remove conflict
Showing
benchmark/IntelOptimizedPaddle.md
0 → 100644
doc/design/images/asgd.gif
0 → 100644
{kind=link}
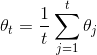
620 字节
doc/design/images/theta_star.gif
0 → 100644
{kind=link}
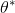
156 字节
doc/design/parameter_average.md
0 → 100644
go/proto/.gitignore
0 → 100644
paddle/framework/lod_rank_table.h
0 → 100644
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
paddle/platform/environment.h
已删除
100644 → 0
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。