update to develop branch and resolve conflicts.
Showing
doc/design/ops/dist_train.md
0 → 100644
文件已添加
doc/design/ops/src/dist-graph.png
0 → 100644
{kind=link}
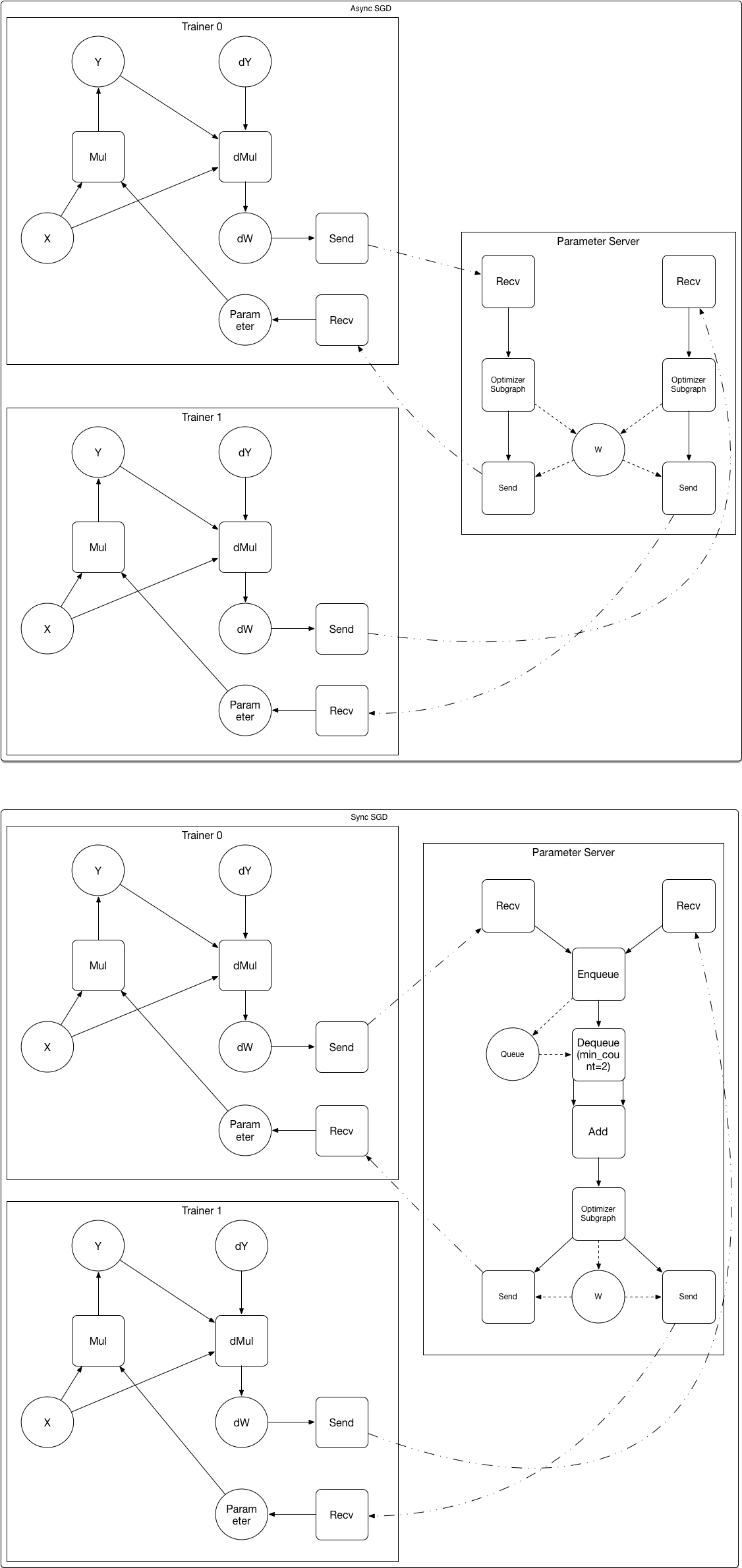
222.2 KB
文件已添加
{kind=link}
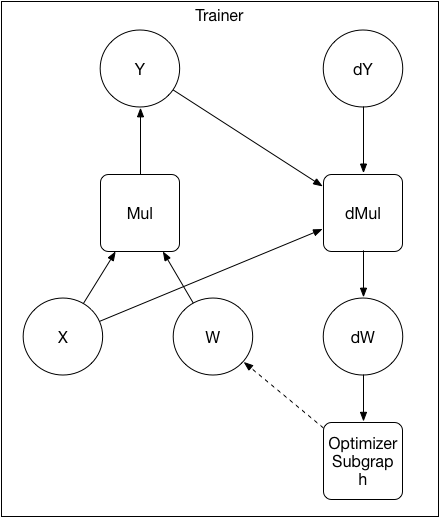
27.9 KB
{kind=link}
{kind=link}
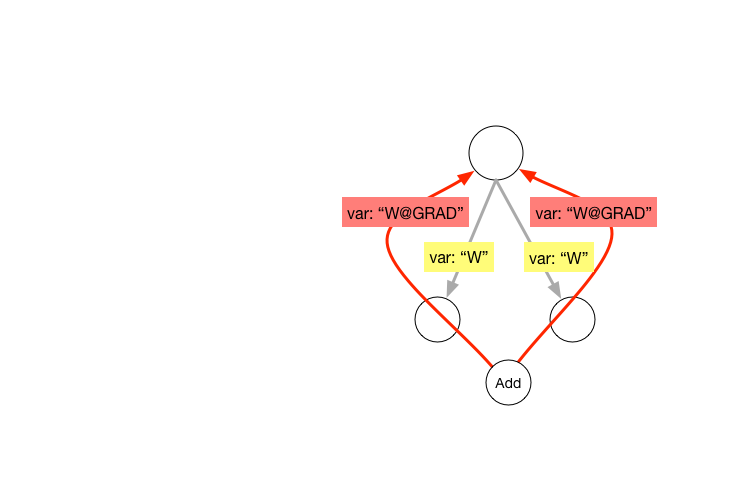
| W: | H:
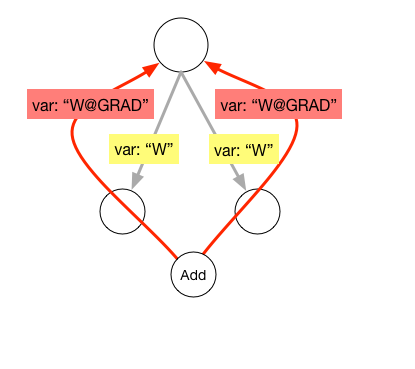
| W: | H:
paddle/operators/concat_op.cc
0 → 100644
paddle/operators/concat_op.cu
0 → 100644
paddle/operators/concat_op.h
0 → 100644
paddle/operators/sum_op.cc
0 → 100644
paddle/operators/sum_op.cu
0 → 100644
paddle/operators/sum_op.h
0 → 100644
paddle/operators/top_k_op.cc
0 → 100644
paddle/operators/top_k_op.cu
0 → 100644
paddle/operators/top_k_op.h
0 → 100644