Merge branch 'develop' into soft_label_cross_entropy
Showing
{kind=link}
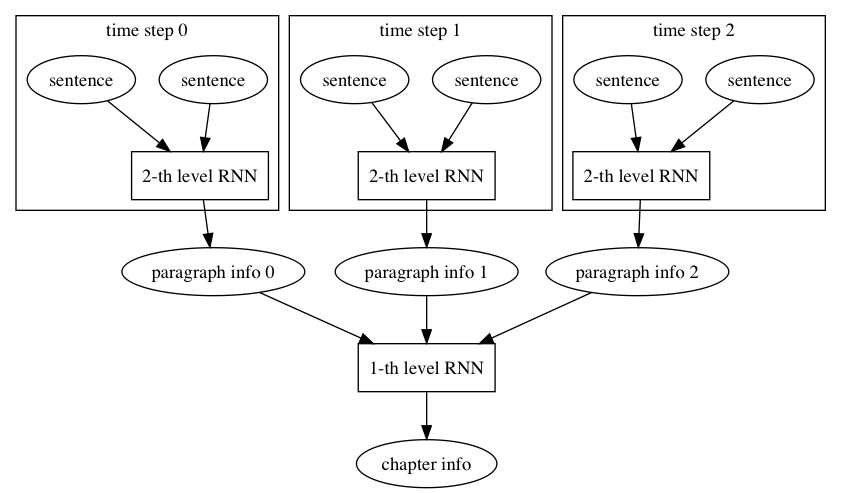
51.4 KB
doc/design/ops/images/rnn.dot
0 → 100644
doc/design/ops/images/rnn.jpg
0 → 100644
{kind=link}
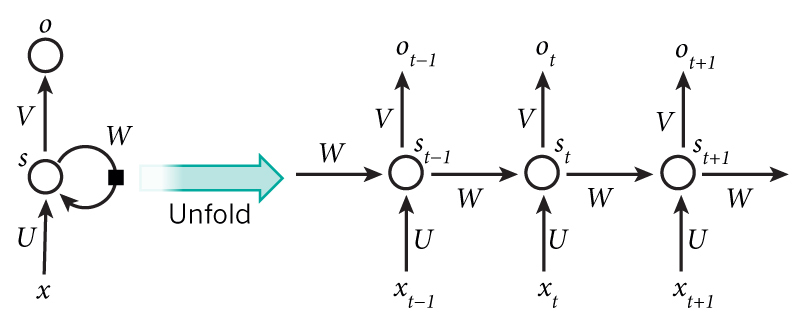
43.3 KB
doc/design/ops/images/rnn.png
0 → 100644
{kind=link}
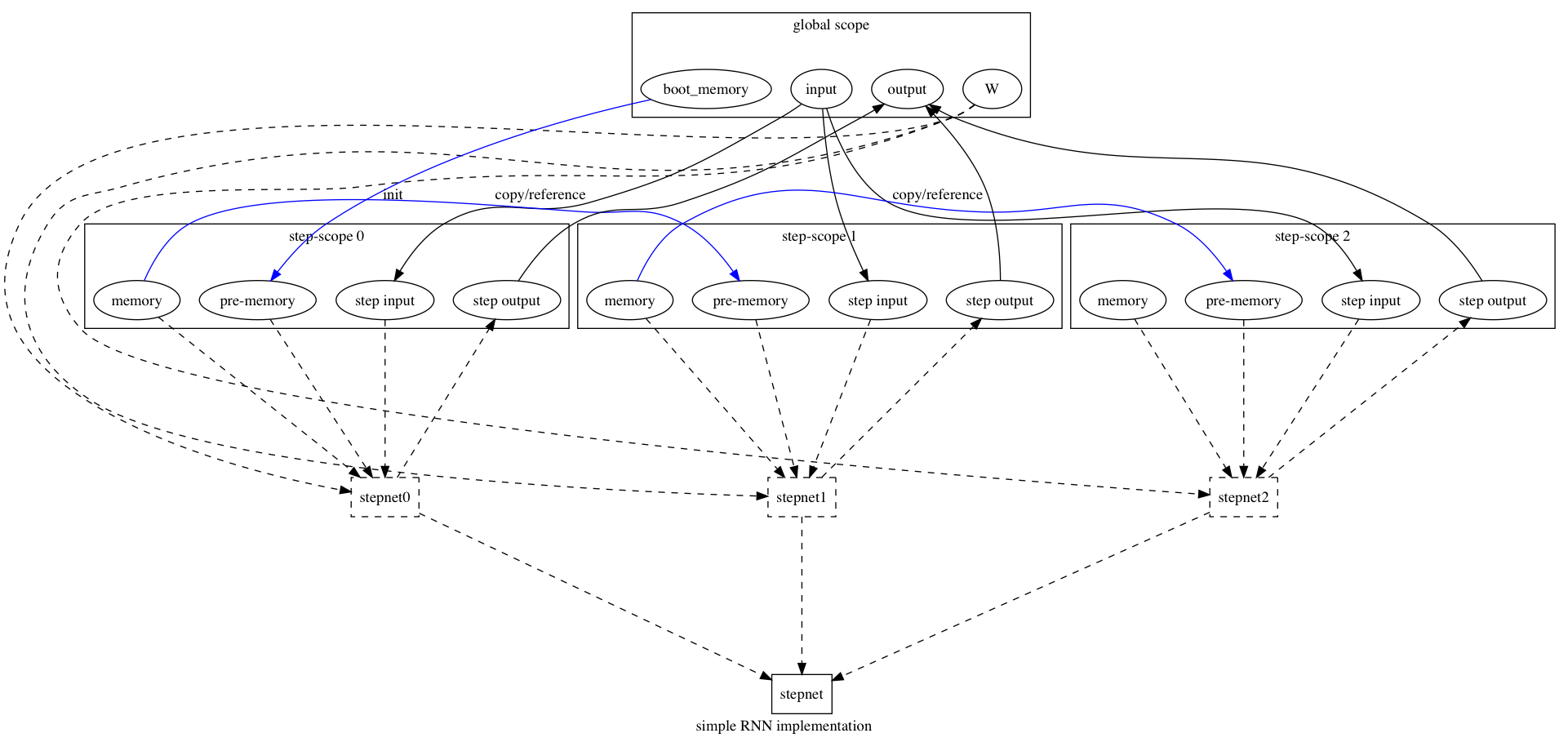
180.8 KB
{kind=link}
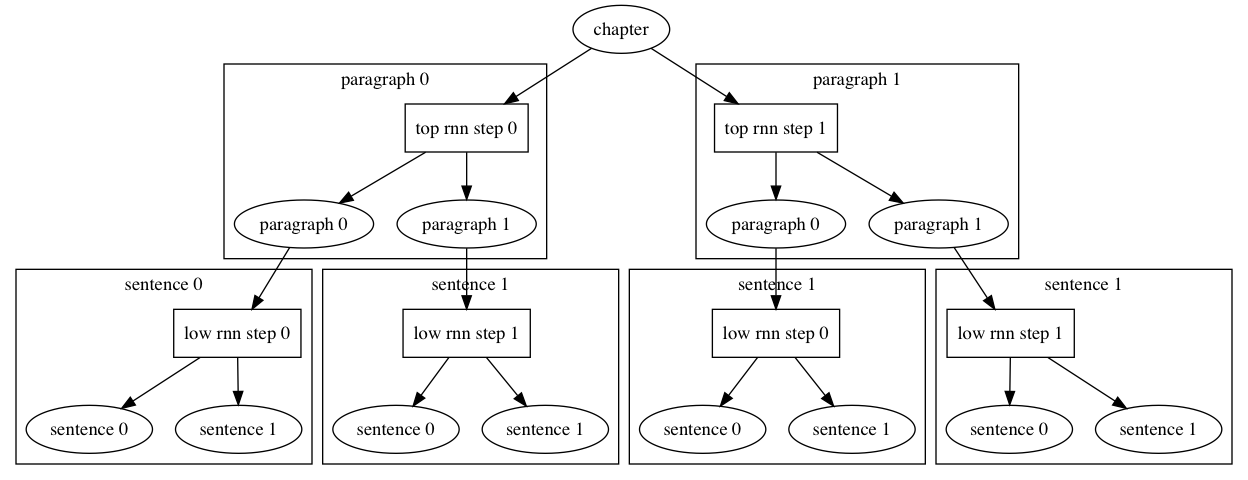
67.3 KB
doc/design/ops/rnn.md
0 → 100644
paddle/operators/accuracy_op.cc
0 → 100644
paddle/operators/accuracy_op.cu
0 → 100644
paddle/operators/accuracy_op.h
0 → 100644
paddle/operators/concat_op.cu
已删除
100644 → 0
paddle/operators/cond_op.cc
0 → 100644
paddle/operators/cond_op.h
0 → 100644
paddle/operators/pad_op.cc
0 → 100644
paddle/operators/pad_op.cu
0 → 100644
paddle/operators/pad_op.h
0 → 100644
此差异已折叠。
paddle/platform/transform.h
0 → 100644
此差异已折叠。
paddle/platform/transform_test.cu
0 → 100644
此差异已折叠。
此差异已折叠。
文件已移动
此差异已折叠。
此差异已折叠。
此差异已折叠。
文件已移动
此差异已折叠。
此差异已折叠。
此差异已折叠。