Each trainer runs the forward and backward passes using their local
data:
1. In the forward pass, when a trainer runs the forward algorithm of a
lookup operator, it retrieves W(x) from the storage service.
1. The trainer computes W'(x) in the backward pass using W(x).
During the global update process:
1. Each trainer uploads its W'(x) to parameter servers.
1. The parameter server runs the optimization algorithm, e.g., the
Adam optimization algorithm, which requires that
1. The parameter server retrieves W(x) from memcached, and
1. The parameter server pushes $\Delta W(x)=f(W(x), lambda \sum_j
W'(x))$ to memcached, where $f$ denotes the optimization
algorithm.
### Storage Service Does Optimize
This design is very similar to the above one, except that the
optimization algorithm $f$ runs on the storage service.
- Pro: parameter servers do not retrieve W(x) from the storage
service, thus saves half network communication.
- Con: the storage service needs to be able to run the optimization
algorithm.
## Conclusion
Let us do the "storage service does not optimize" solution first, as a
baseline at least, because it is easier to use a well-optimized
distributed storage service like memcached. We can do the "storage
service does optimize" solution later or at the same time, which, if
implemented carefully, should have better performance than the former.
## Distributed Lookup Table
### Problem 1: The lookup table may be very large.
In condition like search engien and recommendation system, the number of feature ID may be very large, see 1000000000, then for a lookup table of size 8, the total size of the table is:
```
100000000000 * 8 * 4.0 = 2980.23 GB
```
### Solution: Distributed storage
1. Paddle use SelectedRows as the storage format for the lookup table, the lookup table parameter will be splited to multi machine according to the hash of the feature ID, and data will also be splited and send to the same machine to prefetch the parameter.
1. For common parameters, trainer will get the whole parameter for training, but for the big lookup table, trainer can not store the whole parameter, but the input data feature is very sparse, so every time we only need a few parameter for training, so we use `prefetch_op` to only prefetch the parameter needed to trainer.
### Problem 2. The Id in the lookup table is not sure before training.
The feature Id is calculated by hash function, because the feature data source is so large, we can not get all the id before training. So we can not initialize the table before training.
### Solution: Id auto growth
At the beginning of training, paddle only malloc the memory for the lookup table at pserver side, the id and the data will not be initialized. During training, when a pserver recived a Id, if the is is already in the lookup table, it will return the exist parameter, if the id is not exist, paddle will add it into the lookup table and initialize the value for it.
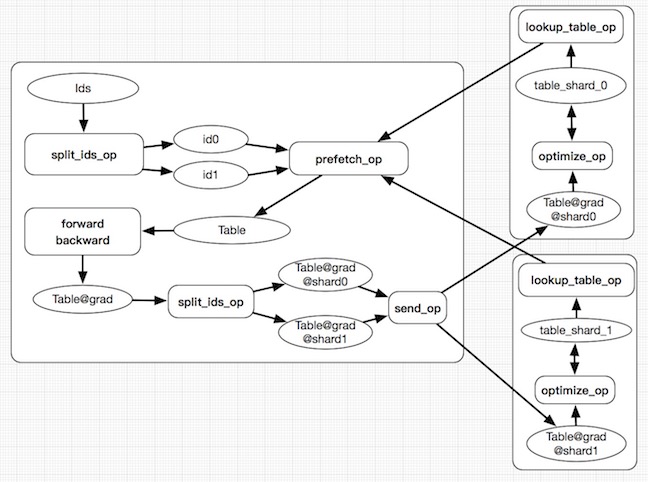
## Architecture
The whole architecture of the distribute lookup table is as below:
### Training steps:
1. Read a batch of data, the data is feature ids.
1. The input ids will be splited by `split_ids_op` with the same hash function of the lookup table.
1. The `prefetch_op` use the splited result to prefetch parameters back from lookup table.
1. Run forward backward to get the the gradient of the lookup table.
1.`split_ids_op` split the gradient and then use `send_op` to parameter server.
1. parameter server update the table with the received gradient.
{kind=link}