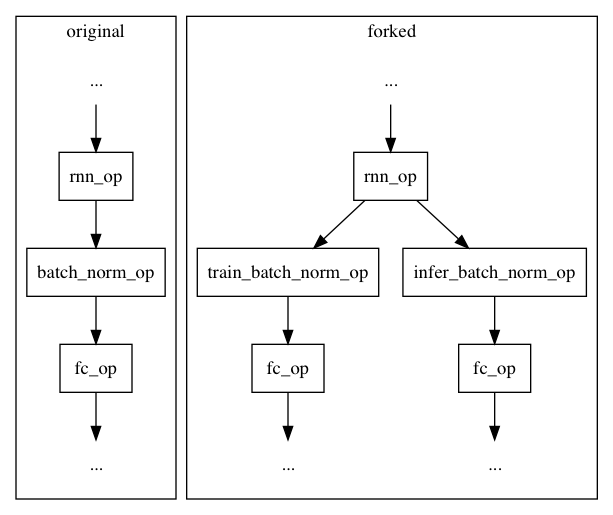
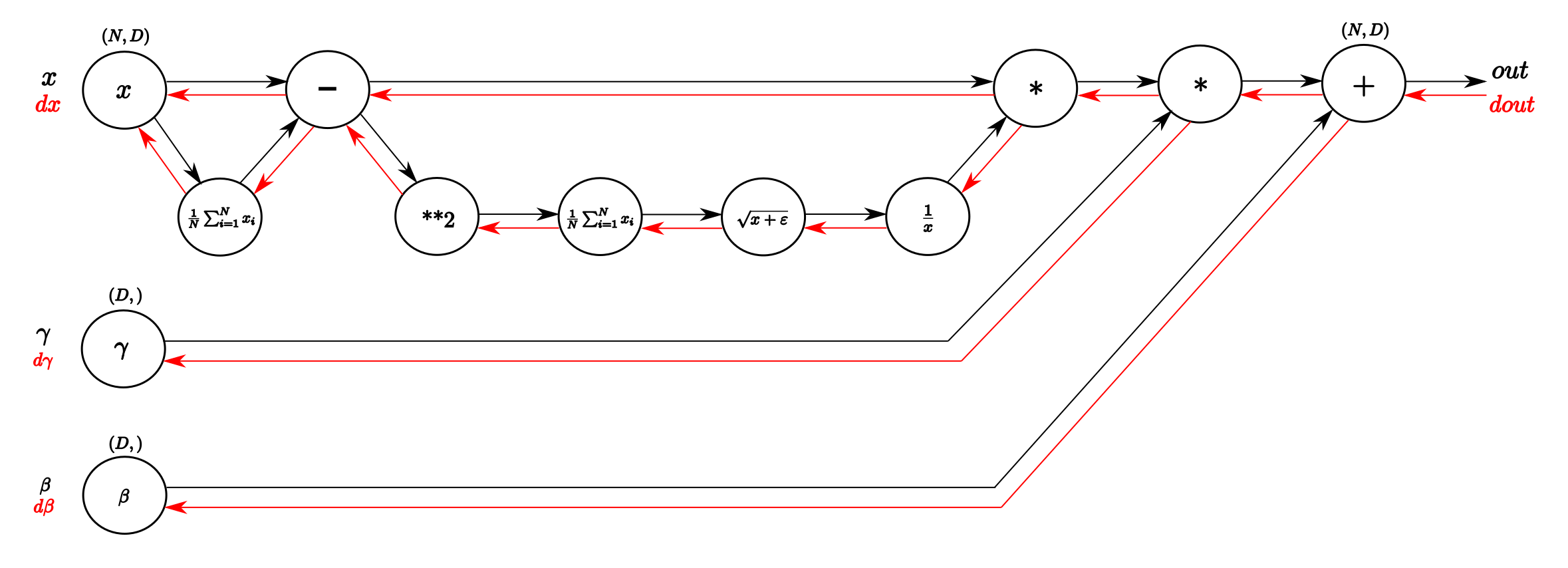
Design doc: Batch Normalization Operator (#3748)
* Add design doc of batch_norm_op * Move batch_norm_op.png to operator/images * Refine batch_norm_op design doc
Showing
paddle/operators/batch_norm_op.md
0 → 100644
{kind=link}
23.3 KB
{kind=link}
161.3 KB