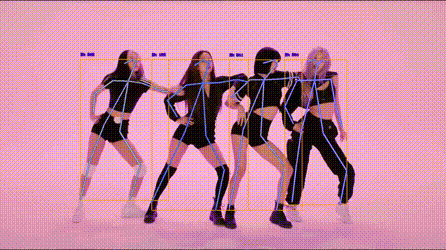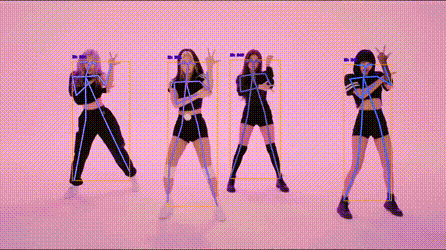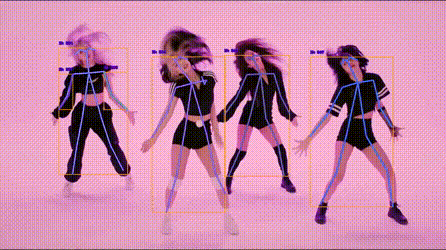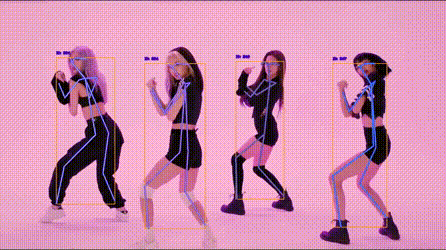Skip to content
体验新版
项目
组织
正在加载...
登录
切换导航
打开侧边栏
电池薯条
light_pose
提交
7d3dd3fc
light_pose
项目概览
电池薯条
/
light_pose
与 Fork 源项目一致
Fork自
DataBall / light_pose
通知
1
Star
0
Fork
0
代码
文件
提交
分支
Tags
贡献者
分支图
Diff
Issue
0
列表
看板
标记
里程碑
合并请求
0
DevOps
流水线
流水线任务
计划
Wiki
0
Wiki
分析
仓库
DevOps
项目成员
Pages
light_pose
项目概览
项目概览
详情
发布
仓库
仓库
文件
提交
分支
标签
贡献者
分支图
比较
Issue
0
Issue
0
列表
看板
标记
里程碑
合并请求
0
合并请求
0
Pages
DevOps
DevOps
流水线
流水线任务
计划
分析
分析
仓库分析
DevOps
Wiki
0
Wiki
成员
成员
收起侧边栏
关闭侧边栏
动态
分支图
创建新Issue
流水线任务
提交
Issue看板
体验新版 GitCode,发现更多精彩内容 >>
提交
7d3dd3fc
编写于
5月 14, 2021
作者:
DataBall
🚴🏻
浏览文件
操作
浏览文件
下载
电子邮件补丁
差异文件
update
上级
355bec54
变更
3
隐藏空白更改
内联
并排
Showing
3 changed file
with
22 addition
and
4 deletion
+22
-4
README.md
README.md
+16
-0
inference_video.py
inference_video.py
+6
-4
samples/s1.gif
samples/s1.gif
+0
-0
未找到文件。
README.md
浏览文件 @
7d3dd3fc
# light pose
# light pose
人体关键点检测
人体关键点检测
## 项目介绍
人体关键点检测
!
[
video
](
https://codechina.csdn.net/EricLee/light_pose/-/raw/master/samples/s1.gif
)
## 项目配置
*
作者开发环境:
*
Python 3.7
*
PyTorch >= 1.5.1
## 数据集
### coco2017 数据集
[
数据集下载地址(百度网盘 Password: )
](
)
## 预训练模型
*
[
预训练模型下载地址(百度网盘 Password: )
](
)
## 项目使用方法
*
step 1: python prepare_train_labels.py
*
step 1: python prepare_train_labels.py
*
step 2: python make_val_subset.py
*
step 2: python make_val_subset.py
*
step 3: python train.py
*
step 3: python train.py
...
...
inference_video.py
浏览文件 @
7d3dd3fc
...
@@ -181,12 +181,12 @@ def draw_one_pose(img,keypoints,color_x = [255, 0, 0]):
...
@@ -181,12 +181,12 @@ def draw_one_pose(img,keypoints,color_x = [255, 0, 0]):
cv2
.
line
(
img
,
(
int
(
x_a
),
int
(
y_a
)),
(
int
(
x_b
),
int
(
y_b
)),
color_x
,
2
)
cv2
.
line
(
img
,
(
int
(
x_a
),
int
(
y_a
)),
(
int
(
x_b
),
int
(
y_b
)),
color_x
,
2
)
if
__name__
==
'__main__'
:
if
__name__
==
'__main__'
:
video_path
=
"./video/
rw_7
.mp4"
# 加载视频
video_path
=
"./video/
a
.mp4"
# 加载视频
# video_path = 0 # 加载相机
# video_path = 0 # 加载相机
model_path
=
"
finetune_model/light_pose
.pth"
model_path
=
"
light_pose_checkpoints/light_pose-iter_1000
.pth"
model_pose
=
light_pose_model
(
model_path
=
model_path
,
heatmaps_thr
=
0.08
)
# 定义模型推理类
model_pose
=
light_pose_model
(
model_path
=
model_path
,
heatmaps_thr
=
0.08
)
# 定义模型推理类
print
(
"load:{}"
.
format
(
model_path
))
video_capture
=
cv2
.
VideoCapture
(
video_path
)
video_capture
=
cv2
.
VideoCapture
(
video_path
)
flag_write_video
=
True
# 是否记录推理 demo 视频
flag_write_video
=
True
# 是否记录推理 demo 视频
...
@@ -201,7 +201,7 @@ if __name__ == '__main__':
...
@@ -201,7 +201,7 @@ if __name__ == '__main__':
if
flag_video_start
==
False
and
flag_write_video
:
if
flag_video_start
==
False
and
flag_write_video
:
loc_time
=
time
.
localtime
()
loc_time
=
time
.
localtime
()
str_time
=
time
.
strftime
(
"%Y-%m-%d_%H-%M-%S"
,
loc_time
)
str_time
=
time
.
strftime
(
"%Y-%m-%d_%H-%M-%S"
,
loc_time
)
video_writer
=
cv2
.
VideoWriter
(
"./demo/demo_{}.mp4"
.
format
(
str_time
),
cv2
.
VideoWriter_fourcc
(
*
"mp4v"
),
fps
=
2
5
,
frameSize
=
(
int
(
im0
.
shape
[
1
]),
int
(
im0
.
shape
[
0
])))
video_writer
=
cv2
.
VideoWriter
(
"./demo/demo_{}.mp4"
.
format
(
str_time
),
cv2
.
VideoWriter_fourcc
(
*
"mp4v"
),
fps
=
2
4
,
frameSize
=
(
int
(
im0
.
shape
[
1
]),
int
(
im0
.
shape
[
0
])))
flag_video_start
=
True
flag_video_start
=
True
pose_dict
=
model_pose
.
predict
(
im0
.
copy
())
pose_dict
=
model_pose
.
predict
(
im0
.
copy
())
...
@@ -224,6 +224,8 @@ if __name__ == '__main__':
...
@@ -224,6 +224,8 @@ if __name__ == '__main__':
if
cv2
.
waitKey
(
1
)
==
27
:
if
cv2
.
waitKey
(
1
)
==
27
:
break
break
else
:
break
cv2
.
destroyAllWindows
()
cv2
.
destroyAllWindows
()
if
flag_write_video
:
if
flag_write_video
:
...
...
samples/s1.gif
0 → 100644
浏览文件 @
7d3dd3fc
5.9 MB
编辑
预览
Markdown
is supported
0%
请重试
或
添加新附件
.
添加附件
取消
You are about to add
0
people
to the discussion. Proceed with caution.
先完成此消息的编辑!
取消
想要评论请
注册
或
登录

{kind=link}