Skip to content
体验新版
项目
组织
正在加载...
登录
切换导航
打开侧边栏
慢慢CG
Mace
提交
bdaa5c18
Mace
项目概览
慢慢CG
/
Mace
与 Fork 源项目一致
Fork自
Xiaomi / Mace
通知
1
Star
0
Fork
0
代码
文件
提交
分支
Tags
贡献者
分支图
Diff
Issue
0
列表
看板
标记
里程碑
合并请求
0
DevOps
流水线
流水线任务
计划
Wiki
0
Wiki
分析
仓库
DevOps
项目成员
Pages
Mace
项目概览
项目概览
详情
发布
仓库
仓库
文件
提交
分支
标签
贡献者
分支图
比较
Issue
0
Issue
0
列表
看板
标记
里程碑
合并请求
0
合并请求
0
Pages
DevOps
DevOps
流水线
流水线任务
计划
分析
分析
仓库分析
DevOps
Wiki
0
Wiki
成员
成员
收起侧边栏
关闭侧边栏
动态
分支图
创建新Issue
流水线任务
提交
Issue看板
提交
bdaa5c18
编写于
5月 18, 2018
作者:
Y
yejianwu
浏览文件
操作
浏览文件
下载
差异文件
Merge branch 'master' of v9.git.n.xiaomi.com:deep-computing/mace into load_model_in_pb
上级
221b0c0d
ca12d9f8
变更
72
隐藏空白更改
内联
并排
Showing
72 changed file
with
1284 addition
and
1005 deletion
+1284
-1005
.gitlab-ci.yml
.gitlab-ci.yml
+2
-1
docker/Dockerfile
docker/Dockerfile
+2
-1
docs/faq.md
docs/faq.md
+11
-0
docs/getting_started/docker.md
docs/getting_started/docker.md
+0
-27
docs/getting_started/how_to_build.rst
docs/getting_started/how_to_build.rst
+70
-24
docs/getting_started/introduction.md
docs/getting_started/introduction.md
+0
-8
docs/getting_started/introduction.rst
docs/getting_started/introduction.rst
+46
-0
docs/getting_started/mace-arch.png
docs/getting_started/mace-arch.png
+0
-0
docs/getting_started/op_lists.rst
docs/getting_started/op_lists.rst
+11
-7
docs/getting_started/workflow.jpg
docs/getting_started/workflow.jpg
+0
-0
docs/index.rst
docs/index.rst
+0
-1
mace/core/BUILD
mace/core/BUILD
+6
-1
mace/core/allocator.h
mace/core/allocator.h
+32
-20
mace/core/arg_helper.cc
mace/core/arg_helper.cc
+2
-1
mace/core/buffer.h
mace/core/buffer.h
+97
-35
mace/core/mace.cc
mace/core/mace.cc
+39
-29
mace/core/runtime/cpu/cpu_runtime.cc
mace/core/runtime/cpu/cpu_runtime.cc
+12
-9
mace/core/runtime/opencl/opencl_allocator.cc
mace/core/runtime/opencl/opencl_allocator.cc
+28
-10
mace/core/runtime/opencl/opencl_allocator.h
mace/core/runtime/opencl/opencl_allocator.h
+4
-3
mace/core/tensor.h
mace/core/tensor.h
+21
-12
mace/core/workspace.cc
mace/core/workspace.cc
+27
-10
mace/core/workspace.h
mace/core/workspace.h
+5
-4
mace/kernels/arm/conv_2d_neon.h
mace/kernels/arm/conv_2d_neon.h
+12
-42
mace/kernels/arm/conv_2d_neon_3x3.cc
mace/kernels/arm/conv_2d_neon_3x3.cc
+26
-27
mace/kernels/arm/conv_2d_neon_5x5.cc
mace/kernels/arm/conv_2d_neon_5x5.cc
+13
-13
mace/kernels/arm/conv_2d_neon_7x7.cc
mace/kernels/arm/conv_2d_neon_7x7.cc
+39
-39
mace/kernels/arm/depthwise_conv2d_neon.h
mace/kernels/arm/depthwise_conv2d_neon.h
+6
-18
mace/kernels/arm/depthwise_conv2d_neon_3x3.cc
mace/kernels/arm/depthwise_conv2d_neon_3x3.cc
+38
-41
mace/kernels/conv_2d.h
mace/kernels/conv_2d.h
+64
-99
mace/kernels/conv_pool_2d_util.cc
mace/kernels/conv_pool_2d_util.cc
+1
-0
mace/kernels/deconv_2d.h
mace/kernels/deconv_2d.h
+49
-60
mace/kernels/depth_to_space.h
mace/kernels/depth_to_space.h
+19
-19
mace/kernels/depthwise_conv2d.h
mace/kernels/depthwise_conv2d.h
+37
-55
mace/kernels/gemm.cc
mace/kernels/gemm.cc
+157
-164
mace/kernels/opencl/activation.cc
mace/kernels/opencl/activation.cc
+2
-1
mace/kernels/opencl/addn.cc
mace/kernels/opencl/addn.cc
+2
-1
mace/kernels/opencl/batch_norm.cc
mace/kernels/opencl/batch_norm.cc
+2
-1
mace/kernels/opencl/bias_add.cc
mace/kernels/opencl/bias_add.cc
+4
-2
mace/kernels/opencl/buffer_to_image.cc
mace/kernels/opencl/buffer_to_image.cc
+2
-1
mace/kernels/opencl/channel_shuffle.cc
mace/kernels/opencl/channel_shuffle.cc
+2
-1
mace/kernels/opencl/concat.cc
mace/kernels/opencl/concat.cc
+4
-2
mace/kernels/opencl/conv_2d_1x1.cc
mace/kernels/opencl/conv_2d_1x1.cc
+2
-1
mace/kernels/opencl/conv_2d_3x3.cc
mace/kernels/opencl/conv_2d_3x3.cc
+2
-1
mace/kernels/opencl/conv_2d_general.cc
mace/kernels/opencl/conv_2d_general.cc
+2
-1
mace/kernels/opencl/deconv_2d_opencl.cc
mace/kernels/opencl/deconv_2d_opencl.cc
+2
-1
mace/kernels/opencl/depth_to_space.cc
mace/kernels/opencl/depth_to_space.cc
+2
-1
mace/kernels/opencl/depthwise_conv.cc
mace/kernels/opencl/depthwise_conv.cc
+2
-1
mace/kernels/opencl/eltwise.cc
mace/kernels/opencl/eltwise.cc
+2
-1
mace/kernels/opencl/fully_connected.cc
mace/kernels/opencl/fully_connected.cc
+4
-2
mace/kernels/opencl/image_to_buffer.cc
mace/kernels/opencl/image_to_buffer.cc
+2
-1
mace/kernels/opencl/matmul.cc
mace/kernels/opencl/matmul.cc
+2
-1
mace/kernels/opencl/out_of_range_check_test.cc
mace/kernels/opencl/out_of_range_check_test.cc
+2
-1
mace/kernels/opencl/pad.cc
mace/kernels/opencl/pad.cc
+2
-1
mace/kernels/opencl/pooling.cc
mace/kernels/opencl/pooling.cc
+2
-1
mace/kernels/opencl/resize_bilinear.cc
mace/kernels/opencl/resize_bilinear.cc
+2
-1
mace/kernels/opencl/slice.cc
mace/kernels/opencl/slice.cc
+2
-1
mace/kernels/opencl/softmax.cc
mace/kernels/opencl/softmax.cc
+2
-1
mace/kernels/opencl/space_to_batch.cc
mace/kernels/opencl/space_to_batch.cc
+2
-1
mace/kernels/opencl/winograd_transform.cc
mace/kernels/opencl/winograd_transform.cc
+4
-2
mace/kernels/pooling.h
mace/kernels/pooling.h
+58
-95
mace/ops/activation.h
mace/ops/activation.h
+1
-1
mace/ops/ops_test_util.h
mace/ops/ops_test_util.h
+2
-0
mace/public/mace.h
mace/public/mace.h
+11
-6
mace/python/tools/converter.py
mace/python/tools/converter.py
+1
-1
mace/python/tools/converter_tool/base_converter.py
mace/python/tools/converter_tool/base_converter.py
+22
-18
mace/python/tools/converter_tool/tensorflow_converter.py
mace/python/tools/converter_tool/tensorflow_converter.py
+22
-1
mace/python/tools/converter_tool/transformer.py
mace/python/tools/converter_tool/transformer.py
+144
-47
mace/python/tools/mace_engine_factory.h.jinja2
mace/python/tools/mace_engine_factory.h.jinja2
+5
-6
mace/python/tools/tf_dsp_converter_lib.py
mace/python/tools/tf_dsp_converter_lib.py
+75
-17
mace/test/mace_api_mt_test.cc
mace/test/mace_api_mt_test.cc
+4
-2
mace/test/mace_api_test.cc
mace/test/mace_api_test.cc
+4
-2
mace/utils/logging.cc
mace/utils/logging.cc
+1
-0
未找到文件。
.gitlab-ci.yml
浏览文件 @
bdaa5c18
...
@@ -25,7 +25,8 @@ docs:
...
@@ -25,7 +25,8 @@ docs:
-
cd docs
-
cd docs
-
make html
-
make html
-
CI_LATEST_OUTPUT_PATH=/mace-build-output/$CI_PROJECT_NAME/latest
-
CI_LATEST_OUTPUT_PATH=/mace-build-output/$CI_PROJECT_NAME/latest
-
CI_JOB_OUTPUT_PATH=/mace-build-output/$CI_PROJECT_NAME/$CI_BUILD_ID
-
CI_JOB_OUTPUT_PATH=/mace-build-output/$CI_PROJECT_NAME/$CI_PIPELINE_ID
-
rm -rf $CI_JOB_OUTPUT_PATH
-
mkdir -p $CI_JOB_OUTPUT_PATH
-
mkdir -p $CI_JOB_OUTPUT_PATH
-
cp -r _build/html $CI_JOB_OUTPUT_PATH/docs
-
cp -r _build/html $CI_JOB_OUTPUT_PATH/docs
-
rm -rf $CI_LATEST_OUTPUT_PATH
-
rm -rf $CI_LATEST_OUTPUT_PATH
...
...
docker/Dockerfile
浏览文件 @
bdaa5c18
...
@@ -110,7 +110,8 @@ RUN apt-get install -y --no-install-recommends \
...
@@ -110,7 +110,8 @@ RUN apt-get install -y --no-install-recommends \
# Install tools
# Install tools
RUN
pip
install
-i
http://pypi.douban.com/simple/
--trusted-host
pypi.douban.com setuptools
RUN
pip
install
-i
http://pypi.douban.com/simple/
--trusted-host
pypi.douban.com setuptools
RUN
pip
install
-i
http://pypi.douban.com/simple/
--trusted-host
pypi.douban.com
tensorflow
==
1.6.0
\
RUN
pip
install
-i
http://pypi.douban.com/simple/
--trusted-host
pypi.douban.com
tensorflow
==
1.7.0
\
numpy>
=
1.14.0
\
scipy
\
scipy
\
jinja2
\
jinja2
\
pyyaml
\
pyyaml
\
...
...
docs/faq.md
浏览文件 @
bdaa5c18
Frequently asked questions
Frequently asked questions
==========================
==========================
Does the tensor data consume extra memory when compiled into C++ code?
----------------------------------------------------------------------
When compiled into C++ code, the data will be mmaped by the system loader.
For CPU runtime, the tensor data are used without memory copy.
For GPU and DSP runtime, the tensor data is used once during model
initialization. The operating system is free to swap the pages out, however,
it still consumes virtual memory space. So generally speaking, it takes
no extra physical memory. If you are short of virtual memory space (this
should be very rare), you can choose load the tensor data from a file, which
can be unmapped after initialization.
Why is the generated static library file size so huge?
Why is the generated static library file size so huge?
-------------------------------------------------------
-------------------------------------------------------
The static library is simply an archive of a set of object files which are
The static library is simply an archive of a set of object files which are
...
...
docs/getting_started/docker.md
已删除
100644 → 0
浏览文件 @
221b0c0d
Docker Images
=============
*
Login in
[
Xiaomi Docker Registry
](
http://docs.api.xiaomi.net/docker-registry/
)
```
docker login cr.d.xiaomi.net
```
*
Build with
`Dockerfile`
```
docker build -t cr.d.xiaomi.net/mace/mace-dev
```
*
Pull image from docker registry
```
docker pull cr.d.xiaomi.net/mace/mace-dev
```
*
Create container
```
# Set 'host' network to use ADB
docker run -it --rm -v /local/path:/container/path --net=host cr.d.xiaomi.net/mace/mace-dev /bin/bash
```
docs/getting_started/how_to_build.rst
浏览文件 @
bdaa5c18
...
@@ -33,11 +33,13 @@ How to build
...
@@ -33,11 +33,13 @@ How to build
+=====================+=================+===================================================================================================+
+=====================+=================+===================================================================================================+
| bazel | >= 0.5.4 | - |
| bazel | >= 0.5.4 | - |
+---------------------+-----------------+---------------------------------------------------------------------------------------------------+
+---------------------+-----------------+---------------------------------------------------------------------------------------------------+
| android-ndk | r1
2c
| - |
| android-ndk | r1
5c,r16b
| - |
+---------------------+-----------------+---------------------------------------------------------------------------------------------------+
+---------------------+-----------------+---------------------------------------------------------------------------------------------------+
| adb | >= 1.0.32 | apt install -y android-tools-adb |
| adb | >= 1.0.32 | apt install -y android-tools-adb |
+---------------------+-----------------+---------------------------------------------------------------------------------------------------+
+---------------------+-----------------+---------------------------------------------------------------------------------------------------+
| tensorflow | 1.4.0 | pip install tensorflow==1.4.0 |
| tensorflow | 1.7.0 | pip install tensorflow==1.7.0 |
+---------------------+-----------------+---------------------------------------------------------------------------------------------------+
| numpy | >= 1.14.0 | pip install numpy |
+---------------------+-----------------+---------------------------------------------------------------------------------------------------+
+---------------------+-----------------+---------------------------------------------------------------------------------------------------+
| scipy | >= 1.0.0 | pip install scipy |
| scipy | >= 1.0.0 | pip install scipy |
+---------------------+-----------------+---------------------------------------------------------------------------------------------------+
+---------------------+-----------------+---------------------------------------------------------------------------------------------------+
...
@@ -45,9 +47,43 @@ How to build
...
@@ -45,9 +47,43 @@ How to build
+---------------------+-----------------+---------------------------------------------------------------------------------------------------+
+---------------------+-----------------+---------------------------------------------------------------------------------------------------+
| PyYaml | >= 3.12 | pip install pyyaml |
| PyYaml | >= 3.12 | pip install pyyaml |
+---------------------+-----------------+---------------------------------------------------------------------------------------------------+
+---------------------+-----------------+---------------------------------------------------------------------------------------------------+
| sh | >= 1.12.14 | pip install sh |
+---------------------+-----------------+---------------------------------------------------------------------------------------------------+
| filelock | >= 3.0.0 | pip install filelock |
+---------------------+-----------------+---------------------------------------------------------------------------------------------------+
| docker(for caffe) | >= 17.09.0-ce | `install doc <https://docs.docker.com/install/linux/docker-ce/ubuntu/#set-up-the-repository>`__ |
| docker(for caffe) | >= 17.09.0-ce | `install doc <https://docs.docker.com/install/linux/docker-ce/ubuntu/#set-up-the-repository>`__ |
+---------------------+-----------------+---------------------------------------------------------------------------------------------------+
+---------------------+-----------------+---------------------------------------------------------------------------------------------------+
Docker Images
----------------
* Login in `Xiaomi Docker Registry <http://docs.api.xiaomi.net/docker-registry/>`__
.. code:: sh
docker login cr.d.xiaomi.net
* Build with Dockerfile
.. code:: sh
docker build -t cr.d.xiaomi.net/mace/mace-dev
* Pull image from docker registry
.. code:: sh
docker pull cr.d.xiaomi.net/mace/mace-dev
* Create container
.. code:: sh
# Set 'host' network to use ADB
docker run -it --rm -v /local/path:/container/path --net=host cr.d.xiaomi.net/mace/mace-dev /bin/bash
使用简介
使用简介
--------
--------
...
@@ -199,29 +235,47 @@ Caffe目前只支持最新版本,旧版本请使用Caffe的工具进行升级
...
@@ -199,29 +235,47 @@ Caffe目前只支持最新版本,旧版本请使用Caffe的工具进行升级
// 引入头文件
// 引入头文件
#include "mace/public/mace.h"
#include "mace/public/mace.h"
#include "mace/public/
{MODEL_TAG}
.h"
#include "mace/public/
mace_engine_factory
.h"
// 0. 设置内部存储
// 0. 设置内部存储
(设置一次即可)
const std::string file_path ="/path/to/store/internel/files";
const std::string file_path ="/path/to/store/internel/files";
std::shared_ptr<KVStorageFactory> storage_factory(
std::shared_ptr<KVStorageFactory> storage_factory(
new FileStorageFactory(file_path));
new FileStorageFactory(file_path));
ConfigKVStorageFactory(storage_factory);
ConfigKVStorageFactory(storage_factory);
//1. 从文件或代码中Load模型数据,也可通过自定义的方式来Load (例如可自己实现压缩加密等)
//1. 声明设备类型(必须与build时指定的runtime一致)
// 如果使用的是数据嵌入的方式,将参数设为nullptr。
DeviceType device_type = DeviceType::GPU;
unsigned char *model_data = mace::MACE_MODEL_TAG::LoadModelData(FLAGS_model_data_file.c_str());
//2. 创建net对象
NetDef net_def = mace::MACE_MODEL_TAG::CreateNet(model_data);
//3. 声明设备类型(必须与build时指定的runtime一致)
//2. 定义输入输出名称数组
DeviceType device_type = DeviceType::OPENCL;
//4. 定义输入输出名称数组
std::vector<std::string> input_names = {...};
std::vector<std::string> input_names = {...};
std::vector<std::string> output_names = {...};
std::vector<std::string> output_names = {...};
//5. 创建输入输出对象
//3. 创建MaceEngine对象
std::shared_ptr<mace::MaceEngine> engine;
MaceStatus create_engine_status;
// Create Engine
if (model_data_file.empty()) {
create_engine_status =
CreateMaceEngine(model_name.c_str(),
nullptr,
input_names,
output_names,
device_type,
&engine);
} else {
create_engine_status =
CreateMaceEngine(model_name.c_str(),
model_data_file.c_str(),
input_names,
output_names,
device_type,
&engine);
}
if (create_engine_status != MaceStatus::MACE_SUCCESS) {
// do something
}
//4. 创建输入输出对象
std::map<std::string, mace::MaceTensor> inputs;
std::map<std::string, mace::MaceTensor> inputs;
std::map<std::string, mace::MaceTensor> outputs;
std::map<std::string, mace::MaceTensor> outputs;
for (size_t i = 0; i < input_count; ++i) {
for (size_t i = 0; i < input_count; ++i) {
...
@@ -246,14 +300,6 @@ Caffe目前只支持最新版本,旧版本请使用Caffe的工具进行升级
...
@@ -246,14 +300,6 @@ Caffe目前只支持最新版本,旧版本请使用Caffe的工具进行升级
outputs[output_names[i]] = mace::MaceTensor(output_shapes[i], buffer_out);
outputs[output_names[i]] = mace::MaceTensor(output_shapes[i], buffer_out);
}
}
//6. 创建MaceEngine对象
//5. 执行模型,得到结果
mace::MaceEngine engine(&net_def, device_type, input_names, output_names);
//7. 如果设备类型是OPENCL或HEXAGON,可以在此释放model_data
if (device_type == DeviceType::OPENCL || device_type == DeviceType::HEXAGON) {
mace::MACE_MODEL_TAG::UnloadModelData(model_data);
}
//8. 执行模型,得到结果
engine.Run(inputs, &outputs);
engine.Run(inputs, &outputs);
docs/getting_started/introduction.md
已删除
100644 → 0
浏览文件 @
221b0c0d
Introduction
============
TODO: describe the conceptions and workflow with diagram.

TODO: describe the runtime.
docs/getting_started/introduction.rst
0 → 100644
浏览文件 @
bdaa5c18
Introduction
============
MiAI
Compute
Engine
is
a
deep
learning
inference
framework
optimized
for
mobile
heterogeneous
computing
platforms
.
The
following
figure
shows
the
overall
architecture
.
..
image
::
mace
-
arch
.
png
:
scale
:
40
%
:
align
:
center
Model
format
------------
MiAI
Compute
Engine
defines
a
customized
model
format
which
is
similar
to
Caffe2
.
The
MiAI
model
can
be
converted
from
exported
models
by
TensorFlow
and
Caffe
.
We
define
a
YAML
schema
to
describe
the
model
deployment
.
In
the
next
chapter
,
there
is
a
detailed
guide
showing
how
to
create
this
YAML
file
.
Model
conversion
----------------
Currently
,
we
provide
model
converters
for
TensorFlow
and
Caffe
.
And
more
frameworks
will
be
supported
in
the
future
.
Model
loading
-------------
The
MiAI
model
format
contains
two
parts
:
the
model
graph
definition
and
the
model
parameter
tensors
.
The
graph
part
utilizes
Protocol
Buffers
for
serialization
.
All
the
model
parameter
tensors
are
concatenated
together
into
a
continuous
array
,
and
we
call
this
array
tensor
data
in
the
following
paragraphs
.
In
the
model
graph
,
the
tensor
data
offsets
and
lengths
are
recorded
.
The
models
can
be
loaded
in
3
ways
:
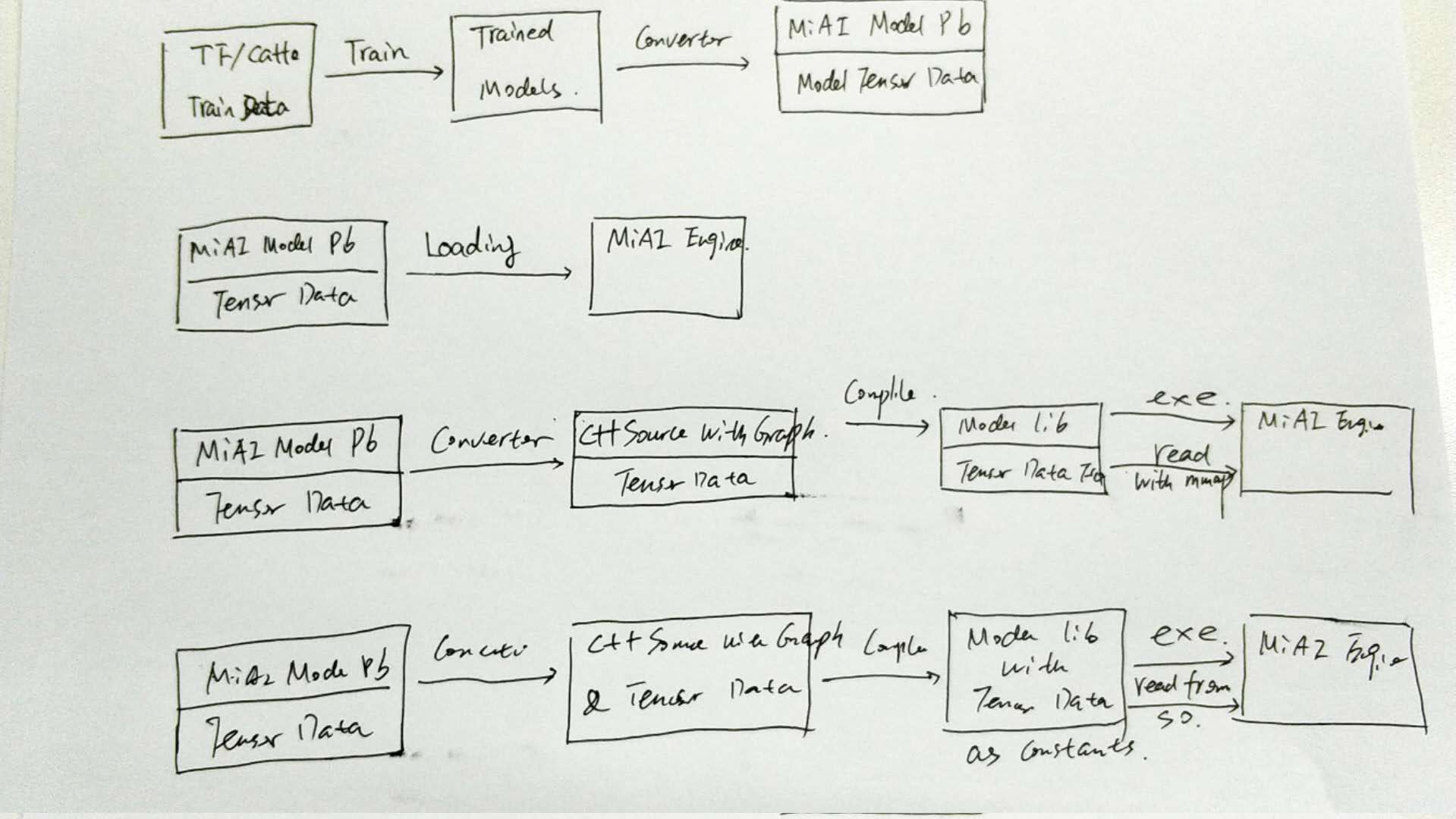
1.
Both
model
graph
and
tensor
data
are
dynamically
loaded
externally
(
by
default
,
from
file
system
,
but
the
users
are
free
to
choose
their
own
implementations
,
for
example
,
with
compression
or
encryption
).
This
approach
provides
the
most
flexibility
but
the
weakest
model
protection
.
2.
Both
model
graph
and
tensor
data
are
converted
into
C
++
code
and
loaded
by
executing
the
compiled
code
.
This
approach
provides
the
strongest
model
protection
and
simplest
deployment
.
3.
The
model
graph
is
converted
into
C
++
code
and
constructed
as
the
second
approach
,
and
the
tensor
data
is
loaded
externally
as
the
first
approach
.
docs/getting_started/mace-arch.png
0 → 100644
浏览文件 @
bdaa5c18
18.2 KB
docs/getting_started/op_lists.rst
浏览文件 @
bdaa5c18
...
@@ -6,20 +6,22 @@ Operator lists
...
@@ -6,20 +6,22 @@ Operator lists
:widths: auto
:widths: auto
:header: "Operator","Android NN","Supported","Remark"
:header: "Operator","Android NN","Supported","Remark"
"ADD","Y","Y",""
"AVERAGE_POOL_2D","Y","Y",""
"AVERAGE_POOL_2D","Y","Y",""
"BATCH_NORM","","Y","Fusion with activation is supported"
"BATCH_NORM","","Y","Fusion with activation is supported"
"BATCH_TO_SPACE_ND","Y","Y",""
"BIAS_ADD","","Y",""
"BIAS_ADD","","Y",""
"CHANNEL_SHUFFLE","","Y",""
"CHANNEL_SHUFFLE","","Y",""
"CONCATENATION","Y","Y",""
"CONCATENATION","Y","Y","
Only support channel axis concatenation
"
"CONV_2D","Y","Y","Fusion with BN and activation layer is supported"
"CONV_2D","Y","Y","Fusion with BN and activation layer is supported"
"DECONV_2D","N","Y","Only tensorflow model is supported"
"DEPTHWISE_CONV_2D","Y","Y","Only multiplier = 1 is supported; Fusion is supported"
"DEPTHWISE_CONV_2D","Y","Y","Only multiplier = 1 is supported; Fusion is supported"
"DEPTH_TO_SPACE","Y","Y",""
"DEPTH_TO_SPACE","Y","Y",""
"DEQUANTIZE","Y","",""
"DEQUANTIZE","Y","Y","Model quantization will be supported later"
"ELEMENT_WISE","Y","Y","ADD/MUL/DIV/MIN/MAX/NEG/ABS/SQR_DIFF/POW"
"EMBEDDING_LOOKUP","Y","",""
"EMBEDDING_LOOKUP","Y","",""
"FLOOR","Y","",""
"FLOOR","Y","",""
"FULLY_CONNECTED","Y","Y",""
"FULLY_CONNECTED","Y","Y",""
"GROUP_CONV_2D","","",""
"GROUP_CONV_2D","","","
Caffe model with group count = channel count is supported
"
"HASHTABLE_LOOKUP","Y","",""
"HASHTABLE_LOOKUP","Y","",""
"L2_NORMALIZATION","Y","",""
"L2_NORMALIZATION","Y","",""
"L2_POOL_2D","Y","",""
"L2_POOL_2D","Y","",""
...
@@ -29,18 +31,20 @@ Operator lists
...
@@ -29,18 +31,20 @@ Operator lists
"LSTM","Y","",""
"LSTM","Y","",""
"MATMUL","","Y",""
"MATMUL","","Y",""
"MAX_POOL_2D","Y","Y",""
"MAX_POOL_2D","Y","Y",""
"
MUL","Y","
",""
"
PAD", "N","Y
",""
"PSROI_ALIGN","","Y",""
"PSROI_ALIGN","","Y",""
"PRELU","","Y",""
"PRELU","","Y","
Only caffe model is supported
"
"RELU","Y","Y",""
"RELU","Y","Y",""
"RELU1","Y","Y",""
"RELU1","Y","Y",""
"RELU6","Y","Y",""
"RELU6","Y","Y",""
"RELUX","","Y",""
"RELUX","","Y",""
"RESHAPE","Y","Y","Limited support"
"RESHAPE","Y","Y","Limited support
: only internal use of reshape in composed operations is supported
"
"RESIZE_BILINEAR","Y","Y",""
"RESIZE_BILINEAR","Y","Y",""
"RNN","Y","",""
"RNN","Y","",""
"RPN_PROPOSAL_LAYER","","Y",""
"RPN_PROPOSAL_LAYER","","Y",""
"SLICE","N","Y","Only support channel axis slice"
"SOFTMAX","Y","Y",""
"SOFTMAX","Y","Y",""
"SPACE_TO_BATCH_ND","Y", "Y",""
"SPACE_TO_DEPTH","Y","Y",""
"SPACE_TO_DEPTH","Y","Y",""
"SVDF","Y","",""
"SVDF","Y","",""
"TANH","Y","Y",""
"TANH","Y","Y",""
docs/getting_started/workflow.jpg
已删除
100644 → 0
浏览文件 @
221b0c0d
116.3 KB
docs/index.rst
浏览文件 @
bdaa5c18
...
@@ -11,7 +11,6 @@ The main documentation is organized into the following sections:
...
@@ -11,7 +11,6 @@ The main documentation is organized into the following sections:
getting_started/introduction
getting_started/introduction
getting_started/create_a_model_deployment
getting_started/create_a_model_deployment
getting_started/docker
getting_started/how_to_build
getting_started/how_to_build
getting_started/op_lists
getting_started/op_lists
...
...
mace/core/BUILD
浏览文件 @
bdaa5c18
...
@@ -15,6 +15,7 @@ load(
...
@@ -15,6 +15,7 @@ load(
"if_production_mode"
,
"if_production_mode"
,
"if_not_production_mode"
,
"if_not_production_mode"
,
"if_openmp_enabled"
,
"if_openmp_enabled"
,
"if_neon_enabled"
,
)
)
cc_library
(
cc_library
(
...
@@ -51,7 +52,11 @@ cc_library(
...
@@ -51,7 +52,11 @@ cc_library(
"-DMACE_ENABLE_OPENMP"
,
"-DMACE_ENABLE_OPENMP"
,
])
+
if_android
([
])
+
if_android
([
"-DMACE_ENABLE_OPENCL"
,
"-DMACE_ENABLE_OPENCL"
,
])
+
if_hexagon_enabled
([
"-DMACE_ENABLE_HEXAGON"
]),
])
+
if_hexagon_enabled
([
"-DMACE_ENABLE_HEXAGON"
,
])
+
if_neon_enabled
([
"-DMACE_ENABLE_NEON"
,
]),
linkopts
=
[
"-ldl"
]
+
if_android
([
linkopts
=
[
"-ldl"
]
+
if_android
([
"-pie"
,
"-pie"
,
"-lm"
,
"-lm"
,
...
...
mace/core/allocator.h
浏览文件 @
bdaa5c18
...
@@ -16,6 +16,7 @@
...
@@ -16,6 +16,7 @@
#define MACE_CORE_ALLOCATOR_H_
#define MACE_CORE_ALLOCATOR_H_
#include <stdlib.h>
#include <stdlib.h>
#include <string.h>
#include <map>
#include <map>
#include <limits>
#include <limits>
#include <vector>
#include <vector>
...
@@ -42,9 +43,10 @@ class Allocator {
...
@@ -42,9 +43,10 @@ class Allocator {
public:
public:
Allocator
()
{}
Allocator
()
{}
virtual
~
Allocator
()
noexcept
{}
virtual
~
Allocator
()
noexcept
{}
virtual
void
*
New
(
size_t
nbytes
)
const
=
0
;
virtual
MaceStatus
New
(
size_t
nbytes
,
void
**
result
)
const
=
0
;
virtual
void
*
NewImage
(
const
std
::
vector
<
size_t
>
&
image_shape
,
virtual
MaceStatus
NewImage
(
const
std
::
vector
<
size_t
>
&
image_shape
,
const
DataType
dt
)
const
=
0
;
const
DataType
dt
,
void
**
result
)
const
=
0
;
virtual
void
Delete
(
void
*
data
)
const
=
0
;
virtual
void
Delete
(
void
*
data
)
const
=
0
;
virtual
void
DeleteImage
(
void
*
data
)
const
=
0
;
virtual
void
DeleteImage
(
void
*
data
)
const
=
0
;
virtual
void
*
Map
(
void
*
buffer
,
size_t
offset
,
size_t
nbytes
)
const
=
0
;
virtual
void
*
Map
(
void
*
buffer
,
size_t
offset
,
size_t
nbytes
)
const
=
0
;
...
@@ -53,44 +55,54 @@ class Allocator {
...
@@ -53,44 +55,54 @@ class Allocator {
std
::
vector
<
size_t
>
*
mapped_image_pitch
)
const
=
0
;
std
::
vector
<
size_t
>
*
mapped_image_pitch
)
const
=
0
;
virtual
void
Unmap
(
void
*
buffer
,
void
*
mapper_ptr
)
const
=
0
;
virtual
void
Unmap
(
void
*
buffer
,
void
*
mapper_ptr
)
const
=
0
;
virtual
bool
OnHost
()
const
=
0
;
virtual
bool
OnHost
()
const
=
0
;
template
<
typename
T
>
T
*
New
(
size_t
num_elements
)
{
if
(
num_elements
>
(
std
::
numeric_limits
<
size_t
>::
max
()
/
sizeof
(
T
)))
{
return
nullptr
;
}
void
*
p
=
New
(
sizeof
(
T
)
*
num_elements
);
T
*
typed_p
=
reinterpret_cast
<
T
*>
(
p
);
return
typed_p
;
}
};
};
class
CPUAllocator
:
public
Allocator
{
class
CPUAllocator
:
public
Allocator
{
public:
public:
~
CPUAllocator
()
override
{}
~
CPUAllocator
()
override
{}
void
*
New
(
size_t
nbytes
)
const
override
{
MaceStatus
New
(
size_t
nbytes
,
void
**
result
)
const
override
{
VLOG
(
3
)
<<
"Allocate CPU buffer: "
<<
nbytes
;
VLOG
(
3
)
<<
"Allocate CPU buffer: "
<<
nbytes
;
if
(
nbytes
==
0
)
{
return
MaceStatus
::
MACE_SUCCESS
;
}
void
*
data
=
nullptr
;
void
*
data
=
nullptr
;
#if defined(__ANDROID__) || defined(__hexagon__)
#if defined(__ANDROID__) || defined(__hexagon__)
data
=
memalign
(
kMaceAlignment
,
nbytes
);
data
=
memalign
(
kMaceAlignment
,
nbytes
);
if
(
data
==
NULL
)
{
LOG
(
WARNING
)
<<
"Allocate CPU Buffer with "
<<
nbytes
<<
" bytes failed because of"
<<
strerror
(
errno
);
*
result
=
nullptr
;
return
MaceStatus
::
MACE_OUT_OF_RESOURCES
;
}
#else
#else
MACE_CHECK
(
posix_memalign
(
&
data
,
kMaceAlignment
,
nbytes
)
==
0
);
int
ret
=
posix_memalign
(
&
data
,
kMaceAlignment
,
nbytes
);
if
(
ret
!=
0
)
{
LOG
(
WARNING
)
<<
"Allocate CPU Buffer with "
<<
nbytes
<<
" bytes failed because of"
<<
strerror
(
errno
);
*
result
=
nullptr
;
return
MaceStatus
::
MACE_OUT_OF_RESOURCES
;
}
#endif
#endif
MACE_CHECK_NOTNULL
(
data
);
// TODO(heliangliang) This should be avoided sometimes
// TODO(heliangliang) This should be avoided sometimes
memset
(
data
,
0
,
nbytes
);
memset
(
data
,
0
,
nbytes
);
return
data
;
*
result
=
data
;
return
MaceStatus
::
MACE_SUCCESS
;
}
}
void
*
NewImage
(
const
std
::
vector
<
size_t
>
&
shape
,
MaceStatus
NewImage
(
const
std
::
vector
<
size_t
>
&
shape
,
const
DataType
dt
)
const
override
{
const
DataType
dt
,
void
**
result
)
const
override
{
MACE_UNUSED
(
shape
);
MACE_UNUSED
(
shape
);
MACE_UNUSED
(
dt
);
MACE_UNUSED
(
dt
);
MACE_UNUSED
(
result
);
LOG
(
FATAL
)
<<
"Allocate CPU image"
;
LOG
(
FATAL
)
<<
"Allocate CPU image"
;
return
nullptr
;
return
MaceStatus
::
MACE_SUCCESS
;
}
}
void
Delete
(
void
*
data
)
const
override
{
void
Delete
(
void
*
data
)
const
override
{
MACE_CHECK_NOTNULL
(
data
);
VLOG
(
3
)
<<
"Free CPU buffer"
;
VLOG
(
3
)
<<
"Free CPU buffer"
;
free
(
data
);
free
(
data
);
}
}
...
...
mace/core/arg_helper.cc
浏览文件 @
bdaa5c18
...
@@ -23,7 +23,8 @@ namespace mace {
...
@@ -23,7 +23,8 @@ namespace mace {
ArgumentHelper
::
ArgumentHelper
(
const
OperatorDef
&
def
)
{
ArgumentHelper
::
ArgumentHelper
(
const
OperatorDef
&
def
)
{
for
(
auto
&
arg
:
def
.
arg
())
{
for
(
auto
&
arg
:
def
.
arg
())
{
if
(
arg_map_
.
find
(
arg
.
name
())
!=
arg_map_
.
end
())
{
if
(
arg_map_
.
find
(
arg
.
name
())
!=
arg_map_
.
end
())
{
LOG
(
WARNING
)
<<
"Duplicated argument name found in operator def."
;
LOG
(
WARNING
)
<<
"Duplicated argument name found in operator def: "
<<
def
.
name
()
<<
" "
<<
arg
.
name
();
}
}
arg_map_
[
arg
.
name
()]
=
arg
;
arg_map_
[
arg
.
name
()]
=
arg
;
...
...
mace/core/buffer.h
浏览文件 @
bdaa5c18
...
@@ -38,6 +38,11 @@ class BufferBase {
...
@@ -38,6 +38,11 @@ class BufferBase {
virtual
void
*
raw_mutable_data
()
=
0
;
virtual
void
*
raw_mutable_data
()
=
0
;
virtual
MaceStatus
Allocate
(
index_t
nbytes
)
=
0
;
virtual
MaceStatus
Allocate
(
const
std
::
vector
<
size_t
>
&
shape
,
DataType
data_type
)
=
0
;
virtual
void
*
Map
(
index_t
offset
,
virtual
void
*
Map
(
index_t
offset
,
index_t
length
,
index_t
length
,
std
::
vector
<
size_t
>
*
pitch
)
const
=
0
;
std
::
vector
<
size_t
>
*
pitch
)
const
=
0
;
...
@@ -48,7 +53,7 @@ class BufferBase {
...
@@ -48,7 +53,7 @@ class BufferBase {
virtual
void
UnMap
()
=
0
;
virtual
void
UnMap
()
=
0
;
virtual
void
Resize
(
index_t
size
)
=
0
;
virtual
MaceStatus
Resize
(
index_t
nbytes
)
=
0
;
virtual
void
Copy
(
void
*
src
,
index_t
offset
,
index_t
length
)
=
0
;
virtual
void
Copy
(
void
*
src
,
index_t
offset
,
index_t
length
)
=
0
;
...
@@ -56,6 +61,8 @@ class BufferBase {
...
@@ -56,6 +61,8 @@ class BufferBase {
virtual
void
Clear
()
=
0
;
virtual
void
Clear
()
=
0
;
virtual
void
Clear
(
index_t
size
)
=
0
;
virtual
index_t
offset
()
const
{
return
0
;
}
virtual
index_t
offset
()
const
{
return
0
;
}
template
<
typename
T
>
template
<
typename
T
>
...
@@ -83,14 +90,6 @@ class Buffer : public BufferBase {
...
@@ -83,14 +90,6 @@ class Buffer : public BufferBase {
mapped_buf_
(
nullptr
),
mapped_buf_
(
nullptr
),
is_data_owner_
(
true
)
{}
is_data_owner_
(
true
)
{}
Buffer
(
Allocator
*
allocator
,
index_t
size
)
:
BufferBase
(
size
),
allocator_
(
allocator
),
mapped_buf_
(
nullptr
),
is_data_owner_
(
true
)
{
buf_
=
allocator
->
New
(
size
);
}
Buffer
(
Allocator
*
allocator
,
void
*
data
,
index_t
size
)
Buffer
(
Allocator
*
allocator
,
void
*
data
,
index_t
size
)
:
BufferBase
(
size
),
:
BufferBase
(
size
),
allocator_
(
allocator
),
allocator_
(
allocator
),
...
@@ -132,6 +131,31 @@ class Buffer : public BufferBase {
...
@@ -132,6 +131,31 @@ class Buffer : public BufferBase {
}
}
}
}
MaceStatus
Allocate
(
index_t
nbytes
)
{
if
(
nbytes
<=
0
)
{
return
MaceStatus
::
MACE_SUCCESS
;
}
MACE_CHECK
(
is_data_owner_
,
"data is not owned by this buffer, cannot reallocate"
);
if
(
mapped_buf_
!=
nullptr
)
{
UnMap
();
}
if
(
buf_
!=
nullptr
)
{
allocator_
->
Delete
(
buf_
);
}
size_
=
nbytes
;
return
allocator_
->
New
(
nbytes
,
&
buf_
);
}
MaceStatus
Allocate
(
const
std
::
vector
<
size_t
>
&
shape
,
DataType
data_type
)
{
if
(
shape
.
empty
())
return
MaceStatus
::
MACE_SUCCESS
;
index_t
nbytes
=
std
::
accumulate
(
shape
.
begin
(),
shape
.
end
(),
1
,
std
::
multiplies
<
size_t
>
())
*
GetEnumTypeSize
(
data_type
);
return
this
->
Allocate
(
nbytes
);
}
void
*
Map
(
index_t
offset
,
index_t
length
,
std
::
vector
<
size_t
>
*
pitch
)
const
{
void
*
Map
(
index_t
offset
,
index_t
length
,
std
::
vector
<
size_t
>
*
pitch
)
const
{
MACE_CHECK_NOTNULL
(
buf_
);
MACE_CHECK_NOTNULL
(
buf_
);
MACE_UNUSED
(
pitch
);
MACE_UNUSED
(
pitch
);
...
@@ -154,16 +178,17 @@ class Buffer : public BufferBase {
...
@@ -154,16 +178,17 @@ class Buffer : public BufferBase {
mapped_buf_
=
nullptr
;
mapped_buf_
=
nullptr
;
}
}
void
Resize
(
index_t
size
)
{
MaceStatus
Resize
(
index_t
nbytes
)
{
MACE_CHECK
(
is_data_owner_
,
MACE_CHECK
(
is_data_owner_
,
"data is not owned by this buffer, cannot resize"
);
"data is not owned by this buffer, cannot resize"
);
if
(
size
!=
size_
)
{
if
(
nbytes
!=
size_
)
{
if
(
buf_
!=
nullptr
)
{
if
(
buf_
!=
nullptr
)
{
allocator_
->
Delete
(
buf_
);
allocator_
->
Delete
(
buf_
);
}
}
size_
=
size
;
size_
=
nbytes
;
buf_
=
allocator_
->
New
(
size
);
return
allocator_
->
New
(
nbytes
,
&
buf_
);
}
}
return
MaceStatus
::
MACE_SUCCESS
;
}
}
void
Copy
(
void
*
src
,
index_t
offset
,
index_t
length
)
{
void
Copy
(
void
*
src
,
index_t
offset
,
index_t
length
)
{
...
@@ -175,7 +200,11 @@ class Buffer : public BufferBase {
...
@@ -175,7 +200,11 @@ class Buffer : public BufferBase {
bool
OnHost
()
const
{
return
allocator_
->
OnHost
();
}
bool
OnHost
()
const
{
return
allocator_
->
OnHost
();
}
void
Clear
()
{
void
Clear
()
{
memset
(
reinterpret_cast
<
char
*>
(
raw_mutable_data
()),
0
,
size_
);
Clear
(
size_
);
}
void
Clear
(
index_t
size
)
{
memset
(
reinterpret_cast
<
char
*>
(
raw_mutable_data
()),
0
,
size
);
}
}
protected:
protected:
...
@@ -195,18 +224,6 @@ class Image : public BufferBase {
...
@@ -195,18 +224,6 @@ class Image : public BufferBase {
buf_
(
nullptr
),
buf_
(
nullptr
),
mapped_buf_
(
nullptr
)
{}
mapped_buf_
(
nullptr
)
{}
Image
(
std
::
vector
<
size_t
>
shape
,
DataType
data_type
)
:
BufferBase
(
std
::
accumulate
(
shape
.
begin
(),
shape
.
end
(),
1
,
std
::
multiplies
<
index_t
>
())
*
GetEnumTypeSize
(
data_type
)),
allocator_
(
GetDeviceAllocator
(
GPU
)),
mapped_buf_
(
nullptr
)
{
shape_
=
shape
;
data_type_
=
data_type
;
buf_
=
allocator_
->
NewImage
(
shape
,
data_type
);
}
virtual
~
Image
()
{
virtual
~
Image
()
{
if
(
mapped_buf_
!=
nullptr
)
{
if
(
mapped_buf_
!=
nullptr
)
{
UnMap
();
UnMap
();
...
@@ -233,6 +250,29 @@ class Image : public BufferBase {
...
@@ -233,6 +250,29 @@ class Image : public BufferBase {
std
::
vector
<
size_t
>
image_shape
()
const
{
return
shape_
;
}
std
::
vector
<
size_t
>
image_shape
()
const
{
return
shape_
;
}
MaceStatus
Allocate
(
index_t
nbytes
)
{
MACE_UNUSED
(
nbytes
);
LOG
(
FATAL
)
<<
"Image should not call this allocate function"
;
return
MaceStatus
::
MACE_SUCCESS
;
}
MaceStatus
Allocate
(
const
std
::
vector
<
size_t
>
&
shape
,
DataType
data_type
)
{
index_t
size
=
std
::
accumulate
(
shape
.
begin
(),
shape
.
end
(),
1
,
std
::
multiplies
<
index_t
>
())
*
GetEnumTypeSize
(
data_type
);
if
(
mapped_buf_
!=
nullptr
)
{
UnMap
();
}
if
(
buf_
!=
nullptr
)
{
allocator_
->
DeleteImage
(
buf_
);
}
size_
=
size
;
shape_
=
shape
;
data_type_
=
data_type
;
return
allocator_
->
NewImage
(
shape
,
data_type
,
&
buf_
);
}
void
*
Map
(
index_t
offset
,
index_t
length
,
std
::
vector
<
size_t
>
*
pitch
)
const
{
void
*
Map
(
index_t
offset
,
index_t
length
,
std
::
vector
<
size_t
>
*
pitch
)
const
{
MACE_UNUSED
(
offset
);
MACE_UNUSED
(
offset
);
MACE_UNUSED
(
length
);
MACE_UNUSED
(
length
);
...
@@ -259,9 +299,10 @@ class Image : public BufferBase {
...
@@ -259,9 +299,10 @@ class Image : public BufferBase {
mapped_buf_
=
nullptr
;
mapped_buf_
=
nullptr
;
}
}
void
Resize
(
index_t
size
)
{
MaceStatus
Resize
(
index_t
size
)
{
MACE_UNUSED
(
size
);
MACE_UNUSED
(
size
);
MACE_NOT_IMPLEMENTED
;
MACE_NOT_IMPLEMENTED
;
return
MaceStatus
::
MACE_SUCCESS
;
}
}
void
Copy
(
void
*
src
,
index_t
offset
,
index_t
length
)
{
void
Copy
(
void
*
src
,
index_t
offset
,
index_t
length
)
{
...
@@ -277,6 +318,11 @@ class Image : public BufferBase {
...
@@ -277,6 +318,11 @@ class Image : public BufferBase {
MACE_NOT_IMPLEMENTED
;
MACE_NOT_IMPLEMENTED
;
}
}
void
Clear
(
index_t
size
)
{
MACE_UNUSED
(
size
);
MACE_NOT_IMPLEMENTED
;
}
private:
private:
Allocator
*
allocator_
;
Allocator
*
allocator_
;
std
::
vector
<
size_t
>
shape_
;
std
::
vector
<
size_t
>
shape_
;
...
@@ -339,6 +385,20 @@ class BufferSlice : public BufferBase {
...
@@ -339,6 +385,20 @@ class BufferSlice : public BufferBase {
}
}
}
}
MaceStatus
Allocate
(
index_t
size
)
{
MACE_UNUSED
(
size
);
LOG
(
FATAL
)
<<
"BufferSlice should not call allocate function"
;
return
MaceStatus
::
MACE_SUCCESS
;
}
MaceStatus
Allocate
(
const
std
::
vector
<
size_t
>
&
shape
,
DataType
data_type
)
{
MACE_UNUSED
(
shape
);
MACE_UNUSED
(
data_type
);
LOG
(
FATAL
)
<<
"BufferSlice should not call allocate function"
;
return
MaceStatus
::
MACE_SUCCESS
;
}
void
*
Map
(
index_t
offset
,
index_t
length
,
std
::
vector
<
size_t
>
*
pitch
)
const
{
void
*
Map
(
index_t
offset
,
index_t
length
,
std
::
vector
<
size_t
>
*
pitch
)
const
{
MACE_UNUSED
(
offset
);
MACE_UNUSED
(
offset
);
MACE_UNUSED
(
length
);
MACE_UNUSED
(
length
);
...
@@ -364,9 +424,10 @@ class BufferSlice : public BufferBase {
...
@@ -364,9 +424,10 @@ class BufferSlice : public BufferBase {
mapped_buf_
=
nullptr
;
mapped_buf_
=
nullptr
;
}
}
void
Resize
(
index_t
size
)
{
MaceStatus
Resize
(
index_t
size
)
{
MACE_CHECK
(
size
==
size_
,
"resize buffer slice from "
,
size_
,
MACE_CHECK
(
size
==
size_
,
"resize buffer slice from "
,
size_
,
" to "
,
size
,
" is illegal"
);
" to "
,
size
,
" is illegal"
);
return
MaceStatus
::
MACE_SUCCESS
;
}
}
void
Copy
(
void
*
src
,
index_t
offset
,
index_t
length
)
{
void
Copy
(
void
*
src
,
index_t
offset
,
index_t
length
)
{
...
@@ -381,7 +442,11 @@ class BufferSlice : public BufferBase {
...
@@ -381,7 +442,11 @@ class BufferSlice : public BufferBase {
bool
OnHost
()
const
{
return
buffer_
->
OnHost
();
}
bool
OnHost
()
const
{
return
buffer_
->
OnHost
();
}
void
Clear
()
{
void
Clear
()
{
memset
(
raw_mutable_data
(),
0
,
size_
);
Clear
(
size_
);
}
void
Clear
(
index_t
size
)
{
memset
(
raw_mutable_data
(),
0
,
size
);
}
}
private:
private:
...
@@ -396,20 +461,17 @@ class ScratchBuffer: public Buffer {
...
@@ -396,20 +461,17 @@ class ScratchBuffer: public Buffer {
:
Buffer
(
allocator
),
:
Buffer
(
allocator
),
offset_
(
0
)
{}
offset_
(
0
)
{}
ScratchBuffer
(
Allocator
*
allocator
,
index_t
size
)
:
Buffer
(
allocator
,
size
),
offset_
(
0
)
{}
ScratchBuffer
(
Allocator
*
allocator
,
void
*
data
,
index_t
size
)
ScratchBuffer
(
Allocator
*
allocator
,
void
*
data
,
index_t
size
)
:
Buffer
(
allocator
,
data
,
size
),
:
Buffer
(
allocator
,
data
,
size
),
offset_
(
0
)
{}
offset_
(
0
)
{}
virtual
~
ScratchBuffer
()
{}
virtual
~
ScratchBuffer
()
{}
void
GrowSize
(
index_t
size
)
{
MaceStatus
GrowSize
(
index_t
size
)
{
if
(
size
>
size_
)
{
if
(
size
>
size_
)
{
Resize
(
size
);
return
Resize
(
size
);
}
}
return
MaceStatus
::
MACE_SUCCESS
;
}
}
BufferSlice
Scratch
(
index_t
size
)
{
BufferSlice
Scratch
(
index_t
size
)
{
...
...
mace/core/mace.cc
浏览文件 @
bdaa5c18
...
@@ -90,13 +90,15 @@ std::shared_ptr<float> MaceTensor::data() { return impl_->data; }
...
@@ -90,13 +90,15 @@ std::shared_ptr<float> MaceTensor::data() { return impl_->data; }
// Mace Engine
// Mace Engine
class
MaceEngine
::
Impl
{
class
MaceEngine
::
Impl
{
public:
public:
explicit
Impl
(
const
NetDef
*
net_def
,
explicit
Impl
(
DeviceType
device_type
);
DeviceType
device_type
,
const
std
::
vector
<
std
::
string
>
&
input_nodes
,
const
std
::
vector
<
std
::
string
>
&
output_nodes
,
const
unsigned
char
*
model_data
);
~
Impl
();
~
Impl
();
MaceStatus
Init
(
const
NetDef
*
net_def
,
const
std
::
vector
<
std
::
string
>
&
input_nodes
,
const
std
::
vector
<
std
::
string
>
&
output_nodes
,
const
unsigned
char
*
model_data
);
MaceStatus
Run
(
const
std
::
map
<
std
::
string
,
MaceTensor
>
&
inputs
,
MaceStatus
Run
(
const
std
::
map
<
std
::
string
,
MaceTensor
>
&
inputs
,
std
::
map
<
std
::
string
,
MaceTensor
>
*
outputs
,
std
::
map
<
std
::
string
,
MaceTensor
>
*
outputs
,
RunMetadata
*
run_metadata
);
RunMetadata
*
run_metadata
);
...
@@ -113,11 +115,7 @@ class MaceEngine::Impl {
...
@@ -113,11 +115,7 @@ class MaceEngine::Impl {
DISABLE_COPY_AND_ASSIGN
(
Impl
);
DISABLE_COPY_AND_ASSIGN
(
Impl
);
};
};
MaceEngine
::
Impl
::
Impl
(
const
NetDef
*
net_def
,
MaceEngine
::
Impl
::
Impl
(
DeviceType
device_type
)
DeviceType
device_type
,
const
std
::
vector
<
std
::
string
>
&
input_nodes
,
const
std
::
vector
<
std
::
string
>
&
output_nodes
,
const
unsigned
char
*
model_data
)
:
op_registry_
(
new
OperatorRegistry
()),
:
op_registry_
(
new
OperatorRegistry
()),
device_type_
(
device_type
),
device_type_
(
device_type
),
ws_
(
new
Workspace
()),
ws_
(
new
Workspace
()),
...
@@ -125,7 +123,13 @@ MaceEngine::Impl::Impl(const NetDef *net_def,
...
@@ -125,7 +123,13 @@ MaceEngine::Impl::Impl(const NetDef *net_def,
#ifdef MACE_ENABLE_HEXAGON
#ifdef MACE_ENABLE_HEXAGON
,
hexagon_controller_
(
nullptr
)
,
hexagon_controller_
(
nullptr
)
#endif
#endif
{
{}
MaceStatus
MaceEngine
::
Impl
::
Init
(
const
NetDef
*
net_def
,
const
std
::
vector
<
std
::
string
>
&
input_nodes
,
const
std
::
vector
<
std
::
string
>
&
output_nodes
,
const
unsigned
char
*
model_data
)
{
LOG
(
INFO
)
<<
"MACE version: "
<<
MaceVersion
();
LOG
(
INFO
)
<<
"MACE version: "
<<
MaceVersion
();
// Set storage path for internal usage
// Set storage path for internal usage
for
(
auto
input_name
:
input_nodes
)
{
for
(
auto
input_name
:
input_nodes
)
{
...
@@ -137,7 +141,7 @@ MaceEngine::Impl::Impl(const NetDef *net_def,
...
@@ -137,7 +141,7 @@ MaceEngine::Impl::Impl(const NetDef *net_def,
GetDeviceAllocator
(
device_type_
),
DT_FLOAT
);
GetDeviceAllocator
(
device_type_
),
DT_FLOAT
);
}
}
#ifdef MACE_ENABLE_HEXAGON
#ifdef MACE_ENABLE_HEXAGON
if
(
device_type
==
HEXAGON
)
{
if
(
device_type
_
==
HEXAGON
)
{
hexagon_controller_
.
reset
(
new
HexagonControlWrapper
());
hexagon_controller_
.
reset
(
new
HexagonControlWrapper
());
MACE_CHECK
(
hexagon_controller_
->
Config
(),
"hexagon config error"
);
MACE_CHECK
(
hexagon_controller_
->
Config
(),
"hexagon config error"
);
MACE_CHECK
(
hexagon_controller_
->
Init
(),
"hexagon init error"
);
MACE_CHECK
(
hexagon_controller_
->
Init
(),
"hexagon init error"
);
...
@@ -153,18 +157,23 @@ MaceEngine::Impl::Impl(const NetDef *net_def,
...
@@ -153,18 +157,23 @@ MaceEngine::Impl::Impl(const NetDef *net_def,
}
}
}
else
{
}
else
{
#endif
#endif
ws_
->
LoadModelTensor
(
*
net_def
,
device_type
,
model_data
);
MaceStatus
status
=
ws_
->
LoadModelTensor
(
*
net_def
,
device_type_
,
model_data
);
if
(
status
!=
MaceStatus
::
MACE_SUCCESS
)
{
return
status
;
}
// Init model
// Init model
auto
net
=
CreateNet
(
op_registry_
,
*
net_def
,
ws_
.
get
(),
device_type
,
auto
net
=
CreateNet
(
op_registry_
,
*
net_def
,
ws_
.
get
(),
device_type
_
,
NetMode
::
INIT
);
NetMode
::
INIT
);
if
(
!
net
->
Run
())
{
if
(
!
net
->
Run
())
{
LOG
(
FATAL
)
<<
"Net init run failed"
;
LOG
(
FATAL
)
<<
"Net init run failed"
;
}
}
net_
=
CreateNet
(
op_registry_
,
*
net_def
,
ws_
.
get
(),
device_type
);
net_
=
CreateNet
(
op_registry_
,
*
net_def
,
ws_
.
get
(),
device_type
_
);
#ifdef MACE_ENABLE_HEXAGON
#ifdef MACE_ENABLE_HEXAGON
}
}
#endif
#endif
return
MaceStatus
::
MACE_SUCCESS
;
}
}
MaceEngine
::
Impl
::~
Impl
()
{
MaceEngine
::
Impl
::~
Impl
()
{
...
@@ -254,18 +263,18 @@ MaceStatus MaceEngine::Impl::Run(
...
@@ -254,18 +263,18 @@ MaceStatus MaceEngine::Impl::Run(
return
MACE_SUCCESS
;
return
MACE_SUCCESS
;
}
}
MaceEngine
::
MaceEngine
(
const
NetDef
*
net_def
,
MaceEngine
::
MaceEngine
(
DeviceType
device_type
)
:
DeviceType
device_type
,
impl_
(
new
MaceEngine
::
Impl
(
device_type
))
{}
const
std
::
vector
<
std
::
string
>
&
input_nodes
,
const
std
::
vector
<
std
::
string
>
&
output_nodes
,
const
unsigned
char
*
model_data
)
{
impl_
=
std
::
unique_ptr
<
MaceEngine
::
Impl
>
(
new
MaceEngine
::
Impl
(
net_def
,
device_type
,
input_nodes
,
output_nodes
,
model_data
));
}
MaceEngine
::~
MaceEngine
()
=
default
;
MaceEngine
::~
MaceEngine
()
=
default
;
MaceStatus
MaceEngine
::
Init
(
const
NetDef
*
net_def
,
const
std
::
vector
<
std
::
string
>
&
input_nodes
,
const
std
::
vector
<
std
::
string
>
&
output_nodes
,
const
unsigned
char
*
model_data
)
{
return
impl_
->
Init
(
net_def
,
input_nodes
,
output_nodes
,
model_data
);
}
MaceStatus
MaceEngine
::
Run
(
const
std
::
map
<
std
::
string
,
MaceTensor
>
&
inputs
,
MaceStatus
MaceEngine
::
Run
(
const
std
::
map
<
std
::
string
,
MaceTensor
>
&
inputs
,
std
::
map
<
std
::
string
,
MaceTensor
>
*
outputs
,
std
::
map
<
std
::
string
,
MaceTensor
>
*
outputs
,
RunMetadata
*
run_metadata
)
{
RunMetadata
*
run_metadata
)
{
...
@@ -325,17 +334,18 @@ MaceStatus CreateMaceEngineFromPB(const std::string &model_data_file,
...
@@ -325,17 +334,18 @@ MaceStatus CreateMaceEngineFromPB(const std::string &model_data_file,
const_tensor
.
data_size
()
*
const_tensor
.
data_size
()
*
GetEnumTypeSize
(
const_tensor
.
data_type
())));
GetEnumTypeSize
(
const_tensor
.
data_type
())));
}
}
MaceStatus
status
;
const
unsigned
char
*
model_data
=
nullptr
;
const
unsigned
char
*
model_data
=
nullptr
;
model_data
=
LoadModelData
(
model_data_file
,
model_data_size
);
model_data
=
LoadModelData
(
model_data_file
,
model_data_size
);
engine
->
reset
(
engine
->
reset
(
new
mace
::
MaceEngine
(
device_type
));
new
mace
::
MaceEngine
(
&
net_def
,
device_type
,
input_nodes
,
output_nodes
,
status
=
(
*
engine
)
->
Init
(
&
net_def
,
input_nodes
,
output_nodes
,
model_data
);
model_data
));
if
(
device_type
==
DeviceType
::
GPU
||
device_type
==
DeviceType
::
HEXAGON
)
{
if
(
device_type
==
DeviceType
::
GPU
||
device_type
==
DeviceType
::
HEXAGON
)
{
UnloadModelData
(
model_data
,
model_data_size
);
UnloadModelData
(
model_data
,
model_data_size
);
}
}
return
MACE_SUCCESS
;
return
status
;
}
}
}
// namespace mace
}
// namespace mace
mace/core/runtime/cpu/cpu_runtime.cc
浏览文件 @
bdaa5c18
...
@@ -18,9 +18,11 @@
...
@@ -18,9 +18,11 @@
#include <omp.h>
#include <omp.h>
#endif
#endif
#include <errno.h>
#include <unistd.h>
#include <unistd.h>
#include <sys/syscall.h>
#include <sys/syscall.h>
#include <sys/types.h>
#include <sys/types.h>
#include <string.h>
#include <algorithm>
#include <algorithm>
#include <utility>
#include <utility>
#include <vector>
#include <vector>
...
@@ -44,7 +46,7 @@ int GetCPUCount() {
...
@@ -44,7 +46,7 @@ int GetCPUCount() {
result
=
access
(
path
,
F_OK
);
result
=
access
(
path
,
F_OK
);
if
(
result
!=
0
)
{
if
(
result
!=
0
)
{
if
(
errno
!=
ENOENT
)
{
if
(
errno
!=
ENOENT
)
{
LOG
(
ERROR
)
<<
"Access "
<<
path
<<
" failed
, errno: "
<<
errno
;
LOG
(
ERROR
)
<<
"Access "
<<
path
<<
" failed
: "
<<
strerror
(
errno
)
;
}
}
return
cpu_count
;
return
cpu_count
;
}
}
...
@@ -81,7 +83,7 @@ void SetThreadAffinity(cpu_set_t mask) {
...
@@ -81,7 +83,7 @@ void SetThreadAffinity(cpu_set_t mask) {
pid_t
pid
=
syscall
(
SYS_gettid
);
pid_t
pid
=
syscall
(
SYS_gettid
);
#endif
#endif
int
err
=
sched_setaffinity
(
pid
,
sizeof
(
mask
),
&
mask
);
int
err
=
sched_setaffinity
(
pid
,
sizeof
(
mask
),
&
mask
);
MACE_CHECK
(
err
==
0
,
"set affinity error: "
,
errno
);
MACE_CHECK
(
err
==
0
,
"set affinity error: "
,
strerror
(
errno
)
);
}
}
}
// namespace
}
// namespace
...
@@ -101,7 +103,7 @@ MaceStatus GetCPUBigLittleCoreIDs(std::vector<int> *big_core_ids,
...
@@ -101,7 +103,7 @@ MaceStatus GetCPUBigLittleCoreIDs(std::vector<int> *big_core_ids,
for
(
int
i
=
0
;
i
<
cpu_count
;
++
i
)
{
for
(
int
i
=
0
;
i
<
cpu_count
;
++
i
)
{
cpu_max_freq
[
i
]
=
GetCPUMaxFreq
(
i
);
cpu_max_freq
[
i
]
=
GetCPUMaxFreq
(
i
);
if
(
cpu_max_freq
[
i
]
==
0
)
{
if
(
cpu_max_freq
[
i
]
==
0
)
{
LOG
(
WARNING
)
<<
"Cannot get
cpu
"
<<
i
LOG
(
WARNING
)
<<
"Cannot get
CPU
"
<<
i
<<
"'s max frequency info, maybe it is offline."
;
<<
"'s max frequency info, maybe it is offline."
;
return
MACE_INVALID_ARGS
;
return
MACE_INVALID_ARGS
;
}
}
...
@@ -128,13 +130,12 @@ MaceStatus GetCPUBigLittleCoreIDs(std::vector<int> *big_core_ids,
...
@@ -128,13 +130,12 @@ MaceStatus GetCPUBigLittleCoreIDs(std::vector<int> *big_core_ids,
void
SetOpenMPThreadsAndAffinityCPUs
(
int
omp_num_threads
,
void
SetOpenMPThreadsAndAffinityCPUs
(
int
omp_num_threads
,
const
std
::
vector
<
int
>
&
cpu_ids
)
{
const
std
::
vector
<
int
>
&
cpu_ids
)
{
#ifdef MACE_ENABLE_OPENMP
VLOG
(
1
)
<<
"Set OpenMP threads number: "
<<
omp_num_threads
VLOG
(
1
)
<<
"Set OpenMP threads number: "
<<
omp_num_threads
<<
", CPU core IDs: "
<<
MakeString
(
cpu_ids
);
<<
", CPU core IDs: "
<<
MakeString
(
cpu_ids
);
#ifdef MACE_ENABLE_OPENMP
omp_set_num_threads
(
omp_num_threads
);
omp_set_num_threads
(
omp_num_threads
);
#else
#else
LOG
(
WARNING
)
<<
"
OpenMP not enabled. Set OpenMP threads number fai
led."
;
LOG
(
WARNING
)
<<
"
Set OpenMP threads number failed: OpenMP not enab
led."
;
#endif
#endif
// compute mask
// compute mask
...
@@ -147,11 +148,13 @@ void SetOpenMPThreadsAndAffinityCPUs(int omp_num_threads,
...
@@ -147,11 +148,13 @@ void SetOpenMPThreadsAndAffinityCPUs(int omp_num_threads,
#ifdef MACE_ENABLE_OPENMP
#ifdef MACE_ENABLE_OPENMP
#pragma omp parallel for
#pragma omp parallel for
for
(
int
i
=
0
;
i
<
omp_num_threads
;
++
i
)
{
for
(
int
i
=
0
;
i
<
omp_num_threads
;
++
i
)
{
VLOG
(
1
)
<<
"Set affinity for OpenMP thread "
<<
omp_get_thread_num
()
<<
"/"
<<
omp_get_num_threads
();
SetThreadAffinity
(
mask
);
SetThreadAffinity
(
mask
);
}
}
#else
#else
SetThreadAffinity
(
mask
);
SetThreadAffinity
(
mask
);
LOG
(
INFO
)
<<
"SetThreadAffinity
: "
<<
mask
.
__bits
[
0
];
VLOG
(
1
)
<<
"Set affinity without OpenMP
: "
<<
mask
.
__bits
[
0
];
#endif
#endif
}
}
...
@@ -163,7 +166,7 @@ MaceStatus SetOpenMPThreadsAndAffinityPolicy(int omp_num_threads_hint,
...
@@ -163,7 +166,7 @@ MaceStatus SetOpenMPThreadsAndAffinityPolicy(int omp_num_threads_hint,
omp_set_num_threads
(
std
::
min
(
omp_num_threads_hint
,
omp_get_num_procs
()));
omp_set_num_threads
(
std
::
min
(
omp_num_threads_hint
,
omp_get_num_procs
()));
}
}
#else
#else
LOG
(
WARNING
)
<<
"
OpenMP not enabled. Set OpenMP threads number fai
led."
;
LOG
(
WARNING
)
<<
"
Set OpenMP threads number failed: OpenMP not enab
led."
;
#endif
#endif
return
MACE_SUCCESS
;
return
MACE_SUCCESS
;
}
}
...
@@ -192,7 +195,7 @@ MaceStatus SetOpenMPThreadsAndAffinityPolicy(int omp_num_threads_hint,
...
@@ -192,7 +195,7 @@ MaceStatus SetOpenMPThreadsAndAffinityPolicy(int omp_num_threads_hint,
MaceStatus
SetOpenMPThreadPolicy
(
int
num_threads_hint
,
MaceStatus
SetOpenMPThreadPolicy
(
int
num_threads_hint
,
CPUAffinityPolicy
policy
)
{
CPUAffinityPolicy
policy
)
{
VLOG
(
1
)
<<
"Set
CPU openmp num_threads_
hint: "
<<
num_threads_hint
VLOG
(
1
)
<<
"Set
OpenMP threads number
hint: "
<<
num_threads_hint
<<
", affinity policy: "
<<
policy
;
<<
", affinity policy: "
<<
policy
;
return
SetOpenMPThreadsAndAffinityPolicy
(
num_threads_hint
,
policy
);
return
SetOpenMPThreadsAndAffinityPolicy
(
num_threads_hint
,
policy
);
}
}
...
...
mace/core/runtime/opencl/opencl_allocator.cc
浏览文件 @
bdaa5c18
...
@@ -44,18 +44,30 @@ static cl_channel_type DataTypeToCLChannelType(const DataType t) {
...
@@ -44,18 +44,30 @@ static cl_channel_type DataTypeToCLChannelType(const DataType t) {
OpenCLAllocator
::
OpenCLAllocator
()
{}
OpenCLAllocator
::
OpenCLAllocator
()
{}
OpenCLAllocator
::~
OpenCLAllocator
()
{}
OpenCLAllocator
::~
OpenCLAllocator
()
{}
void
*
OpenCLAllocator
::
New
(
size_t
nbytes
)
const
{
MaceStatus
OpenCLAllocator
::
New
(
size_t
nbytes
,
void
**
result
)
const
{
if
(
nbytes
==
0
)
{
return
MaceStatus
::
MACE_SUCCESS
;
}
VLOG
(
3
)
<<
"Allocate OpenCL buffer: "
<<
nbytes
;
VLOG
(
3
)
<<
"Allocate OpenCL buffer: "
<<
nbytes
;
cl_int
error
;
cl_int
error
;
cl
::
Buffer
*
buffer
=
new
cl
::
Buffer
(
OpenCLRuntime
::
Global
()
->
context
(),
cl
::
Buffer
*
buffer
=
new
cl
::
Buffer
(
OpenCLRuntime
::
Global
()
->
context
(),
CL_MEM_READ_WRITE
|
CL_MEM_ALLOC_HOST_PTR
,
CL_MEM_READ_WRITE
|
CL_MEM_ALLOC_HOST_PTR
,
nbytes
,
nullptr
,
&
error
);
nbytes
,
nullptr
,
&
error
);
MACE_CHECK_CL_SUCCESS
(
error
);
if
(
error
!=
CL_SUCCESS
)
{
return
static_cast
<
void
*>
(
buffer
);
LOG
(
WARNING
)
<<
"Allocate OpenCL Buffer with "
<<
nbytes
<<
" bytes failed because of"
<<
OpenCLErrorToString
(
error
);
*
result
=
nullptr
;
return
MaceStatus
::
MACE_OUT_OF_RESOURCES
;
}
else
{
*
result
=
buffer
;
return
MaceStatus
::
MACE_SUCCESS
;
}
}
}
void
*
OpenCLAllocator
::
NewImage
(
const
std
::
vector
<
size_t
>
&
image_shape
,
MaceStatus
OpenCLAllocator
::
NewImage
(
const
std
::
vector
<
size_t
>
&
image_shape
,
const
DataType
dt
)
const
{
const
DataType
dt
,
void
**
result
)
const
{
MACE_CHECK
(
image_shape
.
size
()
==
2
)
<<
"Image shape's size must equal 2"
;
MACE_CHECK
(
image_shape
.
size
()
==
2
)
<<
"Image shape's size must equal 2"
;
VLOG
(
3
)
<<
"Allocate OpenCL image: "
<<
image_shape
[
0
]
<<
", "
VLOG
(
3
)
<<
"Allocate OpenCL image: "
<<
image_shape
[
0
]
<<
", "
<<
image_shape
[
1
];
<<
image_shape
[
1
];
...
@@ -67,11 +79,17 @@ void *OpenCLAllocator::NewImage(const std::vector<size_t> &image_shape,
...
@@ -67,11 +79,17 @@ void *OpenCLAllocator::NewImage(const std::vector<size_t> &image_shape,
new
cl
::
Image2D
(
OpenCLRuntime
::
Global
()
->
context
(),
new
cl
::
Image2D
(
OpenCLRuntime
::
Global
()
->
context
(),
CL_MEM_READ_WRITE
|
CL_MEM_ALLOC_HOST_PTR
,
img_format
,
CL_MEM_READ_WRITE
|
CL_MEM_ALLOC_HOST_PTR
,
img_format
,
image_shape
[
0
],
image_shape
[
1
],
0
,
nullptr
,
&
error
);
image_shape
[
0
],
image_shape
[
1
],
0
,
nullptr
,
&
error
);
MACE_CHECK_CL_SUCCESS
(
error
)
<<
" with image shape: ["
if
(
error
!=
CL_SUCCESS
)
{
<<
image_shape
[
0
]
<<
", "
<<
image_shape
[
1
]
LOG
(
WARNING
)
<<
"Allocate OpenCL image with shape: ["
<<
"]"
;
<<
image_shape
[
0
]
<<
", "
<<
image_shape
[
1
]
<<
"] failed because of"
return
cl_image
;
<<
OpenCLErrorToString
(
error
);
*
result
=
nullptr
;
return
MaceStatus
::
MACE_OUT_OF_RESOURCES
;
}
else
{
*
result
=
cl_image
;
return
MaceStatus
::
MACE_SUCCESS
;
}
}
}
void
OpenCLAllocator
::
Delete
(
void
*
buffer
)
const
{
void
OpenCLAllocator
::
Delete
(
void
*
buffer
)
const
{
...
...
mace/core/runtime/opencl/opencl_allocator.h
浏览文件 @
bdaa5c18
...
@@ -27,15 +27,16 @@ class OpenCLAllocator : public Allocator {
...
@@ -27,15 +27,16 @@ class OpenCLAllocator : public Allocator {
~
OpenCLAllocator
()
override
;
~
OpenCLAllocator
()
override
;
void
*
New
(
size_t
nbytes
)
const
override
;
MaceStatus
New
(
size_t
nbytes
,
void
**
result
)
const
override
;
/*
/*
* Use Image2D with RGBA (128-bit) format to represent the image.
* Use Image2D with RGBA (128-bit) format to represent the image.
*
*
* @ shape : [depth, ..., height, width ].
* @ shape : [depth, ..., height, width ].
*/
*/
void
*
NewImage
(
const
std
::
vector
<
size_t
>
&
image_shape
,
MaceStatus
NewImage
(
const
std
::
vector
<
size_t
>
&
image_shape
,
const
DataType
dt
)
const
override
;
const
DataType
dt
,
void
**
result
)
const
override
;
void
Delete
(
void
*
buffer
)
const
override
;
void
Delete
(
void
*
buffer
)
const
override
;
...
...
mace/core/tensor.h
浏览文件 @
bdaa5c18
...
@@ -208,7 +208,7 @@ class Tensor {
...
@@ -208,7 +208,7 @@ class Tensor {
inline
void
Clear
()
{
inline
void
Clear
()
{
MACE_CHECK_NOTNULL
(
buffer_
);
MACE_CHECK_NOTNULL
(
buffer_
);
buffer_
->
Clear
();
buffer_
->
Clear
(
raw_size
()
);
}
}
inline
void
Reshape
(
const
std
::
vector
<
index_t
>
&
shape
)
{
inline
void
Reshape
(
const
std
::
vector
<
index_t
>
&
shape
)
{
...
@@ -216,16 +216,21 @@ class Tensor {
...
@@ -216,16 +216,21 @@ class Tensor {
MACE_CHECK
(
raw_size
()
<=
buffer_
->
size
());
MACE_CHECK
(
raw_size
()
<=
buffer_
->
size
());
}
}
inline
void
Resize
(
const
std
::
vector
<
index_t
>
&
shape
)
{
inline
MaceStatus
Resize
(
const
std
::
vector
<
index_t
>
&
shape
)
{
shape_
=
shape
;
shape_
=
shape
;
image_shape_
.
clear
();
image_shape_
.
clear
();
if
(
buffer_
!=
nullptr
)
{
if
(
buffer_
!=
nullptr
)
{
MACE_CHECK
(
!
has_opencl_image
(),
"Cannot resize image, use ResizeImage."
);
MACE_CHECK
(
!
has_opencl_image
(),
"Cannot resize image, use ResizeImage."
);
if
(
raw_size
()
+
EXTRA_BUFFER_PAD_SIZE
>
buffer_
->
size
())
if
(
raw_size
()
+
EXTRA_BUFFER_PAD_SIZE
>
buffer_
->
size
())
{
buffer_
->
Resize
(
raw_size
()
+
EXTRA_BUFFER_PAD_SIZE
);
LOG
(
WARNING
)
<<
"Resize buffer from size "
<<
buffer_
->
size
()
<<
" to "
<<
raw_size
()
+
EXTRA_BUFFER_PAD_SIZE
;
return
buffer_
->
Resize
(
raw_size
()
+
EXTRA_BUFFER_PAD_SIZE
);
}
return
MaceStatus
::
MACE_SUCCESS
;
}
else
{
}
else
{
MACE_CHECK
(
is_buffer_owner_
);
MACE_CHECK
(
is_buffer_owner_
);
buffer_
=
new
Buffer
(
allocator_
,
raw_size
()
+
EXTRA_BUFFER_PAD_SIZE
);
buffer_
=
new
Buffer
(
allocator_
);
return
buffer_
->
Allocate
(
raw_size
()
+
EXTRA_BUFFER_PAD_SIZE
);
}
}
}
}
...
@@ -241,13 +246,14 @@ class Tensor {
...
@@ -241,13 +246,14 @@ class Tensor {
is_buffer_owner_
=
false
;
is_buffer_owner_
=
false
;
}
}
inline
void
ResizeImage
(
const
std
::
vector
<
index_t
>
&
shape
,
inline
MaceStatus
ResizeImage
(
const
std
::
vector
<
index_t
>
&
shape
,
const
std
::
vector
<
size_t
>
&
image_shape
)
{
const
std
::
vector
<
size_t
>
&
image_shape
)
{
shape_
=
shape
;
shape_
=
shape
;
image_shape_
=
image_shape
;
image_shape_
=
image_shape
;
if
(
buffer_
==
nullptr
)
{
if
(
buffer_
==
nullptr
)
{
MACE_CHECK
(
is_buffer_owner_
);
MACE_CHECK
(
is_buffer_owner_
);
buffer_
=
new
Image
(
image_shape
,
dtype_
);
buffer_
=
new
Image
();
return
buffer_
->
Allocate
(
image_shape
,
dtype_
);
}
else
{
}
else
{
MACE_CHECK
(
has_opencl_image
(),
"Cannot ResizeImage buffer, use Resize."
);
MACE_CHECK
(
has_opencl_image
(),
"Cannot ResizeImage buffer, use Resize."
);
Image
*
image
=
dynamic_cast
<
Image
*>
(
buffer_
);
Image
*
image
=
dynamic_cast
<
Image
*>
(
buffer_
);
...
@@ -257,24 +263,27 @@ class Tensor {
...
@@ -257,24 +263,27 @@ class Tensor {
"): current physical image shape: "
,
image
->
image_shape
()[
0
],
"): current physical image shape: "
,
image
->
image_shape
()[
0
],
", "
,
image
->
image_shape
()[
1
],
" < logical image shape: "
,
", "
,
image
->
image_shape
()[
1
],
" < logical image shape: "
,
image_shape
[
0
],
", "
,
image_shape
[
1
]);
image_shape
[
0
],
", "
,
image_shape
[
1
]);
return
MaceStatus
::
MACE_SUCCESS
;
}
}
}
}
inline
void
ResizeLike
(
const
Tensor
&
other
)
{
ResizeLike
(
&
other
);
}
inline
MaceStatus
ResizeLike
(
const
Tensor
&
other
)
{
return
ResizeLike
(
&
other
);
}
inline
void
ResizeLike
(
const
Tensor
*
other
)
{
inline
MaceStatus
ResizeLike
(
const
Tensor
*
other
)
{
if
(
other
->
has_opencl_image
())
{
if
(
other
->
has_opencl_image
())
{
if
(
is_buffer_owner_
&&
buffer_
!=
nullptr
&&
!
has_opencl_image
())
{
if
(
is_buffer_owner_
&&
buffer_
!=
nullptr
&&
!
has_opencl_image
())
{
delete
buffer_
;
delete
buffer_
;
buffer_
=
nullptr
;
buffer_
=
nullptr
;
}
}
ResizeImage
(
other
->
shape
(),
other
->
image_shape_
);
return
ResizeImage
(
other
->
shape
(),
other
->
image_shape_
);
}
else
{
}
else
{
if
(
is_buffer_owner_
&&
buffer_
!=
nullptr
&&
has_opencl_image
())
{
if
(
is_buffer_owner_
&&
buffer_
!=
nullptr
&&
has_opencl_image
())
{
delete
buffer_
;
delete
buffer_
;
buffer_
=
nullptr
;
buffer_
=
nullptr
;
}
}
Resize
(
other
->
shape
());
return
Resize
(
other
->
shape
());
}
}
}
}
...
...
mace/core/workspace.cc
浏览文件 @
bdaa5c18
...
@@ -60,9 +60,9 @@ std::vector<std::string> Workspace::Tensors() const {
...
@@ -60,9 +60,9 @@ std::vector<std::string> Workspace::Tensors() const {
return
names
;
return
names
;
}
}
void
Workspace
::
LoadModelTensor
(
const
NetDef
&
net_def
,
MaceStatus
Workspace
::
LoadModelTensor
(
const
NetDef
&
net_def
,
DeviceType
type
,
DeviceType
type
,
const
unsigned
char
*
model_data
)
{
const
unsigned
char
*
model_data
)
{
MACE_LATENCY_LOGGER
(
1
,
"Load model tensors"
);
MACE_LATENCY_LOGGER
(
1
,
"Load model tensors"
);
index_t
model_data_size
=
0
;
index_t
model_data_size
=
0
;
for
(
auto
&
const_tensor
:
net_def
.
tensors
())
{
for
(
auto
&
const_tensor
:
net_def
.
tensors
())
{
...
@@ -82,7 +82,11 @@ void Workspace::LoadModelTensor(const NetDef &net_def,
...
@@ -82,7 +82,11 @@ void Workspace::LoadModelTensor(const NetDef &net_def,
model_data_size
));
model_data_size
));
}
else
{
}
else
{
tensor_buffer_
=
std
::
unique_ptr
<
Buffer
>
(
tensor_buffer_
=
std
::
unique_ptr
<
Buffer
>
(
new
Buffer
(
GetDeviceAllocator
(
type
),
model_data_size
));
new
Buffer
(
GetDeviceAllocator
(
type
)));
MaceStatus
status
=
tensor_buffer_
->
Allocate
(
model_data_size
);
if
(
status
!=
MaceStatus
::
MACE_SUCCESS
)
{
return
status
;
}
tensor_buffer_
->
Map
(
nullptr
);
tensor_buffer_
->
Map
(
nullptr
);
tensor_buffer_
->
Copy
(
const_cast
<
unsigned
char
*>
(
model_data
),
tensor_buffer_
->
Copy
(
const_cast
<
unsigned
char
*>
(
model_data
),
0
,
model_data_size
);
0
,
model_data_size
);
...
@@ -112,14 +116,16 @@ void Workspace::LoadModelTensor(const NetDef &net_def,
...
@@ -112,14 +116,16 @@ void Workspace::LoadModelTensor(const NetDef &net_def,
}
}
if
(
type
==
DeviceType
::
CPU
||
type
==
DeviceType
::
GPU
)
{
if
(
type
==
DeviceType
::
CPU
||
type
==
DeviceType
::
GPU
)
{
CreateOutputTensorBuffer
(
net_def
,
type
);
MaceStatus
status
=
CreateOutputTensorBuffer
(
net_def
,
type
);
if
(
status
!=
MaceStatus
::
MACE_SUCCESS
)
return
status
;
}
}
return
MaceStatus
::
MACE_SUCCESS
;
}
}
void
Workspace
::
CreateOutputTensorBuffer
(
const
NetDef
&
net_def
,
MaceStatus
Workspace
::
CreateOutputTensorBuffer
(
const
NetDef
&
net_def
,
DeviceType
device_type
)
{
DeviceType
device_type
)
{
if
(
!
net_def
.
has_mem_arena
()
||
net_def
.
mem_arena
().
mem_block_size
()
==
0
)
{
if
(
!
net_def
.
has_mem_arena
()
||
net_def
.
mem_arena
().
mem_block_size
()
==
0
)
{
return
;
return
MaceStatus
::
MACE_SUCCESS
;
}
}
DataType
dtype
=
DataType
::
DT_INVALID
;
DataType
dtype
=
DataType
::
DT_INVALID
;
...
@@ -149,14 +155,24 @@ void Workspace::CreateOutputTensorBuffer(const NetDef &net_def,
...
@@ -149,14 +155,24 @@ void Workspace::CreateOutputTensorBuffer(const NetDef &net_def,
// TODO(liuqi): refactor based on PB
// TODO(liuqi): refactor based on PB
if
(
mem_block
.
mem_id
()
>=
20000
)
{
if
(
mem_block
.
mem_id
()
>=
20000
)
{
std
::
unique_ptr
<
BufferBase
>
image_buf
(
std
::
unique_ptr
<
BufferBase
>
image_buf
(
new
Image
({
mem_block
.
x
(),
mem_block
.
y
()},
dtype
));
new
Image
());
MaceStatus
status
=
image_buf
->
Allocate
(
{
mem_block
.
x
(),
mem_block
.
y
()},
dtype
);
if
(
status
!=
MaceStatus
::
MACE_SUCCESS
)
{
return
status
;
}
preallocated_allocator_
.
SetBuffer
(
mem_block
.
mem_id
(),
preallocated_allocator_
.
SetBuffer
(
mem_block
.
mem_id
(),
std
::
move
(
image_buf
));
std
::
move
(
image_buf
));
}
}
}
else
{
}
else
{
if
(
mem_block
.
mem_id
()
<
20000
)
{
if
(
mem_block
.
mem_id
()
<
20000
)
{
std
::
unique_ptr
<
BufferBase
>
tensor_buf
(
std
::
unique_ptr
<
BufferBase
>
tensor_buf
(
new
Buffer
(
GetDeviceAllocator
(
device_type
),
mem_block
.
x
()));
new
Buffer
(
GetDeviceAllocator
(
device_type
)));
MaceStatus
status
=
tensor_buf
->
Allocate
(
mem_block
.
x
()
*
GetEnumTypeSize
(
dtype
)
+
EXTRA_BUFFER_PAD_SIZE
);
if
(
status
!=
MaceStatus
::
MACE_SUCCESS
)
{
return
status
;
}
preallocated_allocator_
.
SetBuffer
(
mem_block
.
mem_id
(),
preallocated_allocator_
.
SetBuffer
(
mem_block
.
mem_id
(),
std
::
move
(
tensor_buf
));
std
::
move
(
tensor_buf
));
}
}
...
@@ -193,6 +209,7 @@ void Workspace::CreateOutputTensorBuffer(const NetDef &net_def,
...
@@ -193,6 +209,7 @@ void Workspace::CreateOutputTensorBuffer(const NetDef &net_def,
}
}
}
}
}
}
return
MaceStatus
::
MACE_SUCCESS
;
}
}
ScratchBuffer
*
Workspace
::
GetScratchBuffer
(
DeviceType
device_type
)
{
ScratchBuffer
*
Workspace
::
GetScratchBuffer
(
DeviceType
device_type
)
{
...
...
mace/core/workspace.h
浏览文件 @
bdaa5c18
...
@@ -47,14 +47,15 @@ class Workspace {
...
@@ -47,14 +47,15 @@ class Workspace {
std
::
vector
<
std
::
string
>
Tensors
()
const
;
std
::
vector
<
std
::
string
>
Tensors
()
const
;
void
LoadModelTensor
(
const
NetDef
&
net_def
,
MaceStatus
LoadModelTensor
(
const
NetDef
&
net_def
,
DeviceType
type
,
DeviceType
type
,
const
unsigned
char
*
model_data
);
const
unsigned
char
*
model_data
);
ScratchBuffer
*
GetScratchBuffer
(
DeviceType
device_type
);
ScratchBuffer
*
GetScratchBuffer
(
DeviceType
device_type
);
private:
private:
void
CreateOutputTensorBuffer
(
const
NetDef
&
net_def
,
DeviceType
device_type
);
MaceStatus
CreateOutputTensorBuffer
(
const
NetDef
&
net_def
,
DeviceType
device_type
);
TensorMap
tensor_map_
;
TensorMap
tensor_map_
;
...
...
mace/kernels/arm/conv_2d_neon.h
浏览文件 @
bdaa5c18
...
@@ -31,68 +31,38 @@ extern void Conv2dNeonK1x1S1(const float *input,
...
@@ -31,68 +31,38 @@ extern void Conv2dNeonK1x1S1(const float *input,
extern
void
Conv2dNeonK3x3S1
(
const
float
*
input
,
extern
void
Conv2dNeonK3x3S1
(
const
float
*
input
,
const
float
*
filter
,
const
float
*
filter
,
const
index_t
batch
,
const
index_t
*
in_shape
,
const
index_t
in_height
,
const
index_t
*
out_shape
,
const
index_t
in_width
,
const
index_t
in_channels
,
const
index_t
out_height
,
const
index_t
out_width
,
const
index_t
out_channels
,
float
*
output
);
float
*
output
);
extern
void
Conv2dNeonK3x3S2
(
const
float
*
input
,
extern
void
Conv2dNeonK3x3S2
(
const
float
*
input
,
const
float
*
filter
,
const
float
*
filter
,
const
index_t
batch
,
const
index_t
*
in_shape
,
const
index_t
in_height
,
const
index_t
*
out_shape
,
const
index_t
in_width
,
const
index_t
in_channels
,
const
index_t
out_height
,
const
index_t
out_width
,
const
index_t
out_channels
,
float
*
output
);
float
*
output
);
extern
void
Conv2dNeonK5x5S1
(
const
float
*
input
,
extern
void
Conv2dNeonK5x5S1
(
const
float
*
input
,
const
float
*
filter
,
const
float
*
filter
,
const
index_t
batch
,
const
index_t
*
in_shape
,
const
index_t
in_height
,
const
index_t
*
out_shape
,
const
index_t
in_width
,
const
index_t
in_channels
,
const
index_t
out_height
,
const
index_t
out_width
,
const
index_t
out_channels
,
float
*
output
);
float
*
output
);
extern
void
Conv2dNeonK7x7S1
(
const
float
*
input
,
extern
void
Conv2dNeonK7x7S1
(
const
float
*
input
,
const
float
*
filter
,
const
float
*
filter
,
const
index_t
batch
,
const
index_t
*
in_shape
,
const
index_t
in_height
,
const
index_t
*
out_shape
,
const
index_t
in_width
,
const
index_t
in_channels
,
const
index_t
out_height
,
const
index_t
out_width
,
const
index_t
out_channels
,
float
*
output
);
float
*
output
);
extern
void
Conv2dNeonK7x7S2
(
const
float
*
input
,
extern
void
Conv2dNeonK7x7S2
(
const
float
*
input
,
const
float
*
filter
,
const
float
*
filter
,
const
index_t
batch
,
const
index_t
*
in_shape
,
const
index_t
in_height
,
const
index_t
*
out_shape
,
const
index_t
in_width
,
const
index_t
in_channels
,
const
index_t
out_height
,
const
index_t
out_width
,
const
index_t
out_channels
,
float
*
output
);
float
*
output
);
extern
void
Conv2dNeonK7x7S3
(
const
float
*
input
,
extern
void
Conv2dNeonK7x7S3
(
const
float
*
input
,
const
float
*
filter
,
const
float
*
filter
,
const
index_t
batch
,
const
index_t
*
in_shape
,
const
index_t
in_height
,
const
index_t
*
out_shape
,
const
index_t
in_width
,
const
index_t
in_channels
,
const
index_t
out_height
,
const
index_t
out_width
,
const
index_t
out_channels
,
float
*
output
);
float
*
output
);
}
// namespace kernels
}
// namespace kernels
...
...
mace/kernels/arm/conv_2d_neon_3x3.cc
浏览文件 @
bdaa5c18
...
@@ -24,22 +24,22 @@ namespace kernels {
...
@@ -24,22 +24,22 @@ namespace kernels {
// Ho = 2, Wo = 4, Co = 2
// Ho = 2, Wo = 4, Co = 2
void
Conv2dNeonK3x3S1
(
const
float
*
input
,
void
Conv2dNeonK3x3S1
(
const
float
*
input
,
const
float
*
filter
,
const
float
*
filter
,
const
index_t
batch
,
const
index_t
*
in_shape
,
const
index_t
in_height
,
const
index_t
*
out_shape
,
const
index_t
in_width
,
const
index_t
in_channels
,
const
index_t
out_height
,
const
index_t
out_width
,
const
index_t
out_channels
,
float
*
output
)
{
float
*
output
)
{
const
index_t
in_image_size
=
in_
height
*
in_width
;
const
index_t
in_image_size
=
in_
shape
[
2
]
*
in_shape
[
3
]
;
const
index_t
out_image_size
=
out_
height
*
out_width
;
const
index_t
out_image_size
=
out_
shape
[
2
]
*
out_shape
[
3
]
;
const
index_t
in_batch_size
=
in_
channels
*
in_image_size
;
const
index_t
in_batch_size
=
in_
shape
[
1
]
*
in_image_size
;
const
index_t
out_batch_size
=
out_
channels
*
out_image_size
;
const
index_t
out_batch_size
=
out_
shape
[
1
]
*
out_image_size
;
#pragma omp parallel for collapse(2)
#pragma omp parallel for collapse(2)
for
(
index_t
b
=
0
;
b
<
batch
;
++
b
)
{
for
(
index_t
b
=
0
;
b
<
out_shape
[
0
];
++
b
)
{
for
(
index_t
m
=
0
;
m
<
out_channels
;
m
+=
2
)
{
for
(
index_t
m
=
0
;
m
<
out_shape
[
1
];
m
+=
2
)
{
const
index_t
out_channels
=
out_shape
[
1
];
const
index_t
out_height
=
out_shape
[
2
];
const
index_t
out_width
=
out_shape
[
3
];
const
index_t
in_channels
=
in_shape
[
1
];
const
index_t
in_width
=
in_shape
[
3
];
if
(
m
+
1
<
out_channels
)
{
if
(
m
+
1
<
out_channels
)
{
float
*
out_ptr0_base
=
output
+
b
*
out_batch_size
+
m
*
out_image_size
;
float
*
out_ptr0_base
=
output
+
b
*
out_batch_size
+
m
*
out_image_size
;
#if defined(MACE_ENABLE_NEON)
#if defined(MACE_ENABLE_NEON)
...
@@ -522,23 +522,22 @@ void Conv2dNeonK3x3S1(const float *input,
...
@@ -522,23 +522,22 @@ void Conv2dNeonK3x3S1(const float *input,
void
Conv2dNeonK3x3S2
(
const
float
*
input
,
void
Conv2dNeonK3x3S2
(
const
float
*
input
,
const
float
*
filter
,
const
float
*
filter
,
const
index_t
batch
,
const
index_t
*
in_shape
,
const
index_t
in_height
,
const
index_t
*
out_shape
,
const
index_t
in_width
,
const
index_t
in_channels
,
const
index_t
out_height
,
const
index_t
out_width
,
const
index_t
out_channels
,
float
*
output
)
{
float
*
output
)
{
const
index_t
in_image_size
=
in_
height
*
in_width
;
const
index_t
in_image_size
=
in_
shape
[
2
]
*
in_shape
[
3
]
;
const
index_t
out_image_size
=
out_
height
*
out_width
;
const
index_t
out_image_size
=
out_
shape
[
2
]
*
out_shape
[
3
]
;
const
index_t
in_batch_size
=
in_
channels
*
in_image_size
;
const
index_t
in_batch_size
=
in_
shape
[
1
]
*
in_image_size
;
const
index_t
out_batch_size
=
out_
channels
*
out_image_size
;
const
index_t
out_batch_size
=
out_
shape
[
1
]
*
out_image_size
;
#pragma omp parallel for collapse(2)
#pragma omp parallel for collapse(2)
for
(
index_t
b
=
0
;
b
<
batch
;
++
b
)
{
for
(
index_t
b
=
0
;
b
<
out_shape
[
0
];
++
b
)
{
for
(
index_t
m
=
0
;
m
<
out_channels
;
++
m
)
{
for
(
index_t
m
=
0
;
m
<
out_shape
[
1
];
++
m
)
{
for
(
index_t
c
=
0
;
c
<
in_channels
;
++
c
)
{
for
(
index_t
c
=
0
;
c
<
in_shape
[
1
];
++
c
)
{
const
index_t
in_channels
=
in_shape
[
1
];
const
index_t
in_width
=
in_shape
[
3
];
const
index_t
out_height
=
out_shape
[
2
];
const
index_t
out_width
=
out_shape
[
3
];
const
float
*
in_base
=
input
+
b
*
in_batch_size
+
c
*
in_image_size
;
const
float
*
in_base
=
input
+
b
*
in_batch_size
+
c
*
in_image_size
;
const
float
const
float
*
filter_ptr
=
filter
+
m
*
in_channels
*
9
+
c
*
9
;
*
filter_ptr
=
filter
+
m
*
in_channels
*
9
+
c
*
9
;
...
...
mace/kernels/arm/conv_2d_neon_5x5.cc
浏览文件 @
bdaa5c18
...
@@ -103,22 +103,22 @@ inline void Conv2dCPUK5x5Calc(const float *in_ptr_base,
...
@@ -103,22 +103,22 @@ inline void Conv2dCPUK5x5Calc(const float *in_ptr_base,
// Ho = 1, Wo = 4, Co = 4
// Ho = 1, Wo = 4, Co = 4
void
Conv2dNeonK5x5S1
(
const
float
*
input
,
void
Conv2dNeonK5x5S1
(
const
float
*
input
,
const
float
*
filter
,
const
float
*
filter
,
const
index_t
batch
,
const
index_t
*
in_shape
,
const
index_t
in_height
,
const
index_t
*
out_shape
,
const
index_t
in_width
,
const
index_t
in_channels
,
const
index_t
out_height
,
const
index_t
out_width
,
const
index_t
out_channels
,
float
*
output
)
{
float
*
output
)
{
const
index_t
in_image_size
=
in_
height
*
in_width
;
const
index_t
in_image_size
=
in_
shape
[
2
]
*
in_shape
[
3
]
;
const
index_t
out_image_size
=
out_
height
*
out_width
;
const
index_t
out_image_size
=
out_
shape
[
2
]
*
out_shape
[
3
]
;
const
index_t
in_batch_size
=
in_
channels
*
in_image_size
;
const
index_t
in_batch_size
=
in_
shape
[
1
]
*
in_image_size
;
const
index_t
out_batch_size
=
out_
channels
*
out_image_size
;
const
index_t
out_batch_size
=
out_
shape
[
1
]
*
out_image_size
;
#pragma omp parallel for collapse(2)
#pragma omp parallel for collapse(2)
for
(
index_t
b
=
0
;
b
<
batch
;
++
b
)
{
for
(
index_t
b
=
0
;
b
<
out_shape
[
0
];
++
b
)
{
for
(
index_t
m
=
0
;
m
<
out_channels
;
m
+=
4
)
{
for
(
index_t
m
=
0
;
m
<
out_shape
[
1
];
m
+=
4
)
{
const
index_t
out_channels
=
out_shape
[
1
];
const
index_t
out_height
=
out_shape
[
2
];
const
index_t
out_width
=
out_shape
[
3
];
const
index_t
in_channels
=
in_shape
[
1
];
const
index_t
in_width
=
in_shape
[
3
];
if
(
m
+
3
<
out_channels
)
{
if
(
m
+
3
<
out_channels
)
{
float
*
out_ptr0_base
=
output
+
b
*
out_batch_size
+
m
*
out_image_size
;
float
*
out_ptr0_base
=
output
+
b
*
out_batch_size
+
m
*
out_image_size
;
#if defined(MACE_ENABLE_NEON) && !defined(__aarch64__)
#if defined(MACE_ENABLE_NEON) && !defined(__aarch64__)
...
...
mace/kernels/arm/conv_2d_neon_7x7.cc
浏览文件 @
bdaa5c18
...
@@ -180,22 +180,22 @@ inline void Conv2dCPUK7x7Calc(const float *in_ptr_base,
...
@@ -180,22 +180,22 @@ inline void Conv2dCPUK7x7Calc(const float *in_ptr_base,
// Ho = 1, Wo = 4, Co = 4
// Ho = 1, Wo = 4, Co = 4
void
Conv2dNeonK7x7S1
(
const
float
*
input
,
void
Conv2dNeonK7x7S1
(
const
float
*
input
,
const
float
*
filter
,
const
float
*
filter
,
const
index_t
batch
,
const
index_t
*
in_shape
,
const
index_t
in_height
,
const
index_t
*
out_shape
,
const
index_t
in_width
,
const
index_t
in_channels
,
const
index_t
out_height
,
const
index_t
out_width
,
const
index_t
out_channels
,
float
*
output
)
{
float
*
output
)
{
const
index_t
in_image_size
=
in_
height
*
in_width
;
const
index_t
in_image_size
=
in_
shape
[
2
]
*
in_shape
[
3
]
;
const
index_t
out_image_size
=
out_
height
*
out_width
;
const
index_t
out_image_size
=
out_
shape
[
2
]
*
out_shape
[
3
]
;
const
index_t
in_batch_size
=
in_
channels
*
in_image_size
;
const
index_t
in_batch_size
=
in_
shape
[
1
]
*
in_image_size
;
const
index_t
out_batch_size
=
out_
channels
*
out_image_size
;
const
index_t
out_batch_size
=
out_
shape
[
1
]
*
out_image_size
;
#pragma omp parallel for collapse(2)
#pragma omp parallel for collapse(2)
for
(
index_t
b
=
0
;
b
<
batch
;
++
b
)
{
for
(
index_t
b
=
0
;
b
<
out_shape
[
0
];
++
b
)
{
for
(
index_t
m
=
0
;
m
<
out_channels
;
m
+=
4
)
{
for
(
index_t
m
=
0
;
m
<
out_shape
[
1
];
m
+=
4
)
{
const
index_t
out_channels
=
out_shape
[
1
];
const
index_t
out_height
=
out_shape
[
2
];
const
index_t
out_width
=
out_shape
[
3
];
const
index_t
in_channels
=
in_shape
[
1
];
const
index_t
in_width
=
in_shape
[
3
];
if
(
m
+
3
<
out_channels
)
{
if
(
m
+
3
<
out_channels
)
{
float
*
out_ptr0_base
=
output
+
b
*
out_batch_size
+
m
*
out_image_size
;
float
*
out_ptr0_base
=
output
+
b
*
out_batch_size
+
m
*
out_image_size
;
#if defined(MACE_ENABLE_NEON)
#if defined(MACE_ENABLE_NEON)
...
@@ -336,22 +336,22 @@ void Conv2dNeonK7x7S1(const float *input,
...
@@ -336,22 +336,22 @@ void Conv2dNeonK7x7S1(const float *input,
// Ho = 1, Wo = 4, Co = 4
// Ho = 1, Wo = 4, Co = 4
void
Conv2dNeonK7x7S2
(
const
float
*
input
,
void
Conv2dNeonK7x7S2
(
const
float
*
input
,
const
float
*
filter
,
const
float
*
filter
,
const
index_t
batch
,
const
index_t
*
in_shape
,
const
index_t
in_height
,
const
index_t
*
out_shape
,
const
index_t
in_width
,
const
index_t
in_channels
,
const
index_t
out_height
,
const
index_t
out_width
,
const
index_t
out_channels
,
float
*
output
)
{
float
*
output
)
{
const
index_t
in_image_size
=
in_
height
*
in_width
;
const
index_t
in_image_size
=
in_
shape
[
2
]
*
in_shape
[
3
]
;
const
index_t
out_image_size
=
out_
height
*
out_width
;
const
index_t
out_image_size
=
out_
shape
[
2
]
*
out_shape
[
3
]
;
const
index_t
in_batch_size
=
in_
channels
*
in_image_size
;
const
index_t
in_batch_size
=
in_
shape
[
1
]
*
in_image_size
;
const
index_t
out_batch_size
=
out_
channels
*
out_image_size
;
const
index_t
out_batch_size
=
out_
shape
[
1
]
*
out_image_size
;
#pragma omp parallel for collapse(2)
#pragma omp parallel for collapse(2)
for
(
index_t
b
=
0
;
b
<
batch
;
++
b
)
{
for
(
index_t
b
=
0
;
b
<
out_shape
[
0
];
++
b
)
{
for
(
index_t
m
=
0
;
m
<
out_channels
;
m
+=
4
)
{
for
(
index_t
m
=
0
;
m
<
out_shape
[
1
];
m
+=
4
)
{
const
index_t
out_channels
=
out_shape
[
1
];
const
index_t
out_height
=
out_shape
[
2
];
const
index_t
out_width
=
out_shape
[
3
];
const
index_t
in_channels
=
in_shape
[
1
];
const
index_t
in_width
=
in_shape
[
3
];
if
(
m
+
3
<
out_channels
)
{
if
(
m
+
3
<
out_channels
)
{
float
*
out_ptr0_base
=
output
+
b
*
out_batch_size
+
m
*
out_image_size
;
float
*
out_ptr0_base
=
output
+
b
*
out_batch_size
+
m
*
out_image_size
;
#if defined(MACE_ENABLE_NEON)
#if defined(MACE_ENABLE_NEON)
...
@@ -502,22 +502,22 @@ void Conv2dNeonK7x7S2(const float *input,
...
@@ -502,22 +502,22 @@ void Conv2dNeonK7x7S2(const float *input,
// Ho = 1, Wo = 4, Co = 4
// Ho = 1, Wo = 4, Co = 4
void
Conv2dNeonK7x7S3
(
const
float
*
input
,
void
Conv2dNeonK7x7S3
(
const
float
*
input
,
const
float
*
filter
,
const
float
*
filter
,
const
index_t
batch
,
const
index_t
*
in_shape
,
const
index_t
in_height
,
const
index_t
*
out_shape
,
const
index_t
in_width
,
const
index_t
in_channels
,
const
index_t
out_height
,
const
index_t
out_width
,
const
index_t
out_channels
,
float
*
output
)
{
float
*
output
)
{
const
index_t
in_image_size
=
in_
height
*
in_width
;
const
index_t
in_image_size
=
in_
shape
[
2
]
*
in_shape
[
3
]
;
const
index_t
out_image_size
=
out_
height
*
out_width
;
const
index_t
out_image_size
=
out_
shape
[
2
]
*
out_shape
[
3
]
;
const
index_t
in_batch_size
=
in_
channels
*
in_image_size
;
const
index_t
in_batch_size
=
in_
shape
[
1
]
*
in_image_size
;
const
index_t
out_batch_size
=
out_
channels
*
out_image_size
;
const
index_t
out_batch_size
=
out_
shape
[
1
]
*
out_image_size
;
#pragma omp parallel for collapse(2)
#pragma omp parallel for collapse(2)
for
(
index_t
b
=
0
;
b
<
batch
;
++
b
)
{
for
(
index_t
b
=
0
;
b
<
out_shape
[
0
];
++
b
)
{
for
(
index_t
m
=
0
;
m
<
out_channels
;
m
+=
4
)
{
for
(
index_t
m
=
0
;
m
<
out_shape
[
1
];
m
+=
4
)
{
const
index_t
out_channels
=
out_shape
[
1
];
const
index_t
out_height
=
out_shape
[
2
];
const
index_t
out_width
=
out_shape
[
3
];
const
index_t
in_channels
=
in_shape
[
1
];
const
index_t
in_width
=
in_shape
[
3
];
if
(
m
+
3
<
out_channels
)
{
if
(
m
+
3
<
out_channels
)
{
float
*
out_ptr0_base
=
output
+
b
*
out_batch_size
+
m
*
out_image_size
;
float
*
out_ptr0_base
=
output
+
b
*
out_batch_size
+
m
*
out_image_size
;
#if defined(MACE_ENABLE_NEON)
#if defined(MACE_ENABLE_NEON)
...
...
mace/kernels/arm/depthwise_conv2d_neon.h
浏览文件 @
bdaa5c18
...
@@ -22,15 +22,9 @@ namespace kernels {
...
@@ -22,15 +22,9 @@ namespace kernels {
void
DepthwiseConv2dNeonK3x3S1
(
const
float
*
input
,
void
DepthwiseConv2dNeonK3x3S1
(
const
float
*
input
,
const
float
*
filter
,
const
float
*
filter
,
const
index_t
batch
,
const
index_t
*
in_shape
,
const
index_t
in_height
,
const
index_t
*
out_shape
,
const
index_t
in_width
,
const
int
*
pad_hw
,
const
index_t
in_channels
,
const
index_t
out_height
,
const
index_t
out_width
,
const
index_t
out_channels
,
const
int
pad_top
,
const
int
pad_left
,
const
index_t
valid_h_start
,
const
index_t
valid_h_start
,
const
index_t
valid_h_stop
,
const
index_t
valid_h_stop
,
const
index_t
valid_w_start
,
const
index_t
valid_w_start
,
...
@@ -39,15 +33,9 @@ void DepthwiseConv2dNeonK3x3S1(const float *input,
...
@@ -39,15 +33,9 @@ void DepthwiseConv2dNeonK3x3S1(const float *input,
void
DepthwiseConv2dNeonK3x3S2
(
const
float
*
input
,
void
DepthwiseConv2dNeonK3x3S2
(
const
float
*
input
,
const
float
*
filter
,
const
float
*
filter
,
const
index_t
batch
,
const
index_t
*
in_shape
,
const
index_t
in_height
,
const
index_t
*
out_shape
,
const
index_t
in_width
,
const
int
*
pad_hw
,
const
index_t
in_channels
,
const
index_t
out_height
,
const
index_t
out_width
,
const
index_t
out_channels
,
const
int
pad_top
,
const
int
pad_left
,
const
index_t
valid_h_start
,
const
index_t
valid_h_start
,
const
index_t
valid_h_stop
,
const
index_t
valid_h_stop
,
const
index_t
valid_w_start
,
const
index_t
valid_w_start
,
...
...
mace/kernels/arm/depthwise_conv2d_neon_3x3.cc
浏览文件 @
bdaa5c18
...
@@ -52,15 +52,9 @@ void DepthwiseConv2dPixel(const float *in_base,
...
@@ -52,15 +52,9 @@ void DepthwiseConv2dPixel(const float *in_base,
// Ho = 2, Wo = 4, Co = 1
// Ho = 2, Wo = 4, Co = 1
void
DepthwiseConv2dNeonK3x3S1
(
const
float
*
input
,
void
DepthwiseConv2dNeonK3x3S1
(
const
float
*
input
,
const
float
*
filter
,
const
float
*
filter
,
const
index_t
batch
,
const
index_t
*
in_shape
,
const
index_t
in_height
,
const
index_t
*
out_shape
,
const
index_t
in_width
,
const
int
*
pad_hw
,
const
index_t
in_channels
,
const
index_t
out_height
,
const
index_t
out_width
,
const
index_t
out_channels
,
const
int
pad_top
,
const
int
pad_left
,
const
index_t
valid_h_start
,
const
index_t
valid_h_start
,
const
index_t
valid_h_stop
,
const
index_t
valid_h_stop
,
const
index_t
valid_w_start
,
const
index_t
valid_w_start
,
...
@@ -70,25 +64,30 @@ void DepthwiseConv2dNeonK3x3S1(const float *input,
...
@@ -70,25 +64,30 @@ void DepthwiseConv2dNeonK3x3S1(const float *input,
MACE_UNUSED
(
valid_w_start
);
MACE_UNUSED
(
valid_w_start
);
MACE_UNUSED
(
valid_w_stop
);
MACE_UNUSED
(
valid_w_stop
);
#endif
#endif
const
index_t
multiplier
=
out_
channels
/
in_channels
;
const
index_t
multiplier
=
out_
shape
[
1
]
/
in_shape
[
1
]
;
const
index_t
in_image_size
=
in_
height
*
in_width
;
const
index_t
in_image_size
=
in_
shape
[
2
]
*
in_shape
[
3
]
;
const
index_t
out_image_size
=
out_
height
*
out_width
;
const
index_t
out_image_size
=
out_
shape
[
2
]
*
out_shape
[
3
]
;
const
index_t
in_batch_size
=
in_
channels
*
in_image_size
;
const
index_t
in_batch_size
=
in_
shape
[
1
]
*
in_image_size
;
const
index_t
out_batch_size
=
out_
channels
*
out_image_size
;
const
index_t
out_batch_size
=
out_
shape
[
1
]
*
out_image_size
;
#pragma omp parallel for collapse(2)
#pragma omp parallel for collapse(2)
for
(
index_t
b
=
0
;
b
<
batch
;
++
b
)
{
for
(
index_t
b
=
0
;
b
<
in_shape
[
0
]
;
++
b
)
{
for
(
index_t
m
=
0
;
m
<
out_
channels
;
++
m
)
{
for
(
index_t
m
=
0
;
m
<
out_
shape
[
1
]
;
++
m
)
{
index_t
c
=
m
/
multiplier
;
index_t
c
=
m
/
multiplier
;
index_t
multi_index
=
m
%
multiplier
;
index_t
multi_index
=
m
%
multiplier
;
const
float
*
in_base
=
input
+
b
*
in_batch_size
+
c
*
in_image_size
;
const
float
*
in_base
=
input
+
b
*
in_batch_size
+
c
*
in_image_size
;
const
float
*
filter_ptr
=
filter
+
multi_index
*
in_
channels
*
9
+
c
*
9
;
const
float
*
filter_ptr
=
filter
+
multi_index
*
in_
shape
[
1
]
*
9
+
c
*
9
;
float
*
out_base
=
output
+
b
*
out_batch_size
+
m
*
out_image_size
;
float
*
out_base
=
output
+
b
*
out_batch_size
+
m
*
out_image_size
;
index_t
h
,
w
;
index_t
h
,
w
;
const
index_t
pad_top
=
pad_hw
[
0
];
const
index_t
pad_left
=
pad_hw
[
1
];
const
index_t
out_width
=
out_shape
[
3
];
const
index_t
in_height
=
in_shape
[
2
];
const
index_t
in_width
=
in_shape
[
3
];
// top
// top
for
(
h
=
0
;
h
<
valid_h_start
;
++
h
)
{
for
(
h
=
0
;
h
<
valid_h_start
;
++
h
)
{
for
(
w
=
0
;
w
<
out_
width
;
++
w
)
{
for
(
w
=
0
;
w
<
out_
shape
[
3
]
;
++
w
)
{
DepthwiseConv2dPixel
(
in_base
,
DepthwiseConv2dPixel
(
in_base
,
filter_ptr
,
filter_ptr
,
h
,
h
,
...
@@ -256,7 +255,7 @@ void DepthwiseConv2dNeonK3x3S1(const float *input,
...
@@ -256,7 +255,7 @@ void DepthwiseConv2dNeonK3x3S1(const float *input,
}
// h
}
// h
#else
#else
for
(
index_t
ih
=
valid_h_start
;
ih
<
valid_h_stop
;
++
ih
)
{
for
(
index_t
ih
=
valid_h_start
;
ih
<
valid_h_stop
;
++
ih
)
{
for
(
index_t
iw
=
0
;
iw
<
out_
width
;
++
iw
)
{
for
(
index_t
iw
=
0
;
iw
<
out_
shape
[
3
]
;
++
iw
)
{
DepthwiseConv2dPixel
(
in_base
,
DepthwiseConv2dPixel
(
in_base
,
filter_ptr
,
filter_ptr
,
ih
,
ih
,
...
@@ -274,8 +273,8 @@ void DepthwiseConv2dNeonK3x3S1(const float *input,
...
@@ -274,8 +273,8 @@ void DepthwiseConv2dNeonK3x3S1(const float *input,
#endif
#endif
// bottom
// bottom
for
(;
h
<
out_
height
;
++
h
)
{
for
(;
h
<
out_
shape
[
2
]
;
++
h
)
{
for
(
w
=
0
;
w
<
out_
width
;
++
w
)
{
for
(
w
=
0
;
w
<
out_
shape
[
3
]
;
++
w
)
{
DepthwiseConv2dPixel
(
in_base
,
DepthwiseConv2dPixel
(
in_base
,
filter_ptr
,
filter_ptr
,
h
,
h
,
...
@@ -296,15 +295,9 @@ void DepthwiseConv2dNeonK3x3S1(const float *input,
...
@@ -296,15 +295,9 @@ void DepthwiseConv2dNeonK3x3S1(const float *input,
void
DepthwiseConv2dNeonK3x3S2
(
const
float
*
input
,
void
DepthwiseConv2dNeonK3x3S2
(
const
float
*
input
,
const
float
*
filter
,
const
float
*
filter
,
const
index_t
batch
,
const
index_t
*
in_shape
,
const
index_t
in_height
,
const
index_t
*
out_shape
,
const
index_t
in_width
,
const
int
*
pad_hw
,
const
index_t
in_channels
,
const
index_t
out_height
,
const
index_t
out_width
,
const
index_t
out_channels
,
const
int
pad_top
,
const
int
pad_left
,
const
index_t
valid_h_start
,
const
index_t
valid_h_start
,
const
index_t
valid_h_stop
,
const
index_t
valid_h_stop
,
const
index_t
valid_w_start
,
const
index_t
valid_w_start
,
...
@@ -314,22 +307,26 @@ void DepthwiseConv2dNeonK3x3S2(const float *input,
...
@@ -314,22 +307,26 @@ void DepthwiseConv2dNeonK3x3S2(const float *input,
MACE_UNUSED
(
valid_w_start
);
MACE_UNUSED
(
valid_w_start
);
MACE_UNUSED
(
valid_w_stop
);
MACE_UNUSED
(
valid_w_stop
);
#endif
#endif
const
index_t
multiplier
=
out_
channels
/
in_channels
;
const
index_t
multiplier
=
out_
shape
[
1
]
/
in_shape
[
1
]
;
const
index_t
in_image_size
=
in_
height
*
in_width
;
const
index_t
in_image_size
=
in_
shape
[
2
]
*
in_shape
[
3
]
;
const
index_t
out_image_size
=
out_
height
*
out_width
;
const
index_t
out_image_size
=
out_
shape
[
2
]
*
out_shape
[
3
]
;
const
index_t
in_batch_size
=
in_
channels
*
in_image_size
;
const
index_t
in_batch_size
=
in_
shape
[
1
]
*
in_image_size
;
const
index_t
out_batch_size
=
out_
channels
*
out_image_size
;
const
index_t
out_batch_size
=
out_
shape
[
1
]
*
out_image_size
;
#pragma omp parallel for collapse(2)
#pragma omp parallel for collapse(2)
for
(
index_t
b
=
0
;
b
<
batch
;
++
b
)
{
for
(
index_t
b
=
0
;
b
<
in_shape
[
0
]
;
++
b
)
{
for
(
index_t
m
=
0
;
m
<
out_
channels
;
++
m
)
{
for
(
index_t
m
=
0
;
m
<
out_
shape
[
1
]
;
++
m
)
{
index_t
c
=
m
/
multiplier
;
index_t
c
=
m
/
multiplier
;
index_t
multi_index
=
m
%
multiplier
;
index_t
multi_index
=
m
%
multiplier
;
const
float
*
in_base
=
input
+
b
*
in_batch_size
+
c
*
in_image_size
;
const
float
*
in_base
=
input
+
b
*
in_batch_size
+
c
*
in_image_size
;
const
float
*
filter_ptr
=
filter
+
multi_index
*
in_
channels
*
9
+
c
*
9
;
const
float
*
filter_ptr
=
filter
+
multi_index
*
in_
shape
[
1
]
*
9
+
c
*
9
;
float
*
out_base
=
output
+
b
*
out_batch_size
+
m
*
out_image_size
;
float
*
out_base
=
output
+
b
*
out_batch_size
+
m
*
out_image_size
;
index_t
h
,
w
;
index_t
h
,
w
;
const
index_t
pad_top
=
pad_hw
[
0
];
const
index_t
pad_left
=
pad_hw
[
1
];
const
index_t
out_width
=
out_shape
[
3
];
const
index_t
in_height
=
in_shape
[
2
];
const
index_t
in_width
=
in_shape
[
3
];
// top
// top
for
(
h
=
0
;
h
<
valid_h_start
;
++
h
)
{
for
(
h
=
0
;
h
<
valid_h_start
;
++
h
)
{
for
(
w
=
0
;
w
<
out_width
;
++
w
)
{
for
(
w
=
0
;
w
<
out_width
;
++
w
)
{
...
@@ -472,8 +469,8 @@ void DepthwiseConv2dNeonK3x3S2(const float *input,
...
@@ -472,8 +469,8 @@ void DepthwiseConv2dNeonK3x3S2(const float *input,
#endif
#endif
// bottom
// bottom
for
(;
h
<
out_
height
;
++
h
)
{
for
(;
h
<
out_
shape
[
2
]
;
++
h
)
{
for
(
w
=
0
;
w
<
out_
width
;
++
w
)
{
for
(
w
=
0
;
w
<
out_
shape
[
3
]
;
++
w
)
{
DepthwiseConv2dPixel
(
in_base
,
DepthwiseConv2dPixel
(
in_base
,
filter_ptr
,
filter_ptr
,
h
,
h
,
...
...
mace/kernels/conv_2d.h
浏览文件 @
bdaa5c18
...
@@ -84,49 +84,45 @@ struct Conv2dFunctor<DeviceType::CPU, float> : Conv2dFunctorBase {
...
@@ -84,49 +84,45 @@ struct Conv2dFunctor<DeviceType::CPU, float> : Conv2dFunctorBase {
void
Conv2dGeneral
(
const
float
*
input
,
void
Conv2dGeneral
(
const
float
*
input
,
const
float
*
filter
,
const
float
*
filter
,
const
index_t
batch
,
const
index_t
*
in_shape
,
const
index_t
in_height
,
const
index_t
*
out_shape
,
const
index_t
in_width
,
const
index_t
*
filter_shape
,
const
index_t
in_channels
,
const
int
*
stride_hw
,
const
index_t
out_height
,
const
int
*
dilation_hw
,
const
index_t
out_width
,
const
index_t
out_channels
,
const
int
filter_height
,
const
int
filter_width
,
const
int
stride_h
,
const
int
stride_w
,
const
int
dilation_h
,
const
int
dilation_w
,
float
*
output
)
{
float
*
output
)
{
const
index_t
in_image_size
=
in_
height
*
in_width
;
const
index_t
in_image_size
=
in_
shape
[
2
]
*
in_shape
[
3
]
;
const
index_t
out_image_size
=
out_
height
*
out_width
;
const
index_t
out_image_size
=
out_
shape
[
2
]
*
out_shape
[
3
]
;
const
index_t
in_batch_size
=
in_channels
*
in_image_size
;
const
index_t
in_batch_size
=
filter_shape
[
1
]
*
in_image_size
;
const
index_t
out_batch_size
=
out_channels
*
out_image_size
;
const
index_t
out_batch_size
=
filter_shape
[
0
]
*
out_image_size
;
const
index_t
filter_size
=
filter_
height
*
filter_width
;
const
index_t
filter_size
=
filter_
shape
[
2
]
*
filter_shape
[
3
]
;
#pragma omp parallel for collapse(2)
#pragma omp parallel for collapse(2)
for
(
index_t
b
=
0
;
b
<
batch
;
++
b
)
{
for
(
index_t
b
=
0
;
b
<
in_shape
[
0
];
b
++
)
{
for
(
index_t
m
=
0
;
m
<
out_channels
;
m
+=
4
)
{
for
(
index_t
m
=
0
;
m
<
filter_shape
[
0
];
m
+=
4
)
{
const
index_t
in_width
=
in_shape
[
3
];
const
index_t
out_height
=
out_shape
[
2
];
const
index_t
out_width
=
out_shape
[
3
];
const
index_t
out_channels
=
filter_shape
[
0
];
const
index_t
in_channels
=
filter_shape
[
1
];
const
int
stride_h
=
stride_hw
[
0
];
const
int
stride_w
=
stride_hw
[
1
];
const
int
dilation_h
=
dilation_hw
[
0
];
const
int
dilation_w
=
dilation_hw
[
1
];
if
(
m
+
3
<
out_channels
)
{
if
(
m
+
3
<
out_channels
)
{
float
*
out_ptr0_base
=
float
*
out_ptr0_base
=
output
+
b
*
out_batch_size
+
m
*
out_image_size
;
output
+
b
*
out_batch_size
+
m
*
out_image_size
;
float
*
out_ptr1_base
=
float
*
out_ptr1_base
=
out_ptr0_base
+
out_image_size
;
output
+
b
*
out_batch_size
+
(
m
+
1
)
*
out_image_size
;
float
*
out_ptr2_base
=
out_ptr1_base
+
out_image_size
;
float
*
out_ptr2_base
=
float
*
out_ptr3_base
=
out_ptr2_base
+
out_image_size
;
output
+
b
*
out_batch_size
+
(
m
+
2
)
*
out_image_size
;
float
*
out_ptr3_base
=
output
+
b
*
out_batch_size
+
(
m
+
3
)
*
out_image_size
;
for
(
index_t
c
=
0
;
c
<
in_channels
;
++
c
)
{
for
(
index_t
c
=
0
;
c
<
in_channels
;
++
c
)
{
const
float
*
in_ptr_base
=
const
float
*
in_ptr_base
=
input
+
b
*
in_batch_size
+
c
*
in_image_size
;
input
+
b
*
in_batch_size
+
c
*
in_image_size
;
const
float
*
filter_ptr0
=
const
float
*
filter_ptr0
=
filter
+
m
*
in_channels
*
filter_size
+
c
*
filter_size
;
filter
+
m
*
in_channels
*
filter_size
+
c
*
filter_size
;
const
float
*
filter_ptr1
=
const
float
*
filter_ptr1
=
filter_ptr0
+
in_channels
*
filter_size
;
filter
+
(
m
+
1
)
*
in_channels
*
filter_size
+
c
*
filter_size
;
const
float
*
filter_ptr2
=
filter_ptr1
+
in_channels
*
filter_size
;
const
float
*
filter_ptr2
=
const
float
*
filter_ptr3
=
filter_ptr2
+
in_channels
*
filter_size
;
filter
+
(
m
+
2
)
*
in_channels
*
filter_size
+
c
*
filter_size
;
const
float
*
filter_ptr3
=
filter
+
(
m
+
3
)
*
in_channels
*
filter_size
+
c
*
filter_size
;
for
(
index_t
h
=
0
;
h
<
out_height
;
++
h
)
{
for
(
index_t
h
=
0
;
h
<
out_height
;
++
h
)
{
for
(
index_t
w
=
0
;
w
+
3
<
out_width
;
w
+=
4
)
{
for
(
index_t
w
=
0
;
w
+
3
<
out_width
;
w
+=
4
)
{
// input offset
// input offset
...
@@ -144,8 +140,8 @@ struct Conv2dFunctor<DeviceType::CPU, float> : Conv2dFunctorBase {
...
@@ -144,8 +140,8 @@ struct Conv2dFunctor<DeviceType::CPU, float> : Conv2dFunctorBase {
vo3
[
ow
]
=
out_ptr3_base
[
out_offset
+
ow
];
vo3
[
ow
]
=
out_ptr3_base
[
out_offset
+
ow
];
}
}
// calc by row
// calc by row
for
(
index_t
kh
=
0
;
kh
<
filter_
height
;
++
kh
)
{
for
(
index_t
kh
=
0
;
kh
<
filter_
shape
[
2
]
;
++
kh
)
{
for
(
index_t
kw
=
0
;
kw
<
filter_
width
;
++
kw
)
{
for
(
index_t
kw
=
0
;
kw
<
filter_
shape
[
3
]
;
++
kw
)
{
// outch 0
// outch 0
vo0
[
0
]
+=
in_ptr_base
[
in_offset
vo0
[
0
]
+=
in_ptr_base
[
in_offset
+
kw
*
dilation_w
]
*
filter_ptr0
[
kw
];
+
kw
*
dilation_w
]
*
filter_ptr0
[
kw
];
...
@@ -185,10 +181,10 @@ struct Conv2dFunctor<DeviceType::CPU, float> : Conv2dFunctorBase {
...
@@ -185,10 +181,10 @@ struct Conv2dFunctor<DeviceType::CPU, float> : Conv2dFunctorBase {
}
// kw
}
// kw
in_offset
+=
dilation_h
*
in_width
;
in_offset
+=
dilation_h
*
in_width
;
filter_ptr0
+=
filter_
width
;
filter_ptr0
+=
filter_
shape
[
3
]
;
filter_ptr1
+=
filter_
width
;
filter_ptr1
+=
filter_
shape
[
3
]
;
filter_ptr2
+=
filter_
width
;
filter_ptr2
+=
filter_
shape
[
3
]
;
filter_ptr3
+=
filter_
width
;
filter_ptr3
+=
filter_
shape
[
3
]
;
}
// kh
}
// kh
for
(
index_t
ow
=
0
;
ow
<
4
;
++
ow
)
{
for
(
index_t
ow
=
0
;
ow
<
4
;
++
ow
)
{
...
@@ -230,8 +226,8 @@ struct Conv2dFunctor<DeviceType::CPU, float> : Conv2dFunctorBase {
...
@@ -230,8 +226,8 @@ struct Conv2dFunctor<DeviceType::CPU, float> : Conv2dFunctorBase {
}
}
// calc by row
// calc by row
for
(
index_t
kh
=
0
;
kh
<
filter_
height
;
++
kh
)
{
for
(
index_t
kh
=
0
;
kh
<
filter_
shape
[
2
]
;
++
kh
)
{
for
(
index_t
kw
=
0
;
kw
<
filter_
width
;
++
kw
)
{
for
(
index_t
kw
=
0
;
kw
<
filter_
shape
[
3
]
;
++
kw
)
{
// outch 0
// outch 0
vo0
[
0
]
+=
in_ptr_base
[
in_offset
vo0
[
0
]
+=
in_ptr_base
[
in_offset
+
kw
*
dilation_w
]
*
filter_ptr0
[
kw
];
+
kw
*
dilation_w
]
*
filter_ptr0
[
kw
];
...
@@ -244,7 +240,7 @@ struct Conv2dFunctor<DeviceType::CPU, float> : Conv2dFunctorBase {
...
@@ -244,7 +240,7 @@ struct Conv2dFunctor<DeviceType::CPU, float> : Conv2dFunctorBase {
}
// kw
}
// kw
in_offset
+=
dilation_h
*
in_width
;
in_offset
+=
dilation_h
*
in_width
;
filter_ptr0
+=
filter_
width
;
filter_ptr0
+=
filter_
shape
[
3
]
;
}
// kh
}
// kh
for
(
index_t
ow
=
0
;
ow
<
4
;
++
ow
)
{
for
(
index_t
ow
=
0
;
ow
<
4
;
++
ow
)
{
...
@@ -301,7 +297,6 @@ struct Conv2dFunctor<DeviceType::CPU, float> : Conv2dFunctorBase {
...
@@ -301,7 +297,6 @@ struct Conv2dFunctor<DeviceType::CPU, float> : Conv2dFunctorBase {
output_shape
.
data
());
output_shape
.
data
());
}
}
output
->
Resize
(
output_shape
);
output
->
Resize
(
output_shape
);
output
->
Clear
();
index_t
batch
=
output
->
dim
(
0
);
index_t
batch
=
output
->
dim
(
0
);
index_t
channels
=
output
->
dim
(
1
);
index_t
channels
=
output
->
dim
(
1
);
...
@@ -419,7 +414,7 @@ struct Conv2dFunctor<DeviceType::CPU, float> : Conv2dFunctorBase {
...
@@ -419,7 +414,7 @@ struct Conv2dFunctor<DeviceType::CPU, float> : Conv2dFunctorBase {
if
(
extra_input_width
!=
padded_input_width
)
{
if
(
extra_input_width
!=
padded_input_width
)
{
pad_right
+=
(
extra_input_width
-
padded_input_width
);
pad_right
+=
(
extra_input_width
-
padded_input_width
);
}
}
}
else
{
}
else
if
(
!
use_neon_1x1_s1
)
{
extra_output_height
=
height
;
extra_output_height
=
height
;
extra_input_height
=
extra_input_height
=
std
::
max
(
padded_input_height
,
(
extra_output_height
-
1
)
*
stride_h
std
::
max
(
padded_input_height
,
(
extra_output_height
-
1
)
*
stride_h
...
@@ -478,6 +473,10 @@ struct Conv2dFunctor<DeviceType::CPU, float> : Conv2dFunctorBase {
...
@@ -478,6 +473,10 @@ struct Conv2dFunctor<DeviceType::CPU, float> : Conv2dFunctorBase {
transformed_output
(
scratch_
->
Scratch
(
transformed_output_size
),
DT_FLOAT
);
transformed_output
(
scratch_
->
Scratch
(
transformed_output_size
),
DT_FLOAT
);
Tensor
padded_input
(
scratch_
->
Scratch
(
padded_input_size
),
DT_FLOAT
);
Tensor
padded_input
(
scratch_
->
Scratch
(
padded_input_size
),
DT_FLOAT
);
Tensor
padded_output
(
scratch_
->
Scratch
(
padded_output_size
),
DT_FLOAT
);
Tensor
padded_output
(
scratch_
->
Scratch
(
padded_output_size
),
DT_FLOAT
);
const
index_t
extra_input_shape
[
4
]
=
{
batch
,
input_channels
,
extra_input_height
,
extra_input_width
};
const
index_t
extra_output_shape
[
4
]
=
{
batch
,
channels
,
extra_output_height
,
extra_output_width
};
// decide which convolution function to call
// decide which convolution function to call
if
(
use_winograd
)
{
if
(
use_winograd
)
{
...
@@ -512,6 +511,7 @@ struct Conv2dFunctor<DeviceType::CPU, float> : Conv2dFunctorBase {
...
@@ -512,6 +511,7 @@ struct Conv2dFunctor<DeviceType::CPU, float> : Conv2dFunctorBase {
float
*
transformed_input_data
=
transformed_input
.
mutable_data
<
float
>
();
float
*
transformed_input_data
=
transformed_input
.
mutable_data
<
float
>
();
float
*
transformed_output_data
=
transformed_output
.
mutable_data
<
float
>
();
float
*
transformed_output_data
=
transformed_output
.
mutable_data
<
float
>
();
conv_func
=
[
=
](
const
float
*
pad_input
,
float
*
pad_output
)
{
conv_func
=
[
=
](
const
float
*
pad_input
,
float
*
pad_output
)
{
WinoGradConv3x3s1
(
pad_input
,
WinoGradConv3x3s1
(
pad_input
,
transformed_filter_ptr
,
transformed_filter_ptr
,
...
@@ -529,26 +529,16 @@ struct Conv2dFunctor<DeviceType::CPU, float> : Conv2dFunctorBase {
...
@@ -529,26 +529,16 @@ struct Conv2dFunctor<DeviceType::CPU, float> : Conv2dFunctorBase {
conv_func
=
[
=
](
const
float
*
pad_input
,
float
*
pad_output
)
{
conv_func
=
[
=
](
const
float
*
pad_input
,
float
*
pad_output
)
{
Conv2dNeonK3x3S1
(
pad_input
,
Conv2dNeonK3x3S1
(
pad_input
,
filter_data
,
filter_data
,
batch
,
extra_input_shape
,
extra_input_height
,
extra_output_shape
,
extra_input_width
,
input_channels
,
extra_output_height
,
extra_output_width
,
channels
,
pad_output
);
pad_output
);
};
};
}
else
if
(
use_neon_3x3_s2
)
{
}
else
if
(
use_neon_3x3_s2
)
{
conv_func
=
[
=
](
const
float
*
pad_input
,
float
*
pad_output
)
{
conv_func
=
[
=
](
const
float
*
pad_input
,
float
*
pad_output
)
{
Conv2dNeonK3x3S2
(
pad_input
,
Conv2dNeonK3x3S2
(
pad_input
,
filter_data
,
filter_data
,
batch
,
extra_input_shape
,
extra_input_height
,
extra_output_shape
,
extra_input_width
,
input_channels
,
extra_output_height
,
extra_output_width
,
channels
,
pad_output
);
pad_output
);
};
};
}
else
if
(
use_neon_1x1_s1
)
{
}
else
if
(
use_neon_1x1_s1
)
{
...
@@ -566,71 +556,43 @@ struct Conv2dFunctor<DeviceType::CPU, float> : Conv2dFunctorBase {
...
@@ -566,71 +556,43 @@ struct Conv2dFunctor<DeviceType::CPU, float> : Conv2dFunctorBase {
conv_func
=
[
=
](
const
float
*
pad_input
,
float
*
pad_output
)
{
conv_func
=
[
=
](
const
float
*
pad_input
,
float
*
pad_output
)
{
Conv2dNeonK5x5S1
(
pad_input
,
Conv2dNeonK5x5S1
(
pad_input
,
filter_data
,
filter_data
,
batch
,
extra_input_shape
,
extra_input_height
,
extra_output_shape
,
extra_input_width
,
input_channels
,
extra_output_height
,
extra_output_width
,
channels
,
pad_output
);
pad_output
);
};
};
}
else
if
(
use_neon_7x7_s1
)
{
}
else
if
(
use_neon_7x7_s1
)
{
conv_func
=
[
=
](
const
float
*
pad_input
,
float
*
pad_output
)
{
conv_func
=
[
=
](
const
float
*
pad_input
,
float
*
pad_output
)
{
Conv2dNeonK7x7S1
(
pad_input
,
Conv2dNeonK7x7S1
(
pad_input
,
filter_data
,
filter_data
,
batch
,
extra_input_shape
,
extra_input_height
,
extra_output_shape
,
extra_input_width
,
input_channels
,
extra_output_height
,
extra_output_width
,
channels
,
pad_output
);
pad_output
);
};
};
}
else
if
(
use_neon_7x7_s2
)
{
}
else
if
(
use_neon_7x7_s2
)
{
conv_func
=
[
=
](
const
float
*
pad_input
,
float
*
pad_output
)
{
conv_func
=
[
=
](
const
float
*
pad_input
,
float
*
pad_output
)
{
Conv2dNeonK7x7S2
(
pad_input
,
Conv2dNeonK7x7S2
(
pad_input
,
filter_data
,
filter_data
,
batch
,
extra_input_shape
,
extra_input_height
,
extra_output_shape
,
extra_input_width
,
input_channels
,
extra_output_height
,
extra_output_width
,
channels
,
pad_output
);
pad_output
);
};
};
}
else
if
(
use_neon_7x7_s3
)
{
}
else
if
(
use_neon_7x7_s3
)
{
conv_func
=
[
=
](
const
float
*
pad_input
,
float
*
pad_output
)
{
conv_func
=
[
=
](
const
float
*
pad_input
,
float
*
pad_output
)
{
Conv2dNeonK7x7S3
(
pad_input
,
Conv2dNeonK7x7S3
(
pad_input
,
filter_data
,
filter_data
,
batch
,
extra_input_shape
,
extra_input_height
,
extra_output_shape
,
extra_input_width
,
input_channels
,
extra_output_height
,
extra_output_width
,
channels
,
pad_output
);
pad_output
);
};
};
}
else
{
}
else
{
conv_func
=
[
=
](
const
float
*
pad_input
,
float
*
pad_output
)
{
conv_func
=
[
=
](
const
float
*
pad_input
,
float
*
pad_output
)
{
Conv2dGeneral
(
pad_input
,
Conv2dGeneral
(
pad_input
,
filter_data
,
filter_data
,
batch
,
extra_input_shape
,
extra_input_height
,
extra_output_shape
,
extra_input_width
,
filter_shape
.
data
(),
input_channels
,
strides_
,
extra_output_height
,
dilations_
,
extra_output_width
,
channels
,
filter_h
,
filter_w
,
stride_h
,
stride_w
,
dilation_h
,
dilation_w
,
pad_output
);
pad_output
);
};
};
}
}
...
@@ -639,7 +601,6 @@ struct Conv2dFunctor<DeviceType::CPU, float> : Conv2dFunctorBase {
...
@@ -639,7 +601,6 @@ struct Conv2dFunctor<DeviceType::CPU, float> : Conv2dFunctorBase {
const
Tensor
*
pad_input_ptr
=
input
;
const
Tensor
*
pad_input_ptr
=
input
;
if
(
extra_input_height
!=
input_height
if
(
extra_input_height
!=
input_height
||
extra_input_width
!=
input_width
)
{
||
extra_input_width
!=
input_width
)
{
padded_input
.
Clear
();
ConstructNCHWInputWithSpecificPadding
(
input
,
ConstructNCHWInputWithSpecificPadding
(
input
,
pad_top
,
pad_top
,
pad_bottom
,
pad_bottom
,
...
@@ -649,13 +610,17 @@ struct Conv2dFunctor<DeviceType::CPU, float> : Conv2dFunctorBase {
...
@@ -649,13 +610,17 @@ struct Conv2dFunctor<DeviceType::CPU, float> : Conv2dFunctorBase {
pad_input_ptr
=
&
padded_input
;
pad_input_ptr
=
&
padded_input
;
}
}
// TODO(libin): don't need clear after bias is integrated in each conv
Tensor
*
pad_output_ptr
=
output
;
Tensor
*
pad_output_ptr
=
output
;
if
(
extra_output_height
!=
height
||
extra_output_width
!=
width
)
{
if
(
extra_output_height
!=
height
||
extra_output_width
!=
width
)
{
padded_output
.
Reshape
({
batch
,
channels
,
extra_output_height
,
padded_output
.
Reshape
({
batch
,
channels
,
extra_output_height
,
extra_output_width
});
extra_output_width
});
padded_output
.
Clear
();
padded_output
.
Clear
();
pad_output_ptr
=
&
padded_output
;
pad_output_ptr
=
&
padded_output
;
}
else
if
(
!
use_neon_1x1_s1
)
{
output
->
Clear
();
}
}
const
float
*
pad_input_data
=
pad_input_ptr
->
data
<
float
>
();
const
float
*
pad_input_data
=
pad_input_ptr
->
data
<
float
>
();
float
*
pad_output_data
=
pad_output_ptr
->
mutable_data
<
float
>
();
float
*
pad_output_data
=
pad_output_ptr
->
mutable_data
<
float
>
();
...
...
mace/kernels/conv_pool_2d_util.cc
浏览文件 @
bdaa5c18
...
@@ -377,6 +377,7 @@ void ConstructNCHWInputWithSpecificPadding(const Tensor *input_tensor,
...
@@ -377,6 +377,7 @@ void ConstructNCHWInputWithSpecificPadding(const Tensor *input_tensor,
std
::
vector
<
index_t
>
output_shape
(
std
::
vector
<
index_t
>
output_shape
(
{
batch
,
channels
,
height
+
pad_height
,
width
+
pad_width
});
{
batch
,
channels
,
height
+
pad_height
,
width
+
pad_width
});
output_tensor
->
Resize
(
output_shape
);
output_tensor
->
Resize
(
output_shape
);
output_tensor
->
Clear
();
Tensor
::
MappingGuard
padded_output_mapper
(
output_tensor
);
Tensor
::
MappingGuard
padded_output_mapper
(
output_tensor
);
float
*
output_data
=
output_tensor
->
mutable_data
<
float
>
();
float
*
output_data
=
output_tensor
->
mutable_data
<
float
>
();
...
...
mace/kernels/deconv_2d.h
浏览文件 @
bdaa5c18
...
@@ -41,48 +41,40 @@ template<typename T>
...
@@ -41,48 +41,40 @@ template<typename T>
void
Deconv2dNCHW
(
const
T
*
input
,
void
Deconv2dNCHW
(
const
T
*
input
,
const
T
*
filter
,
const
T
*
filter
,
const
T
*
bias
,
const
T
*
bias
,
const
index_t
batch
,
const
index_t
*
in_shape
,
const
index_t
in_height
,
const
index_t
*
out_shape
,
const
index_t
in_width
,
const
index_t
*
kernel_hw
,
const
index_t
in_channels
,
const
int
*
strides
,
const
index_t
out_height
,
const
int
*
padding
,
const
index_t
out_width
,
const
index_t
out_channels
,
const
index_t
filter_height
,
const
index_t
filter_width
,
const
index_t
stride_h
,
const
index_t
stride_w
,
const
int
padding_top
,
const
int
padding_left
,
float
*
output
)
{
float
*
output
)
{
#pragma omp parallel for collapse(4)
#pragma omp parallel for collapse(4)
for
(
index_t
b
=
0
;
b
<
batch
;
++
b
)
{
for
(
index_t
b
=
0
;
b
<
out_shape
[
0
]
;
++
b
)
{
for
(
index_t
oc
=
0
;
oc
<
out_
channels
;
++
oc
)
{
for
(
index_t
oc
=
0
;
oc
<
out_
shape
[
1
]
;
++
oc
)
{
for
(
index_t
oh
=
0
;
oh
<
out_
height
;
++
oh
)
{
for
(
index_t
oh
=
0
;
oh
<
out_
shape
[
2
]
;
++
oh
)
{
for
(
index_t
ow
=
0
;
ow
<
out_
width
;
++
ow
)
{
for
(
index_t
ow
=
0
;
ow
<
out_
shape
[
3
]
;
++
ow
)
{
index_t
filter_start_y
,
filter_start_x
;
index_t
filter_start_y
,
filter_start_x
;
index_t
start_x
=
std
::
max
<
int
>
(
0
,
ow
+
stride
_w
-
1
-
padding_left
);
index_t
start_x
=
std
::
max
<
int
>
(
0
,
ow
+
stride
s
[
1
]
-
1
-
padding
[
1
]
);
index_t
start_y
=
std
::
max
<
int
>
(
0
,
oh
+
stride
_h
-
1
-
padding_top
);
index_t
start_y
=
std
::
max
<
int
>
(
0
,
oh
+
stride
s
[
0
]
-
1
-
padding
[
0
]
);
start_x
/=
stride
_w
;
start_x
/=
stride
s
[
1
]
;
start_y
/=
stride
_h
;
start_y
/=
stride
s
[
0
]
;
filter_start_x
=
padding
_left
+
stride_w
*
start_x
-
ow
;
filter_start_x
=
padding
[
1
]
+
strides
[
1
]
*
start_x
-
ow
;
filter_start_y
=
padding
_top
+
stride_h
*
start_y
-
oh
;
filter_start_y
=
padding
[
0
]
+
strides
[
0
]
*
start_y
-
oh
;
filter_start_x
=
filter_width
-
1
-
filter_start_x
;
filter_start_x
=
kernel_hw
[
1
]
-
1
-
filter_start_x
;
filter_start_y
=
filter_height
-
1
-
filter_start_y
;
filter_start_y
=
kernel_hw
[
0
]
-
1
-
filter_start_y
;
T
out_value
=
0
;
T
out_value
=
0
;
index_t
out_pos
=
index_t
out_pos
=
((
b
*
out_
channels
+
oc
)
*
out_height
+
oh
)
*
out_width
+
ow
;
((
b
*
out_
shape
[
1
]
+
oc
)
*
out_shape
[
2
]
+
oh
)
*
out_shape
[
3
]
+
ow
;
for
(
index_t
ic
=
0
;
ic
<
in_
channels
;
++
ic
)
{
for
(
index_t
ic
=
0
;
ic
<
in_
shape
[
1
]
;
++
ic
)
{
for
(
index_t
f_y
=
filter_start_y
,
ih
=
start_y
;
for
(
index_t
f_y
=
filter_start_y
,
ih
=
start_y
;
f_y
>=
0
&&
ih
<
in_
height
;
f_y
-=
stride_h
,
++
ih
)
{
f_y
>=
0
&&
ih
<
in_
shape
[
2
];
f_y
-=
strides
[
0
]
,
++
ih
)
{
for
(
index_t
f_x
=
filter_start_x
,
iw
=
start_x
;
for
(
index_t
f_x
=
filter_start_x
,
iw
=
start_x
;
f_x
>=
0
&&
iw
<
in_
width
;
f_x
-=
stride_w
,
++
iw
)
{
f_x
>=
0
&&
iw
<
in_
shape
[
3
];
f_x
-=
strides
[
1
]
,
++
iw
)
{
index_t
weight_pos
=
index_t
weight_pos
=
((
oc
*
in_
channels
+
ic
)
*
filter_height
+
f_y
)
((
oc
*
in_
shape
[
1
]
+
ic
)
*
kernel_hw
[
0
]
+
f_y
)
*
filter_width
+
f_x
;
*
kernel_hw
[
1
]
+
f_x
;
index_t
in_pos
=
index_t
in_pos
=
((
b
*
in_
channels
+
ic
)
*
in_height
+
ih
)
((
b
*
in_
shape
[
1
]
+
ic
)
*
in_shape
[
2
]
+
ih
)
*
in_
width
+
iw
;
*
in_
shape
[
3
]
+
iw
;
out_value
+=
input
[
in_pos
]
*
filter
[
weight_pos
];
out_value
+=
input
[
in_pos
]
*
filter
[
weight_pos
];
}
}
}
}
...
@@ -269,26 +261,17 @@ struct Deconv2dFunctor : Deconv2dFunctorBase {
...
@@ -269,26 +261,17 @@ struct Deconv2dFunctor : Deconv2dFunctorBase {
paddings_
.
data
(),
true
);
paddings_
.
data
(),
true
);
output
->
Resize
(
output_shape_
);
output
->
Resize
(
output_shape_
);
}
}
index_t
batch
=
output
->
dim
(
0
);
index_t
channels
=
output
->
dim
(
1
);
index_t
height
=
output
->
dim
(
2
);
index_t
width
=
output
->
dim
(
3
);
index_t
input_batch
=
input
->
dim
(
0
);
index_t
input_channels
=
input
->
dim
(
1
);
index_t
input_height
=
input
->
dim
(
2
);
index_t
input_width
=
input
->
dim
(
3
);
index_t
kernel_h
=
filter
->
dim
(
2
);
index_t
kernel_h
=
filter
->
dim
(
2
);
index_t
kernel_w
=
filter
->
dim
(
3
);
index_t
kernel_w
=
filter
->
dim
(
3
);
MACE_CHECK
(
filter
->
dim
(
0
)
==
channels
,
filter
->
dim
(
0
),
" != "
,
channels
);
const
index_t
*
in_shape
=
input
->
shape
().
data
();
MACE_CHECK
(
filter
->
dim
(
1
)
==
input_channels
,
filter
->
dim
(
1
),
" != "
,
const
index_t
*
out_shape
=
output
->
shape
().
data
();
input_channels
);
const
index_t
kernel_hw
[
2
]
=
{
kernel_h
,
kernel_w
};
index_t
stride_h
=
strides_
[
0
];
MACE_CHECK
(
filter
->
dim
(
0
)
==
out_shape
[
1
],
filter
->
dim
(
0
),
" != "
,
index_t
stride_w
=
strides_
[
1
];
output_shape
[
1
]);
MACE_CHECK
(
filter
->
dim
(
1
)
==
in_shape
[
1
],
filter
->
dim
(
1
),
" != "
,
MACE_CHECK
(
batch
==
input_batch
,
"Input/Output batch size mismatch"
);
in_shape
[
1
]);
MACE_CHECK
(
in_shape
[
0
]
==
out_shape
[
0
],
"Input/Output batch size mismatch"
);
Tensor
::
MappingGuard
input_mapper
(
input
);
Tensor
::
MappingGuard
input_mapper
(
input
);
Tensor
::
MappingGuard
filter_mapper
(
filter
);
Tensor
::
MappingGuard
filter_mapper
(
filter
);
Tensor
::
MappingGuard
bias_mapper
(
bias
);
Tensor
::
MappingGuard
bias_mapper
(
bias
);
...
@@ -297,17 +280,23 @@ struct Deconv2dFunctor : Deconv2dFunctorBase {
...
@@ -297,17 +280,23 @@ struct Deconv2dFunctor : Deconv2dFunctorBase {
auto
filter_data
=
filter
->
data
<
T
>
();
auto
filter_data
=
filter
->
data
<
T
>
();
auto
bias_data
=
bias
==
nullptr
?
nullptr
:
bias
->
data
<
T
>
();
auto
bias_data
=
bias
==
nullptr
?
nullptr
:
bias
->
data
<
T
>
();
auto
output_data
=
output
->
mutable_data
<
T
>
();
auto
output_data
=
output
->
mutable_data
<
T
>
();
int
padding_top
=
(
paddings_
[
0
]
+
1
)
>>
1
;
int
padding
[
2
];
int
padding_left
=
(
paddings_
[
1
]
+
1
)
>>
1
;
padding
[
0
]
=
(
paddings_
[
0
]
+
1
)
>>
1
;
padding
[
1
]
=
(
paddings_
[
1
]
+
1
)
>>
1
;
deconv
::
Deconv2dNCHW
(
input_data
,
filter_data
,
bias_data
,
deconv
::
Deconv2dNCHW
(
input_data
,
batch
,
input_height
,
input_width
,
input_channels
,
filter_data
,
height
,
width
,
channels
,
bias_data
,
kernel_h
,
kernel_w
,
in_shape
,
stride_h
,
stride_w
,
padding_top
,
padding_left
,
out_shape
,
kernel_hw
,
strides_
,
padding
,
output_data
);
output_data
);
DoActivation
(
output_data
,
output_data
,
output
->
size
(),
activation_
,
DoActivation
(
output_data
,
output_data
,
output
->
size
(),
activation_
,
relux_max_limit_
);
relux_max_limit_
);
}
}
};
};
...
...
mace/kernels/depth_to_space.h
浏览文件 @
bdaa5c18
...
@@ -34,10 +34,10 @@ struct DepthToSpaceOpFunctor {
...
@@ -34,10 +34,10 @@ struct DepthToSpaceOpFunctor {
:
block_size_
(
block_size
),
d2s_
(
d2s
)
{}
:
block_size_
(
block_size
),
d2s_
(
d2s
)
{}
void
operator
()(
const
Tensor
*
input
,
Tensor
*
output
,
StatsFuture
*
future
)
{
void
operator
()(
const
Tensor
*
input
,
Tensor
*
output
,
StatsFuture
*
future
)
{
MACE_UNUSED
(
future
);
MACE_UNUSED
(
future
);
const
int
batch_size
=
input
->
dim
(
0
);
const
in
dex_
t
batch_size
=
input
->
dim
(
0
);
const
int
input_depth
=
input
->
dim
(
1
);
const
in
dex_
t
input_depth
=
input
->
dim
(
1
);
const
int
input_height
=
input
->
dim
(
2
);
const
in
dex_
t
input_height
=
input
->
dim
(
2
);
const
int
input_width
=
input
->
dim
(
3
);
const
in
dex_
t
input_width
=
input
->
dim
(
3
);
index_t
output_depth
,
output_width
,
output_height
;
index_t
output_depth
,
output_width
,
output_height
;
...
@@ -62,11 +62,11 @@ struct DepthToSpaceOpFunctor {
...
@@ -62,11 +62,11 @@ struct DepthToSpaceOpFunctor {
if
(
d2s_
)
{
if
(
d2s_
)
{
#pragma omp parallel for
#pragma omp parallel for
for
(
int
b
=
0
;
b
<
batch_size
;
++
b
)
{
for
(
in
dex_
t
b
=
0
;
b
<
batch_size
;
++
b
)
{
for
(
int
d
=
0
;
d
<
output_depth
;
++
d
)
{
for
(
in
dex_
t
d
=
0
;
d
<
output_depth
;
++
d
)
{
for
(
int
h
=
0
;
h
<
output_height
;
++
h
)
{
for
(
in
dex_
t
h
=
0
;
h
<
output_height
;
++
h
)
{
const
int
in_h
=
h
/
block_size_
;
const
in
dex_
t
in_h
=
h
/
block_size_
;
const
int
offset_h
=
(
h
%
block_size_
);
const
in
dex_
t
offset_h
=
(
h
%
block_size_
);
for
(
int
w
=
0
;
w
<
output_width
;
++
w
)
{
for
(
int
w
=
0
;
w
<
output_width
;
++
w
)
{
const
index_t
in_w
=
w
/
block_size_
;
const
index_t
in_w
=
w
/
block_size_
;
const
index_t
offset_w
=
w
%
block_size_
;
const
index_t
offset_w
=
w
%
block_size_
;
...
@@ -86,18 +86,18 @@ struct DepthToSpaceOpFunctor {
...
@@ -86,18 +86,18 @@ struct DepthToSpaceOpFunctor {
}
}
}
else
{
}
else
{
#pragma omp parallel for
#pragma omp parallel for
for
(
int
b
=
0
;
b
<
batch_size
;
++
b
)
{
for
(
in
dex_
t
b
=
0
;
b
<
batch_size
;
++
b
)
{
for
(
int
d
=
0
;
d
<
input_depth
;
++
d
)
{
for
(
in
dex_
t
d
=
0
;
d
<
input_depth
;
++
d
)
{
for
(
int
h
=
0
;
h
<
input_height
;
++
h
)
{
for
(
in
dex_
t
h
=
0
;
h
<
input_height
;
++
h
)
{
const
int
out_h
=
h
/
block_size_
;
const
in
dex_
t
out_h
=
h
/
block_size_
;
const
int
offset_h
=
(
h
%
block_size_
);
const
in
dex_
t
offset_h
=
(
h
%
block_size_
);
for
(
int
w
=
0
;
w
<
input_width
;
++
w
)
{
for
(
in
dex_
t
w
=
0
;
w
<
input_width
;
++
w
)
{
const
int
out_w
=
w
/
block_size_
;
const
in
dex_
t
out_w
=
w
/
block_size_
;
const
int
offset_w
=
(
w
%
block_size_
);
const
in
dex_
t
offset_w
=
(
w
%
block_size_
);
const
int
offset_d
=
const
in
dex_
t
offset_d
=
(
offset_h
*
block_size_
+
offset_w
)
*
input_depth
;
(
offset_h
*
block_size_
+
offset_w
)
*
input_depth
;
const
int
out_d
=
d
+
offset_d
;
const
in
dex_
t
out_d
=
d
+
offset_d
;
const
index_t
o_index
=
const
index_t
o_index
=
((
b
*
output_depth
+
out_d
)
*
output_height
+
out_h
)
((
b
*
output_depth
+
out_d
)
*
output_height
+
out_h
)
*
output_width
+
out_w
;
*
output_width
+
out_w
;
...
...
mace/kernels/depthwise_conv2d.h
浏览文件 @
bdaa5c18
...
@@ -78,28 +78,27 @@ struct DepthwiseConv2dFunctor<DeviceType::CPU, float>
...
@@ -78,28 +78,27 @@ struct DepthwiseConv2dFunctor<DeviceType::CPU, float>
void
DepthwiseConv2dGeneral
(
const
float
*
input
,
void
DepthwiseConv2dGeneral
(
const
float
*
input
,
const
float
*
filter
,
const
float
*
filter
,
const
index_t
batch
,
const
index_t
*
in_shape
,
const
index_t
in_height
,
const
index_t
*
out_shape
,
const
index_t
in_width
,
const
index_t
*
filter_shape
,
const
index_t
in_channels
,
const
int
*
stride_hw
,
const
index_t
out_height
,
const
int
*
dilation_hw
,
const
index_t
out_width
,
const
int
*
pad_hw
,
const
index_t
out_channels
,
const
int
filter_height
,
const
int
filter_width
,
const
int
stride_h
,
const
int
stride_w
,
const
int
dilation_h
,
const
int
dilation_w
,
const
int
pad_top
,
const
int
pad_left
,
float
*
output
)
{
float
*
output
)
{
const
index_t
multiplier
=
out_channels
/
in_channels
;
const
index_t
multiplier
=
filter_shape
[
0
]
/
filter_shape
[
1
]
;
#pragma omp parallel for collapse(2)
#pragma omp parallel for collapse(2)
for
(
index_t
b
=
0
;
b
<
batch
;
++
b
)
{
for
(
index_t
b
=
0
;
b
<
in_shape
[
0
];
++
b
)
{
for
(
index_t
m
=
0
;
m
<
out_channels
;
++
m
)
{
for
(
index_t
m
=
0
;
m
<
filter_shape
[
0
];
++
m
)
{
for
(
index_t
h
=
0
;
h
<
out_height
;
++
h
)
{
for
(
index_t
h
=
0
;
h
<
out_shape
[
2
];
++
h
)
{
for
(
index_t
w
=
0
;
w
<
out_width
;
++
w
)
{
for
(
index_t
w
=
0
;
w
<
out_shape
[
3
];
++
w
)
{
const
index_t
out_channels
=
filter_shape
[
0
];
const
index_t
in_channels
=
filter_shape
[
1
];
const
index_t
filter_height
=
filter_shape
[
2
];
const
index_t
filter_width
=
filter_shape
[
3
];
const
index_t
in_height
=
in_shape
[
2
];
const
index_t
in_width
=
in_shape
[
3
];
const
index_t
out_height
=
out_shape
[
2
];
const
index_t
out_width
=
out_shape
[
3
];
index_t
out_offset
=
index_t
out_offset
=
((
b
*
out_channels
+
m
)
*
out_height
+
h
)
*
out_width
+
w
;
((
b
*
out_channels
+
m
)
*
out_height
+
h
)
*
out_width
+
w
;
index_t
c
=
m
/
multiplier
;
index_t
c
=
m
/
multiplier
;
...
@@ -107,8 +106,8 @@ struct DepthwiseConv2dFunctor<DeviceType::CPU, float>
...
@@ -107,8 +106,8 @@ struct DepthwiseConv2dFunctor<DeviceType::CPU, float>
float
sum
=
0
;
float
sum
=
0
;
for
(
index_t
kh
=
0
;
kh
<
filter_height
;
++
kh
)
{
for
(
index_t
kh
=
0
;
kh
<
filter_height
;
++
kh
)
{
for
(
index_t
kw
=
0
;
kw
<
filter_width
;
++
kw
)
{
for
(
index_t
kw
=
0
;
kw
<
filter_width
;
++
kw
)
{
index_t
ih
=
h
*
stride_h
+
kh
*
dilation_h
-
pad_top
;
index_t
ih
=
h
*
stride_h
w
[
0
]
+
kh
*
dilation_hw
[
0
]
-
pad_hw
[
0
]
;
index_t
iw
=
w
*
stride_
w
+
kw
*
dilation_w
-
pad_left
;
index_t
iw
=
w
*
stride_
hw
[
1
]
+
kw
*
dilation_hw
[
1
]
-
pad_hw
[
1
]
;
if
(
ih
>=
0
&&
ih
<
in_height
&&
iw
>=
0
&&
iw
<
in_width
)
{
if
(
ih
>=
0
&&
ih
<
in_height
&&
iw
>=
0
&&
iw
<
in_width
)
{
index_t
in_offset
=
index_t
in_offset
=
((
b
*
in_channels
+
c
)
*
in_height
+
ih
)
*
in_width
+
iw
;
((
b
*
in_channels
+
c
)
*
in_height
+
ih
)
*
in_width
+
iw
;
...
@@ -214,20 +213,18 @@ struct DepthwiseConv2dFunctor<DeviceType::CPU, float>
...
@@ -214,20 +213,18 @@ struct DepthwiseConv2dFunctor<DeviceType::CPU, float>
auto
bias_data
=
bias
==
nullptr
?
nullptr
:
bias
->
data
<
float
>
();
auto
bias_data
=
bias
==
nullptr
?
nullptr
:
bias
->
data
<
float
>
();
auto
output_data
=
output
->
mutable_data
<
float
>
();
auto
output_data
=
output
->
mutable_data
<
float
>
();
const
int
pad_hw
[
2
]
=
{
pad_top
,
pad_left
};
const
index_t
input_shape
[
4
]
=
{
batch
,
input_channels
,
input_height
,
input_width
};
if
(
filter_h
==
3
&&
filter_w
==
3
&&
stride_h
==
1
&&
stride_w
==
1
if
(
filter_h
==
3
&&
filter_w
==
3
&&
stride_h
==
1
&&
stride_w
==
1
&&
dilation_h
==
1
&&
dilation_w
==
1
)
{
&&
dilation_h
==
1
&&
dilation_w
==
1
)
{
conv_func
=
[
=
](
const
float
*
input
,
float
*
output
)
{
conv_func
=
[
=
](
const
float
*
input
,
float
*
output
)
{
DepthwiseConv2dNeonK3x3S1
(
input
,
DepthwiseConv2dNeonK3x3S1
(
input
,
filter_data
,
filter_data
,
batch
,
input_shape
,
input_height
,
output_shape
.
data
(),
input_width
,
pad_hw
,
input_channels
,
height
,
width
,
channels
,
pad_top
,
pad_left
,
valid_h_start
,
valid_h_start
,
valid_h_stop
,
valid_h_stop
,
valid_w_start
,
valid_w_start
,
...
@@ -239,15 +236,9 @@ struct DepthwiseConv2dFunctor<DeviceType::CPU, float>
...
@@ -239,15 +236,9 @@ struct DepthwiseConv2dFunctor<DeviceType::CPU, float>
conv_func
=
[
=
](
const
float
*
input
,
float
*
output
)
{
conv_func
=
[
=
](
const
float
*
input
,
float
*
output
)
{
DepthwiseConv2dNeonK3x3S2
(
input
,
DepthwiseConv2dNeonK3x3S2
(
input
,
filter_data
,
filter_data
,
batch
,
input_shape
,
input_height
,
output_shape
.
data
(),
input_width
,
pad_hw
,
input_channels
,
height
,
width
,
channels
,
pad_top
,
pad_left
,
valid_h_start
,
valid_h_start
,
valid_h_stop
,
valid_h_stop
,
valid_w_start
,
valid_w_start
,
...
@@ -258,21 +249,12 @@ struct DepthwiseConv2dFunctor<DeviceType::CPU, float>
...
@@ -258,21 +249,12 @@ struct DepthwiseConv2dFunctor<DeviceType::CPU, float>
conv_func
=
[
=
](
const
float
*
input
,
float
*
output
)
{
conv_func
=
[
=
](
const
float
*
input
,
float
*
output
)
{
DepthwiseConv2dGeneral
(
input
,
DepthwiseConv2dGeneral
(
input
,
filter_data
,
filter_data
,
batch
,
input_shape
,
input_height
,
output_shape
.
data
(),
input_width
,
filter_shape
.
data
(),
input_channels
,
strides_
,
height
,
dilations_
,
width
,
pad_hw
,
channels
,
filter_h
,
filter_w
,
stride_h
,
stride_w
,
dilation_h
,
dilation_w
,
pad_top
,
pad_left
,
output
);
output
);
};
};
}
}
...
...
mace/kernels/gemm.cc
浏览文件 @
bdaa5c18
...
@@ -140,8 +140,8 @@ inline void GemmTile(const float *A,
...
@@ -140,8 +140,8 @@ inline void GemmTile(const float *A,
#endif
#endif
#if defined(MACE_ENABLE_NEON) && defined(__aarch64__)
#if defined(MACE_ENABLE_NEON) && defined(__aarch64__)
for
(
h
=
0
;
h
+
7
<
height
;
h
+=
8
)
{
for
(
h
=
0
;
h
<
height
-
7
;
h
+=
8
)
{
for
(
k
=
0
;
k
+
7
<
K
;
k
+=
8
)
{
for
(
k
=
0
;
k
<
K
-
7
;
k
+=
8
)
{
const
float
*
a_ptr
=
A
+
(
h
*
stride_k
+
k
);
const
float
*
a_ptr
=
A
+
(
h
*
stride_k
+
k
);
#ifdef __clang__
#ifdef __clang__
int
nw
=
width
>>
2
;
int
nw
=
width
>>
2
;
...
@@ -185,156 +185,150 @@ inline void GemmTile(const float *A,
...
@@ -185,156 +185,150 @@ inline void GemmTile(const float *A,
float
*
c_ptr7
=
C
+
(
h
+
7
)
*
stride_w
;
float
*
c_ptr7
=
C
+
(
h
+
7
)
*
stride_w
;
asm
volatile
(
asm
volatile
(
"0:
\n
"
"prfm pldl1keep, [%9, #128]
\n
"
"ld1 {v16.4s}, [%9], #16
\n
"
"prfm pldl1keep, [%1, #128]
\n
"
"ld1 {v24.4s}, [%1]
\n
"
// load b: 0-7
"prfm pldl1keep, [%9, #128]
\n
"
"ld1 {v16.4s}, [%9], #16
\n
"
"prfm pldl1keep, [%10, #128]
\n
"
"ld1 {v17.4s}, [%10], #16
\n
"
"prfm pldl1keep, [%11, #128]
\n
"
"ld1 {v18.4s}, [%11], #16
\n
"
"prfm pldl1keep, [%12, #128]
\n
"
"ld1 {v19.4s}, [%12], #16
\n
"
"prfm pldl1keep, [%2, #128]
\n
"
"ld1 {v25.4s}, [%2]
\n
"
"prfm pldl1keep, [%13, #128]
\n
"
"ld1 {v20.4s}, [%13], #16
\n
"
"prfm pldl1keep, [%14, #128]
\n
"
"ld1 {v21.4s}, [%14], #16
\n
"
"prfm pldl1keep, [%15, #128]
\n
"
"ld1 {v22.4s}, [%15], #16
\n
"
"prfm pldl1keep, [%16, #128]
\n
"
"ld1 {v23.4s}, [%16], #16
\n
"
"prfm pldl1keep, [%3, #128]
\n
"
"ld1 {v26.4s}, [%3]
\n
"
"fmla v24.4s, v16.4s, %34.s[0]
\n
"
"fmla v24.4s, v17.4s, %34.s[1]
\n
"
"fmla v24.4s, v18.4s, %34.s[2]
\n
"
"fmla v24.4s, v19.4s, %34.s[3]
\n
"
"fmla v24.4s, v20.4s, %35.s[0]
\n
"
"fmla v24.4s, v21.4s, %35.s[1]
\n
"
"fmla v24.4s, v22.4s, %35.s[2]
\n
"
"fmla v24.4s, v23.4s, %35.s[3]
\n
"
"st1 {v24.4s}, [%1], #16
\n
"
"fmla v25.4s, v16.4s, %36.s[0]
\n
"
"fmla v25.4s, v17.4s, %36.s[1]
\n
"
"fmla v25.4s, v18.4s, %36.s[2]
\n
"
"fmla v25.4s, v19.4s, %36.s[3]
\n
"
"fmla v25.4s, v20.4s, %37.s[0]
\n
"
"fmla v25.4s, v21.4s, %37.s[1]
\n
"
"fmla v25.4s, v22.4s, %37.s[2]
\n
"
"fmla v25.4s, v23.4s, %37.s[3]
\n
"
"prfm pldl1keep, [%4, #128]
\n
"
"ld1 {v24.4s}, [%4]
\n
"
"st1 {v25.4s}, [%2], #16
\n
"
"fmla v26.4s, v16.4s, %38.s[0]
\n
"
"fmla v26.4s, v17.4s, %38.s[1]
\n
"
"fmla v26.4s, v18.4s, %38.s[2]
\n
"
"fmla v26.4s, v19.4s, %38.s[3]
\n
"
"fmla v26.4s, v20.4s, %39.s[0]
\n
"
"prfm pldl1keep, [%1, #128]
\n
"
"fmla v26.4s, v21.4s, %39.s[1]
\n
"
"ld1 {v18.4s}, [%1]
\n
"
"fmla v26.4s, v22.4s, %39.s[2]
\n
"
"fmla v26.4s, v23.4s, %39.s[3]
\n
"
"prfm pldl1keep, [%5
, #128]
\n
"
"prfm pldl1keep, [%2
, #128]
\n
"
"ld1 {v25.4s}, [%5
]
\n
"
"ld1 {v19.4s}, [%2
]
\n
"
"st1 {v26.4s}, [%3], #16
\n
"
"0:
\n
"
"fmla v24.4s, v16.4s, %40.s[0]
\n
"
"fmla v24.4s, v17.4s, %40.s[1]
\n
"
"fmla v24.4s, v18.4s, %40.s[2]
\n
"
"fmla v24.4s, v19.4s, %40.s[3]
\n
"
"fmla v24.4s, v20.4s, %41.s[0]
\n
"
"fmla v24.4s, v21.4s, %41.s[1]
\n
"
"fmla v24.4s, v22.4s, %41.s[2]
\n
"
"fmla v24.4s, v23.4s, %41.s[3]
\n
"
"prfm pldl1keep, [%6, #128]
\n
"
"ld1 {v26.4s}, [%6]
\n
"
"st1 {v24.4s}, [%4], #16
\n
"
"fmla v25.4s, v16.4s, %42.s[0]
\n
"
"fmla v25.4s, v17.4s, %42.s[1]
\n
"
"fmla v25.4s, v18.4s, %42.s[2]
\n
"
"fmla v25.4s, v19.4s, %42.s[3]
\n
"
"fmla v25.4s, v20.4s, %43.s[0]
\n
"
"fmla v25.4s, v21.4s, %43.s[1]
\n
"
"fmla v25.4s, v22.4s, %43.s[2]
\n
"
"fmla v25.4s, v23.4s, %43.s[3]
\n
"
"prfm pldl1keep, [%7, #128]
\n
"
"ld1 {v24.4s}, [%7]
\n
"
"st1 {v25.4s}, [%5], #16
\n
"
"fmla v26.4s, v16.4s, %44.s[0]
\n
"
"fmla v26.4s, v17.4s, %44.s[1]
\n
"
"fmla v26.4s, v18.4s, %44.s[2]
\n
"
"fmla v26.4s, v19.4s, %44.s[3]
\n
"
"fmla v26.4s, v20.4s, %45.s[0]
\n
"
"fmla v26.4s, v21.4s, %45.s[1]
\n
"
"fmla v26.4s, v22.4s, %45.s[2]
\n
"
"fmla v26.4s, v23.4s, %45.s[3]
\n
"
"prfm pldl1keep, [%8, #128]
\n
"
"ld1 {v25.4s}, [%8]
\n
"
"st1 {v26.4s}, [%6], #16
\n
"
"fmla v24.4s, v16.4s, %46.s[0]
\n
"
"fmla v24.4s, v17.4s, %46.s[1]
\n
"
"fmla v24.4s, v18.4s, %46.s[2]
\n
"
"fmla v24.4s, v19.4s, %46.s[3]
\n
"
"fmla v24.4s, v20.4s, %47.s[0]
\n
"
"fmla v24.4s, v21.4s, %47.s[1]
\n
"
"fmla v24.4s, v22.4s, %47.s[2]
\n
"
"fmla v24.4s, v23.4s, %47.s[3]
\n
"
"st1 {v24.4s}, [%7], #16
\n
"
"fmla v25.4s, v16.4s, %48.s[0]
\n
"
"fmla v25.4s, v17.4s, %48.s[1]
\n
"
"fmla v25.4s, v18.4s, %48.s[2]
\n
"
"fmla v25.4s, v19.4s, %48.s[3]
\n
"
"fmla v25.4s, v20.4s, %49.s[0]
\n
"
"fmla v25.4s, v21.4s, %49.s[1]
\n
"
"fmla v25.4s, v22.4s, %49.s[2]
\n
"
"fmla v25.4s, v23.4s, %49.s[3]
\n
"
"st1 {v25.4s}, [%8], #16
\n
"
"subs %w0, %w0, #1
\n
"
"prfm pldl1keep, [%3, #128]
\n
"
"bne 0b
\n
"
"ld1 {v20.4s}, [%3]
\n
"
:
"=r"
(
nw
),
// 0
"prfm pldl1keep, [%4, #128]
\n
"
"ld1 {v21.4s}, [%4]
\n
"
"prfm pldl1keep, [%5, #128]
\n
"
"ld1 {v22.4s}, [%5]
\n
"
"prfm pldl1keep, [%6, #128]
\n
"
"ld1 {v23.4s}, [%6]
\n
"
"prfm pldl1keep, [%7, #128]
\n
"
"ld1 {v24.4s}, [%7]
\n
"
"prfm pldl1keep, [%8, #128]
\n
"
"ld1 {v25.4s}, [%8]
\n
"
"prfm pldl1keep, [%10, #128]
\n
"
"ld1 {v17.4s}, [%10], #16
\n
"
"fmla v18.4s, v16.4s, %34.s[0]
\n
"
"fmla v19.4s, v16.4s, %35.s[0]
\n
"
"fmla v20.4s, v16.4s, %36.s[0]
\n
"
"fmla v21.4s, v16.4s, %37.s[0]
\n
"
"fmla v22.4s, v16.4s, %38.s[0]
\n
"
"fmla v23.4s, v16.4s, %39.s[0]
\n
"
"fmla v24.4s, v16.4s, %40.s[0]
\n
"
"fmla v25.4s, v16.4s, %41.s[0]
\n
"
"fmla v18.4s, v17.4s, %34.s[1]
\n
"
"fmla v19.4s, v17.4s, %35.s[1]
\n
"
"fmla v20.4s, v17.4s, %36.s[1]
\n
"
"fmla v21.4s, v17.4s, %37.s[1]
\n
"
"prfm pldl1keep, [%11, #128]
\n
"
"ld1 {v16.4s}, [%11], #16
\n
"
"fmla v22.4s, v17.4s, %38.s[1]
\n
"
"fmla v23.4s, v17.4s, %39.s[1]
\n
"
"fmla v24.4s, v17.4s, %40.s[1]
\n
"
"fmla v25.4s, v17.4s, %41.s[1]
\n
"
"fmla v18.4s, v16.4s, %34.s[2]
\n
"
"fmla v19.4s, v16.4s, %35.s[2]
\n
"
"fmla v20.4s, v16.4s, %36.s[2]
\n
"
"fmla v21.4s, v16.4s, %37.s[2]
\n
"
"prfm pldl1keep, [%12, #128]
\n
"
"ld1 {v17.4s}, [%12], #16
\n
"
"fmla v22.4s, v16.4s, %38.s[2]
\n
"
"fmla v23.4s, v16.4s, %39.s[2]
\n
"
"fmla v24.4s, v16.4s, %40.s[2]
\n
"
"fmla v25.4s, v16.4s, %41.s[2]
\n
"
"fmla v18.4s, v17.4s, %34.s[3]
\n
"
"fmla v19.4s, v17.4s, %35.s[3]
\n
"
"fmla v20.4s, v17.4s, %36.s[3]
\n
"
"fmla v21.4s, v17.4s, %37.s[3]
\n
"
"prfm pldl1keep, [%13, #128]
\n
"
"ld1 {v16.4s}, [%13], #16
\n
"
"fmla v22.4s, v17.4s, %38.s[3]
\n
"
"fmla v23.4s, v17.4s, %39.s[3]
\n
"
"fmla v24.4s, v17.4s, %40.s[3]
\n
"
"fmla v25.4s, v17.4s, %41.s[3]
\n
"
"fmla v18.4s, v16.4s, %42.s[0]
\n
"
"fmla v19.4s, v16.4s, %43.s[0]
\n
"
"fmla v20.4s, v16.4s, %44.s[0]
\n
"
"fmla v21.4s, v16.4s, %45.s[0]
\n
"
"prfm pldl1keep, [%14, #128]
\n
"
"ld1 {v17.4s}, [%14], #16
\n
"
"fmla v22.4s, v16.4s, %46.s[0]
\n
"
"fmla v23.4s, v16.4s, %47.s[0]
\n
"
"fmla v24.4s, v16.4s, %48.s[0]
\n
"
"fmla v25.4s, v16.4s, %49.s[0]
\n
"
"fmla v18.4s, v17.4s, %42.s[1]
\n
"
"fmla v19.4s, v17.4s, %43.s[1]
\n
"
"fmla v20.4s, v17.4s, %44.s[1]
\n
"
"fmla v21.4s, v17.4s, %45.s[1]
\n
"
"prfm pldl1keep, [%15, #128]
\n
"
"ld1 {v16.4s}, [%15], #16
\n
"
"fmla v22.4s, v17.4s, %46.s[1]
\n
"
"fmla v23.4s, v17.4s, %47.s[1]
\n
"
"fmla v24.4s, v17.4s, %48.s[1]
\n
"
"fmla v25.4s, v17.4s, %49.s[1]
\n
"
"fmla v18.4s, v16.4s, %42.s[2]
\n
"
"fmla v19.4s, v16.4s, %43.s[2]
\n
"
"fmla v20.4s, v16.4s, %44.s[2]
\n
"
"fmla v21.4s, v16.4s, %45.s[2]
\n
"
"prfm pldl1keep, [%16, #128]
\n
"
"ld1 {v17.4s}, [%16], #16
\n
"
"fmla v22.4s, v16.4s, %46.s[2]
\n
"
"fmla v23.4s, v16.4s, %47.s[2]
\n
"
"fmla v24.4s, v16.4s, %48.s[2]
\n
"
"fmla v25.4s, v16.4s, %49.s[2]
\n
"
"fmla v18.4s, v17.4s, %42.s[3]
\n
"
"fmla v19.4s, v17.4s, %43.s[3]
\n
"
"fmla v20.4s, v17.4s, %44.s[3]
\n
"
"fmla v21.4s, v17.4s, %45.s[3]
\n
"
"st1 {v18.4s}, [%1], #16
\n
"
"st1 {v19.4s}, [%2], #16
\n
"
"st1 {v20.4s}, [%3], #16
\n
"
"st1 {v21.4s}, [%4], #16
\n
"
"fmla v22.4s, v17.4s, %46.s[3]
\n
"
"fmla v23.4s, v17.4s, %47.s[3]
\n
"
"fmla v24.4s, v17.4s, %48.s[3]
\n
"
"fmla v25.4s, v17.4s, %49.s[3]
\n
"
"st1 {v22.4s}, [%5], #16
\n
"
"st1 {v23.4s}, [%6], #16
\n
"
"st1 {v24.4s}, [%7], #16
\n
"
"st1 {v25.4s}, [%8], #16
\n
"
"prfm pldl1keep, [%9, #128]
\n
"
"ld1 {v16.4s}, [%9], #16
\n
"
"prfm pldl1keep, [%1, #128]
\n
"
"ld1 {v18.4s}, [%1]
\n
"
"prfm pldl1keep, [%2, #128]
\n
"
"ld1 {v19.4s}, [%2]
\n
"
"subs %w0, %w0, #1
\n
"
"bne 0b
\n
"
:
"=r"
(
nw
),
// 0
"=r"
(
c_ptr0
),
// 1
"=r"
(
c_ptr0
),
// 1
"=r"
(
c_ptr1
),
// 2
"=r"
(
c_ptr1
),
// 2
"=r"
(
c_ptr2
),
// 3
"=r"
(
c_ptr2
),
// 3
...
@@ -351,7 +345,7 @@ inline void GemmTile(const float *A,
...
@@ -351,7 +345,7 @@ inline void GemmTile(const float *A,
"=r"
(
b_ptr5
),
// 14
"=r"
(
b_ptr5
),
// 14
"=r"
(
b_ptr6
),
// 15
"=r"
(
b_ptr6
),
// 15
"=r"
(
b_ptr7
)
// 16
"=r"
(
b_ptr7
)
// 16
:
"0"
(
nw
),
// 17
:
"0"
(
nw
),
// 17
"1"
(
c_ptr0
),
// 18
"1"
(
c_ptr0
),
// 18
"2"
(
c_ptr1
),
// 19
"2"
(
c_ptr1
),
// 19
"3"
(
c_ptr2
),
// 20
"3"
(
c_ptr2
),
// 20
...
@@ -369,20 +363,20 @@ inline void GemmTile(const float *A,
...
@@ -369,20 +363,20 @@ inline void GemmTile(const float *A,
"15"
(
b_ptr6
),
// 32
"15"
(
b_ptr6
),
// 32
"16"
(
b_ptr7
),
// 33
"16"
(
b_ptr7
),
// 33
"w"
(
a0
),
// 34
"w"
(
a0
),
// 34
"w"
(
a
1
),
// 35
"w"
(
a
2
),
// 35
"w"
(
a
2
),
// 36
"w"
(
a
4
),
// 36
"w"
(
a
3
),
// 37
"w"
(
a
6
),
// 37
"w"
(
a
4
),
// 38
"w"
(
a
8
),
// 38
"w"
(
a
5
),
// 39
"w"
(
a
10
),
// 39
"w"
(
a
6
),
// 40
"w"
(
a
12
),
// 40
"w"
(
a
7
),
// 41
"w"
(
a
14
),
// 41
"w"
(
a
8
),
// 42
"w"
(
a
1
),
// 42
"w"
(
a
9
),
// 43
"w"
(
a
3
),
// 43
"w"
(
a
10
),
// 44
"w"
(
a
5
),
// 44
"w"
(
a
11
),
// 45
"w"
(
a
7
),
// 45
"w"
(
a
12
),
// 46
"w"
(
a
9
),
// 46
"w"
(
a1
3
),
// 47
"w"
(
a1
1
),
// 47
"w"
(
a1
4
),
// 48
"w"
(
a1
3
),
// 48
"w"
(
a15
)
// 49
"w"
(
a15
)
// 49
:
"cc"
,
"memory"
,
:
"cc"
,
"memory"
,
"v16"
,
"v16"
,
...
@@ -585,7 +579,6 @@ void Gemm(const float *A,
...
@@ -585,7 +579,6 @@ void Gemm(const float *A,
}
}
memset
(
C
,
0
,
sizeof
(
float
)
*
batch
*
height
*
width
);
memset
(
C
,
0
,
sizeof
(
float
)
*
batch
*
height
*
width
);
// It is better to use large block size if it fits for fast cache.
// It is better to use large block size if it fits for fast cache.
// Assume l1 cache size is 32k, we load three blocks at a time (A, B, C),
// Assume l1 cache size is 32k, we load three blocks at a time (A, B, C),
// the block size should be sqrt(32k / sizeof(T) / 3).
// the block size should be sqrt(32k / sizeof(T) / 3).
...
...
mace/kernels/opencl/activation.cc
浏览文件 @
bdaa5c18
...
@@ -45,7 +45,8 @@ void ActivationFunctor<DeviceType::GPU, T>::operator()(const Tensor *input,
...
@@ -45,7 +45,8 @@ void ActivationFunctor<DeviceType::GPU, T>::operator()(const Tensor *input,
if
(
runtime
->
IsOutOfRangeCheckEnabled
())
{
if
(
runtime
->
IsOutOfRangeCheckEnabled
())
{
built_options
.
emplace
(
"-DOUT_OF_RANGE_CHECK"
);
built_options
.
emplace
(
"-DOUT_OF_RANGE_CHECK"
);
kernel_error_
=
std
::
move
(
std
::
unique_ptr
<
Buffer
>
(
kernel_error_
=
std
::
move
(
std
::
unique_ptr
<
Buffer
>
(
new
Buffer
(
GetDeviceAllocator
(
DeviceType
::
GPU
),
1
)));
new
Buffer
(
GetDeviceAllocator
(
DeviceType
::
GPU
))));
kernel_error_
->
Allocate
(
1
);
kernel_error_
->
Map
(
nullptr
);
kernel_error_
->
Map
(
nullptr
);
*
(
kernel_error_
->
mutable_data
<
char
>
())
=
0
;
*
(
kernel_error_
->
mutable_data
<
char
>
())
=
0
;
kernel_error_
->
UnMap
();
kernel_error_
->
UnMap
();
...
...
mace/kernels/opencl/addn.cc
浏览文件 @
bdaa5c18
...
@@ -58,7 +58,8 @@ void AddNFunctor<DeviceType::GPU, T>::operator()(
...
@@ -58,7 +58,8 @@ void AddNFunctor<DeviceType::GPU, T>::operator()(
if
(
runtime
->
IsOutOfRangeCheckEnabled
())
{
if
(
runtime
->
IsOutOfRangeCheckEnabled
())
{
built_options
.
emplace
(
"-DOUT_OF_RANGE_CHECK"
);
built_options
.
emplace
(
"-DOUT_OF_RANGE_CHECK"
);
kernel_error_
=
std
::
move
(
std
::
unique_ptr
<
Buffer
>
(
kernel_error_
=
std
::
move
(
std
::
unique_ptr
<
Buffer
>
(
new
Buffer
(
GetDeviceAllocator
(
DeviceType
::
GPU
),
1
)));
new
Buffer
(
GetDeviceAllocator
(
DeviceType
::
GPU
))));
kernel_error_
->
Allocate
(
1
);
kernel_error_
->
Map
(
nullptr
);
kernel_error_
->
Map
(
nullptr
);
*
(
kernel_error_
->
mutable_data
<
char
>
())
=
0
;
*
(
kernel_error_
->
mutable_data
<
char
>
())
=
0
;
kernel_error_
->
UnMap
();
kernel_error_
->
UnMap
();
...
...
mace/kernels/opencl/batch_norm.cc
浏览文件 @
bdaa5c18
...
@@ -56,7 +56,8 @@ void BatchNormFunctor<DeviceType::GPU, T>::operator()(const Tensor *input,
...
@@ -56,7 +56,8 @@ void BatchNormFunctor<DeviceType::GPU, T>::operator()(const Tensor *input,
if
(
runtime
->
IsOutOfRangeCheckEnabled
())
{
if
(
runtime
->
IsOutOfRangeCheckEnabled
())
{
built_options
.
emplace
(
"-DOUT_OF_RANGE_CHECK"
);
built_options
.
emplace
(
"-DOUT_OF_RANGE_CHECK"
);
kernel_error_
=
std
::
move
(
std
::
unique_ptr
<
Buffer
>
(
kernel_error_
=
std
::
move
(
std
::
unique_ptr
<
Buffer
>
(
new
Buffer
(
GetDeviceAllocator
(
DeviceType
::
GPU
),
1
)));
new
Buffer
(
GetDeviceAllocator
(
DeviceType
::
GPU
))));
kernel_error_
->
Allocate
(
1
);
kernel_error_
->
Map
(
nullptr
);
kernel_error_
->
Map
(
nullptr
);
*
(
kernel_error_
->
mutable_data
<
char
>
())
=
0
;
*
(
kernel_error_
->
mutable_data
<
char
>
())
=
0
;
kernel_error_
->
UnMap
();
kernel_error_
->
UnMap
();
...
...
mace/kernels/opencl/bias_add.cc
浏览文件 @
bdaa5c18
...
@@ -49,7 +49,8 @@ void BiasAddFunctor<DeviceType::GPU, T>::operator()(const Tensor *input,
...
@@ -49,7 +49,8 @@ void BiasAddFunctor<DeviceType::GPU, T>::operator()(const Tensor *input,
if
(
runtime
->
IsOutOfRangeCheckEnabled
())
{
if
(
runtime
->
IsOutOfRangeCheckEnabled
())
{
built_options
.
emplace
(
"-DOUT_OF_RANGE_CHECK"
);
built_options
.
emplace
(
"-DOUT_OF_RANGE_CHECK"
);
kernel_error_
=
std
::
move
(
std
::
unique_ptr
<
Buffer
>
(
kernel_error_
=
std
::
move
(
std
::
unique_ptr
<
Buffer
>
(
new
Buffer
(
GetDeviceAllocator
(
DeviceType
::
GPU
),
1
)));
new
Buffer
(
GetDeviceAllocator
(
DeviceType
::
GPU
))));
kernel_error_
->
Allocate
(
1
);
kernel_error_
->
Map
(
nullptr
);
kernel_error_
->
Map
(
nullptr
);
*
(
kernel_error_
->
mutable_data
<
char
>
())
=
0
;
*
(
kernel_error_
->
mutable_data
<
char
>
())
=
0
;
kernel_error_
->
UnMap
();
kernel_error_
->
UnMap
();
...
@@ -90,7 +91,8 @@ void BiasAddFunctor<DeviceType::GPU, T>::operator()(const Tensor *input,
...
@@ -90,7 +91,8 @@ void BiasAddFunctor<DeviceType::GPU, T>::operator()(const Tensor *input,
}
else
{
}
else
{
std
::
vector
<
uint32_t
>
roundup_gws
(
lws
.
size
());
std
::
vector
<
uint32_t
>
roundup_gws
(
lws
.
size
());
for
(
size_t
i
=
0
;
i
<
lws
.
size
();
++
i
)
{
for
(
size_t
i
=
0
;
i
<
lws
.
size
();
++
i
)
{
roundup_gws
[
i
]
=
RoundUp
(
gws
[
i
],
lws
[
i
]);
if
(
lws
[
i
]
!=
0
)
roundup_gws
[
i
]
=
RoundUp
(
gws
[
i
],
lws
[
i
]);
}
}
error
=
runtime
->
command_queue
().
enqueueNDRangeKernel
(
error
=
runtime
->
command_queue
().
enqueueNDRangeKernel
(
...
...
mace/kernels/opencl/buffer_to_image.cc
浏览文件 @
bdaa5c18
...
@@ -93,7 +93,8 @@ void BufferToImageFunctor<DeviceType::GPU, T>::operator()(
...
@@ -93,7 +93,8 @@ void BufferToImageFunctor<DeviceType::GPU, T>::operator()(
built_options
.
emplace
(
"-DOUT_OF_RANGE_CHECK"
);
built_options
.
emplace
(
"-DOUT_OF_RANGE_CHECK"
);
if
(
!
kernel_error_
)
{
if
(
!
kernel_error_
)
{
kernel_error_
=
std
::
move
(
std
::
unique_ptr
<
Buffer
>
(
kernel_error_
=
std
::
move
(
std
::
unique_ptr
<
Buffer
>
(
new
Buffer
(
GetDeviceAllocator
(
DeviceType
::
GPU
),
1
)));
new
Buffer
(
GetDeviceAllocator
(
DeviceType
::
GPU
))));
kernel_error_
->
Allocate
(
1
);
kernel_error_
->
Map
(
nullptr
);
kernel_error_
->
Map
(
nullptr
);
*
(
kernel_error_
->
mutable_data
<
char
>
())
=
0
;
*
(
kernel_error_
->
mutable_data
<
char
>
())
=
0
;
kernel_error_
->
UnMap
();
kernel_error_
->
UnMap
();
...
...
mace/kernels/opencl/channel_shuffle.cc
浏览文件 @
bdaa5c18
...
@@ -56,7 +56,8 @@ void ChannelShuffleFunctor<DeviceType::GPU, T>::operator()(
...
@@ -56,7 +56,8 @@ void ChannelShuffleFunctor<DeviceType::GPU, T>::operator()(
if
(
runtime
->
IsOutOfRangeCheckEnabled
())
{
if
(
runtime
->
IsOutOfRangeCheckEnabled
())
{
built_options
.
emplace
(
"-DOUT_OF_RANGE_CHECK"
);
built_options
.
emplace
(
"-DOUT_OF_RANGE_CHECK"
);
kernel_error_
=
std
::
move
(
std
::
unique_ptr
<
Buffer
>
(
kernel_error_
=
std
::
move
(
std
::
unique_ptr
<
Buffer
>
(
new
Buffer
(
GetDeviceAllocator
(
DeviceType
::
GPU
),
1
)));
new
Buffer
(
GetDeviceAllocator
(
DeviceType
::
GPU
))));
kernel_error_
->
Allocate
(
1
);
kernel_error_
->
Map
(
nullptr
);
kernel_error_
->
Map
(
nullptr
);
*
(
kernel_error_
->
mutable_data
<
char
>
())
=
0
;
*
(
kernel_error_
->
mutable_data
<
char
>
())
=
0
;
kernel_error_
->
UnMap
();
kernel_error_
->
UnMap
();
...
...
mace/kernels/opencl/concat.cc
浏览文件 @
bdaa5c18
...
@@ -67,7 +67,8 @@ static void Concat2(cl::Kernel *kernel,
...
@@ -67,7 +67,8 @@ static void Concat2(cl::Kernel *kernel,
if
(
runtime
->
IsOutOfRangeCheckEnabled
())
{
if
(
runtime
->
IsOutOfRangeCheckEnabled
())
{
built_options
.
emplace
(
"-DOUT_OF_RANGE_CHECK"
);
built_options
.
emplace
(
"-DOUT_OF_RANGE_CHECK"
);
*
kernel_error
=
std
::
move
(
std
::
unique_ptr
<
Buffer
>
(
*
kernel_error
=
std
::
move
(
std
::
unique_ptr
<
Buffer
>
(
new
Buffer
(
GetDeviceAllocator
(
DeviceType
::
GPU
),
1
)));
new
Buffer
(
GetDeviceAllocator
(
DeviceType
::
GPU
))));
(
*
kernel_error
)
->
Allocate
(
1
);
(
*
kernel_error
)
->
Map
(
nullptr
);
(
*
kernel_error
)
->
Map
(
nullptr
);
*
((
*
kernel_error
)
->
mutable_data
<
char
>
())
=
0
;
*
((
*
kernel_error
)
->
mutable_data
<
char
>
())
=
0
;
(
*
kernel_error
)
->
UnMap
();
(
*
kernel_error
)
->
UnMap
();
...
@@ -148,7 +149,8 @@ static void ConcatN(cl::Kernel *kernel,
...
@@ -148,7 +149,8 @@ static void ConcatN(cl::Kernel *kernel,
if
(
runtime
->
IsOutOfRangeCheckEnabled
())
{
if
(
runtime
->
IsOutOfRangeCheckEnabled
())
{
built_options
.
emplace
(
"-DOUT_OF_RANGE_CHECK"
);
built_options
.
emplace
(
"-DOUT_OF_RANGE_CHECK"
);
*
kernel_error
=
std
::
move
(
std
::
unique_ptr
<
Buffer
>
(
*
kernel_error
=
std
::
move
(
std
::
unique_ptr
<
Buffer
>
(
new
Buffer
(
GetDeviceAllocator
(
DeviceType
::
GPU
),
1
)));
new
Buffer
(
GetDeviceAllocator
(
DeviceType
::
GPU
))));
(
*
kernel_error
)
->
Allocate
(
1
);
(
*
kernel_error
)
->
Map
(
nullptr
);
(
*
kernel_error
)
->
Map
(
nullptr
);
*
((
*
kernel_error
)
->
mutable_data
<
char
>
())
=
0
;
*
((
*
kernel_error
)
->
mutable_data
<
char
>
())
=
0
;
(
*
kernel_error
)
->
UnMap
();
(
*
kernel_error
)
->
UnMap
();
...
...
mace/kernels/opencl/conv_2d_1x1.cc
浏览文件 @
bdaa5c18
...
@@ -100,7 +100,8 @@ extern void Conv2dOpenclK1x1(cl::Kernel *kernel,
...
@@ -100,7 +100,8 @@ extern void Conv2dOpenclK1x1(cl::Kernel *kernel,
if
(
runtime
->
IsOutOfRangeCheckEnabled
())
{
if
(
runtime
->
IsOutOfRangeCheckEnabled
())
{
built_options
.
emplace
(
"-DOUT_OF_RANGE_CHECK"
);
built_options
.
emplace
(
"-DOUT_OF_RANGE_CHECK"
);
*
kernel_error
=
std
::
move
(
std
::
unique_ptr
<
Buffer
>
(
*
kernel_error
=
std
::
move
(
std
::
unique_ptr
<
Buffer
>
(
new
Buffer
(
GetDeviceAllocator
(
DeviceType
::
GPU
),
1
)));
new
Buffer
(
GetDeviceAllocator
(
DeviceType
::
GPU
))));
(
*
kernel_error
)
->
Allocate
(
1
);
(
*
kernel_error
)
->
Map
(
nullptr
);
(
*
kernel_error
)
->
Map
(
nullptr
);
*
((
*
kernel_error
)
->
mutable_data
<
char
>
())
=
0
;
*
((
*
kernel_error
)
->
mutable_data
<
char
>
())
=
0
;
(
*
kernel_error
)
->
UnMap
();
(
*
kernel_error
)
->
UnMap
();
...
...
mace/kernels/opencl/conv_2d_3x3.cc
浏览文件 @
bdaa5c18
...
@@ -86,7 +86,8 @@ extern void Conv2dOpenclK3x3(cl::Kernel *kernel,
...
@@ -86,7 +86,8 @@ extern void Conv2dOpenclK3x3(cl::Kernel *kernel,
if
(
runtime
->
IsOutOfRangeCheckEnabled
())
{
if
(
runtime
->
IsOutOfRangeCheckEnabled
())
{
built_options
.
emplace
(
"-DOUT_OF_RANGE_CHECK"
);
built_options
.
emplace
(
"-DOUT_OF_RANGE_CHECK"
);
*
kernel_error
=
std
::
move
(
std
::
unique_ptr
<
Buffer
>
(
*
kernel_error
=
std
::
move
(
std
::
unique_ptr
<
Buffer
>
(
new
Buffer
(
GetDeviceAllocator
(
DeviceType
::
GPU
),
1
)));
new
Buffer
(
GetDeviceAllocator
(
DeviceType
::
GPU
))));
(
*
kernel_error
)
->
Allocate
(
1
);
(
*
kernel_error
)
->
Map
(
nullptr
);
(
*
kernel_error
)
->
Map
(
nullptr
);
*
((
*
kernel_error
)
->
mutable_data
<
char
>
())
=
0
;
*
((
*
kernel_error
)
->
mutable_data
<
char
>
())
=
0
;
(
*
kernel_error
)
->
UnMap
();
(
*
kernel_error
)
->
UnMap
();
...
...
mace/kernels/opencl/conv_2d_general.cc
浏览文件 @
bdaa5c18
...
@@ -94,7 +94,8 @@ extern void Conv2dOpencl(cl::Kernel *kernel,
...
@@ -94,7 +94,8 @@ extern void Conv2dOpencl(cl::Kernel *kernel,
if
(
runtime
->
IsOutOfRangeCheckEnabled
())
{
if
(
runtime
->
IsOutOfRangeCheckEnabled
())
{
built_options
.
emplace
(
"-DOUT_OF_RANGE_CHECK"
);
built_options
.
emplace
(
"-DOUT_OF_RANGE_CHECK"
);
*
kernel_error
=
std
::
move
(
std
::
unique_ptr
<
Buffer
>
(
*
kernel_error
=
std
::
move
(
std
::
unique_ptr
<
Buffer
>
(
new
Buffer
(
GetDeviceAllocator
(
DeviceType
::
GPU
),
1
)));
new
Buffer
(
GetDeviceAllocator
(
DeviceType
::
GPU
))));
(
*
kernel_error
)
->
Allocate
(
1
);
(
*
kernel_error
)
->
Map
(
nullptr
);
(
*
kernel_error
)
->
Map
(
nullptr
);
*
((
*
kernel_error
)
->
mutable_data
<
char
>
())
=
0
;
*
((
*
kernel_error
)
->
mutable_data
<
char
>
())
=
0
;
(
*
kernel_error
)
->
UnMap
();
(
*
kernel_error
)
->
UnMap
();
...
...
mace/kernels/opencl/deconv_2d_opencl.cc
浏览文件 @
bdaa5c18
...
@@ -65,7 +65,8 @@ void Deconv2dOpencl(cl::Kernel *kernel,
...
@@ -65,7 +65,8 @@ void Deconv2dOpencl(cl::Kernel *kernel,
if
(
runtime
->
IsOutOfRangeCheckEnabled
())
{
if
(
runtime
->
IsOutOfRangeCheckEnabled
())
{
built_options
.
emplace
(
"-DOUT_OF_RANGE_CHECK"
);
built_options
.
emplace
(
"-DOUT_OF_RANGE_CHECK"
);
*
kernel_error
=
std
::
move
(
std
::
unique_ptr
<
Buffer
>
(
*
kernel_error
=
std
::
move
(
std
::
unique_ptr
<
Buffer
>
(
new
Buffer
(
GetDeviceAllocator
(
DeviceType
::
GPU
),
1
)));
new
Buffer
(
GetDeviceAllocator
(
DeviceType
::
GPU
))));
(
*
kernel_error
)
->
Allocate
(
1
);
(
*
kernel_error
)
->
Map
(
nullptr
);
(
*
kernel_error
)
->
Map
(
nullptr
);
*
((
*
kernel_error
)
->
mutable_data
<
char
>
())
=
0
;
*
((
*
kernel_error
)
->
mutable_data
<
char
>
())
=
0
;
(
*
kernel_error
)
->
UnMap
();
(
*
kernel_error
)
->
UnMap
();
...
...
mace/kernels/opencl/depth_to_space.cc
浏览文件 @
bdaa5c18
...
@@ -86,7 +86,8 @@ void DepthToSpaceOpFunctor<DeviceType::GPU, T>::operator()(
...
@@ -86,7 +86,8 @@ void DepthToSpaceOpFunctor<DeviceType::GPU, T>::operator()(
if
(
runtime
->
IsOutOfRangeCheckEnabled
())
{
if
(
runtime
->
IsOutOfRangeCheckEnabled
())
{
built_options
.
emplace
(
"-DOUT_OF_RANGE_CHECK"
);
built_options
.
emplace
(
"-DOUT_OF_RANGE_CHECK"
);
kernel_error_
=
std
::
move
(
std
::
unique_ptr
<
Buffer
>
(
kernel_error_
=
std
::
move
(
std
::
unique_ptr
<
Buffer
>
(
new
Buffer
(
GetDeviceAllocator
(
DeviceType
::
GPU
),
1
)));
new
Buffer
(
GetDeviceAllocator
(
DeviceType
::
GPU
))));
kernel_error_
->
Allocate
(
1
);
kernel_error_
->
Map
(
nullptr
);
kernel_error_
->
Map
(
nullptr
);
*
(
kernel_error_
->
mutable_data
<
char
>
())
=
0
;
*
(
kernel_error_
->
mutable_data
<
char
>
())
=
0
;
kernel_error_
->
UnMap
();
kernel_error_
->
UnMap
();
...
...
mace/kernels/opencl/depthwise_conv.cc
浏览文件 @
bdaa5c18
...
@@ -97,7 +97,8 @@ static void DepthwiseConv2d(cl::Kernel *kernel,
...
@@ -97,7 +97,8 @@ static void DepthwiseConv2d(cl::Kernel *kernel,
if
(
runtime
->
IsOutOfRangeCheckEnabled
())
{
if
(
runtime
->
IsOutOfRangeCheckEnabled
())
{
built_options
.
emplace
(
"-DOUT_OF_RANGE_CHECK"
);
built_options
.
emplace
(
"-DOUT_OF_RANGE_CHECK"
);
*
kernel_error
=
std
::
move
(
std
::
unique_ptr
<
Buffer
>
(
*
kernel_error
=
std
::
move
(
std
::
unique_ptr
<
Buffer
>
(
new
Buffer
(
GetDeviceAllocator
(
DeviceType
::
GPU
),
1
)));
new
Buffer
(
GetDeviceAllocator
(
DeviceType
::
GPU
))));
(
*
kernel_error
)
->
Allocate
(
1
);
(
*
kernel_error
)
->
Map
(
nullptr
);
(
*
kernel_error
)
->
Map
(
nullptr
);
*
((
*
kernel_error
)
->
mutable_data
<
char
>
())
=
0
;
*
((
*
kernel_error
)
->
mutable_data
<
char
>
())
=
0
;
(
*
kernel_error
)
->
UnMap
();
(
*
kernel_error
)
->
UnMap
();
...
...
mace/kernels/opencl/eltwise.cc
浏览文件 @
bdaa5c18
...
@@ -97,7 +97,8 @@ void EltwiseFunctor<DeviceType::GPU, T>::operator()(const Tensor *input0,
...
@@ -97,7 +97,8 @@ void EltwiseFunctor<DeviceType::GPU, T>::operator()(const Tensor *input0,
if
(
runtime
->
IsOutOfRangeCheckEnabled
())
{
if
(
runtime
->
IsOutOfRangeCheckEnabled
())
{
built_options
.
emplace
(
"-DOUT_OF_RANGE_CHECK"
);
built_options
.
emplace
(
"-DOUT_OF_RANGE_CHECK"
);
kernel_error_
=
std
::
move
(
std
::
unique_ptr
<
Buffer
>
(
kernel_error_
=
std
::
move
(
std
::
unique_ptr
<
Buffer
>
(
new
Buffer
(
GetDeviceAllocator
(
DeviceType
::
GPU
),
1
)));
new
Buffer
(
GetDeviceAllocator
(
DeviceType
::
GPU
))));
kernel_error_
->
Allocate
(
1
);
kernel_error_
->
Map
(
nullptr
);
kernel_error_
->
Map
(
nullptr
);
*
(
kernel_error_
->
mutable_data
<
char
>
())
=
0
;
*
(
kernel_error_
->
mutable_data
<
char
>
())
=
0
;
kernel_error_
->
UnMap
();
kernel_error_
->
UnMap
();
...
...
mace/kernels/opencl/fully_connected.cc
浏览文件 @
bdaa5c18
...
@@ -74,7 +74,8 @@ void FCWXKernel(cl::Kernel *kernel,
...
@@ -74,7 +74,8 @@ void FCWXKernel(cl::Kernel *kernel,
if
(
runtime
->
IsOutOfRangeCheckEnabled
())
{
if
(
runtime
->
IsOutOfRangeCheckEnabled
())
{
built_options
.
emplace
(
"-DOUT_OF_RANGE_CHECK"
);
built_options
.
emplace
(
"-DOUT_OF_RANGE_CHECK"
);
*
kernel_error
=
std
::
move
(
std
::
unique_ptr
<
Buffer
>
(
*
kernel_error
=
std
::
move
(
std
::
unique_ptr
<
Buffer
>
(
new
Buffer
(
GetDeviceAllocator
(
DeviceType
::
GPU
),
1
)));
new
Buffer
(
GetDeviceAllocator
(
DeviceType
::
GPU
))));
(
*
kernel_error
)
->
Allocate
(
1
);
(
*
kernel_error
)
->
Map
(
nullptr
);
(
*
kernel_error
)
->
Map
(
nullptr
);
*
((
*
kernel_error
)
->
mutable_data
<
char
>
())
=
0
;
*
((
*
kernel_error
)
->
mutable_data
<
char
>
())
=
0
;
(
*
kernel_error
)
->
UnMap
();
(
*
kernel_error
)
->
UnMap
();
...
@@ -200,7 +201,8 @@ void FCWTXKernel(cl::Kernel *kernel,
...
@@ -200,7 +201,8 @@ void FCWTXKernel(cl::Kernel *kernel,
if
(
runtime
->
IsOutOfRangeCheckEnabled
())
{
if
(
runtime
->
IsOutOfRangeCheckEnabled
())
{
built_options
.
emplace
(
"-DOUT_OF_RANGE_CHECK"
);
built_options
.
emplace
(
"-DOUT_OF_RANGE_CHECK"
);
*
kernel_error
=
std
::
move
(
std
::
unique_ptr
<
Buffer
>
(
*
kernel_error
=
std
::
move
(
std
::
unique_ptr
<
Buffer
>
(
new
Buffer
(
GetDeviceAllocator
(
DeviceType
::
GPU
),
1
)));
new
Buffer
(
GetDeviceAllocator
(
DeviceType
::
GPU
))));
(
*
kernel_error
)
->
Allocate
(
1
);
(
*
kernel_error
)
->
Map
(
nullptr
);
(
*
kernel_error
)
->
Map
(
nullptr
);
*
((
*
kernel_error
)
->
mutable_data
<
char
>
())
=
0
;
*
((
*
kernel_error
)
->
mutable_data
<
char
>
())
=
0
;
(
*
kernel_error
)
->
UnMap
();
(
*
kernel_error
)
->
UnMap
();
...
...
mace/kernels/opencl/image_to_buffer.cc
浏览文件 @
bdaa5c18
...
@@ -86,7 +86,8 @@ void ImageToBufferFunctor<DeviceType::GPU, T>::operator()(
...
@@ -86,7 +86,8 @@ void ImageToBufferFunctor<DeviceType::GPU, T>::operator()(
built_options
.
emplace
(
"-DOUT_OF_RANGE_CHECK"
);
built_options
.
emplace
(
"-DOUT_OF_RANGE_CHECK"
);
if
(
!
kernel_error_
)
{
if
(
!
kernel_error_
)
{
kernel_error_
=
std
::
move
(
std
::
unique_ptr
<
Buffer
>
(
kernel_error_
=
std
::
move
(
std
::
unique_ptr
<
Buffer
>
(
new
Buffer
(
GetDeviceAllocator
(
DeviceType
::
GPU
),
1
)));
new
Buffer
(
GetDeviceAllocator
(
DeviceType
::
GPU
))));
kernel_error_
->
Allocate
(
1
);
kernel_error_
->
Map
(
nullptr
);
kernel_error_
->
Map
(
nullptr
);
*
(
kernel_error_
->
mutable_data
<
char
>
())
=
0
;
*
(
kernel_error_
->
mutable_data
<
char
>
())
=
0
;
kernel_error_
->
UnMap
();
kernel_error_
->
UnMap
();
...
...
mace/kernels/opencl/matmul.cc
浏览文件 @
bdaa5c18
...
@@ -54,7 +54,8 @@ void MatMulFunctor<DeviceType::GPU, T>::operator()(const Tensor *A,
...
@@ -54,7 +54,8 @@ void MatMulFunctor<DeviceType::GPU, T>::operator()(const Tensor *A,
if
(
runtime
->
IsOutOfRangeCheckEnabled
())
{
if
(
runtime
->
IsOutOfRangeCheckEnabled
())
{
built_options
.
emplace
(
"-DOUT_OF_RANGE_CHECK"
);
built_options
.
emplace
(
"-DOUT_OF_RANGE_CHECK"
);
kernel_error_
=
std
::
move
(
std
::
unique_ptr
<
Buffer
>
(
kernel_error_
=
std
::
move
(
std
::
unique_ptr
<
Buffer
>
(
new
Buffer
(
GetDeviceAllocator
(
DeviceType
::
GPU
),
1
)));
new
Buffer
(
GetDeviceAllocator
(
DeviceType
::
GPU
))));
kernel_error_
->
Allocate
(
1
);
kernel_error_
->
Map
(
nullptr
);
kernel_error_
->
Map
(
nullptr
);
*
(
kernel_error_
->
mutable_data
<
char
>
())
=
0
;
*
(
kernel_error_
->
mutable_data
<
char
>
())
=
0
;
kernel_error_
->
UnMap
();
kernel_error_
->
UnMap
();
...
...
mace/kernels/opencl/out_of_range_check_test.cc
浏览文件 @
bdaa5c18
...
@@ -57,7 +57,8 @@ bool BufferToImageOpImpl(Tensor *buffer,
...
@@ -57,7 +57,8 @@ bool BufferToImageOpImpl(Tensor *buffer,
if
(
runtime
->
IsOutOfRangeCheckEnabled
())
{
if
(
runtime
->
IsOutOfRangeCheckEnabled
())
{
built_options
.
emplace
(
"-DOUT_OF_RANGE_CHECK"
);
built_options
.
emplace
(
"-DOUT_OF_RANGE_CHECK"
);
kernel_error
=
std
::
move
(
std
::
unique_ptr
<
Buffer
>
(
kernel_error
=
std
::
move
(
std
::
unique_ptr
<
Buffer
>
(
new
Buffer
(
GetDeviceAllocator
(
DeviceType
::
GPU
),
1
)));
new
Buffer
(
GetDeviceAllocator
(
DeviceType
::
GPU
))));
kernel_error
->
Allocate
(
1
);
kernel_error
->
Map
(
nullptr
);
kernel_error
->
Map
(
nullptr
);
*
(
kernel_error
->
mutable_data
<
char
>
())
=
0
;
*
(
kernel_error
->
mutable_data
<
char
>
())
=
0
;
kernel_error
->
UnMap
();
kernel_error
->
UnMap
();
...
...
mace/kernels/opencl/pad.cc
浏览文件 @
bdaa5c18
...
@@ -60,7 +60,8 @@ void PadFunctor<DeviceType::GPU, T>::operator()(
...
@@ -60,7 +60,8 @@ void PadFunctor<DeviceType::GPU, T>::operator()(
if
(
runtime
->
IsOutOfRangeCheckEnabled
())
{
if
(
runtime
->
IsOutOfRangeCheckEnabled
())
{
built_options
.
emplace
(
"-DOUT_OF_RANGE_CHECK"
);
built_options
.
emplace
(
"-DOUT_OF_RANGE_CHECK"
);
kernel_error_
=
std
::
move
(
std
::
unique_ptr
<
Buffer
>
(
kernel_error_
=
std
::
move
(
std
::
unique_ptr
<
Buffer
>
(
new
Buffer
(
GetDeviceAllocator
(
DeviceType
::
GPU
),
1
)));
new
Buffer
(
GetDeviceAllocator
(
DeviceType
::
GPU
))));
kernel_error_
->
Allocate
(
1
);
kernel_error_
->
Map
(
nullptr
);
kernel_error_
->
Map
(
nullptr
);
*
(
kernel_error_
->
mutable_data
<
char
>
())
=
0
;
*
(
kernel_error_
->
mutable_data
<
char
>
())
=
0
;
kernel_error_
->
UnMap
();
kernel_error_
->
UnMap
();
...
...
mace/kernels/opencl/pooling.cc
浏览文件 @
bdaa5c18
...
@@ -72,7 +72,8 @@ void PoolingFunctor<DeviceType::GPU, T>::operator()(const Tensor *input,
...
@@ -72,7 +72,8 @@ void PoolingFunctor<DeviceType::GPU, T>::operator()(const Tensor *input,
if
(
runtime
->
IsOutOfRangeCheckEnabled
())
{
if
(
runtime
->
IsOutOfRangeCheckEnabled
())
{
built_options
.
emplace
(
"-DOUT_OF_RANGE_CHECK"
);
built_options
.
emplace
(
"-DOUT_OF_RANGE_CHECK"
);
kernel_error_
=
std
::
move
(
std
::
unique_ptr
<
Buffer
>
(
kernel_error_
=
std
::
move
(
std
::
unique_ptr
<
Buffer
>
(
new
Buffer
(
GetDeviceAllocator
(
DeviceType
::
GPU
),
1
)));
new
Buffer
(
GetDeviceAllocator
(
DeviceType
::
GPU
))));
kernel_error_
->
Allocate
(
1
);
kernel_error_
->
Map
(
nullptr
);
kernel_error_
->
Map
(
nullptr
);
*
(
kernel_error_
->
mutable_data
<
char
>
())
=
0
;
*
(
kernel_error_
->
mutable_data
<
char
>
())
=
0
;
kernel_error_
->
UnMap
();
kernel_error_
->
UnMap
();
...
...
mace/kernels/opencl/resize_bilinear.cc
浏览文件 @
bdaa5c18
...
@@ -78,7 +78,8 @@ void ResizeBilinearFunctor<DeviceType::GPU, T>::operator()(
...
@@ -78,7 +78,8 @@ void ResizeBilinearFunctor<DeviceType::GPU, T>::operator()(
if
(
runtime
->
IsOutOfRangeCheckEnabled
())
{
if
(
runtime
->
IsOutOfRangeCheckEnabled
())
{
built_options
.
emplace
(
"-DOUT_OF_RANGE_CHECK"
);
built_options
.
emplace
(
"-DOUT_OF_RANGE_CHECK"
);
kernel_error_
=
std
::
move
(
std
::
unique_ptr
<
Buffer
>
(
kernel_error_
=
std
::
move
(
std
::
unique_ptr
<
Buffer
>
(
new
Buffer
(
GetDeviceAllocator
(
DeviceType
::
GPU
),
1
)));
new
Buffer
(
GetDeviceAllocator
(
DeviceType
::
GPU
))));
kernel_error_
->
Allocate
(
1
);
kernel_error_
->
Map
(
nullptr
);
kernel_error_
->
Map
(
nullptr
);
*
(
kernel_error_
->
mutable_data
<
char
>
())
=
0
;
*
(
kernel_error_
->
mutable_data
<
char
>
())
=
0
;
kernel_error_
->
UnMap
();
kernel_error_
->
UnMap
();
...
...
mace/kernels/opencl/slice.cc
浏览文件 @
bdaa5c18
...
@@ -51,7 +51,8 @@ void SliceFunctor<DeviceType::GPU, T>::operator()(
...
@@ -51,7 +51,8 @@ void SliceFunctor<DeviceType::GPU, T>::operator()(
if
(
runtime
->
IsOutOfRangeCheckEnabled
())
{
if
(
runtime
->
IsOutOfRangeCheckEnabled
())
{
built_options
.
emplace
(
"-DOUT_OF_RANGE_CHECK"
);
built_options
.
emplace
(
"-DOUT_OF_RANGE_CHECK"
);
kernel_error_
=
std
::
move
(
std
::
unique_ptr
<
Buffer
>
(
kernel_error_
=
std
::
move
(
std
::
unique_ptr
<
Buffer
>
(
new
Buffer
(
GetDeviceAllocator
(
DeviceType
::
GPU
),
1
)));
new
Buffer
(
GetDeviceAllocator
(
DeviceType
::
GPU
))));
kernel_error_
->
Allocate
(
1
);
kernel_error_
->
Map
(
nullptr
);
kernel_error_
->
Map
(
nullptr
);
*
(
kernel_error_
->
mutable_data
<
char
>
())
=
0
;
*
(
kernel_error_
->
mutable_data
<
char
>
())
=
0
;
kernel_error_
->
UnMap
();
kernel_error_
->
UnMap
();
...
...
mace/kernels/opencl/softmax.cc
浏览文件 @
bdaa5c18
...
@@ -70,7 +70,8 @@ void SoftmaxFunctor<DeviceType::GPU, T>::operator()(const Tensor *logits,
...
@@ -70,7 +70,8 @@ void SoftmaxFunctor<DeviceType::GPU, T>::operator()(const Tensor *logits,
if
(
runtime
->
IsOutOfRangeCheckEnabled
())
{
if
(
runtime
->
IsOutOfRangeCheckEnabled
())
{
built_options
.
emplace
(
"-DOUT_OF_RANGE_CHECK"
);
built_options
.
emplace
(
"-DOUT_OF_RANGE_CHECK"
);
kernel_error_
=
std
::
move
(
std
::
unique_ptr
<
Buffer
>
(
kernel_error_
=
std
::
move
(
std
::
unique_ptr
<
Buffer
>
(
new
Buffer
(
GetDeviceAllocator
(
DeviceType
::
GPU
),
1
)));
new
Buffer
(
GetDeviceAllocator
(
DeviceType
::
GPU
))));
kernel_error_
->
Allocate
(
1
);
kernel_error_
->
Map
(
nullptr
);
kernel_error_
->
Map
(
nullptr
);
*
(
kernel_error_
->
mutable_data
<
char
>
())
=
0
;
*
(
kernel_error_
->
mutable_data
<
char
>
())
=
0
;
kernel_error_
->
UnMap
();
kernel_error_
->
UnMap
();
...
...
mace/kernels/opencl/space_to_batch.cc
浏览文件 @
bdaa5c18
...
@@ -70,7 +70,8 @@ void SpaceToBatchFunctor<DeviceType::GPU, T>::operator()(
...
@@ -70,7 +70,8 @@ void SpaceToBatchFunctor<DeviceType::GPU, T>::operator()(
if
(
runtime
->
IsOutOfRangeCheckEnabled
())
{
if
(
runtime
->
IsOutOfRangeCheckEnabled
())
{
built_options
.
emplace
(
"-DOUT_OF_RANGE_CHECK"
);
built_options
.
emplace
(
"-DOUT_OF_RANGE_CHECK"
);
kernel_error_
=
std
::
move
(
std
::
unique_ptr
<
Buffer
>
(
kernel_error_
=
std
::
move
(
std
::
unique_ptr
<
Buffer
>
(
new
Buffer
(
GetDeviceAllocator
(
DeviceType
::
GPU
),
1
)));
new
Buffer
(
GetDeviceAllocator
(
DeviceType
::
GPU
))));
kernel_error_
->
Allocate
(
1
);
kernel_error_
->
Map
(
nullptr
);
kernel_error_
->
Map
(
nullptr
);
*
(
kernel_error_
->
mutable_data
<
char
>
())
=
0
;
*
(
kernel_error_
->
mutable_data
<
char
>
())
=
0
;
kernel_error_
->
UnMap
();
kernel_error_
->
UnMap
();
...
...
mace/kernels/opencl/winograd_transform.cc
浏览文件 @
bdaa5c18
...
@@ -39,7 +39,8 @@ void WinogradTransformFunctor<DeviceType::GPU, T>::operator()(
...
@@ -39,7 +39,8 @@ void WinogradTransformFunctor<DeviceType::GPU, T>::operator()(
if
(
runtime
->
IsOutOfRangeCheckEnabled
())
{
if
(
runtime
->
IsOutOfRangeCheckEnabled
())
{
built_options
.
emplace
(
"-DOUT_OF_RANGE_CHECK"
);
built_options
.
emplace
(
"-DOUT_OF_RANGE_CHECK"
);
kernel_error_
=
std
::
move
(
std
::
unique_ptr
<
Buffer
>
(
kernel_error_
=
std
::
move
(
std
::
unique_ptr
<
Buffer
>
(
new
Buffer
(
GetDeviceAllocator
(
DeviceType
::
GPU
),
1
)));
new
Buffer
(
GetDeviceAllocator
(
DeviceType
::
GPU
))));
kernel_error_
->
Allocate
(
1
);
kernel_error_
->
Map
(
nullptr
);
kernel_error_
->
Map
(
nullptr
);
*
(
kernel_error_
->
mutable_data
<
char
>
())
=
0
;
*
(
kernel_error_
->
mutable_data
<
char
>
())
=
0
;
kernel_error_
->
UnMap
();
kernel_error_
->
UnMap
();
...
@@ -138,7 +139,8 @@ void WinogradInverseTransformFunctor<DeviceType::GPU, T>::operator()(
...
@@ -138,7 +139,8 @@ void WinogradInverseTransformFunctor<DeviceType::GPU, T>::operator()(
if
(
runtime
->
IsOutOfRangeCheckEnabled
())
{
if
(
runtime
->
IsOutOfRangeCheckEnabled
())
{
built_options
.
emplace
(
"-DOUT_OF_RANGE_CHECK"
);
built_options
.
emplace
(
"-DOUT_OF_RANGE_CHECK"
);
kernel_error_
=
std
::
move
(
std
::
unique_ptr
<
Buffer
>
(
kernel_error_
=
std
::
move
(
std
::
unique_ptr
<
Buffer
>
(
new
Buffer
(
GetDeviceAllocator
(
DeviceType
::
GPU
),
1
)));
new
Buffer
(
GetDeviceAllocator
(
DeviceType
::
GPU
))));
kernel_error_
->
Allocate
(
1
);
kernel_error_
->
Map
(
nullptr
);
kernel_error_
->
Map
(
nullptr
);
*
(
kernel_error_
->
mutable_data
<
char
>
())
=
0
;
*
(
kernel_error_
->
mutable_data
<
char
>
())
=
0
;
kernel_error_
->
UnMap
();
kernel_error_
->
UnMap
();
...
...
mace/kernels/pooling.h
浏览文件 @
bdaa5c18
...
@@ -75,39 +75,38 @@ struct PoolingFunctor<DeviceType::CPU, float>: PoolingFunctorBase {
...
@@ -75,39 +75,38 @@ struct PoolingFunctor<DeviceType::CPU, float>: PoolingFunctorBase {
}
}
void
MaxPooling
(
const
float
*
input
,
void
MaxPooling
(
const
float
*
input
,
const
index_t
batch
,
const
index_t
*
in_shape
,
const
index_t
in_height
,
const
index_t
*
out_shape
,
const
index_t
in_width
,
const
int
*
filter_hw
,
const
index_t
channels
,
const
int
*
stride_hw
,
const
index_t
out_height
,
const
int
*
dilation_hw
,
const
index_t
out_width
,
const
int
*
pad_hw
,
const
int
filter_height
,
const
int
filter_width
,
const
int
stride_h
,
const
int
stride_w
,
const
int
dilation_h
,
const
int
dilation_w
,
const
int
pad_top
,
const
int
pad_left
,
float
*
output
)
{
float
*
output
)
{
const
index_t
in_image_size
=
in_
height
*
in_width
;
const
index_t
in_image_size
=
in_
shape
[
2
]
*
in_shape
[
3
]
;
const
index_t
out_image_size
=
out_
height
*
out_width
;
const
index_t
out_image_size
=
out_
shape
[
2
]
*
out_shape
[
3
]
;
const
index_t
in_batch_size
=
channels
*
in_image_size
;
const
index_t
in_batch_size
=
in_shape
[
1
]
*
in_image_size
;
const
index_t
out_batch_size
=
channels
*
out_image_size
;
const
index_t
out_batch_size
=
out_shape
[
1
]
*
out_image_size
;
#pragma omp parallel for collapse(2)
#pragma omp parallel for collapse(2)
for
(
index_t
b
=
0
;
b
<
batch
;
++
b
)
{
for
(
index_t
b
=
0
;
b
<
out_shape
[
0
]
;
++
b
)
{
for
(
index_t
c
=
0
;
c
<
channels
;
++
c
)
{
for
(
index_t
c
=
0
;
c
<
out_shape
[
1
]
;
++
c
)
{
const
index_t
out_base
=
b
*
out_batch_size
+
c
*
out_image_size
;
const
index_t
out_base
=
b
*
out_batch_size
+
c
*
out_image_size
;
const
index_t
in_base
=
b
*
in_batch_size
+
c
*
in_image_size
;
const
index_t
in_base
=
b
*
in_batch_size
+
c
*
in_image_size
;
const
index_t
out_height
=
out_shape
[
2
];
const
index_t
out_width
=
out_shape
[
3
];
const
index_t
in_height
=
in_shape
[
2
];
const
index_t
in_width
=
in_shape
[
3
];
for
(
index_t
h
=
0
;
h
<
out_height
;
++
h
)
{
for
(
index_t
h
=
0
;
h
<
out_height
;
++
h
)
{
for
(
index_t
w
=
0
;
w
<
out_width
;
++
w
)
{
for
(
index_t
w
=
0
;
w
<
out_width
;
++
w
)
{
const
index_t
out_offset
=
out_base
+
h
*
out_width
+
w
;
const
index_t
out_offset
=
out_base
+
h
*
out_width
+
w
;
float
res
=
std
::
numeric_limits
<
float
>::
lowest
();
float
res
=
std
::
numeric_limits
<
float
>::
lowest
();
for
(
int
fh
=
0
;
fh
<
filter_height
;
++
fh
)
{
for
(
int
fh
=
0
;
fh
<
filter_hw
[
0
];
++
fh
)
{
for
(
int
fw
=
0
;
fw
<
filter_width
;
++
fw
)
{
for
(
int
fw
=
0
;
fw
<
filter_hw
[
1
];
++
fw
)
{
int
inh
=
h
*
stride_h
+
dilation_h
*
fh
-
pad_top
;
index_t
inh
=
int
inw
=
w
*
stride_w
+
dilation_w
*
fw
-
pad_left
;
h
*
stride_hw
[
0
]
+
dilation_hw
[
0
]
*
fh
-
pad_hw
[
0
];
index_t
inw
=
w
*
stride_hw
[
1
]
+
dilation_hw
[
1
]
*
fw
-
pad_hw
[
1
];
if
(
inh
>=
0
&&
inh
<
in_height
&&
inw
>=
0
&&
inw
<
in_width
)
{
if
(
inh
>=
0
&&
inh
<
in_height
&&
inw
>=
0
&&
inw
<
in_width
)
{
index_t
input_offset
=
in_base
+
inh
*
in_width
+
inw
;
index_t
input_offset
=
in_base
+
inh
*
in_width
+
inw
;
res
=
std
::
max
(
res
,
input
[
input_offset
]);
res
=
std
::
max
(
res
,
input
[
input_offset
]);
...
@@ -122,40 +121,38 @@ struct PoolingFunctor<DeviceType::CPU, float>: PoolingFunctorBase {
...
@@ -122,40 +121,38 @@ struct PoolingFunctor<DeviceType::CPU, float>: PoolingFunctorBase {
}
}
void
AvgPooling
(
const
float
*
input
,
void
AvgPooling
(
const
float
*
input
,
const
index_t
batch
,
const
index_t
*
in_shape
,
const
index_t
in_height
,
const
index_t
*
out_shape
,
const
index_t
in_width
,
const
int
*
filter_hw
,
const
index_t
channels
,
const
int
*
stride_hw
,
const
index_t
out_height
,
const
int
*
dilation_hw
,
const
index_t
out_width
,
const
int
*
pad_hw
,
const
int
filter_height
,
const
int
filter_width
,
const
int
stride_h
,
const
int
stride_w
,
const
int
dilation_h
,
const
int
dilation_w
,
const
int
pad_top
,
const
int
pad_left
,
float
*
output
)
{
float
*
output
)
{
const
index_t
in_image_size
=
in_
height
*
in_width
;
const
index_t
in_image_size
=
in_
shape
[
2
]
*
in_shape
[
3
]
;
const
index_t
out_image_size
=
out_
height
*
out_width
;
const
index_t
out_image_size
=
out_
shape
[
2
]
*
out_shape
[
3
]
;
const
index_t
in_batch_size
=
channels
*
in_image_size
;
const
index_t
in_batch_size
=
in_shape
[
1
]
*
in_image_size
;
const
index_t
out_batch_size
=
channels
*
out_image_size
;
const
index_t
out_batch_size
=
out_shape
[
1
]
*
out_image_size
;
#pragma omp parallel for collapse(2)
#pragma omp parallel for collapse(2)
for
(
index_t
b
=
0
;
b
<
batch
;
++
b
)
{
for
(
index_t
b
=
0
;
b
<
out_shape
[
0
]
;
++
b
)
{
for
(
index_t
c
=
0
;
c
<
channels
;
++
c
)
{
for
(
index_t
c
=
0
;
c
<
out_shape
[
1
]
;
++
c
)
{
const
index_t
out_base
=
b
*
out_batch_size
+
c
*
out_image_size
;
const
index_t
out_base
=
b
*
out_batch_size
+
c
*
out_image_size
;
const
index_t
in_base
=
b
*
in_batch_size
+
c
*
in_image_size
;
const
index_t
in_base
=
b
*
in_batch_size
+
c
*
in_image_size
;
const
index_t
in_height
=
in_shape
[
2
];
const
index_t
in_width
=
in_shape
[
3
];
const
index_t
out_height
=
out_shape
[
2
];
const
index_t
out_width
=
out_shape
[
3
];
for
(
index_t
h
=
0
;
h
<
out_height
;
++
h
)
{
for
(
index_t
h
=
0
;
h
<
out_height
;
++
h
)
{
for
(
index_t
w
=
0
;
w
<
out_width
;
++
w
)
{
for
(
index_t
w
=
0
;
w
<
out_width
;
++
w
)
{
const
index_t
out_offset
=
out_base
+
h
*
out_width
+
w
;
const
index_t
out_offset
=
out_base
+
h
*
out_width
+
w
;
float
res
=
0
;
float
res
=
0
;
int
block_size
=
0
;
int
block_size
=
0
;
for
(
int
fh
=
0
;
fh
<
filter_height
;
++
fh
)
{
for
(
int
fh
=
0
;
fh
<
filter_hw
[
0
];
++
fh
)
{
for
(
int
fw
=
0
;
fw
<
filter_width
;
++
fw
)
{
for
(
int
fw
=
0
;
fw
<
filter_hw
[
1
];
++
fw
)
{
int
inh
=
h
*
stride_h
+
dilation_h
*
fh
-
pad_top
;
index_t
inh
=
int
inw
=
w
*
stride_w
+
dilation_w
*
fw
-
pad_left
;
h
*
stride_hw
[
0
]
+
dilation_hw
[
0
]
*
fh
-
pad_hw
[
0
];
index_t
inw
=
w
*
stride_hw
[
1
]
+
dilation_hw
[
1
]
*
fw
-
pad_hw
[
1
];
if
(
inh
>=
0
&&
inh
<
in_height
&&
inw
>=
0
&&
inw
<
in_width
)
{
if
(
inh
>=
0
&&
inh
<
in_height
&&
inw
>=
0
&&
inw
<
in_width
)
{
index_t
input_offset
=
in_base
+
inh
*
in_width
+
inw
;
index_t
input_offset
=
in_base
+
inh
*
in_width
+
inw
;
res
+=
input
[
input_offset
];
res
+=
input
[
input_offset
];
...
@@ -200,59 +197,25 @@ struct PoolingFunctor<DeviceType::CPU, float>: PoolingFunctorBase {
...
@@ -200,59 +197,25 @@ struct PoolingFunctor<DeviceType::CPU, float>: PoolingFunctorBase {
const
float
*
input
=
input_tensor
->
data
<
float
>
();
const
float
*
input
=
input_tensor
->
data
<
float
>
();
float
*
output
=
output_tensor
->
mutable_data
<
float
>
();
float
*
output
=
output_tensor
->
mutable_data
<
float
>
();
const
index_t
*
input_shape
=
input_tensor
->
shape
().
data
();
const
index_t
*
input_shape
=
input_tensor
->
shape
().
data
();
index_t
batch
=
output_shape
[
0
];
int
pad_hw
[
2
]
=
{
paddings
[
0
]
/
2
,
paddings
[
1
]
/
2
};
index_t
channels
=
output_shape
[
1
];
index_t
height
=
output_shape
[
2
];
index_t
width
=
output_shape
[
3
];
index_t
input_height
=
input_shape
[
2
];
index_t
input_width
=
input_shape
[
3
];
int
filter_h
=
kernels_
[
0
];
int
filter_w
=
kernels_
[
1
];
int
stride_h
=
strides_
[
0
];
int
stride_w
=
strides_
[
1
];
int
dilation_h
=
dilations_
[
0
];
int
dilation_w
=
dilations_
[
1
];
int
pad_top
=
paddings
[
0
]
/
2
;
int
pad_left
=
paddings
[
1
]
/
2
;
if
(
pooling_type_
==
PoolingType
::
MAX
)
{
if
(
pooling_type_
==
PoolingType
::
MAX
)
{
MaxPooling
(
input
,
MaxPooling
(
input
,
batch
,
input_shape
,
input_height
,
output_shape
.
data
(),
input_width
,
kernels_
,
channels
,
strides_
,
height
,
dilations_
,
width
,
pad_hw
,
filter_h
,
filter_w
,
stride_h
,
stride_w
,
dilation_h
,
dilation_w
,
pad_top
,
pad_left
,
output
);
output
);
}
else
if
(
pooling_type_
==
PoolingType
::
AVG
)
{
}
else
if
(
pooling_type_
==
PoolingType
::
AVG
)
{
AvgPooling
(
input
,
AvgPooling
(
input
,
batch
,
input_shape
,
input_height
,
output_shape
.
data
(),
input_width
,
kernels_
,
channels
,
strides_
,
height
,
dilations_
,
width
,
pad_hw
,
filter_h
,
filter_w
,
stride_h
,
stride_w
,
dilation_h
,
dilation_w
,
pad_top
,
pad_left
,
output
);
output
);
}
else
{
}
else
{
MACE_NOT_IMPLEMENTED
;
MACE_NOT_IMPLEMENTED
;
...
...
mace/ops/activation.h
浏览文件 @
bdaa5c18
...
@@ -38,7 +38,7 @@ class ActivationOp : public Operator<D, T> {
...
@@ -38,7 +38,7 @@ class ActivationOp : public Operator<D, T> {
const
Tensor
*
input_tensor
=
this
->
Input
(
0
);
const
Tensor
*
input_tensor
=
this
->
Input
(
0
);
const
Tensor
*
alpha_tensor
=
const
Tensor
*
alpha_tensor
=
this
->
InputSize
()
>=
2
?
this
->
Input
(
1
)
:
nullptr
;
this
->
InputSize
()
>=
2
?
this
->
Input
(
1
)
:
nullptr
;
Tensor
*
output_tensor
=
this
->
outputs_
[
0
]
;
Tensor
*
output_tensor
=
this
->
Output
(
0
)
;
output_tensor
->
ResizeLike
(
input_tensor
);
output_tensor
->
ResizeLike
(
input_tensor
);
functor_
(
input_tensor
,
alpha_tensor
,
output_tensor
,
future
);
functor_
(
input_tensor
,
alpha_tensor
,
output_tensor
,
future
);
...
...
mace/ops/ops_test_util.h
浏览文件 @
bdaa5c18
...
@@ -620,6 +620,8 @@ struct Expector<EXP_TYPE, RES_TYPE, false> {
...
@@ -620,6 +620,8 @@ struct Expector<EXP_TYPE, RES_TYPE, false> {
static
void
Near
(
const
Tensor
&
x
,
const
Tensor
&
y
,
static
void
Near
(
const
Tensor
&
x
,
const
Tensor
&
y
,
const
double
rel_err
,
const
double
rel_err
,
const
double
abs_err
)
{
const
double
abs_err
)
{
MACE_UNUSED
(
rel_err
);
MACE_UNUSED
(
abs_err
);
Equal
(
x
,
y
);
Equal
(
x
,
y
);
}
}
};
};
...
...
mace/public/mace.h
浏览文件 @
bdaa5c18
...
@@ -56,7 +56,11 @@ class RunMetadata {
...
@@ -56,7 +56,11 @@ class RunMetadata {
const
char
*
MaceVersion
();
const
char
*
MaceVersion
();
enum
MaceStatus
{
MACE_SUCCESS
=
0
,
MACE_INVALID_ARGS
=
1
};
enum
MaceStatus
{
MACE_SUCCESS
=
0
,
MACE_INVALID_ARGS
=
1
,
MACE_OUT_OF_RESOURCES
=
2
};
// MACE input/output tensor
// MACE input/output tensor
class
MaceTensor
{
class
MaceTensor
{
...
@@ -84,13 +88,14 @@ class MaceTensor {
...
@@ -84,13 +88,14 @@ class MaceTensor {
class
MaceEngine
{
class
MaceEngine
{
public:
public:
explicit
MaceEngine
(
const
NetDef
*
net_def
,
explicit
MaceEngine
(
DeviceType
device_type
);
DeviceType
device_type
,
const
std
::
vector
<
std
::
string
>
&
input_nodes
,
const
std
::
vector
<
std
::
string
>
&
output_nodes
,
const
unsigned
char
*
model_data
);
~
MaceEngine
();
~
MaceEngine
();
MaceStatus
Init
(
const
NetDef
*
net_def
,
const
std
::
vector
<
std
::
string
>
&
input_nodes
,
const
std
::
vector
<
std
::
string
>
&
output_nodes
,
const
unsigned
char
*
model_data
);
MaceStatus
Run
(
const
std
::
map
<
std
::
string
,
MaceTensor
>
&
inputs
,
MaceStatus
Run
(
const
std
::
map
<
std
::
string
,
MaceTensor
>
&
inputs
,
std
::
map
<
std
::
string
,
MaceTensor
>
*
outputs
);
std
::
map
<
std
::
string
,
MaceTensor
>
*
outputs
);
...
...
mace/python/tools/converter.py
浏览文件 @
bdaa5c18
...
@@ -128,7 +128,7 @@ def main(unused_args):
...
@@ -128,7 +128,7 @@ def main(unused_args):
FLAGS
.
weight_file
)
FLAGS
.
weight_file
)
output_graph_def
=
converter
.
run
()
output_graph_def
=
converter
.
run
()
print
(
"Transform model to one that can better run on device
.
"
)
print
(
"Transform model to one that can better run on device"
)
if
not
FLAGS
.
runtime
:
if
not
FLAGS
.
runtime
:
cpu_graph_def
=
copy
.
deepcopy
(
output_graph_def
)
cpu_graph_def
=
copy
.
deepcopy
(
output_graph_def
)
option
.
device
=
mace_pb2
.
CPU
option
.
device
=
mace_pb2
.
CPU
...
...
mace/python/tools/converter_tool/base_converter.py
浏览文件 @
bdaa5c18
...
@@ -136,23 +136,25 @@ class MaceKeyword(object):
...
@@ -136,23 +136,25 @@ class MaceKeyword(object):
class
TransformerRule
(
Enum
):
class
TransformerRule
(
Enum
):
REMOVE_IDENTITY_OP
=
0
REMOVE_USELESS_RESHAPE_OP
=
0
TRANSFORM_GLOBAL_POOLING
=
1
REMOVE_IDENTITY_OP
=
1
FOLD_SOFTMAX
=
2
TRANSFORM_GLOBAL_POOLING
=
2
FOLD_BATCHNORM
=
3
,
FOLD_RESHAPE
=
3
FOLD_CONV_AND_BN
=
4
,
TRANSFORM_MATMUL_TO_FC
=
4
FOLD_DEPTHWISE_CONV_AND_BN
=
5
,
FOLD_BATCHNORM
=
5
TRANSFORM_GPU_WINOGRAD
=
6
,
FOLD_CONV_AND_BN
=
6
TRANSFORM_ADD_TO_BIASADD
=
7
,
FOLD_DEPTHWISE_CONV_AND_BN
=
7
FOLD_BIASADD
=
8
,
TRANSFORM_GPU_WINOGRAD
=
8
FOLD_ACTIVATION
=
9
,
TRANSFORM_ADD_TO_BIASADD
=
9
TRANSPOSE_FILTERS
=
10
,
FOLD_BIASADD
=
10
RESHAPE_FC_WEIGHT
=
11
,
FOLD_ACTIVATION
=
11
TRANSPOSE_DATA_FORMAT
=
12
,
TRANSPOSE_FILTERS
=
12
TRANSFORM_GLOBAL_CONV_TO_FC
=
13
,
RESHAPE_FC_WEIGHT
=
13
TRANSFORM_BUFFER_IMAGE
=
14
,
TRANSPOSE_DATA_FORMAT
=
14
ADD_DEVICE_AND_DATA_TYPE
=
15
,
TRANSFORM_GLOBAL_CONV_TO_FC
=
15
SORT_BY_EXECUTION
=
16
TRANSFORM_BUFFER_IMAGE
=
16
ADD_DEVICE_AND_DATA_TYPE
=
17
SORT_BY_EXECUTION
=
18
class
ConverterInterface
(
object
):
class
ConverterInterface
(
object
):
...
@@ -199,9 +201,11 @@ class ConverterOption(object):
...
@@ -199,9 +201,11 @@ class ConverterOption(object):
self
.
_device
=
mace_pb2
.
CPU
self
.
_device
=
mace_pb2
.
CPU
self
.
_winograd_enabled
=
False
self
.
_winograd_enabled
=
False
self
.
_transformer_option
=
[
self
.
_transformer_option
=
[
TransformerRule
.
REMOVE_USELESS_RESHAPE_OP
,
TransformerRule
.
REMOVE_IDENTITY_OP
,
TransformerRule
.
REMOVE_IDENTITY_OP
,
TransformerRule
.
TRANSFORM_GLOBAL_POOLING
,
TransformerRule
.
TRANSFORM_GLOBAL_POOLING
,
TransformerRule
.
FOLD_SOFTMAX
,
TransformerRule
.
FOLD_RESHAPE
,
TransformerRule
.
TRANSFORM_MATMUL_TO_FC
,
TransformerRule
.
FOLD_BATCHNORM
,
TransformerRule
.
FOLD_BATCHNORM
,
TransformerRule
.
FOLD_CONV_AND_BN
,
TransformerRule
.
FOLD_CONV_AND_BN
,
TransformerRule
.
FOLD_DEPTHWISE_CONV_AND_BN
,
TransformerRule
.
FOLD_DEPTHWISE_CONV_AND_BN
,
...
...
mace/python/tools/converter_tool/tensorflow_converter.py
浏览文件 @
bdaa5c18
...
@@ -101,9 +101,11 @@ class TensorflowConverter(base_converter.ConverterInterface):
...
@@ -101,9 +101,11 @@ class TensorflowConverter(base_converter.ConverterInterface):
'AvgPool'
:
self
.
convert_pooling
,
'AvgPool'
:
self
.
convert_pooling
,
'MaxPool'
:
self
.
convert_pooling
,
'MaxPool'
:
self
.
convert_pooling
,
'Squeeze'
:
self
.
convert_identity
,
'Squeeze'
:
self
.
convert_identity
,
'MatMul'
:
self
.
convert_matmul
,
'Identity'
:
self
.
convert_identity
,
'Identity'
:
self
.
convert_identity
,
'Reshape'
:
self
.
convert_reshape
,
'Reshape'
:
self
.
convert_reshape
,
'Shape'
:
self
.
convert_nop
,
'Shape'
:
self
.
convert_nop
,
'Transpose'
:
self
.
convert_transpose
,
'Softmax'
:
self
.
convert_softmax
,
'Softmax'
:
self
.
convert_softmax
,
'ResizeBilinear'
:
self
.
convert_resize_bilinear
,
'ResizeBilinear'
:
self
.
convert_resize_bilinear
,
'Placeholder'
:
self
.
convert_nop
,
'Placeholder'
:
self
.
convert_nop
,
...
@@ -144,7 +146,8 @@ class TensorflowConverter(base_converter.ConverterInterface):
...
@@ -144,7 +146,8 @@ class TensorflowConverter(base_converter.ConverterInterface):
for
i
in
xrange
(
len
(
op
.
input
)):
for
i
in
xrange
(
len
(
op
.
input
)):
if
op
.
input
[
i
][
-
2
:]
==
':0'
:
if
op
.
input
[
i
][
-
2
:]
==
':0'
:
op_name
=
op
.
input
[
i
][:
-
2
]
op_name
=
op
.
input
[
i
][:
-
2
]
if
op_name
in
self
.
_option
.
input_nodes
:
if
op_name
in
self
.
_option
.
input_nodes
\
or
op_name
in
self
.
_option
.
output_nodes
:
op
.
input
[
i
]
=
op_name
op
.
input
[
i
]
=
op_name
for
i
in
xrange
(
len
(
op
.
output
)):
for
i
in
xrange
(
len
(
op
.
output
)):
if
op
.
output
[
i
][
-
2
:]
==
':0'
:
if
op
.
output
[
i
][
-
2
:]
==
':0'
:
...
@@ -411,6 +414,10 @@ class TensorflowConverter(base_converter.ConverterInterface):
...
@@ -411,6 +414,10 @@ class TensorflowConverter(base_converter.ConverterInterface):
self
.
_skip_tensor
.
update
(
tf_op
.
inputs
[
-
1
].
name
)
self
.
_skip_tensor
.
update
(
tf_op
.
inputs
[
-
1
].
name
)
def
convert_matmul
(
self
,
tf_op
):
op
=
self
.
convert_general_op
(
tf_op
)
op
.
type
=
MaceOp
.
MatMul
.
name
def
convert_reshape
(
self
,
tf_op
):
def
convert_reshape
(
self
,
tf_op
):
op
=
self
.
convert_general_op
(
tf_op
)
op
=
self
.
convert_general_op
(
tf_op
)
op
.
type
=
MaceOp
.
Reshape
.
name
op
.
type
=
MaceOp
.
Reshape
.
name
...
@@ -430,6 +437,20 @@ class TensorflowConverter(base_converter.ConverterInterface):
...
@@ -430,6 +437,20 @@ class TensorflowConverter(base_converter.ConverterInterface):
shape_arg
.
ints
.
extend
(
shape_value
)
shape_arg
.
ints
.
extend
(
shape_value
)
def
convert_transpose
(
self
,
tf_op
):
perm
=
tf_op
.
inputs
[
1
].
eval
().
astype
(
np
.
int32
)
ordered_perm
=
np
.
sort
(
perm
)
mace_check
(
np
.
array_equal
(
perm
,
ordered_perm
),
"Transpose not supported yet, only internal transpose"
" in composed ops might be supported"
)
op
=
self
.
convert_general_op
(
tf_op
)
op
.
type
=
'Identity'
del
op
.
input
[
1
:]
self
.
_skip_tensor
.
add
(
tf_op
.
inputs
[
1
].
name
)
def
convert_mean
(
self
,
tf_op
):
def
convert_mean
(
self
,
tf_op
):
op
=
self
.
convert_general_op
(
tf_op
)
op
=
self
.
convert_general_op
(
tf_op
)
del
op
.
input
[
1
:]
del
op
.
input
[
1
:]
...
...
mace/python/tools/converter_tool/transformer.py
浏览文件 @
bdaa5c18
...
@@ -53,9 +53,11 @@ class Transformer(base_converter.ConverterInterface):
...
@@ -53,9 +53,11 @@ class Transformer(base_converter.ConverterInterface):
def
__init__
(
self
,
option
,
model
):
def
__init__
(
self
,
option
,
model
):
# DO NOT reorder the following transformers
# DO NOT reorder the following transformers
self
.
_registered_transformers_order
=
[
self
.
_registered_transformers_order
=
[
TransformerRule
.
REMOVE_USELESS_RESHAPE_OP
,
TransformerRule
.
REMOVE_IDENTITY_OP
,
TransformerRule
.
REMOVE_IDENTITY_OP
,
TransformerRule
.
TRANSFORM_GLOBAL_POOLING
,
TransformerRule
.
TRANSFORM_GLOBAL_POOLING
,
TransformerRule
.
FOLD_SOFTMAX
,
TransformerRule
.
FOLD_RESHAPE
,
TransformerRule
.
TRANSFORM_MATMUL_TO_FC
,
TransformerRule
.
FOLD_BATCHNORM
,
TransformerRule
.
FOLD_BATCHNORM
,
TransformerRule
.
FOLD_CONV_AND_BN
,
TransformerRule
.
FOLD_CONV_AND_BN
,
TransformerRule
.
FOLD_DEPTHWISE_CONV_AND_BN
,
TransformerRule
.
FOLD_DEPTHWISE_CONV_AND_BN
,
...
@@ -72,10 +74,14 @@ class Transformer(base_converter.ConverterInterface):
...
@@ -72,10 +74,14 @@ class Transformer(base_converter.ConverterInterface):
TransformerRule
.
SORT_BY_EXECUTION
,
TransformerRule
.
SORT_BY_EXECUTION
,
]
]
self
.
_registered_transformers
=
{
self
.
_registered_transformers
=
{
TransformerRule
.
REMOVE_USELESS_RESHAPE_OP
:
self
.
remove_useless_reshape_op
,
TransformerRule
.
REMOVE_IDENTITY_OP
:
self
.
remove_identity_op
,
TransformerRule
.
REMOVE_IDENTITY_OP
:
self
.
remove_identity_op
,
TransformerRule
.
TRANSFORM_GLOBAL_POOLING
:
TransformerRule
.
TRANSFORM_GLOBAL_POOLING
:
self
.
transform_global_pooling
,
self
.
transform_global_pooling
,
TransformerRule
.
FOLD_SOFTMAX
:
self
.
fold_softmax
,
TransformerRule
.
FOLD_RESHAPE
:
self
.
fold_reshape
,
TransformerRule
.
TRANSFORM_MATMUL_TO_FC
:
self
.
transform_matmul_to_fc
,
TransformerRule
.
FOLD_BATCHNORM
:
self
.
fold_batchnorm
,
TransformerRule
.
FOLD_BATCHNORM
:
self
.
fold_batchnorm
,
TransformerRule
.
FOLD_CONV_AND_BN
:
TransformerRule
.
FOLD_CONV_AND_BN
:
self
.
fold_conv_and_bn
,
# data_format related
self
.
fold_conv_and_bn
,
# data_format related
...
@@ -161,18 +167,26 @@ class Transformer(base_converter.ConverterInterface):
...
@@ -161,18 +167,26 @@ class Transformer(base_converter.ConverterInterface):
for
output_tensor
in
op
.
output
:
for
output_tensor
in
op
.
output
:
self
.
_producer
[
output_tensor
]
=
op
self
.
_producer
[
output_tensor
]
=
op
for
input_node
in
self
.
_option
.
input_nodes
.
values
():
for
input_node
in
self
.
_option
.
input_nodes
.
values
():
op
=
mace_pb2
.
OperatorDef
()
input_node_existed
=
False
op
.
name
=
self
.
normalize_op_name
(
input_node
.
name
)
for
op
in
self
.
_model
.
op
:
op
.
type
=
'Input'
if
input_node
.
name
in
op
.
output
:
op
.
output
.
extend
(
input_node
.
name
)
input_node_existed
=
True
output_shape
=
op
.
output_shape
.
add
()
break
output_shape
.
dims
.
extend
(
input_node
.
shape
)
if
not
input_node_existed
:
if
self
.
_option
.
device
==
mace_pb2
.
CPU
:
op
=
mace_pb2
.
OperatorDef
()
self
.
transpose_shape
(
output_shape
.
dims
,
[
0
,
3
,
1
,
2
])
op
.
name
=
self
.
normalize_op_name
(
input_node
.
name
)
ConverterUtil
.
add_data_format_arg
(
op
,
DataFormat
.
NCHW
)
op
.
type
=
'Input'
else
:
op
.
output
.
extend
([
input_node
.
name
])
ConverterUtil
.
add_data_format_arg
(
op
,
DataFormat
.
NHWC
)
output_shape
=
op
.
output_shape
.
add
()
self
.
_producer
[
op
.
output
[
0
]]
=
op
output_shape
.
dims
.
extend
(
input_node
.
shape
)
if
ConverterUtil
.
data_format
(
self
.
_consumers
[
input_node
.
name
][
0
])
\
==
DataFormat
.
NCHW
:
self
.
transpose_shape
(
output_shape
.
dims
,
[
0
,
3
,
1
,
2
])
ConverterUtil
.
add_data_format_arg
(
op
,
DataFormat
.
NCHW
)
else
:
ConverterUtil
.
add_data_format_arg
(
op
,
DataFormat
.
NHWC
)
self
.
_producer
[
op
.
output
[
0
]]
=
op
@
staticmethod
@
staticmethod
def
replace
(
obj_list
,
source
,
target
):
def
replace
(
obj_list
,
source
,
target
):
...
@@ -191,6 +205,12 @@ class Transformer(base_converter.ConverterInterface):
...
@@ -191,6 +205,12 @@ class Transformer(base_converter.ConverterInterface):
def
normalize_op_name
(
name
):
def
normalize_op_name
(
name
):
return
name
.
replace
(
':'
,
'_'
)
return
name
.
replace
(
':'
,
'_'
)
def
get_tensor_shape
(
self
,
tensor
):
producer
=
self
.
_producer
[
tensor
]
for
i
in
xrange
(
len
(
producer
.
output
)):
if
producer
.
output
[
i
]
==
tensor
:
return
list
(
producer
.
output_shape
[
i
].
dims
)
def
consumer_count
(
self
,
tensor_name
):
def
consumer_count
(
self
,
tensor_name
):
return
len
(
self
.
_consumers
.
get
(
tensor_name
,
[]))
return
len
(
self
.
_consumers
.
get
(
tensor_name
,
[]))
...
@@ -203,23 +223,68 @@ class Transformer(base_converter.ConverterInterface):
...
@@ -203,23 +223,68 @@ class Transformer(base_converter.ConverterInterface):
return
False
return
False
def
replace_output_node
(
self
,
op
):
def
safe_remove_node
(
self
,
op
,
replace_op
):
"""if it is an output node, change output node to the op before it"""
"""remove op.
if
self
.
is_op_output_node
(
op
):
1. change the inputs of its consumers to the outputs of replace_op
real_output_node
=
self
.
_producer
[
op
.
input
[
0
]]
2. if the op is output node, change output node to replace op"""
self
.
replace
(
real_output_node
.
output
,
op
.
input
[
0
],
op
.
output
[
0
])
print
(
"change %s to %s"
%
(
real_output_node
.
name
,
op
.
name
))
if
replace_op
is
None
:
# When no replace op specified, we change the inputs of
# its consumers to the input of the op. This handles the case
# that the op is identity op and its input is a tensor.
mace_check
(
len
(
op
.
output
)
==
1
and
len
(
op
.
input
)
==
1
,
"cannot remove op that w/o replace op specified"
" and input/output length > 1"
+
str
(
op
))
for
consumer_op
in
self
.
_consumers
.
get
(
op
.
output
[
0
],
[]):
self
.
replace
(
consumer_op
.
input
,
op
.
output
[
0
],
op
.
input
[
0
])
mace_check
(
op
.
output
[
0
]
not
in
self
.
_option
.
output_nodes
,
"cannot remove op that is output node"
)
else
:
mace_check
(
len
(
op
.
output
)
==
len
(
replace_op
.
output
),
"cannot remove op since len(op.output) "
"!= len(replace_op.output)"
)
for
i
in
xrange
(
len
(
op
.
output
)):
for
consumer_op
in
self
.
_consumers
.
get
(
op
.
output
[
i
],
[]):
self
.
replace
(
consumer_op
.
input
,
op
.
output
[
i
],
replace_op
.
output
[
i
])
# if the op is output node, change replace_op output name to the op
# output name
for
i
in
xrange
(
len
(
op
.
output
)):
if
op
.
output
[
i
]
in
self
.
_option
.
output_nodes
:
for
consumer
in
self
.
_consumers
.
get
(
replace_op
.
output
[
i
],
[]):
self
.
replace
(
consumer
.
input
,
replace_op
.
output
[
i
],
op
.
output
[
i
])
replace_op
.
output
[
i
]
=
op
.
output
[
i
]
self
.
_model
.
op
.
remove
(
op
)
def
remove_useless_reshape_op
(
self
):
net
=
self
.
_model
for
op
in
net
.
op
:
if
op
.
type
==
MaceOp
.
Reshape
.
name
:
shape
=
list
(
ConverterUtil
.
get_arg
(
op
,
MaceKeyword
.
mace_shape_str
).
ints
)
if
shape
==
self
.
get_tensor_shape
(
op
.
input
[
0
]):
print
(
"Remove useless reshape: %s(%s)"
%
(
op
.
name
,
op
.
type
))
op
.
type
=
'Identity'
return
False
def
remove_identity_op
(
self
):
def
remove_identity_op
(
self
):
net
=
self
.
_model
net
=
self
.
_model
for
op
in
net
.
op
:
for
op
in
net
.
op
:
if
op
.
type
==
'Identity'
:
if
op
.
type
==
'Identity'
:
print
(
"Remove identity: %s(%s)"
%
(
op
.
name
,
op
.
type
))
print
(
"Remove identity: %s(%s)"
%
(
op
.
name
,
op
.
type
))
for
consumer_op
in
self
.
_consumers
.
get
(
op
.
output
[
0
],
[]):
self
.
safe_remove_node
(
op
,
Transformer
.
replace
(
consumer_op
.
input
,
op
.
output
[
0
],
self
.
_producer
.
get
(
op
.
input
[
0
],
None
))
op
.
input
[
0
])
self
.
replace_output_node
(
op
)
net
.
op
.
remove
(
op
)
return
True
return
True
return
False
return
False
...
@@ -264,10 +329,10 @@ class Transformer(base_converter.ConverterInterface):
...
@@ -264,10 +329,10 @@ class Transformer(base_converter.ConverterInterface):
and
len
(
self
.
_consts
[
consumer_op
.
input
[
1
]].
dims
)
==
1
:
and
len
(
self
.
_consts
[
consumer_op
.
input
[
1
]].
dims
)
==
1
:
print
(
"Fold batchnorm: %s(%s)"
%
(
op
.
name
,
op
.
type
))
print
(
"Fold batchnorm: %s(%s)"
%
(
op
.
name
,
op
.
type
))
consumer_op
.
type
=
MaceOp
.
FoldedBatchNorm
.
name
consumer_op
.
type
=
MaceOp
.
FoldedBatchNorm
.
name
inputs
=
[
op
.
input
[
0
],
op
.
input
[
1
],
consumer_op
.
input
[
1
]]
consumer_op
.
input
[:]
=
[
op
.
input
[
0
],
op
.
input
[
1
],
consumer_op
.
input
[:]
=
inputs
[:
]
consumer_op
.
input
[
1
]
]
net
.
op
.
remove
(
op
)
self
.
safe_remove_node
(
op
,
None
)
return
True
return
True
return
False
return
False
...
@@ -514,7 +579,7 @@ class Transformer(base_converter.ConverterInterface):
...
@@ -514,7 +579,7 @@ class Transformer(base_converter.ConverterInterface):
filter
.
float_data
[:]
=
weight_tensor_value
.
flat
[:]
filter
.
float_data
[:]
=
weight_tensor_value
.
flat
[:]
filter
.
dims
[:]
=
weight_tensor_value
.
shape
[:]
filter
.
dims
[:]
=
weight_tensor_value
.
shape
[:]
net
.
op
.
remove
(
op
)
self
.
safe_remove_node
(
op
,
iwt_
op
)
return
False
return
False
...
@@ -544,10 +609,8 @@ class Transformer(base_converter.ConverterInterface):
...
@@ -544,10 +609,8 @@ class Transformer(base_converter.ConverterInterface):
consumer_op
=
self
.
_consumers
[
op
.
output
[
0
]][
0
]
consumer_op
=
self
.
_consumers
[
op
.
output
[
0
]][
0
]
if
consumer_op
.
type
==
MaceOp
.
BiasAdd
.
name
:
if
consumer_op
.
type
==
MaceOp
.
BiasAdd
.
name
:
print
(
"Fold biasadd: %s(%s)"
%
(
op
.
name
,
op
.
type
))
print
(
"Fold biasadd: %s(%s)"
%
(
op
.
name
,
op
.
type
))
op
.
name
=
consumer_op
.
name
op
.
input
.
append
(
consumer_op
.
input
[
1
])
op
.
input
.
append
(
consumer_op
.
input
[
1
])
op
.
output
[
0
]
=
consumer_op
.
output
[
0
]
self
.
safe_remove_node
(
consumer_op
,
op
)
net
.
op
.
remove
(
consumer_op
)
return
True
return
True
return
False
return
False
...
@@ -575,7 +638,7 @@ class Transformer(base_converter.ConverterInterface):
...
@@ -575,7 +638,7 @@ class Transformer(base_converter.ConverterInterface):
or
arg
.
name
==
MaceKeyword
.
mace_activation_max_limit_str
:
# noqa
or
arg
.
name
==
MaceKeyword
.
mace_activation_max_limit_str
:
# noqa
op
.
arg
.
extend
([
arg
])
op
.
arg
.
extend
([
arg
])
net
.
op
.
remove
(
consumer_
op
)
self
.
safe_remove_node
(
consumer_op
,
op
)
return
True
return
True
return
False
return
False
...
@@ -651,11 +714,14 @@ class Transformer(base_converter.ConverterInterface):
...
@@ -651,11 +714,14 @@ class Transformer(base_converter.ConverterInterface):
op
.
output
.
extend
([
input_node
.
name
])
op
.
output
.
extend
([
input_node
.
name
])
output_shape
=
op
.
output_shape
.
add
()
output_shape
=
op
.
output_shape
.
add
()
output_shape
.
dims
.
extend
(
input_node
.
shape
)
output_shape
.
dims
.
extend
(
input_node
.
shape
)
self
.
transpose_shape
(
output_shape
.
dims
,
[
0
,
3
,
1
,
2
])
dims_arg
=
op
.
arg
.
add
()
dims_arg
=
op
.
arg
.
add
()
dims_arg
.
name
=
MaceKeyword
.
mace_dims_str
dims_arg
.
name
=
MaceKeyword
.
mace_dims_str
dims_arg
.
ints
.
extend
([
0
,
3
,
1
,
2
])
dims_arg
.
ints
.
extend
([
0
,
3
,
1
,
2
])
ConverterUtil
.
add_data_format_arg
(
op
,
DataFormat
.
NCHW
)
for
output_node
in
self
.
_option
.
output_nodes
.
values
():
for
output_node
in
self
.
_option
.
output_nodes
.
values
():
output_name
=
MaceKeyword
.
mace_output_node_name
\
output_name
=
MaceKeyword
.
mace_output_node_name
\
+
'_'
+
output_node
.
name
+
'_'
+
output_node
.
name
...
@@ -673,6 +739,8 @@ class Transformer(base_converter.ConverterInterface):
...
@@ -673,6 +739,8 @@ class Transformer(base_converter.ConverterInterface):
dims_arg
.
name
=
MaceKeyword
.
mace_dims_str
dims_arg
.
name
=
MaceKeyword
.
mace_dims_str
dims_arg
.
ints
.
extend
([
0
,
2
,
3
,
1
])
dims_arg
.
ints
.
extend
([
0
,
2
,
3
,
1
])
ConverterUtil
.
add_data_format_arg
(
op
,
DataFormat
.
NHWC
)
return
False
return
False
def
transpose_filters
(
self
):
def
transpose_filters
(
self
):
...
@@ -695,21 +763,29 @@ class Transformer(base_converter.ConverterInterface):
...
@@ -695,21 +763,29 @@ class Transformer(base_converter.ConverterInterface):
filter_data
=
filter_data
.
transpose
(
3
,
2
,
0
,
1
)
filter_data
=
filter_data
.
transpose
(
3
,
2
,
0
,
1
)
filter
.
float_data
[:]
=
filter_data
.
flat
filter
.
float_data
[:]
=
filter_data
.
flat
filter
.
dims
[:]
=
filter_data
.
shape
filter
.
dims
[:]
=
filter_data
.
shape
if
op
.
type
==
MaceOp
.
FullyConnected
.
name
:
weight
=
self
.
_consts
[
op
.
input
[
1
]]
weight_data
=
np
.
array
(
weight
.
float_data
).
reshape
(
weight
.
dims
)
weight_data
=
weight_data
.
transpose
(
1
,
0
)
weight
.
float_data
[:]
=
weight_data
.
flat
weight
.
dims
[:]
=
weight_data
.
shape
self
.
set_filter_format
(
FilterFormat
.
OIHW
)
self
.
set_filter_format
(
FilterFormat
.
OIHW
)
return
False
return
False
def
reshape_fc_weight
(
self
):
def
reshape_fc_weight
(
self
):
print
(
"Reshape fully connected weight shape"
)
net
=
self
.
_model
net
=
self
.
_model
for
op
in
net
.
op
:
for
op
in
net
.
op
:
if
op
.
type
==
MaceOp
.
FullyConnected
.
name
:
if
op
.
type
==
MaceOp
.
FullyConnected
.
name
:
weight
=
self
.
_consts
[
op
.
input
[
1
]]
weight
=
self
.
_consts
[
op
.
input
[
1
]]
# NCHW
input_op
=
self
.
_producer
[
op
.
input
[
0
]]
input_shape
=
list
(
self
.
_producer
[
op
.
input
[
0
]]
input_shape
=
list
(
input_op
.
output_shape
[
0
].
dims
)
.
output_shape
[
0
].
dims
)
input_data_format
=
ConverterUtil
.
data_format
(
input_op
)
weight
_shape
=
[
weight
.
dims
[
0
]]
+
input_shape
[
1
:]
weight
.
dims
[:]
=
[
weight
.
dims
[
0
]]
+
input_shape
[
1
:]
del
weight
.
dims
[:]
if
input_data_format
==
DataFormat
.
NHWC
:
weight
.
dims
.
extend
(
weight_shape
)
self
.
transpose_shape
(
weight
.
dims
,
[
0
,
3
,
1
,
2
]
)
return
False
return
False
...
@@ -788,6 +864,8 @@ class Transformer(base_converter.ConverterInterface):
...
@@ -788,6 +864,8 @@ class Transformer(base_converter.ConverterInterface):
arg
.
name
=
MaceKeyword
.
mace_buffer_type
arg
.
name
=
MaceKeyword
.
mace_buffer_type
arg
.
i
=
OpenCLBufferType
.
IN_OUT_CHANNEL
.
value
arg
.
i
=
OpenCLBufferType
.
IN_OUT_CHANNEL
.
value
ConverterUtil
.
add_data_format_arg
(
op_def
,
DataFormat
.
NHWC
)
for
output_node
in
self
.
_option
.
output_nodes
.
values
():
for
output_node
in
self
.
_option
.
output_nodes
.
values
():
output_name
=
MaceKeyword
.
mace_output_node_name
\
output_name
=
MaceKeyword
.
mace_output_node_name
\
+
'_'
+
output_node
.
name
+
'_'
+
output_node
.
name
...
@@ -803,14 +881,16 @@ class Transformer(base_converter.ConverterInterface):
...
@@ -803,14 +881,16 @@ class Transformer(base_converter.ConverterInterface):
arg
.
name
=
MaceKeyword
.
mace_buffer_type
arg
.
name
=
MaceKeyword
.
mace_buffer_type
arg
.
i
=
OpenCLBufferType
.
IN_OUT_CHANNEL
.
value
arg
.
i
=
OpenCLBufferType
.
IN_OUT_CHANNEL
.
value
ConverterUtil
.
add_data_format_arg
(
op_def
,
DataFormat
.
NHWC
)
return
False
return
False
def
fold_
softmax
(
self
):
def
fold_
reshape
(
self
):
changed
=
False
changed
=
False
net
=
self
.
_model
net
=
self
.
_model
for
op
in
net
.
op
:
for
op
in
net
.
op
:
if
op
.
type
==
MaceOp
.
Softmax
.
name
:
if
op
.
type
==
MaceOp
.
Softmax
.
name
or
op
.
type
==
MaceOp
.
MatMul
.
name
:
print
(
"Fold
softmax
: %s(%s)"
%
(
op
.
name
,
op
.
type
))
print
(
"Fold
reshape
: %s(%s)"
%
(
op
.
name
,
op
.
type
))
if
self
.
consumer_count
(
op
.
output
[
0
])
==
1
:
if
self
.
consumer_count
(
op
.
output
[
0
])
==
1
:
consumer
=
self
.
_consumers
[
op
.
output
[
0
]][
0
]
consumer
=
self
.
_consumers
[
op
.
output
[
0
]][
0
]
if
consumer
.
type
==
MaceOp
.
Reshape
.
name
:
if
consumer
.
type
==
MaceOp
.
Reshape
.
name
:
...
@@ -818,15 +898,14 @@ class Transformer(base_converter.ConverterInterface):
...
@@ -818,15 +898,14 @@ class Transformer(base_converter.ConverterInterface):
MaceKeyword
.
mace_shape_str
).
ints
# noqa
MaceKeyword
.
mace_shape_str
).
ints
# noqa
del
op
.
output_shape
[
0
].
dims
[:]
del
op
.
output_shape
[
0
].
dims
[:]
op
.
output_shape
[
0
].
dims
.
extend
(
shape
)
op
.
output_shape
[
0
].
dims
.
extend
(
shape
)
self
.
replace_output_node
(
consumer
)
self
.
safe_remove_node
(
consumer
,
op
)
net
.
op
.
remove
(
consumer
)
changed
=
True
changed
=
True
producer
=
self
.
_producer
[
op
.
input
[
0
]]
producer
=
self
.
_producer
[
op
.
input
[
0
]]
if
producer
.
type
==
MaceOp
.
Reshape
.
name
:
if
producer
.
type
==
MaceOp
.
Reshape
.
name
:
op
.
input
[
0
]
=
producer
.
input
[
0
]
self
.
safe_remove_node
(
producer
,
self
.
replace_output_node
(
producer
)
self
.
_producer
[
net
.
op
.
remove
(
producer
)
producer
.
input
[
0
]]
)
changed
=
True
changed
=
True
if
len
(
op
.
output_shape
[
0
].
dims
)
<
4
:
if
len
(
op
.
output_shape
[
0
].
dims
)
<
4
:
...
@@ -839,6 +918,20 @@ class Transformer(base_converter.ConverterInterface):
...
@@ -839,6 +918,20 @@ class Transformer(base_converter.ConverterInterface):
return
False
return
False
def
transform_matmul_to_fc
(
self
):
net
=
self
.
_model
for
op
in
net
.
op
:
if
op
.
type
==
MaceOp
.
MatMul
.
name
:
input_shape
=
self
.
get_tensor_shape
(
op
.
input
[
0
])
_
,
h
,
w
,
_
=
self
.
sort_feature_map_shape
(
input_shape
,
ConverterUtil
.
data_format
(
self
.
_producer
[
op
.
input
[
0
]]))
# noqa
if
h
==
1
and
w
==
1
and
op
.
input
[
1
]
in
self
.
_consts
:
weight
=
self
.
_consts
[
op
.
input
[
1
]]
if
len
(
weight
.
dims
)
==
2
:
op
.
type
=
MaceOp
.
FullyConnected
.
name
return
False
def
transform_global_conv_to_fc
(
self
):
def
transform_global_conv_to_fc
(
self
):
"""Transform global conv to fc should be placed after transposing
"""Transform global conv to fc should be placed after transposing
input/output and filter"""
input/output and filter"""
...
@@ -917,4 +1010,8 @@ class Transformer(base_converter.ConverterInterface):
...
@@ -917,4 +1010,8 @@ class Transformer(base_converter.ConverterInterface):
del
net
.
op
[:]
del
net
.
op
[:]
net
.
op
.
extend
(
sorted_nodes
)
net
.
op
.
extend
(
sorted_nodes
)
print
(
"Final ops:"
)
for
op
in
net
.
op
:
print
(
"%s (%s)"
%
(
op
.
name
,
op
.
type
))
return
False
return
False
mace/python/tools/mace_engine_factory.h.jinja2
浏览文件 @
bdaa5c18
...
@@ -64,26 +64,25 @@ MaceStatus CreateMaceEngineFromCode(
...
@@ -64,26 +64,25 @@ MaceStatus CreateMaceEngineFromCode(
}
}
const unsigned char * model_data = nullptr;
const unsigned char * model_data = nullptr;
NetDef net_def;
NetDef net_def;
MaceStatus status = MaceStatus::MACE_SUCCESS;
switch (model_name_map[model_name]) {
switch (model_name_map[model_name]) {
{% for i in range(model_tags |length) %}
{% for i in range(model_tags |length) %}
case {{ i }}:
case {{ i }}:
model_data =
model_data =
mace::{{model_tags[i]}}::LoadModelData(model_data_file);
mace::{{model_tags[i]}}::LoadModelData(model_data_file);
net_def = mace::{{model_tags[i]}}::CreateNet();
net_def = mace::{{model_tags[i]}}::CreateNet();
engine->reset(new mace::MaceEngine(device_type));
engine->reset(
status = (*engine)->Init(&net_def, input_nodes, output_nodes, model_data);
new mace::MaceEngine(&net_def, device_type, input_nodes, output_nodes,
model_data));
if (device_type == DeviceType::GPU || device_type == DeviceType::HEXAGON) {
if (device_type == DeviceType::GPU || device_type == DeviceType::HEXAGON) {
mace::{{model_tags[i]}}::UnloadModelData(model_data);
mace::{{model_tags[i]}}::UnloadModelData(model_data);
}
}
break;
break;
{% endfor %}
{% endfor %}
default:
default:
return
MaceStatus::MACE_INVALID_ARGS;
status =
MaceStatus::MACE_INVALID_ARGS;
}
}
return
MaceStatus::MACE_SUCCESS
;
return
status
;
}
}
{% else %}
{% else %}
MaceStatus CreateMaceEngineFromCode(
MaceStatus CreateMaceEngineFromCode(
...
...
mace/python/tools/tf_dsp_converter_lib.py
浏览文件 @
bdaa5c18
...
@@ -95,12 +95,19 @@ def add_shape_const_node(net_def, op, values, name):
...
@@ -95,12 +95,19 @@ def add_shape_const_node(net_def, op, values, name):
def
convert_op_outputs
(
mace_op_def
,
tf_op
):
def
convert_op_outputs
(
mace_op_def
,
tf_op
):
mace_op_def
.
out_max_byte_size
.
extend
(
[
max_elem_size
(
output
)
for
output
in
tf_op
.
outputs
])
mace_op_def
.
output_type
.
extend
(
mace_op_def
.
output_type
.
extend
(
[
tf_dtype_2_mace_dtype
(
output
.
dtype
)
for
output
in
tf_op
.
outputs
])
[
tf_dtype_2_mace_dtype
(
output
.
dtype
)
for
output
in
tf_op
.
outputs
])
output_shapes
=
[]
output_shapes
=
[]
for
output
in
tf_op
.
outputs
:
for
output
in
tf_op
.
outputs
:
output_shape
=
mace_pb2
.
OutputShape
()
output_shape
=
mace_pb2
.
OutputShape
()
output_shape
.
dims
.
extend
(
output
.
shape
.
as_list
())
shape_list
=
output
.
shape
.
as_list
()
if
not
shape_list
:
shape_list
=
[
1
]
elif
len
(
shape_list
)
==
2
:
shape_list
=
[
1
,
1
,
shape_list
[
0
],
shape_list
[
1
]]
output_shape
.
dims
.
extend
(
shape_list
)
output_shapes
.
append
(
output_shape
)
output_shapes
.
append
(
output_shape
)
mace_op_def
.
output_shape
.
extend
(
output_shapes
)
mace_op_def
.
output_shape
.
extend
(
output_shapes
)
...
@@ -159,8 +166,6 @@ def convert_ops(unresolved_ops, resolved_ops, net_def, output_node, dsp_ops):
...
@@ -159,8 +166,6 @@ def convert_ops(unresolved_ops, resolved_ops, net_def, output_node, dsp_ops):
op_def
.
input
.
append
(
input_tensor
.
name
)
op_def
.
input
.
append
(
input_tensor
.
name
)
op_def
.
input
.
extend
([
t
.
name
for
t
in
s2b_op
.
inputs
[
1
:]])
op_def
.
input
.
extend
([
t
.
name
for
t
in
s2b_op
.
inputs
[
1
:]])
op_def
.
input
.
extend
([
min_tensor
.
name
,
max_tensor
.
name
])
op_def
.
input
.
extend
([
min_tensor
.
name
,
max_tensor
.
name
])
op_def
.
out_max_byte_size
.
extend
(
[
max_elem_size
(
out
)
for
out
in
quantize_op
.
outputs
])
convert_op_outputs
(
op_def
,
quantize_op
)
convert_op_outputs
(
op_def
,
quantize_op
)
elif
len
(
first_op
.
outputs
)
>
0
and
\
elif
len
(
first_op
.
outputs
)
>
0
and
\
first_op
.
type
==
'QuantizedReshape'
and
\
first_op
.
type
==
'QuantizedReshape'
and
\
...
@@ -193,9 +198,71 @@ def convert_ops(unresolved_ops, resolved_ops, net_def, output_node, dsp_ops):
...
@@ -193,9 +198,71 @@ def convert_ops(unresolved_ops, resolved_ops, net_def, output_node, dsp_ops):
op_def
.
type
=
dsp_ops
.
map_nn_op
(
'QuantizedSoftmax'
)
op_def
.
type
=
dsp_ops
.
map_nn_op
(
'QuantizedSoftmax'
)
op_def
.
input
.
extend
(
op_def
.
input
.
extend
(
[
input_tensor
.
name
,
min_tensor
.
name
,
max_tensor
.
name
])
[
input_tensor
.
name
,
min_tensor
.
name
,
max_tensor
.
name
])
op_def
.
out_max_byte_size
.
extend
(
[
max_elem_size
(
out
)
for
out
in
quantize_reshape_op
.
outputs
])
convert_op_outputs
(
op_def
,
quantize_reshape_op
)
convert_op_outputs
(
op_def
,
quantize_reshape_op
)
# remove Squeeze
elif
len
(
first_op
.
outputs
)
>
0
and
\
first_op
.
type
==
'Requantize'
and
\
len
(
first_op
.
outputs
[
0
].
consumers
())
>
0
and
\
first_op
.
outputs
[
0
].
consumers
()[
0
].
type
==
'Dequantize'
and
\
len
(
first_op
.
outputs
[
0
].
consumers
()[
0
].
outputs
[
0
].
consumers
())
\
>
0
and
\
first_op
.
outputs
[
0
].
consumers
()[
0
].
outputs
[
0
].
consumers
()[
0
].
type
\
==
'Squeeze'
:
dequantize_op
=
first_op
.
outputs
[
0
].
consumers
()[
0
]
squeeze_op
=
dequantize_op
.
outputs
[
0
].
consumers
()[
0
]
reshape_op
=
squeeze_op
.
outputs
[
0
].
consumers
()[
0
]
min_op
=
reshape_op
.
outputs
[
0
].
consumers
()[
0
]
max_op
=
reshape_op
.
outputs
[
0
].
consumers
()[
1
]
quantize_op
=
min_op
.
outputs
[
0
].
consumers
()[
0
]
resolved_ops
.
add
(
dequantize_op
.
name
)
resolved_ops
.
add
(
squeeze_op
.
name
)
resolved_ops
.
add
(
reshape_op
.
name
)
resolved_ops
.
add
(
min_op
.
name
)
resolved_ops
.
add
(
max_op
.
name
)
resolved_ops
.
add
(
quantize_op
.
name
)
op_def
.
name
=
quantize_op
.
name
op_def
.
input
.
extend
([
t
.
name
for
t
in
first_op
.
inputs
])
convert_op_outputs
(
op_def
,
quantize_op
)
# Squeeze -> Softmax
next_op
=
quantize_op
.
outputs
[
0
].
consumers
()[
0
]
\
if
len
(
quantize_op
.
outputs
)
>
0
else
None
dequantize_op
=
next_op
.
outputs
[
0
].
consumers
()[
0
]
\
if
next_op
and
len
(
next_op
.
outputs
)
>
0
and
\
next_op
.
type
==
'QuantizedReshape'
and
\
len
(
next_op
.
outputs
[
0
].
consumers
())
>
0
else
None
softmax_op
=
dequantize_op
.
outputs
[
0
].
consumers
()[
0
]
\
if
dequantize_op
and
len
(
dequantize_op
.
outputs
)
>
0
and
\
dequantize_op
.
type
==
'Dequantize'
and
\
len
(
dequantize_op
.
outputs
[
0
].
consumers
())
>
0
else
None
if
softmax_op
and
softmax_op
.
type
==
'Softmax'
:
reshape_op
=
softmax_op
.
outputs
[
0
].
consumers
()[
0
]
min_op
=
reshape_op
.
outputs
[
0
].
consumers
()[
0
]
max_op
=
reshape_op
.
outputs
[
0
].
consumers
()[
1
]
quantize_op
=
min_op
.
outputs
[
0
].
consumers
()[
0
]
quantize_reshape_op
=
quantize_op
.
outputs
[
0
].
consumers
()[
0
]
resolved_ops
.
add
(
next_op
.
name
)
resolved_ops
.
add
(
dequantize_op
.
name
)
resolved_ops
.
add
(
softmax_op
.
name
)
resolved_ops
.
add
(
reshape_op
.
name
)
resolved_ops
.
add
(
min_op
.
name
)
resolved_ops
.
add
(
max_op
.
name
)
resolved_ops
.
add
(
quantize_op
.
name
)
resolved_ops
.
add
(
quantize_reshape_op
.
name
)
softmax_op_def
=
net_def
.
op
.
add
()
softmax_op_def
.
padding
=
padding_mode
[
'NA'
]
softmax_op_def
.
name
=
quantize_reshape_op
.
name
softmax_op_def
.
type
=
dsp_ops
.
map_nn_op
(
'QuantizedSoftmax'
)
softmax_op_def
.
input
.
extend
([
get_tensor_name_from_op
(
op_def
.
name
,
0
),
get_tensor_name_from_op
(
op_def
.
name
,
1
),
get_tensor_name_from_op
(
op_def
.
name
,
2
)])
convert_op_outputs
(
softmax_op_def
,
quantize_reshape_op
)
elif
len
(
first_op
.
outputs
)
>
0
and
first_op
.
type
==
'Dequantize'
and
\
elif
len
(
first_op
.
outputs
)
>
0
and
first_op
.
type
==
'Dequantize'
and
\
len
(
first_op
.
outputs
[
0
].
consumers
())
>
0
and
\
len
(
first_op
.
outputs
[
0
].
consumers
())
>
0
and
\
first_op
.
outputs
[
0
].
consumers
()[
0
].
type
==
'Tanh'
:
first_op
.
outputs
[
0
].
consumers
()[
0
].
type
==
'Tanh'
:
...
@@ -220,8 +287,6 @@ def convert_ops(unresolved_ops, resolved_ops, net_def, output_node, dsp_ops):
...
@@ -220,8 +287,6 @@ def convert_ops(unresolved_ops, resolved_ops, net_def, output_node, dsp_ops):
op_def
.
type
=
dsp_ops
.
map_nn_op
(
'Quantized'
+
tanh_op
.
type
)
op_def
.
type
=
dsp_ops
.
map_nn_op
(
'Quantized'
+
tanh_op
.
type
)
op_def
.
input
.
extend
(
op_def
.
input
.
extend
(
[
input_tensor
.
name
,
min_tensor
.
name
,
max_tensor
.
name
])
[
input_tensor
.
name
,
min_tensor
.
name
,
max_tensor
.
name
])
op_def
.
out_max_byte_size
.
extend
(
[
max_elem_size
(
out
)
for
out
in
quantize_op
.
outputs
])
convert_op_outputs
(
op_def
,
quantize_op
)
convert_op_outputs
(
op_def
,
quantize_op
)
# tanh is last op
# tanh is last op
else
:
else
:
...
@@ -251,8 +316,6 @@ def convert_ops(unresolved_ops, resolved_ops, net_def, output_node, dsp_ops):
...
@@ -251,8 +316,6 @@ def convert_ops(unresolved_ops, resolved_ops, net_def, output_node, dsp_ops):
get_tensor_name_from_op
(
op_def
.
name
,
1
),
get_tensor_name_from_op
(
op_def
.
name
,
1
),
get_tensor_name_from_op
(
op_def
.
name
,
2
)
get_tensor_name_from_op
(
op_def
.
name
,
2
)
])
])
new_tanh_op_def
.
out_max_byte_size
.
extend
(
[
max_elem_size
(
tanh_op
.
outputs
[
0
])])
convert_op_outputs
(
new_tanh_op_def
,
tanh_op
)
convert_op_outputs
(
new_tanh_op_def
,
tanh_op
)
elif
has_padding_and_strides
(
first_op
):
elif
has_padding_and_strides
(
first_op
):
op_def
.
padding
=
padding_mode
[
first_op
.
get_attr
(
'padding'
)]
op_def
.
padding
=
padding_mode
[
first_op
.
get_attr
(
'padding'
)]
...
@@ -266,19 +329,13 @@ def convert_ops(unresolved_ops, resolved_ops, net_def, output_node, dsp_ops):
...
@@ -266,19 +329,13 @@ def convert_ops(unresolved_ops, resolved_ops, net_def, output_node, dsp_ops):
strides_tensor
=
add_shape_const_node
(
net_def
,
first_op
,
strides
,
strides_tensor
=
add_shape_const_node
(
net_def
,
first_op
,
strides
,
'strides'
)
'strides'
)
op_def
.
input
.
extend
([
strides_tensor
])
op_def
.
input
.
extend
([
strides_tensor
])
op_def
.
out_max_byte_size
.
extend
(
[
max_elem_size
(
out
)
for
out
in
first_op
.
outputs
])
convert_op_outputs
(
op_def
,
first_op
)
convert_op_outputs
(
op_def
,
first_op
)
elif
is_node_flatten_reshape
(
first_op
):
elif
is_node_flatten_reshape
(
first_op
):
op_def
.
type
=
'Flatten'
op_def
.
type
=
'Flatten'
op_def
.
input
.
extend
([
t
.
name
for
t
in
first_op
.
inputs
])
op_def
.
input
.
extend
([
first_op
.
inputs
[
0
].
name
])
op_def
.
out_max_byte_size
.
extend
(
[
max_elem_size
(
out
)
for
out
in
first_op
.
outputs
])
convert_op_outputs
(
op_def
,
first_op
)
convert_op_outputs
(
op_def
,
first_op
)
elif
dsp_ops
.
has_op
(
first_op
.
type
):
elif
dsp_ops
.
has_op
(
first_op
.
type
):
op_def
.
input
.
extend
([
t
.
name
for
t
in
first_op
.
inputs
])
op_def
.
input
.
extend
([
t
.
name
for
t
in
first_op
.
inputs
])
op_def
.
out_max_byte_size
.
extend
(
[
max_elem_size
(
out
)
for
out
in
first_op
.
outputs
])
convert_op_outputs
(
op_def
,
first_op
)
convert_op_outputs
(
op_def
,
first_op
)
else
:
else
:
raise
Exception
(
'Unsupported op: '
,
first_op
)
raise
Exception
(
'Unsupported op: '
,
first_op
)
...
@@ -478,7 +535,8 @@ def fuse_quantize(net_def, input_node, output_node):
...
@@ -478,7 +535,8 @@ def fuse_quantize(net_def, input_node, output_node):
skip_ops
=
skip_ops
.
union
(
skip_ops
=
skip_ops
.
union
(
[
flatten_op
.
name
,
minf_op
.
name
,
maxf_op
.
name
])
[
flatten_op
.
name
,
minf_op
.
name
,
maxf_op
.
name
])
skip_tensors
=
skip_tensors
.
union
(
skip_tensors
=
skip_tensors
.
union
(
[
flatten_op
.
input
[
1
],
minf_op
.
input
[
1
],
maxf_op
.
input
[
1
]])
[
minf_op
.
input
[
0
],
maxf_op
.
input
[
0
],
quantize_op
.
input
[
1
],
quantize_op
.
input
[
2
]])
quantize_op
.
type
=
'AutoQuantize'
quantize_op
.
type
=
'AutoQuantize'
del
quantize_op
.
input
[
1
:]
del
quantize_op
.
input
[
1
:]
...
...
mace/test/mace_api_mt_test.cc
浏览文件 @
bdaa5c18
...
@@ -318,8 +318,10 @@ void MaceRunFunc(const int in_out_size) {
...
@@ -318,8 +318,10 @@ void MaceRunFunc(const int in_out_size) {
new
FileStorageFactory
(
file_path
));
new
FileStorageFactory
(
file_path
));
mace
::
SetKVStorageFactory
(
storage_factory
);
mace
::
SetKVStorageFactory
(
storage_factory
);
MaceEngine
engine
(
&
net_def
,
device
,
input_names
,
output_names
,
MaceEngine
engine
(
device
);
reinterpret_cast
<
unsigned
char
*>
(
data
.
data
()));
MaceStatus
status
=
engine
.
Init
(
&
net_def
,
input_names
,
output_names
,
reinterpret_cast
<
unsigned
char
*>
(
data
.
data
()));
ASSERT_EQ
(
status
,
MaceStatus
::
MACE_SUCCESS
);
std
::
map
<
std
::
string
,
mace
::
MaceTensor
>
inputs
;
std
::
map
<
std
::
string
,
mace
::
MaceTensor
>
inputs
;
std
::
map
<
std
::
string
,
mace
::
MaceTensor
>
outputs
;
std
::
map
<
std
::
string
,
mace
::
MaceTensor
>
outputs
;
...
...
mace/test/mace_api_test.cc
浏览文件 @
bdaa5c18
...
@@ -323,8 +323,10 @@ void MaceRun(const int in_out_size,
...
@@ -323,8 +323,10 @@ void MaceRun(const int in_out_size,
&
net_def
);
&
net_def
);
}
}
MaceEngine
engine
(
&
net_def
,
device
,
input_names
,
output_names
,
MaceEngine
engine
(
device
);
reinterpret_cast
<
unsigned
char
*>
(
data
.
data
()));
MaceStatus
status
=
engine
.
Init
(
&
net_def
,
input_names
,
output_names
,
reinterpret_cast
<
unsigned
char
*>
(
data
.
data
()));
ASSERT_EQ
(
status
,
MaceStatus
::
MACE_SUCCESS
);
std
::
map
<
std
::
string
,
mace
::
MaceTensor
>
inputs
;
std
::
map
<
std
::
string
,
mace
::
MaceTensor
>
inputs
;
std
::
map
<
std
::
string
,
mace
::
MaceTensor
>
outputs
;
std
::
map
<
std
::
string
,
mace
::
MaceTensor
>
outputs
;
...
...
mace/utils/logging.cc
浏览文件 @
bdaa5c18
...
@@ -15,6 +15,7 @@
...
@@ -15,6 +15,7 @@
#include "mace/utils/logging.h"
#include "mace/utils/logging.h"
#include <stdlib.h>
#include <stdlib.h>
#include <string.h>
#if defined(ANDROID) || defined(__ANDROID__)
#if defined(ANDROID) || defined(__ANDROID__)
#include <android/log.h>
#include <android/log.h>
#include <iostream>
#include <iostream>
...
...
编辑
预览
Markdown
is supported
0%
请重试
或
添加新附件
.
添加附件
取消
You are about to add
0
people
to the discussion. Proceed with caution.
先完成此消息的编辑!
取消
想要评论请
注册
或
登录
{kind=link}

{kind=link}