:
{
"depths"
:
[
2
,
5
,
15
,
1
],
"widths"
:
[
80
,
240
,
720
,
1920
],
"group_width"
:
120
,
"default_size"
:
224
,
"block_type"
:
"X"
},
"x120"
:
{
"depths"
:
[
2
,
5
,
11
,
1
],
"widths"
:
[
224
,
448
,
896
,
2240
],
"group_width"
:
112
,
"default_size"
:
224
,
"block_type"
:
"X"
},
"x160"
:
{
"depths"
:
[
2
,
6
,
13
,
1
],
"widths"
:
[
256
,
512
,
896
,
2048
],
"group_width"
:
128
,
"default_size"
:
224
,
"block_type"
:
"X"
},
"x320"
:
{
"depths"
:
[
2
,
7
,
13
,
1
],
"widths"
:
[
336
,
672
,
1344
,
2520
],
"group_width"
:
168
,
"default_size"
:
224
,
"block_type"
:
"X"
},
"y002"
:
{
"depths"
:
[
1
,
1
,
4
,
7
],
"widths"
:
[
24
,
56
,
152
,
368
],
"group_width"
:
8
,
"default_size"
:
224
,
"block_type"
:
"Y"
},
"y004"
:
{
"depths"
:
[
1
,
3
,
6
,
6
],
"widths"
:
[
48
,
104
,
208
,
440
],
"group_width"
:
8
,
"default_size"
:
224
,
"block_type"
:
"Y"
},
"y006"
:
{
"depths"
:
[
1
,
3
,
7
,
4
],
"widths"
:
[
48
,
112
,
256
,
608
],
"group_width"
:
16
,
"default_size"
:
224
,
"block_type"
:
"Y"
},
"y008"
:
{
"depths"
:
[
1
,
3
,
8
,
2
],
"widths"
:
[
64
,
128
,
320
,
768
],
"group_width"
:
16
,
"default_size"
:
224
,
"block_type"
:
"Y"
},
"y016"
:
{
"depths"
:
[
2
,
6
,
17
,
2
],
"widths"
:
[
48
,
120
,
336
,
888
],
"group_width"
:
24
,
"default_size"
:
224
,
"block_type"
:
"Y"
},
"y032"
:
{
"depths"
:
[
2
,
5
,
13
,
1
],
"widths"
:
[
72
,
216
,
576
,
1512
],
"group_width"
:
24
,
"default_size"
:
224
,
"block_type"
:
"Y"
},
"y040"
:
{
"depths"
:
[
2
,
6
,
12
,
2
],
"widths"
:
[
128
,
192
,
512
,
1088
],
"group_width"
:
64
,
"default_size"
:
224
,
"block_type"
:
"Y"
},
"y064"
:
{
"depths"
:
[
2
,
7
,
14
,
2
],
"widths"
:
[
144
,
288
,
576
,
1296
],
"group_width"
:
72
,
"default_size"
:
224
,
"block_type"
:
"Y"
},
"y080"
:
{
"depths"
:
[
2
,
4
,
10
,
1
],
"widths"
:
[
168
,
448
,
896
,
2016
],
"group_width"
:
56
,
"default_size"
:
224
,
"block_type"
:
"Y"
},
"y120"
:
{
"depths"
:
[
2
,
5
,
11
,
1
],
"widths"
:
[
224
,
448
,
896
,
2240
],
"group_width"
:
112
,
"default_size"
:
224
,
"block_type"
:
"Y"
},
"y160"
:
{
"depths"
:
[
2
,
4
,
11
,
1
],
"widths"
:
[
224
,
448
,
1232
,
3024
],
"group_width"
:
112
,
"default_size"
:
224
,
"block_type"
:
"Y"
},
"y320"
:
{
"depths"
:
[
2
,
5
,
12
,
1
],
"widths"
:
[
232
,
696
,
1392
,
3712
],
"group_width"
:
232
,
"default_size"
:
224
,
"block_type"
:
"Y"
},
}
# 将输入重新缩放并归一化为[0,1]和ImageNet均值和std
def
PreStem
(
x
,
name
=
None
):
x
=
layers
.
experimental
.
preprocessing
.
Rescaling
(
1.
/
255.
)(
x
)
return
x
# 论文中的stem(stride=2 3x3卷积+w0 = 32 output channels)
def
Stem
(
x
,
name
=
None
):
x
=
layers
.
Conv2D
(
32
,
(
3
,
3
),
strides
=
2
,
use_bias
=
False
,
padding
=
'same'
,
kernel_initializer
=
'he_normal'
,
name
=
name
+
'_stem_conv'
)(
x
)
x
=
layers
.
BatchNormalization
(
momentum
=
0.9
,
epsilon
=
1e-5
,
name
=
name
+
"_stem_bn"
)(
x
)
x
=
layers
.
ReLU
(
name
=
name
+
'_stem_relu'
)(
x
)
return
x
# XBlock实现:1x1卷积+3x3分组卷积+1x1卷积(conv后跟BN+ReLU)
def
XBlock
(
inputs
,
filters_in
,
filters_out
,
group_width
,
stride
=
1
,
name
=
None
):
# declare layers
groups
=
filters_out
//
group_width
# 当stide=2的时候,残差边需要使用1x1卷积降维处理保持shape一致
if
stride
!=
1
:
skip
=
layers
.
Conv2D
(
filters_out
,
(
1
,
1
),
strides
=
stride
,
use_bias
=
False
,
kernel_initializer
=
'he_normal'
,
name
=
name
+
'_skip_1x1'
)(
inputs
)
skip
=
layers
.
BatchNormalization
(
momentum
=
0.9
,
epsilon
=
1e-5
,
name
=
name
+
"_skip_bn"
)(
skip
)
else
:
skip
=
inputs
# build block
# conv_1x1_1
x
=
layers
.
Conv2D
(
filters_out
,
(
1
,
1
),
use_bias
=
False
,
kernel_initializer
=
'he_normal'
,
name
=
name
+
'_conv_1x1_1'
)(
inputs
)
x
=
layers
.
BatchNormalization
(
momentum
=
0.9
,
epsilon
=
1e-5
,
name
=
name
+
"_conv_1x1_1_bn"
)(
x
)
x
=
layers
.
ReLU
(
name
=
name
+
"_conv_1x1_1_relu"
)(
x
)
# group conv_3x3
x
=
layers
.
Conv2D
(
filters_out
,
(
3
,
3
),
use_bias
=
False
,
strides
=
stride
,
groups
=
groups
,
padding
=
'same'
,
kernel_initializer
=
'he_normal'
,
name
=
name
+
'_conv_3x3'
)(
x
)
x
=
layers
.
BatchNormalization
(
momentum
=
0.9
,
epsilon
=
1e-5
,
name
=
name
+
"_conv_3x3_bn"
)(
x
)
x
=
layers
.
ReLU
(
name
=
name
+
"_conv_3x3_relu"
)(
x
)
# conv_1x1_2
x
=
layers
.
Conv2D
(
filters_out
,
(
1
,
1
),
use_bias
=
False
,
kernel_initializer
=
"he_normal"
,
name
=
name
+
"_conv_1x1_2"
)(
x
)
x
=
layers
.
BatchNormalization
(
momentum
=
0.9
,
epsilon
=
1e-5
,
name
=
name
+
"_conv_1x1_2_bn"
)(
x
)
x
=
layers
.
ReLU
(
name
=
name
+
"_exit_relu"
)(
x
+
skip
)
return
x
def
Stage
(
inputs
,
block_type
,
# 必须是X、Y、Z之一
depth
,
# stage深度,要使用的块数
group_width
,
# 本stage所有块的group宽度
filters_in
,
#
filters_out
,
name
=
None
):
# 名称前缀
x
=
inputs
if
block_type
==
"X"
:
# 论文原话:Stage的第一个block的步长为2
x
=
XBlock
(
x
,
filters_in
,
filters_out
,
group_width
,
stride
=
2
,
name
=
f
"
{
name
}
_XBlock_0"
)
for
i
in
range
(
1
,
depth
):
x
=
XBlock
(
x
,
filters_out
,
filters_out
,
group_width
,
name
=
f
"
{
name
}
_XBlock_
{
i
}
"
)
# TODO YBlock,ZBlock
return
x
def
Head
(
x
,
num_classes
=
1000
,
name
=
None
):
x
=
layers
.
GlobalAveragePooling2D
(
name
=
name
+
'_head_gap'
)(
x
)
x
=
layers
.
Dense
(
num_classes
,
name
=
name
+
'head_dense'
)(
x
)
return
x
def
RegNet
(
depths
,
# 每个stage的深度
widths
,
# 块宽度(输出通道数)
group_width
,
# 每组中要使用的通道数
block_type
,
# "X","Y","Z"之一
default_size
,
# 默认输入图像大小
model_name
=
'regnet'
,
# 模型的可选名称
include_preprocessing
=
True
,
# 是否包含预处理
include_top
=
True
,
# 是否包含分类头
weights
=
'imagenet'
,
input_tensor
=
None
,
input_shape
=
None
,
pooling
=
None
,
classes
=
1000
,
# 可选的类数量
classifier_activation
=
'softmax'
):
# 分类器激活
img_input
=
layers
.
Input
(
shape
=
input_shape
)
inputs
=
img_input
x
=
inputs
if
include_preprocessing
:
x
=
PreStem
(
x
,
name
=
model_name
)
x
=
Stem
(
x
,
name
=
model_name
)
in_channels
=
32
# Output from Stem
for
num_stage
in
range
(
4
):
depth
=
depths
[
num_stage
]
out_channels
=
widths
[
num_stage
]
x
=
Stage
(
x
,
block_type
,
depth
,
group_width
,
in_channels
,
out_channels
,
name
=
model_name
+
'_Stage_'
+
str
(
num_stage
))
in_channels
=
out_channels
if
include_top
:
x
=
Head
(
x
,
num_classes
=
classes
,
name
=
'head'
)
else
:
if
pooling
==
'avg'
:
x
=
layers
.
GlobalAveragePooling2D
()(
x
)
elif
pooling
==
'max'
:
x
-
layers
.
GlobalMaxPooling2D
()(
x
)
model
=
Model
(
inputs
=
inputs
,
outputs
=
x
,
name
=
model_name
)
return
model
'''
"x002": {
"depths": [1, 1, 4, 7],
"widths": [24, 56, 152, 368],
"group_width": 8,
"default_size": 224,
"block_type": "X"
}
'''
def
RegNetX002
(
model_name
=
'regnetx002'
,
include_top
=
True
,
include_preprocessing
=
True
,
weights
=
'imagenet'
,
input_tensor
=
None
,
input_shape
=
None
,
pooling
=
None
,
classes
=
1000
,
classifier_activation
=
'softmax'
):
return
RegNet
(
MODEL_CONFIGS
[
'x002'
][
'depths'
],
MODEL_CONFIGS
[
'x002'
][
'widths'
],
MODEL_CONFIGS
[
'x002'
][
'group_width'
],
MODEL_CONFIGS
[
'x002'
][
'block_type'
],
MODEL_CONFIGS
[
'x002'
][
'default_size'
],
model_name
=
model_name
,
include_top
=
include_top
,
include_preprocessing
=
include_preprocessing
,
weights
=
weights
,
input_tensor
=
input_tensor
,
input_shape
=
input_shape
,
pooling
=
pooling
,
classes
=
classes
,
classifier_activation
=
classifier_activation
)
if
__name__
==
'__main__'
:
model
=
RegNetX002
(
input_shape
=
(
224
,
224
,
3
))
model
.
summary
()
编辑
预览
Markdown
is supported
0%
请重试
或
添加新附件
.
添加附件
取消
You are about to add
0
people
to the discussion. Proceed with caution.
先完成此消息的编辑!
取消
想要评论请
注册
或
登录

{kind=link}
{kind=link}