Merge pull request #371 from Meiyim/ernie_tiny
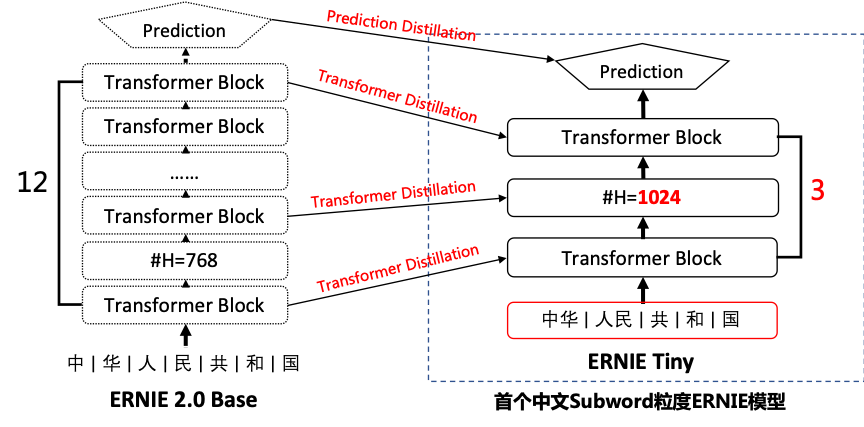
Ernie tiny
Showing
.metas/ernie_tiny.png
0 → 100644
{kind=link}
99.0 KB
| ... | ... | @@ -5,3 +5,5 @@ scikit-learn==0.20.3 |
| scipy==1.2.1 | ||
| six==1.11.0 | ||
| sklearn==0.0 | ||
| sentencepiece==0.1.8 | ||
| paddlepaddle-gpu==1.5.2.post107 |