Skip to content
体验新版
项目
组织
正在加载...
登录
切换导航
打开侧边栏
慢慢CG
TDengine
提交
1a2ba1e0
T
TDengine
项目概览
慢慢CG
/
TDengine
与 Fork 源项目一致
Fork自
taosdata / TDengine
通知
1
Star
0
Fork
0
代码
文件
提交
分支
Tags
贡献者
分支图
Diff
Issue
0
列表
看板
标记
里程碑
合并请求
0
Wiki
0
Wiki
分析
仓库
DevOps
项目成员
Pages
T
TDengine
项目概览
项目概览
详情
发布
仓库
仓库
文件
提交
分支
标签
贡献者
分支图
比较
Issue
0
Issue
0
列表
看板
标记
里程碑
合并请求
0
合并请求
0
Pages
分析
分析
仓库分析
DevOps
Wiki
0
Wiki
成员
成员
收起侧边栏
关闭侧边栏
动态
分支图
创建新Issue
提交
Issue看板
提交
1a2ba1e0
编写于
7月 31, 2020
作者:
陶建辉(Jeff)
浏览文件
操作
浏览文件
下载
电子邮件补丁
差异文件
add new document
上级
7cf4430a
变更
5
隐藏空白更改
内联
并排
Showing
5 changed file
with
160 addition
and
43 deletion
+160
-43
documentation20/webdocs/assets/dnode.png
documentation20/webdocs/assets/dnode.png
+0
-0
documentation20/webdocs/assets/modules.png
documentation20/webdocs/assets/modules.png
+0
-0
documentation20/webdocs/assets/vnode.png
documentation20/webdocs/assets/vnode.png
+0
-0
documentation20/webdocs/markdowndocs/administrator-ch.md
documentation20/webdocs/markdowndocs/administrator-ch.md
+54
-43
documentation20/webdocs/markdowndocs/taosd-ch.md
documentation20/webdocs/markdowndocs/taosd-ch.md
+106
-0
未找到文件。
documentation20/webdocs/assets/dnode.png
0 → 100644
浏览文件 @
1a2ba1e0
96.9 KB
documentation20/webdocs/assets/modules.png
0 → 100644
浏览文件 @
1a2ba1e0
86.9 KB
documentation20/webdocs/assets/vnode.png
查看替换文件 @
7cf4430a
浏览文件 @
1a2ba1e0
6.8 KB
|
W:
|
H:
54.3 KB
|
W:
|
H:
2-up
Swipe
Onion skin
documentation20/webdocs/markdowndocs/administrator-ch.md
浏览文件 @
1a2ba1e0
#系统管理
#
系统管理
## 容量规划
## 容量规划
一个系统的处理能力是有限的,但通过对TDengine配置参数的调整,可以做到资源的最佳配置
。
使用TDengine来搭建一个物联网大数据平台,计算资源、存储资源需要根据业务场景进行规划。下面分别讨论系统运行所需要的内存、CPU以及硬盘空间
。
###内存需求
###
内存需求
每个D
atabase可以创建固定数目的Vnode,默认与CPU核数相同,可通过maxVgroupsPerDb配置;每个vnode会占用固定大小的内存(大小与数据库的配置参数blocks和cache有关);每个Table会占用与Tag总大小有关的内存;此外,系统会有一些固定的内存开销。因此,每个Database
需要的系统内存可通过如下公式计算:
每个D
B可以创建固定数目的vnode,默认与CPU核数相同,可通过maxVgroupsPerDb配置;每个vnode会占用固定大小的内存(大小与数据库的配置参数blocks和cache有关);每个Table会占用与Tag总大小有关的内存;此外,系统会有一些固定的内存开销。因此,每个DB
需要的系统内存可通过如下公式计算:
```
```
Memory Size = maxVgroupsPerDb * (blocks * cache + 10Mb) + numOfTables * (tagSizePerTable + 0.5Kb)
Memory Size = maxVgroupsPerDb * (blocks * cache + 10Mb) + numOfTables * (tagSizePerTable + 0.5Kb)
```
```
示例:假设是4核机器,cache是缺省大小16M, blocks是缺省值6,假设有10万张表,标签总长度是256字节,则从的内存需求为:4
\*
(16
\*
6+10) + 100000
*
(0.25+0.5)/1000 = 499M
示例:假设是4核机器,cache是缺省大小16M, blocks是缺省值6,假设有10万张表,标签总长度是256字节,则总的内存需求为:4
\*
(16
\*
6+10) + 100000
*
(0.25+0.5)/1000 = 499M。
实际运行的系统往往会根据数据特点的不同,将数据存放在不同的DB里。因此做规划时,也需要考虑。
如果内存充裕,可以加大Blocks的配置,这样更多数据将保存在内存里,提高查询速度。
如果内存充裕,可以加大Blocks的配置,这样更多数据将保存在内存里,提高查询速度。
###CPU需求
###
CPU需求
CPU的需求取决于如下两方面:
CPU的需求取决于如下两方面:
-
数据插入:TDengine单核每秒能至少处理一万个插入请求。每个插入请求可以带多条记录
。条数越大,插入效率越高
。但对前端数据采集的要求越高,因为需要缓存记录,然后一批插入。
-
数据插入:TDengine单核每秒能至少处理一万个插入请求。每个插入请求可以带多条记录
,一次插入一条记录与插入10条记录,消耗的计算资源差别很小。因此没次插入,条数越大,插入效率越高。如果一个插入请求带200条以上记录,单核就能达到每秒插入100万条记录的速度
。但对前端数据采集的要求越高,因为需要缓存记录,然后一批插入。
-
查询需求:TDengine提供高效的查询,但是每个场景的查询差异很大,查询频次变化也很大,难以给出客观数字。需要用户针对自己的场景,写一些查询语句,才能确定。
-
查询需求:TDengine提供高效的查询,但是每个场景的查询差异很大,查询频次变化也很大,难以给出客观数字。需要用户针对自己的场景,写一些查询语句,才能确定。
因此仅对数据插入而言,CPU是可以估算出来的,但查询所耗的计算资源无法估算。在实际运营过程中,不建议CPU使用率超过50%,超过后,需要增加新的节点,以获得更多计算资源。
因此仅对数据插入而言,CPU是可以估算出来的,但查询所耗的计算资源无法估算。在实际运营过程中,不建议CPU使用率超过50%,超过后,需要增加新的节点,以获得更多计算资源。
###存储需求
###
存储需求
TDengine相对于通用数据库,有超高的压缩比,在绝大多数场景下,TDengine的压缩比不会低于5倍,有的场合,压缩比可达到10倍以上,取决于数据特征。压缩前的原始数据大小可通过如下方式计算:
TDengine相对于通用数据库,有超高的压缩比,在绝大多数场景下,TDengine的压缩比不会低于5倍,有的场合,压缩比可达到10倍以上,取决于
实际场景的
数据特征。压缩前的原始数据大小可通过如下方式计算:
```
```
Raw DataSize = numOfTables * rowSizePerTable * rowsPerTable
Raw DataSize = numOfTables * rowSizePerTable * rowsPerTable
...
@@ -39,6 +41,12 @@ Raw DataSize = numOfTables * rowSizePerTable * rowsPerTable
...
@@ -39,6 +41,12 @@ Raw DataSize = numOfTables * rowSizePerTable * rowsPerTable
为提高速度,可以配置多快硬盘,这样可以并发写入或读取数据。
为提高速度,可以配置多快硬盘,这样可以并发写入或读取数据。
### 物理机或虚拟机台数
根据上面的内存、CPU、存储的预估,就可以知道整个系统需要多少核、多少内存、多少存储空间。如果数据副本数不为1,总需求量再乘以副本数。
根据总量,再根据单个物理机或虚拟机的资源,就可以轻松决定需要购置多少台机器了。
## 容错和灾备
## 容错和灾备
### 容错
### 容错
...
@@ -47,15 +55,16 @@ TDengine支持**WAL**(Write Ahead Log)机制,实现数据的容错能力
...
@@ -47,15 +55,16 @@ TDengine支持**WAL**(Write Ahead Log)机制,实现数据的容错能力
TDengine接收到应用的请求数据包时,先将请求的原始数据包写入数据库日志文件,等数据成功写入数据库数据文件后,再删除相应的WAL。这样保证了TDengine能够在断电等因素导致的服务重启时从数据库日志文件中恢复数据,避免数据的丢失。
TDengine接收到应用的请求数据包时,先将请求的原始数据包写入数据库日志文件,等数据成功写入数据库数据文件后,再删除相应的WAL。这样保证了TDengine能够在断电等因素导致的服务重启时从数据库日志文件中恢复数据,避免数据的丢失。
涉及的系统配置参数有两个
.
涉及的系统配置参数有两个
:
walLevel:WAL级别,0:不写wal; 1:写wal, 但不执行fsync; 2:写wal, 而且执行fsync。
-
walLevel:WAL级别,0:不写wal; 1:写wal, 但不执行fsync; 2:写wal, 而且执行fsync。
-
fsync:当walLevel设置为2时,执行fsync的周期。设置为0,表示每次写入,立即执行fsync。
fsync:当walLevel设置为2时,执行fsync的周期。设置为0,表示每次写入,立即执行fsync
。
如果要100%的保证数据不丢失,需要将walLevel设置为2,fsync设置为0。这时写入速度将会下降。但如果应用侧启动的写数据的线程数达到一定的数量(超过50),那么写入数据的性能也会很不错,只会比fsync设置为3000毫秒下降30%左右
。
**灾备**
### 灾备
TDengine的集群通过多个副本的机制,来提供系统的高可
靠
性,实现灾备能力。
TDengine的集群通过多个副本的机制,来提供系统的高可
用
性,实现灾备能力。
TDengine集群是由mnode负责管理的,为保证mnode的高可靠,可以配置多个mnode副本,副本数由系统配置参数numOfMnodes决定,为了支持高可靠,需要设置大于1。为保证元数据的强一致性,mnode副本之间通过同步方式进行数据复制,保证了元数据的强一致性。
TDengine集群是由mnode负责管理的,为保证mnode的高可靠,可以配置多个mnode副本,副本数由系统配置参数numOfMnodes决定,为了支持高可靠,需要设置大于1。为保证元数据的强一致性,mnode副本之间通过同步方式进行数据复制,保证了元数据的强一致性。
...
@@ -63,33 +72,7 @@ TDengine集群中的时序数据的副本数是与数据库关联的,一个集
...
@@ -63,33 +72,7 @@ TDengine集群中的时序数据的副本数是与数据库关联的,一个集
TDengine集群的节点数必须大于等于副本数,否则创建表时将报错。
TDengine集群的节点数必须大于等于副本数,否则创建表时将报错。
当TDengine集群中的节点部署在不同的物理机上(比如不同的机架、或不同的IDC),并设置多个副本数时,就实现了异地容灾,从而提供系统的高可靠性,无需再使用其他软件或工具。
当TDengine集群中的节点部署在不同的物理机上,并设置多个副本数时,就实现了系统的高可靠性,无需再使用其他软件或工具。TDengine企业版还可以将副本部署在不同机房,从而实现异地容灾。
## 文件目录结构
安装TDengine后,默认会在操作系统中生成下列目录或文件:
| 目录/文件 | 说明 |
| ---------------------- | :------------------------------------------------|
| /usr/local/taos/bin | TDengine可执行文件目录。其中的执行文件都会软链接到/usr/bin目录下。 |
| /usr/local/taos/connector | TDengine各种连接器目录。 |
| /usr/local/taos/driver | TDengine动态链接库目录。会软链接到/usr/lib目录下。 |
| /usr/local/taos/examples | TDengine各种语言应用示例目录。 |
| /usr/local/taos/include | TDengine对外提供的C语言接口的头文件。 |
| /etc/taos/taos.cfg | TDengine默认[配置文件] |
| /var/lib/taos | TDengine默认数据文件目录,可通过[配置文件]修改位置. |
| /var/log/taos | TDengine默认日志文件目录,可通过[配置文件]修改位置 |
**可执行文件**
TDengine的所有可执行文件默认存放在 _/usr/local/taos/bin_ 目录下。其中包括:
-
_taosd_:TDengine服务端可执行文件
-
_taos_: TDengine Shell可执行文件
-
_taosdump_:数据导入导出工具
-
remove.sh:卸载TDengine的脚本, 请谨慎执行,链接到/usr/bin目录下的rmtaos命令。会删除TDengine的安装目录/usr/local/taos,但会保留/etc/taos、/var/lib/taos、/var/log/taos。
您可以通过修改系统配置文件taos.cfg来配置不同的数据目录和日志目录。
## 服务端配置
## 服务端配置
...
@@ -97,8 +80,8 @@ TDengine系统后台服务由taosd提供,可以在配置文件taos.cfg里修
...
@@ -97,8 +80,8 @@ TDengine系统后台服务由taosd提供,可以在配置文件taos.cfg里修
下面仅仅列出一些重要的配置参数,更多的参数请看配置文件里的说明。各个参数的详细介绍及作用请看前述章节。
**注意:配置修改后,需要重启*taosd*服务才能生效。**
下面仅仅列出一些重要的配置参数,更多的参数请看配置文件里的说明。各个参数的详细介绍及作用请看前述章节。
**注意:配置修改后,需要重启*taosd*服务才能生效。**
-
first: taosd启动时,主动连接的集群中第一个dnode的end point, 缺省值为 localhost:6030。
-
first
Ep
: taosd启动时,主动连接的集群中第一个dnode的end point, 缺省值为 localhost:6030。
-
second: taosd启动时,如果first连接不上,尝试连接集群中第二个dnode的end point, 缺省值为空。
-
second
Ep
: taosd启动时,如果first连接不上,尝试连接集群中第二个dnode的end point, 缺省值为空。
-
fqdn:数据节点的FQDN。如果为空,将自动获取操作系统配置的第一个, 缺省值为空。
-
fqdn:数据节点的FQDN。如果为空,将自动获取操作系统配置的第一个, 缺省值为空。
-
serverPort:taosd启动后,对外服务的端口号,默认值为6030。
-
serverPort:taosd启动后,对外服务的端口号,默认值为6030。
-
httpPort: RESTful服务使用的端口号,所有的HTTP请求(TCP)都需要向该接口发起查询/写入请求。
-
httpPort: RESTful服务使用的端口号,所有的HTTP请求(TCP)都需要向该接口发起查询/写入请求。
...
@@ -313,3 +296,31 @@ TDengine启动后,会自动创建一个监测数据库SYS,并自动将服务
...
@@ -313,3 +296,31 @@ TDengine启动后,会自动创建一个监测数据库SYS,并自动将服务
这些监测信息的采集缺省是打开的,但可以修改配置文件里的选项enableMonitor将其关闭或打开。
这些监测信息的采集缺省是打开的,但可以修改配置文件里的选项enableMonitor将其关闭或打开。
## 文件目录结构
安装TDengine后,默认会在操作系统中生成下列目录或文件:
| 目录/文件 | 说明 |
| ------------------------- | :----------------------------------------------------------- |
| /usr/local/taos/bin | TDengine可执行文件目录。其中的执行文件都会软链接到/usr/bin目录下。 |
| /usr/local/taos/connector | TDengine各种连接器目录。 |
| /usr/local/taos/driver | TDengine动态链接库目录。会软链接到/usr/lib目录下。 |
| /usr/local/taos/examples | TDengine各种语言应用示例目录。 |
| /usr/local/taos/include | TDengine对外提供的C语言接口的头文件。 |
| /etc/taos/taos.cfg | TDengine默认[配置文件] |
| /var/lib/taos | TDengine默认数据文件目录,可通过[配置文件]修改位置. |
| /var/log/taos | TDengine默认日志文件目录,可通过[配置文件]修改位置 |
**可执行文件**
TDengine的所有可执行文件默认存放在 _/usr/local/taos/bin_ 目录下。其中包括:
-
_taosd_:TDengine服务端可执行文件
-
_taos_: TDengine Shell可执行文件
-
_taosdump_:数据导入导出工具
-
remove.sh:卸载TDengine的脚本, 请谨慎执行,链接到/usr/bin目录下的rmtaos命令。会删除TDengine的安装目录/usr/local/taos,但会保留/etc/taos、/var/lib/taos、/var/log/taos。
您可以通过修改系统配置文件taos.cfg来配置不同的数据目录和日志目录。
documentation20/webdocs/markdowndocs/taosd-ch.md
0 → 100644
浏览文件 @
1a2ba1e0
# TDengine 2.0 执行代码taosd的设计
逻辑上,TDengine系统包含dnode, taosc和App,dnode是服务器侧执行代码taosd的一个运行实例,因此taosd是TDengine的核心,本文对taosd的设计做一简单的介绍,模块内的实现细节请见其他文档。
## 系统模块图
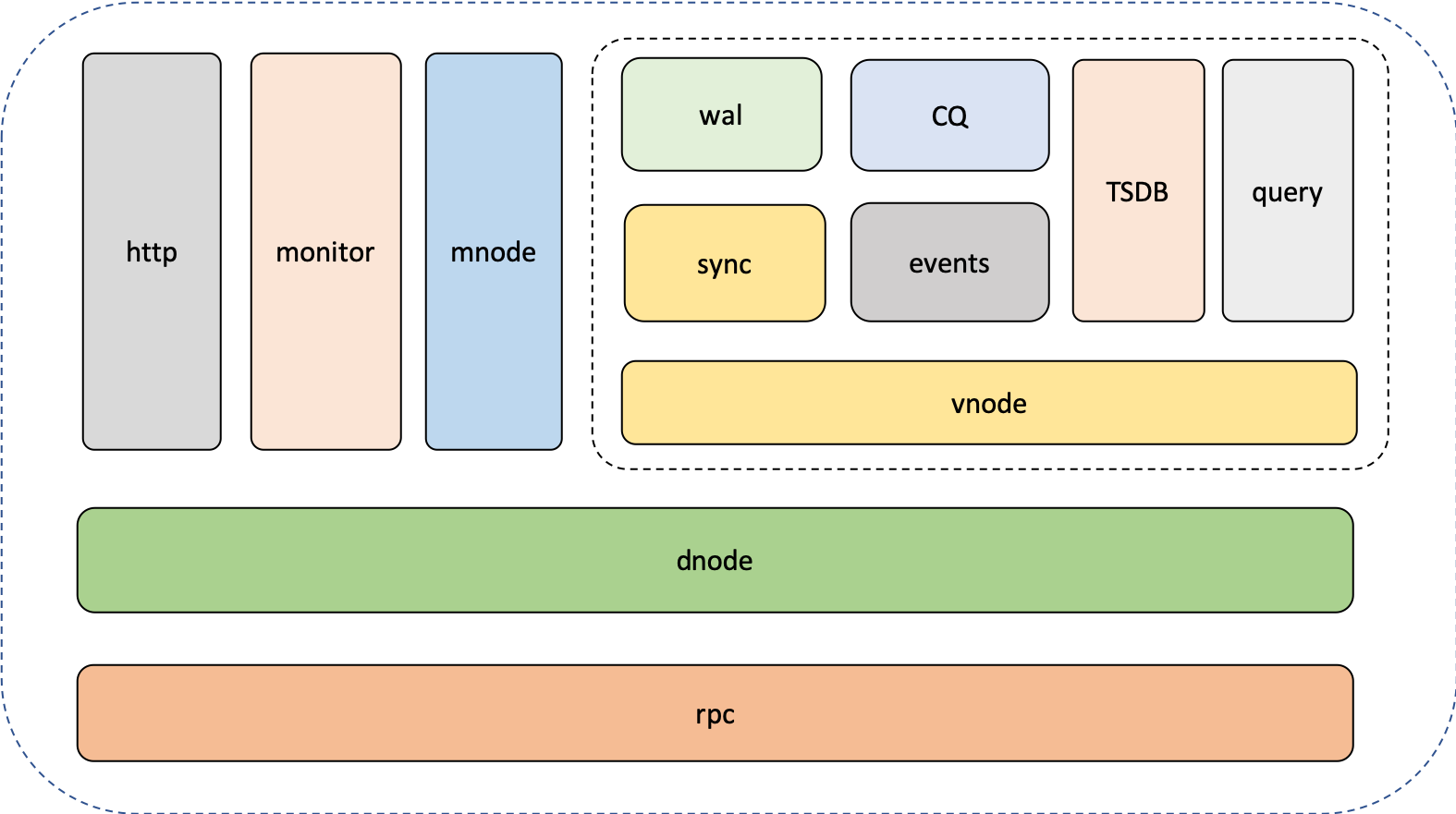
taosd包含rpc, dnode, vnode, tsdb, query, cq, sync, wal, mnode, http, monitor等模块,具体如下图:
<center>
<img
src=
"../assets/modules.png"
>
</center>
taosd的启动入口是dnode模块,dnode然后启动其他模块,包括可选配置的http, monitor模块。taosc或dnode之间交互的消息都是通过rpc模块进行,dnode模块根据接收到的消息类型,将消息分发到vnode或mnode的消息队列,或由dnode模块自己消费。dnode的工作线程(worker)消费消息队列里的消息,交给mnode或vnode进行处理。下面对各个模块做简要说明。
## RPC模块
该模块负责taosd与taosc, 以及其他数据节点之间的通讯。TDengine没有采取标准的HTTP或gRPC等第三方工具,而是实现了自己的通讯模块RPC。
考虑到物联网场景下,数据写入的包一般不大,因此除支持TCP链接之外,RPC还支持UDP链接。当数据包小于15K时,RPC将采用UDP方式进行链接,否则将采用TCP链接。对于查询类的消息,RPC不管包的大小,总是采取TCP链接。对于UDP链接,RPC实现了自己的超时、重传、顺序检查等机制,以保证数据可靠传输。
RPC模块还提供数据压缩功能,如果数据包的字节数超过系统配置参数compressMsgSize, RPC在传输中将自动压缩数据,以节省带宽。
为保证数据的安全和数据的integrity, RPC模块采用MD5做数字签名,对数据的真实性和完整性进行认证。
## DNODE模块
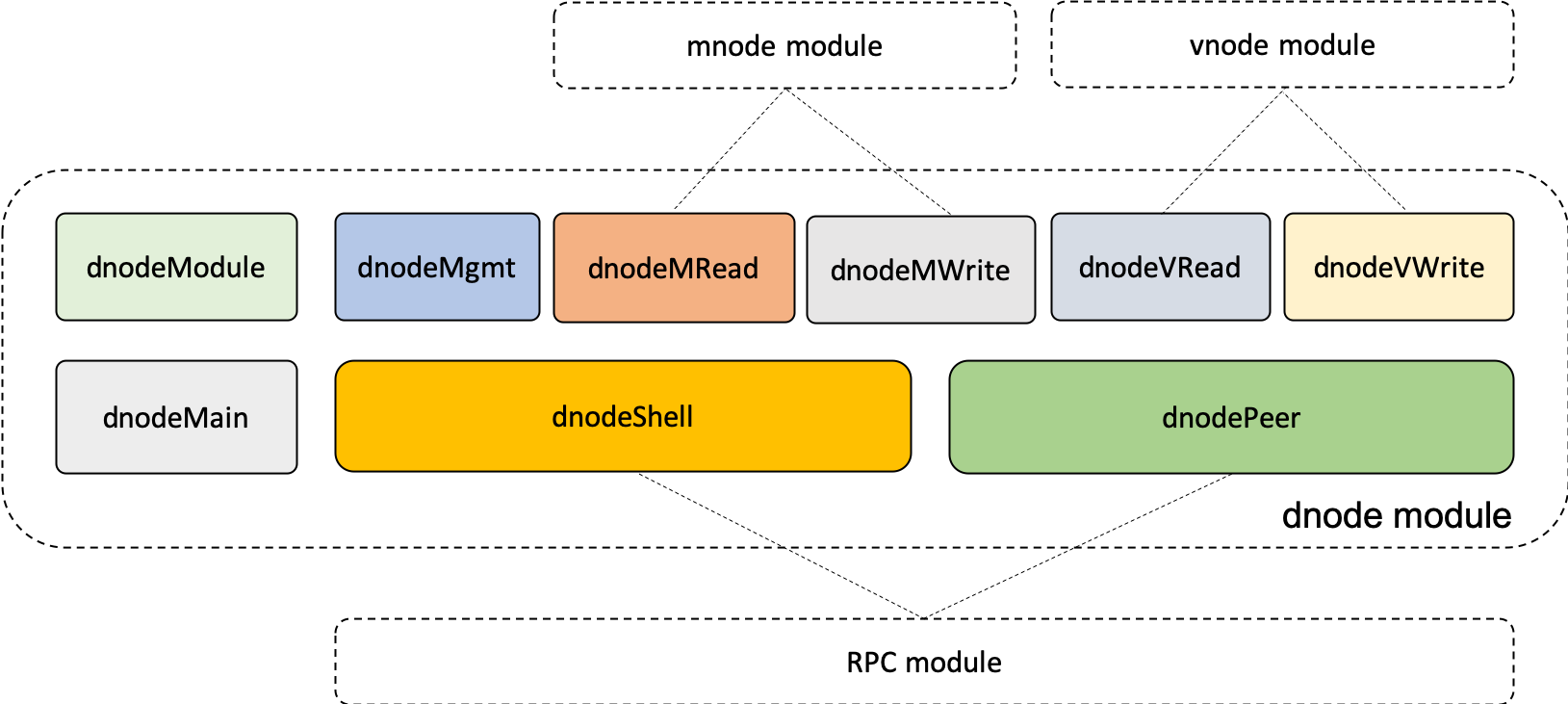
该模块是整个taosd的入口,它具体负责如下任务:
-
系统的初始化,包括
-
从文件taos.cfg读取系统配置参数,从文件dnodeCfg.json读取数据节点的配置参数;
-
启动RPC模块,并建立起与taosc通讯的server链接,与其他数据节点通讯的server链接;
-
启动并初始化dnode的内部管理, 该模块将扫描该数据节点已有的vnode,并打开它们;
-
初始化可配置的模块,如mnode, http, monitor等。
-
数据节点的管理,包括
-
定时的向mnode发送status消息,报告自己的状态;
-
根据mnode的指示,创建、改变、删除vnode;
-
根据mnode的指示,修改自己的配置参数;
-
消息的分发、消费,包括
-
为每一个vnode和mnode的创建并维护一个读队列、一个写队列;
-
将从taosc或其他数据节点来的消息,根据消息类型,将其直接分发到不同的消息队列,或由自己的管理模块直接消费;
-
维护一个读的线程池,消费读队列的消息,交给vnode或mnode处理。为支持高并发,一个读线程(Worker)可以消费多个队列的消息,一个读队列可以由多个worker消费;
-
维护一个写的线程池,消费写队列的消息,交给vnode或mnode处理。为保证写操作的序列化,一个写队列只能由一个写线程负责,但一个写线程可以负责多个写队列。
taosd的消息消费由dnode通过读写线程池进行控制,是系统的中枢。该模块内的结构体图如下:
<center>
<img
src=
"../assets/dnode.png"
>
</center>
## VNODE模块
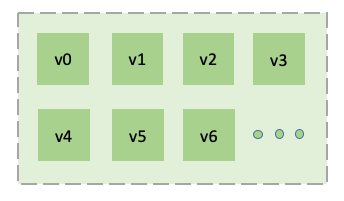
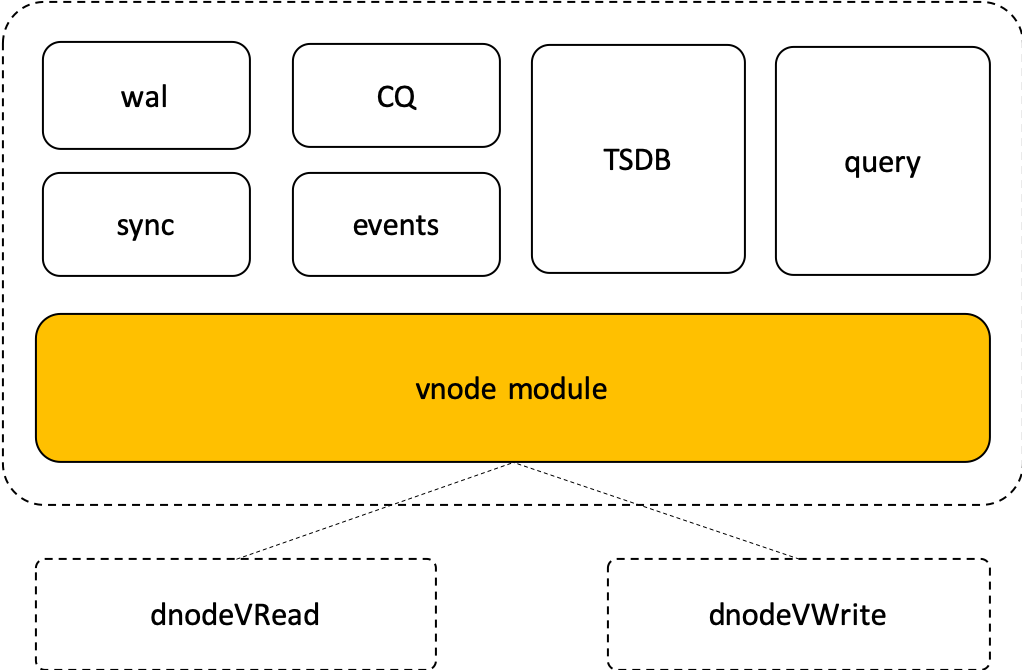
vnode是一独立的数据存储查询逻辑单元,但因为一个vnode只能容许一个DB,因此vnode内部没有account, DB, user等概念。为实现更好的模块化、封装以及未来的扩展,它有很多子模块,包括负责存储的TSDB,负责查询的Query, 负责数据复制的sync,负责数据库日志的的wal, 负责连续查询的cq(continuous query), 负责事件触发的流计算的event等模块,这些子模块只与vnode模块发生关系,与其他模块没有任何调用关系。模块图如下:
<center>
<img
src=
"../assets/vnode.png"
>
</center>
vnode模块向下,与dnodeVRead,dnodeVWrite发生互动,向上,与子模块发生互动。它主要的功能有:
-
协调各个子模块的互动。各个子模块之间都不直接调用,都需要通过vnode模块进行;
-
对于来自taosc或mnode的写操作,vnode模块将其分解为写日志(wal), 转发(sync), 本地存储(tsdb)子模块的操作;
-
对于查询操作,分发到query模块进行。
一个数据节点里有多个vnode, 因此vnode模块是有多个运行实例的。每个运行实例是完全独立的。
vnode与其子模块是通过API直接调用,而不是通过消息队列传递。而且各个子模块只与vnode模块有交互,不与dnode, rpc等模块发生任何直接关联。
## MNODE模块
mnode是整个系统的大脑,负责整个系统的资源调度,负责meta data的管理与存储。
一个运行的系统里,只有一个mnode,但它有多个副本(由系统配置参数numOfMpeers控制)。这些副本分布在不同的dnode里,目的是保证系统的高可靠运行。副本之间的数据复制是采用同步而非异步的方式,以确保数据的一致性,确保数据不会丢失。这些副本会自动选举一个Master,其他副本是slave。所有数据更新类的操作,都只能在master上进行,而查询类的可以在slave节点上进行。代码实现上,同步模块与vnode共享,但mnode被分配一个特殊的vgroup ID: 1,而且quorum大于1。整个集群系统是由多个dnode组成的,运行的mnode的副本数不可能超过dnode的个数,但不会超过配置的副本数。如果某个mnode副本宕机一段时间,只要超过半数的mnode副本仍在运行,运行的mnode会自动根据整个系统的资源情况,在其他dnode里再启动一个mnode, 以保证运行的副本数。
各个dnode通过信息交换,保存有mnode各个副本的End Point列表,并向其中的master节点定时(间隔由系统配置参数statusInterval控制)发送status消息,消息体里包含该dnode的CPU、内存、剩余存储空间、vnode个数,以及各个vnode的状态(存储空间、原始数据大小、记录条数、角色等)。这样mnode就了解整个系统的资源情况,如果用户创建新的表,就可以决定需要在哪个dnode创建;如果增加或删除dnode, 或者监测到某dnode数据过热、或离线太长,就可以决定需要挪动那些vnode,以实现负载均衡。
mnode里还负责account, user, DB, stable, table, vgroup, dnode的创建、删除与更新。mnode不仅把这些entity的meta data保存在内存,还做持久化存储。但为节省内存,各个表的标签值不保存在mnode(保存在vnode),而且子表不维护自己的schema, 而是与stable共享。为减小mnode的查询压力,taosc会缓存table、stable的schema。对于查询类的操作,各个slave mnode也可以提供,以减轻master压力。
## TSDB模块
TSDB模块是VNODE中的负责快速高并发地存储和读取属于该VNODE的表的元数据及采集的时序数据的引擎。除此之外,TSDB还提供了表结构的修改、表标签值的修改等功能。TSDB提供API供VNODE和Query等模块调用。TSDB中存储了两类数据,1:元数据信息;2:时序数据
### 元数据信息
TSDB中存储的元数据包含属于其所在的VNODE中表的类型,schema的定义等。对于超级表和超级表下的子表而言,又包含了tag的schema定义以及子表的tag值等。对于元数据信息而言,TSDB就相当于一个全内存的KV型数据库,属于该VNODE的表对象全部在内存中,方便快速查询表的信息。除此之外,TSDB还对其中的子表,按照tag的第一列取值做了全内存的索引,大大加快了对于标签的过滤查询。TSDB中的元数据的最新状态在落盘时,会以追加(append-only)的形式,写入到meta文件中。meta文件只进行追加操作,即便是元数据的删除,也会以一条记录的形式写入到文件末尾。TSDB也提供了对于元数据的修改操作,如表schema的修改,tag schema的修改以及tag值的修改等。
### 时序数据
每个TSDB在创建时,都会事先分配一定量的内存缓冲区,且内存缓冲区的大小可配可修改。表采集的时序数据,在写入TSDB时,首先以追加的方式写入到分配的内存缓冲区中,同时建立基于时间戳的内存索引,方便快速查询。当内存缓冲区的数据积累到一定的程度时(达到内存缓冲区总大小的1/3),则会触发落盘操作,将缓冲区中的数据持久化到硬盘文件上。时序数据在内存缓冲区中是以行(row)的形式存储的。
而时序数据在写入到TSDB的数据文件时,是以列(column)的形式存储的。TSDB中的数据文件包含多个数据文件组,每个数据文件组中又包含.head、.data和.last三个文件,如(v2f1801.head、v2f1801.data、v2f1801.last)数据文件组。TSDB中的数据文件组是按照时间跨度进行分片的,默认是10天一个文件组,且可通过配置文件及建库选项进行配置。分片的数据文件组又按照编号递增排列,方便快速定位某一时间段的时序数据,高效定位数据文件组。时序数据在TSDB的数据文件中是以块的形式进行列式存储的,每个块中只包含一张表的数据,且数据在一个块中是按照时间顺序递增排列的。在一个数据文件组中,.head文件负责存储数据块的索引及统计信息,如每个块的位置,压缩算法,时间戳范围等。存储在.head文件中一张表的索引信息是按照数据块中存储的数据的时间递增排列的,方便进行折半查找等工作。.head和.last文件是存储真实数据块的文件,若数据块中的数据累计到一定程度,则会写入.data文件中,否则,会写入.last文件中,等待下次落盘时合并数据写入.data文件中,从而大大减少文件中块的个数,避免数据的过度碎片化。
## Query模块
该模块负责整体系统的查询处理。客户端调用该该模块进行SQL语法解析,并将查询或写入请求发送到vnode,同时负责针对超级表的查询进行二阶段的聚合操作。在Vnode端,该模块调用TSDB模块读取系统中存储的数据进行查询处理。Query模块还定义了系统能够支持的全部查询函数,查询函数的实现机制与查询框架无耦合,可以在不修改查询流程的情况下动态增加查询函数。详细的设计请参见《TDengine 2.0查询模块设计》。
## SYNC模块
该模块实现数据的多副本复制,包括vnode与mnode的数据复制,支持异步和同步两种复制方式,以满足meta data与时序数据不同复制的需求。因为它为mnode与vnode共享,系统为mnode副本预留了一个特殊的vgroup ID:1。因此vnode的ID是从2开始的。
每个vnode/mnode模块实例会有一对应的sync模块实例,他们是一一对应的。详细设计请见《TDengine 2.0 数据复制模块设计》
## WAL模块
该模块负责将新插入的数据写入write ahead log(WAL), 为vnode, mnode共享。以保证服务器crash或其他故障,能从WAL中恢复数据。
每个vnode/mnode模块实例会有一对应的wal模块实例,是完全一一对应的。WAL的落盘操作由两个参数walLevel, fsync控制。看具体场景,如果要100%保证数据不会丢失,需要将walLevel配置为2,fsync设置为0,每条数据插入请求,都会实时落盘后,才会给应用确认
## HTTP模块
该模块负责处理系统对外的RESTful接口,可以通过配置,由dnode启动或停止。
该模块将接收到的RESTful请求,做了各种合法性检查后,将其变成标准的SQL语句,通过taosc的异步接口,将请求发往整个系统中的任一dnode。收到处理后的结果后,再翻译成HTTP协议,返回给应用。
如果HTTP模块启动,就意味着启动了一个taosc的实例。任一一个dnode都可以启动该模块,以实现对RESTful请求的分布式处理。
## Monitor模块
该模块负责检测一个dnode的运行状态,可以通过配置,由dnode启动或停止。原则上,每个dnode都应该启动一个monitor实例。
Monitor采集TDengine里的关键操作,比如创建、删除、更新账号、表、库等,而且周期性的收集CPU、内存、网络等资源的使用情况(采集周期由系统配置参数monitorInterval控制)。获得这些数据后,monitor模块将采集的数据写入系统的日志库(DB名字由系统配置参数monitorDbName控制)。
Monitor模块使用taosc来将采集的数据写入系统,因此每个monitor实例,都有一个taosc运行实例。
编辑
预览
Markdown
is supported
0%
请重试
或
添加新附件
.
添加附件
取消
You are about to add
0
people
to the discussion. Proceed with caution.
先完成此消息的编辑!
取消
想要评论请
注册
或
登录
{kind=link}
{kind=link}
{kind=link}
{kind=link}