Skip to content
体验新版
项目
组织
正在加载...
登录
切换导航
打开侧边栏
IT.BOB
TRHX-github-io
提交
066b5155
T
TRHX-github-io
项目概览
IT.BOB
/
TRHX-github-io
通知
16
Star
2
Fork
1
代码
文件
提交
分支
Tags
贡献者
分支图
Diff
Issue
42
列表
看板
标记
里程碑
合并请求
0
Wiki
0
Wiki
分析
仓库
DevOps
项目成员
Pages
T
TRHX-github-io
项目概览
项目概览
详情
发布
仓库
仓库
文件
提交
分支
标签
贡献者
分支图
比较
Issue
42
Issue
42
列表
看板
标记
里程碑
合并请求
0
合并请求
0
Pages
分析
分析
仓库分析
DevOps
Wiki
0
Wiki
成员
成员
收起侧边栏
关闭侧边栏
动态
分支图
创建新Issue
提交
Issue看板
前往新版Gitcode,体验更适合开发者的 AI 搜索 >>
提交
066b5155
编写于
10月 21, 2019
作者:
T
TRHX
浏览文件
操作
浏览文件
下载
电子邮件补丁
差异文件
Back up my www.itrhx.com blog
上级
db526b13
变更
20
展开全部
隐藏空白更改
内联
并排
Showing
20 changed file
with
2182 addition
and
82 deletion
+2182
-82
source/_posts/A39-Python3-spider-C09.md
source/_posts/A39-Python3-spider-C09.md
+24
-2
source/_posts/A51-pyspider-maoyantop100.md
source/_posts/A51-pyspider-maoyantop100.md
+41
-9
source/_posts/A52-pyspider-doubantop250.md
source/_posts/A52-pyspider-doubantop250.md
+29
-14
source/_posts/A53-hexo-backup.md
source/_posts/A53-hexo-backup.md
+1
-1
source/_posts/A54-pyspider-anjuke.md
source/_posts/A54-pyspider-anjuke.md
+225
-0
source/_posts/A55-pyspider-hupu.md
source/_posts/A55-pyspider-hupu.md
+255
-0
source/_posts/A56-pyspider-bilibili-login.md
source/_posts/A56-pyspider-bilibili-login.md
+536
-0
source/_posts/A57-pyspider-12306-login.md
source/_posts/A57-pyspider-12306-login.md
+444
-0
source/_posts/A58-pyspider-58tongcheng.md
source/_posts/A58-pyspider-58tongcheng.md
+521
-0
source/comments/index.md
source/comments/index.md
+1
-2
source/friends/index.md
source/friends/index.md
+69
-29
themes/material-x-1.2.1/_config.yml
themes/material-x-1.2.1/_config.yml
+13
-13
themes/material-x-1.2.1/layout/_partial/article.ejs
themes/material-x-1.2.1/layout/_partial/article.ejs
+2
-2
themes/material-x-1.2.1/layout/_partial/footer.ejs
themes/material-x-1.2.1/layout/_partial/footer.ejs
+1
-1
themes/material-x-1.2.1/layout/_partial/post.ejs
themes/material-x-1.2.1/layout/_partial/post.ejs
+1
-1
themes/material-x-1.2.1/source/less/_article.less
themes/material-x-1.2.1/source/less/_article.less
+4
-1
themes/material-x-1.2.1/source/less/_base.less
themes/material-x-1.2.1/source/less/_base.less
+8
-1
themes/material-x-1.2.1/source/less/_color.less
themes/material-x-1.2.1/source/less/_color.less
+2
-2
themes/material-x-1.2.1/source/less/_fonts.less
themes/material-x-1.2.1/source/less/_fonts.less
+4
-3
themes/material-x-1.2.1/source/less/_main.less
themes/material-x-1.2.1/source/less/_main.less
+1
-1
未找到文件。
source/_posts/A39-Python3-spider-C09.md
浏览文件 @
066b5155
...
...
@@ -243,7 +243,29 @@ id,name,age
10003
,
Jordan
,
21
```
列与列之间的分隔符是可以修改的,只需要传入 delimiter 参数即可:
默认每一行之间是有一行空格的,可以使用参数
`newline`
来去除空行:
```
python
import
csv
with
open
(
'data.csv'
,
'w'
,
newline
=
''
)
as
csvfile
:
writer
=
csv
.
writer
(
csvfile
)
writer
.
writerow
([
'id'
,
'name'
,
'age'
])
writer
.
writerow
([
'10001'
,
'TRHX'
,
20
])
writer
.
writerow
([
'10002'
,
'Bob'
,
22
])
writer
.
writerow
([
'10003'
,
'Jordan'
,
21
])
```
输出结果:
```
python
id
,
name
,
age
10001
,
TRHX
,
20
10002
,
Bob
,
22
10003
,
Jordan
,
21
```
列与列之间的分隔符是可以修改的,只需要传入
`delimiter`
参数即可:
```
python
import
csv
...
...
@@ -268,7 +290,7 @@ id name age
10003
Jordan
21
```
调用
writerows
方法也可以同时写入多行,此时参数就需要为二维列表:
调用
`writerows`
方法也可以同时写入多行,此时参数就需要为二维列表:
```
python
import
csv
...
...
source/_posts/A51-pyspider-
combat-maoyan
.md
→
source/_posts/A51-pyspider-
maoyantop100
.md
浏览文件 @
066b5155
...
...
@@ -10,21 +10,31 @@ thumbnail: https://cdn.jsdelivr.net/gh/TRHX/ImageHosting/ITRHX-PIC/thumbnail/com
avatar
:
https://cdn.jsdelivr.net/gh/TRHX/CDN-for-itrhx.com@2.1.9/images/trhx.png
---
爬取时间:2019-09-24
爬取难度:★☆☆☆☆☆
请求链接:
[
猫眼电影TOP100榜
](
https://maoyan.com/board/4
)
爬取目标:猫眼 TOP100 的电影名称、排名、主演、上映时间、评分、封面图地址,数据保存为 CSV 文件
涉及知识:请求库 requests、解析库 lxml、Xpath 语法、CSV 文件储存
> 爬取时间:2019-09-23
> 爬取难度:★☆☆☆☆☆
> 请求链接:https://maoyan.com/board/4
> 爬取目标:猫眼 TOP100 的电影名称、排名、主演、上映时间、评分、封面图地址,数据保存为 CSV 文件
> 涉及知识:请求库 requests、解析库 lxml、Xpath 语法、CSV 文件储存
> 完整代码:https://github.com/TRHX/Python3-Spider-Practice/tree/master/maoyan-top100
> 其他爬虫实战代码合集(持续更新):https://github.com/TRHX/Python3-Spider-Practice
> 爬虫实战专栏(持续更新):https://itrhx.blog.csdn.net/article/category/9351278
---
<!--more-->
# <font color=#FF0000>【1x00】循环爬取网页模块</font>
观察猫眼电影TOP100榜,请求地址为:https://maoyan.com/board/4
每页展示10条电影信息,翻页观察 url 变化:
第一页:https://maoyan.com/board/4
第二页:https://maoyan.com/board/4?offset=10
第三页:https://maoyan.com/board/4?offset=20
一共有10页,利用一个 for 循环,从 0 到 100 每隔 10 取一个值拼接到 url,实现循环爬取每一页
```
python
...
...
@@ -38,6 +48,10 @@ if __name__ == '__main__':
index
=
index_page
(
i
)
```
---
# <font color=#FF0000>【2x00】解析模块</font>
定义一个页面解析函数
`parse_page()`
,使用 lxml 解析库的 Xpath 方法依次提取电影排名(ranking)、电影名称(movie_name)、主演(performer)、上映时间(releasetime)、评分(score)、电影封面图 url(movie_img)
通过对主演部分的提取发现有多余的空格符和换行符,循环 performer 列表,使用
`strip()`
方法去除字符串头尾空格和换行符
...
...
@@ -67,7 +81,11 @@ def parse_page(content):
return
zip
(
ranking
,
movie_name
,
performer
,
releasetime
,
score
,
movie_img
)
```
最后定义一个
`save_results()`
函数,将所有数据保存到
`maoyan.csv`
文件
---
# <font color=#FF0000>【3x00】数据储存模块</font>
定义一个
`save_results()`
函数,将所有数据保存到
`maoyan.csv`
文件
```
python
def
save_results
(
result
):
...
...
@@ -76,9 +94,21 @@ def save_results(result):
writer
.
writerow
(
result
)
```
完整代码:
---
# <font color=#FF0000>【4x00】完整代码</font>
```
python
# =============================================
# --*-- coding: utf-8 --*--
# @Time : 2019-09-23
# @Author : TRHX
# @Blog : www.itrhx.com
# @CSDN : https://blog.csdn.net/qq_36759224
# @FileName: maoyan.py
# @Software: PyCharm
# =============================================
import
requests
from
lxml
import
etree
import
csv
...
...
@@ -127,11 +157,13 @@ if __name__ == '__main__':
results
=
parse_page
(
index
)
for
i
in
results
:
save_results
(
i
)
print
(
'数据爬取完毕!
!
'
)
print
(
'数据爬取完毕!'
)
```
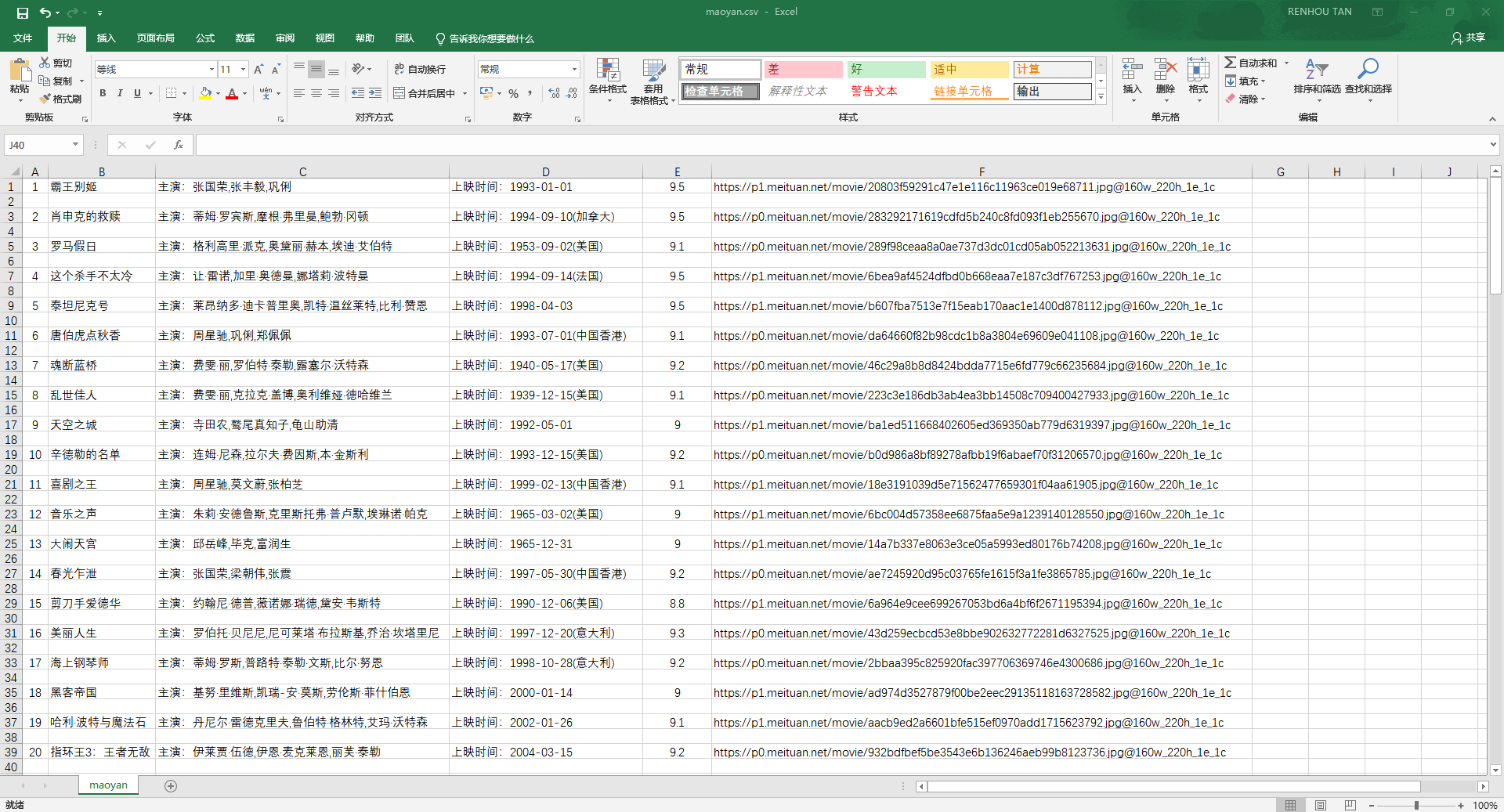
爬取到的数据(maoyan.csv 文件):
---
# <font color=#FF0000>【4x00】数据截图</font>
<fancybox>
...
...
source/_posts/A52-pyspider-
combat-douban
.md
→
source/_posts/A52-pyspider-
doubantop250
.md
浏览文件 @
066b5155
...
...
@@ -10,24 +10,29 @@ thumbnail: https://cdn.jsdelivr.net/gh/TRHX/ImageHosting/ITRHX-PIC/thumbnail/com
avatar
:
https://cdn.jsdelivr.net/gh/TRHX/CDN-for-itrhx.com@2.1.9/images/trhx.png
---
爬取时间:2019-09-27
爬取难度:★★☆☆☆☆
请求链接:
[
豆瓣电影 Top 250
](
https://movie.douban.com/top250
)
以及每部电影详情页
爬取目标:爬取榜单上每一部电影详情页的数据,保存为 CSV 文件;下载所有电影海报到本地
涉及知识:请求库 requests、解析库 lxml、Xpath 语法、正则表达式、CSV 和二进制数据储存、列表操作
> 爬取时间:2019-09-27
> 爬取难度:★★☆☆☆☆
> 请求链接:https://movie.douban.com/top250 以及每部电影详情页
> 爬取目标:爬取榜单上每一部电影详情页的数据,保存为 CSV 文件;下载所有电影海报到本地
> 涉及知识:请求库 requests、解析库 lxml、Xpath 语法、正则表达式、CSV 和二进制数据储存、列表操作
> 完整代码:https://github.com/TRHX/Python3-Spider-Practice/tree/master/douban-top250
> 其他爬虫实战代码合集(持续更新):https://github.com/TRHX/Python3-Spider-Practice
> 爬虫实战专栏(持续更新):https://itrhx.blog.csdn.net/article/category/9351278
---
<!--more-->
# <font color=#FF0000>【1x00】循环爬取
首页
</font>
# <font color=#FF0000>【1x00】循环爬取
网页模块
</font>
观察豆瓣电影 Top 250,请求地址为:https://movie.douban.com/top250
每页展示25条电影信息,照例翻页观察 url 的变化:
第一页:https://movie.douban.com/top250
第二页:https://movie.douban.com/top250?start=25&filter=
第三页:https://movie.douban.com/top250?start=50&filter=
一共有10页,每次改变的是 start 的值,利用一个 for 循环,从 0 到 250 每隔 25 取一个值拼接到 url,实现循环爬取每一页,由于我们的目标是进入每一部电影的详情页,然后爬取详情页的内容,所以我们可以使用 Xpath 提取每一页每部电影详情页的 URL,将其赋值给
`m_urls`
,并返回
`m_urls`
,
`m_urls`
是一个列表,列表元素就是电影详情页的 URL
...
...
@@ -203,15 +208,19 @@ with open(poster_path, "wb")as f:
---
# <font color=#FF0000>【5x00】程序不足的地方</font>
程序不足的地方:豆瓣电影有反爬机制,当程序爬取到大约 150 条数据的时候,IP 就会被封掉,第二天 IP 才会解封,可以考虑综合使用多个代理、多个 User-Agent、随机时间暂停等方法进行爬取
---
# <font color=#FF0000>【6x00】完整代码</font>
# <font color=#FF0000>【5x00】完整代码</font>
```
python
# =============================================
# --*-- coding: utf-8 --*--
# @Time : 2019-09-27
# @Author : TRHX
# @Blog : www.itrhx.com
# @CSDN : https://blog.csdn.net/qq_36759224
# @FileName: douban.py
# @Software: PyCharm
# =============================================
import
requests
from
lxml
import
etree
import
csv
...
...
@@ -331,7 +340,7 @@ if __name__ == '__main__':
---
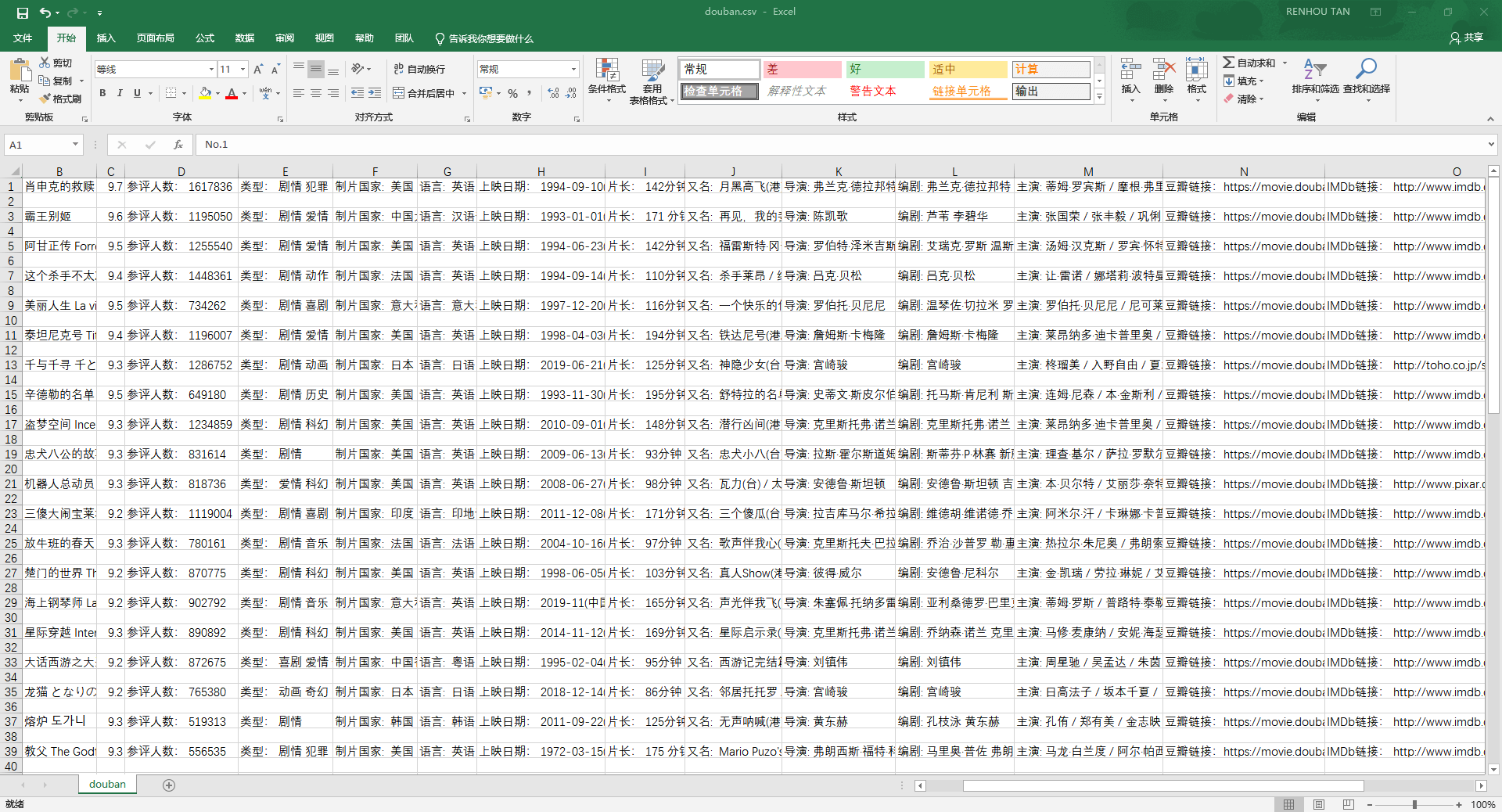
# <font color=#FF0000>【
7
x00】数据截图</font>
# <font color=#FF0000>【
6
x00】数据截图</font>
<fancybox>
...
...
@@ -340,3 +349,9 @@ if __name__ == '__main__':
<fancybox>
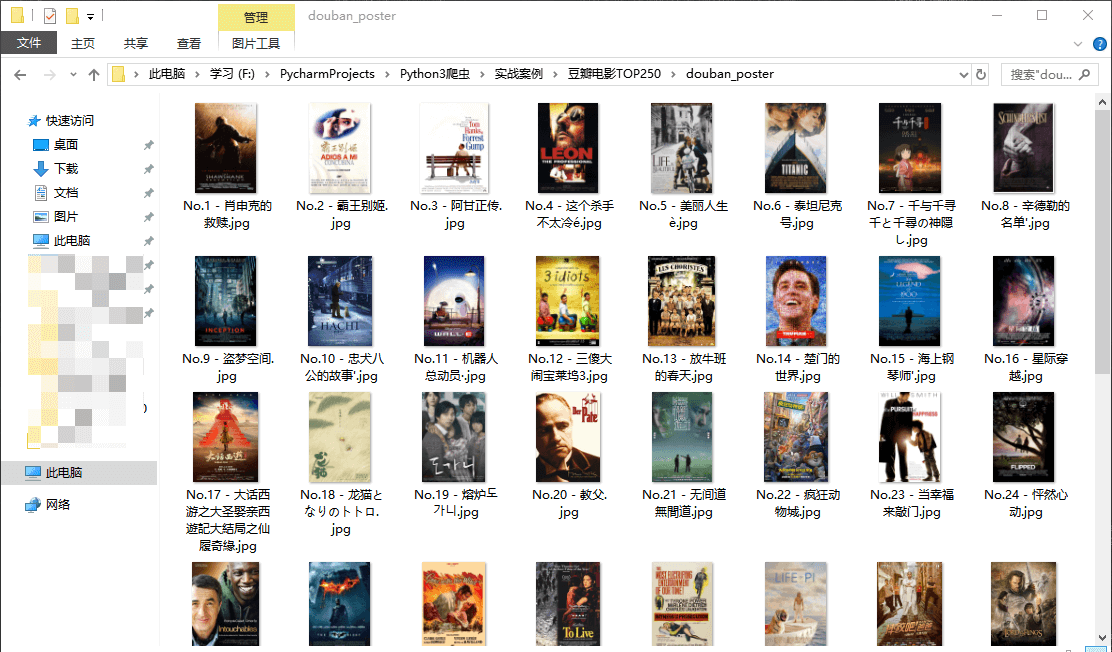
</fancybox>
---
# <font color=#FF0000>【7x00】程序不足的地方</font>
程序不足的地方:豆瓣电影有反爬机制,当程序爬取到大约 150 条数据的时候,IP 就会被封掉,第二天 IP 才会解封,可以考虑综合使用多个代理、多个 User-Agent、随机时间暂停等方法进行爬取
source/_posts/A53-hexo-backup.md
浏览文件 @
066b5155
...
...
@@ -60,7 +60,7 @@ $ hexo backup
或者使用以下简写命令也可以:
```
bash
$
hexo
d
$
hexo
b
```
备份成功后可以在你的仓库分支下看到备份的原始文件:
...
...
source/_posts/A54-pyspider-anjuke.md
0 → 100644
浏览文件 @
066b5155
---
title
:
Python3 爬虫实战 — 安居客武汉二手房
tags
:
-
爬虫
-
安居客
categories
:
-
Python3 学习笔记
-
爬虫实战
thumbnail
:
https://cdn.jsdelivr.net/gh/TRHX/ImageHosting/ITRHX-PIC/thumbnail/combat.png
avatar
:
https://cdn.jsdelivr.net/gh/TRHX/CDN-for-itrhx.com@2.1.9/images/trhx.png
---
> 爬取时间:2019-10-09
> 爬取难度:★★☆☆☆☆
> 请求链接:https://wuhan.anjuke.com/sale/
> 爬取目标:爬取武汉二手房每一条售房信息,包含地理位置、价格、面积等,保存为 CSV 文件
> 涉及知识:请求库 requests、解析库 Beautiful Soup、CSV 文件储存、列表操作、分页判断
> 完整代码:https://github.com/TRHX/Python3-Spider-Practice/tree/master/anjuke
> 其他爬虫实战代码合集(持续更新):https://github.com/TRHX/Python3-Spider-Practice
> 爬虫实战专栏(持续更新):https://itrhx.blog.csdn.net/article/category/9351278
---
<!--more-->
# <font color=#FF0000>【1x00】页面整体分析</font>
分析
[
安居客武汉二手房页面
](
https://wuhan.anjuke.com/sale/
)
,这次爬取实战准备使用 BeautifulSoup 解析库,熟练 BeautifulSoup 解析库的用法,注意到该页面与其他页面不同的是,不能一次性看到到底有多少页,以前知道一共有多少页,直接一个循环爬取就行了,虽然可以通过改变 url 来尝试找到最后一页,但是这样就显得不程序员了😂,因此可以通过 BeautifulSoup 解析
`下一页按钮`
,提取到下一页的 url,直到没有
`下一页按钮`
这个元素为止,从而实现所有页面的爬取,剩下的信息提取和储存就比较简单了
---
# <font color=#FF0000>【2x00】解析模块</font>
分析页面,可以发现每条二手房信息都是包含在
`<li> `
标签内的,因此可以使用 BeautifulSoup 解析页面得到所有的
`<li> `
标签,然后再循环访问每个
`<li>`
标签,依次解析得到每条二手房的各种信息
<fancybox>
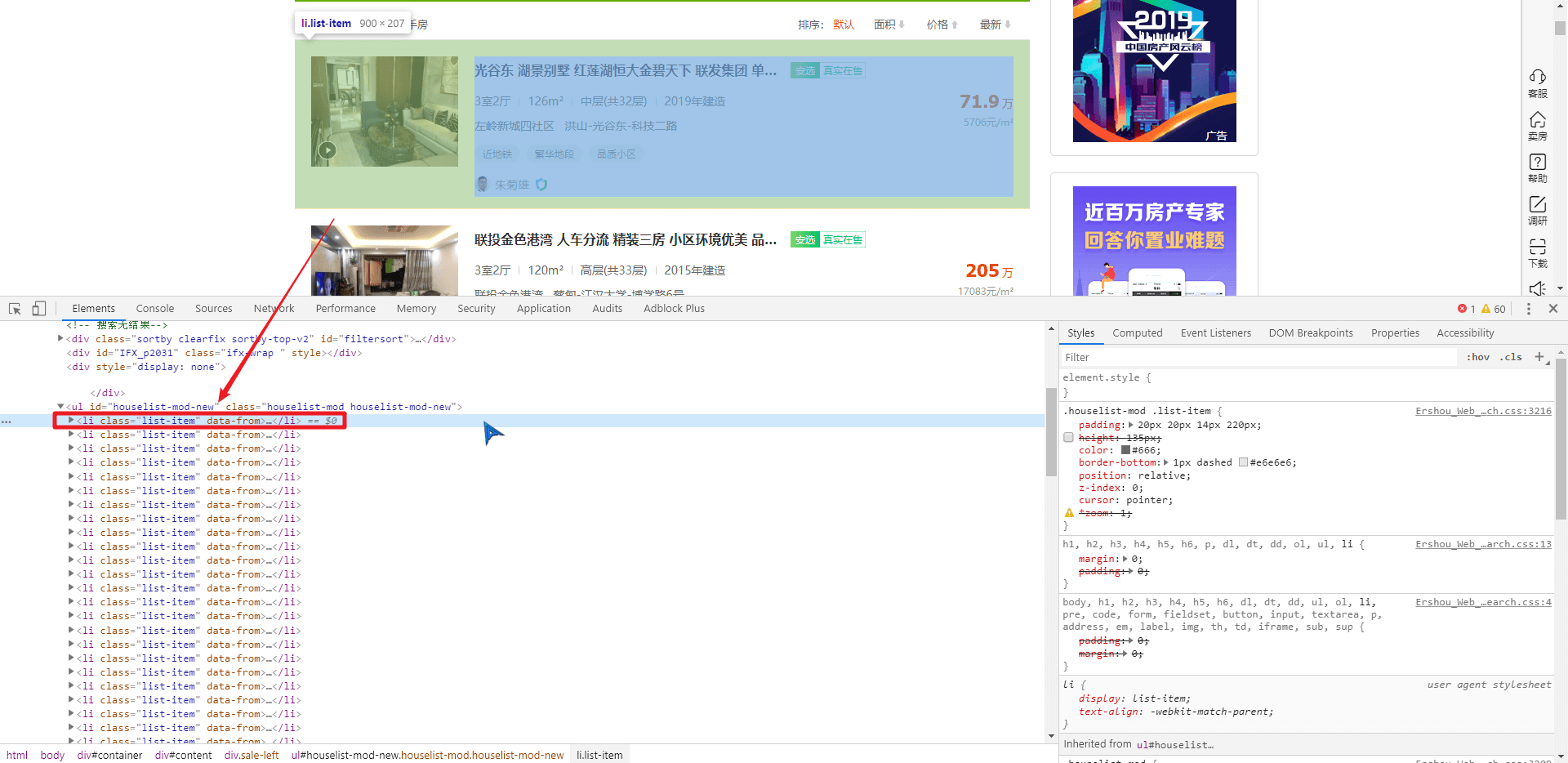
</fancybox>
```
python
def
parse_pages
(
url
,
num
):
response
=
requests
.
get
(
url
=
url
,
headers
=
headers
)
soup
=
BeautifulSoup
(
response
.
text
,
'lxml'
)
result_list
=
soup
.
find_all
(
'li'
,
class_
=
'list-item'
)
# print(len(result_list))
for
result
in
result_list
:
# 标题
title
=
result
.
find
(
'a'
,
class_
=
'houseListTitle'
).
text
.
strip
()
# print(title)
# 户型
layout
=
result
.
select
(
'.details-item > span'
)[
0
].
text
# print(layout)
# 面积
cover
=
result
.
select
(
'.details-item > span'
)[
1
].
text
# print(cover)
# 楼层
floor
=
result
.
select
(
'.details-item > span'
)[
2
].
text
# print(floor)
# 建造年份
year
=
result
.
select
(
'.details-item > span'
)[
3
].
text
# print(year)
# 单价
unit_price
=
result
.
find
(
'span'
,
class_
=
'unit-price'
).
text
.
strip
()
# print(unit_price)
# 总价
total_price
=
result
.
find
(
'span'
,
class_
=
'price-det'
).
text
.
strip
()
# print(total_price)
# 关键字
keyword
=
result
.
find
(
'div'
,
class_
=
'tags-bottom'
).
text
.
strip
()
# print(keyword)
# 地址
address
=
result
.
find
(
'span'
,
class_
=
'comm-address'
).
text
.
replace
(
' '
,
''
).
replace
(
'
\n
'
,
''
)
# print(address)
# 详情页url
details_url
=
result
.
find
(
'a'
,
class_
=
'houseListTitle'
)[
'href'
]
# print(details_url)
if
__name__
==
'__main__'
:
start_num
=
0
start_url
=
'https://wuhan.anjuke.com/sale/'
parse_pages
(
start_url
,
start_num
)
```
---
# <font color=#FF0000>【3x00】循环爬取模块</font>
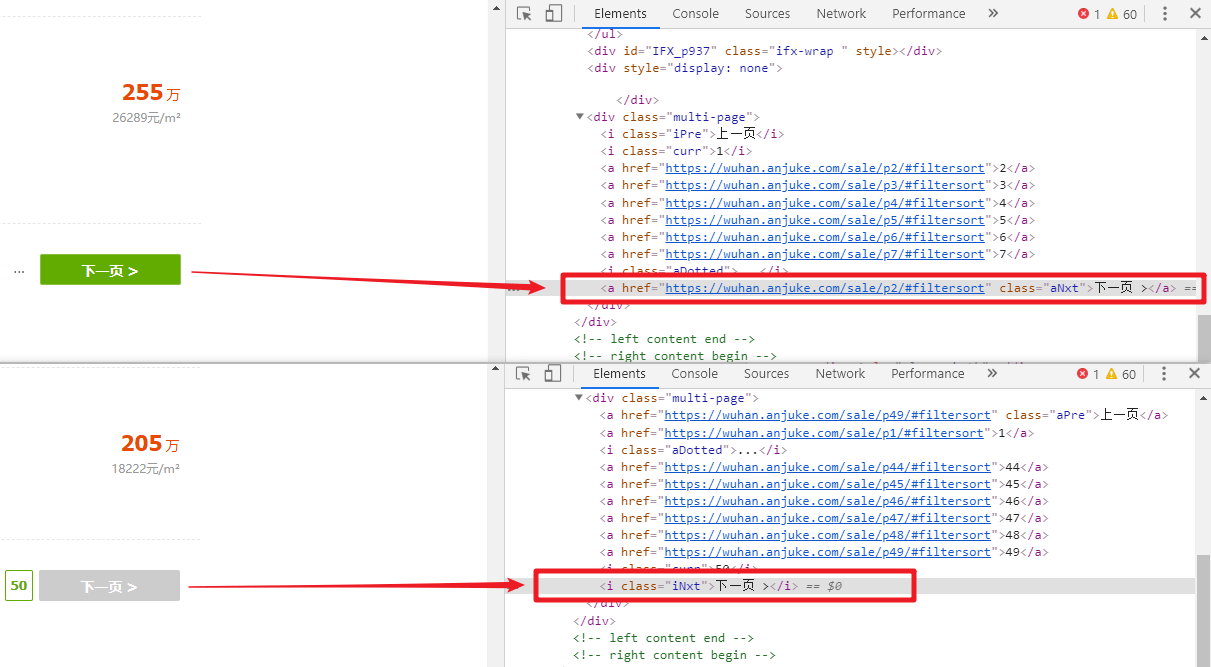
前面已经分析过,该网页是无法一下就能看到一共有多少页的,尝试找到最后一页,发现一共有50页,那么此时就可以搞个循环,一直到第50页就行了,但是如果有一天页面数增加了呢,那么代码的可维护性就不好了,我们可以观察
`下一页按钮`
,当存在下一页的时候,是
`<a>`
标签,并且带有下一页的 URL,不存在下一页的时候是
`<i>`
标签,因此可以写个
`if`
语句,判断是否存在此
`<a>`
标签,若存在,表示有下一页,然后提取其
`href`
属性并传给解析模块,实现后面所有页面的信息提取,此外,由于安居客有反爬系统,我们还可以利用 Python中的
`random.randint()`
方法,在两个数值之间随机取一个数,传入
`time.sleep()`
方法,实现随机暂停爬取
<fancybox>
</fancybox>
```
python
# 判断是否还有下一页
next_url
=
soup
.
find_all
(
'a'
,
class_
=
'aNxt'
)
if
len
(
next_url
)
!=
0
:
num
+=
1
print
(
'第'
+
str
(
num
)
+
'页数据爬取完毕!'
)
# 3-60秒之间随机暂停
time
.
sleep
(
random
.
randint
(
3
,
60
))
parse_pages
(
next_url
[
0
].
attrs
[
'href'
],
num
)
else
:
print
(
'所有数据爬取完毕!'
)
```
---
# <font color=#FF0000>【4x00】数据储存模块</font>
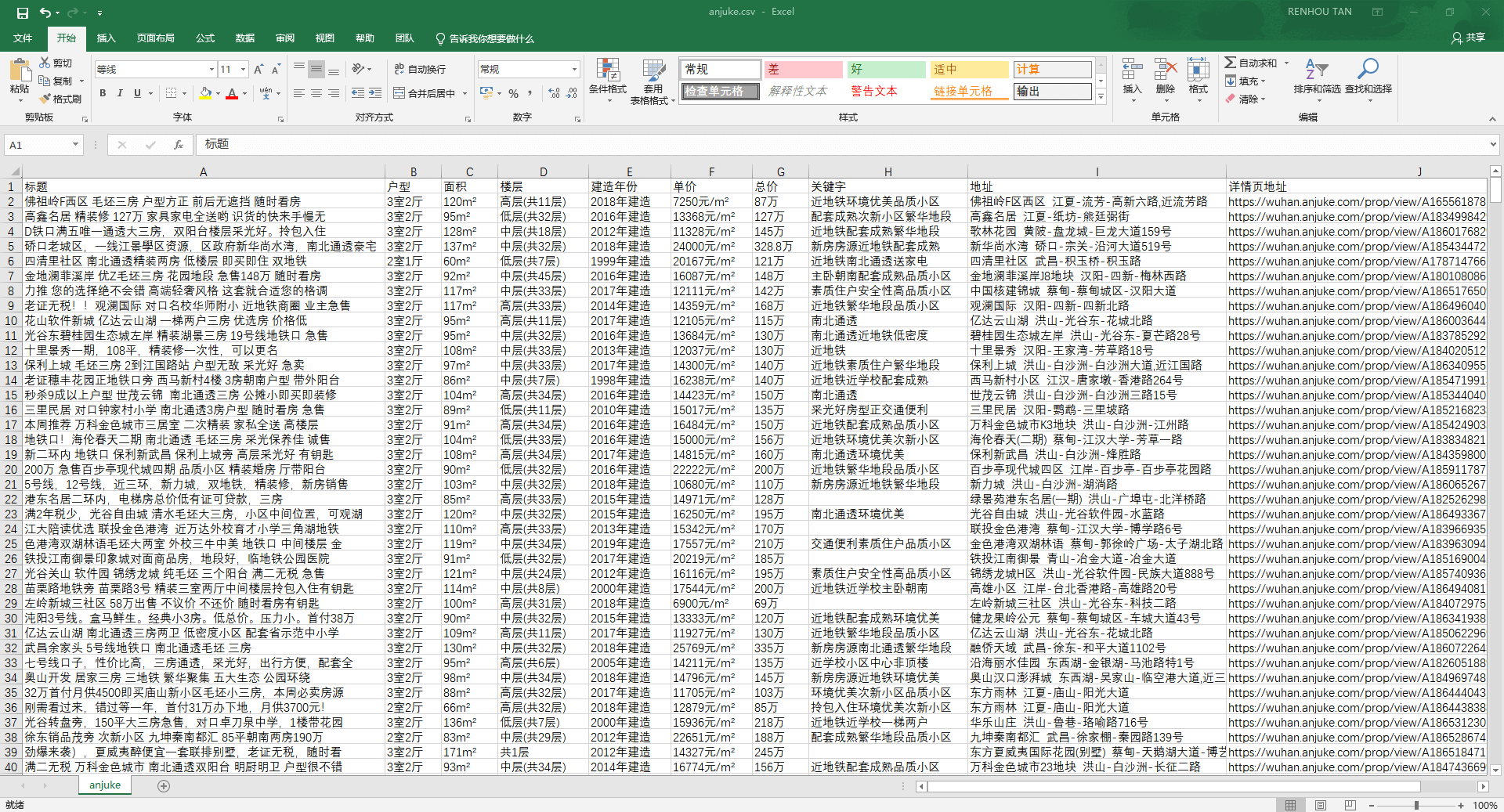
数据储存比较简单,将每个二手房信息组成一个列表,依次写入到 anjuke.csv 文件中即可
```
python
results
=
[
title
,
layout
,
cover
,
floor
,
year
,
unit_price
,
total_price
,
keyword
,
address
,
details_url
]
with
open
(
'anjuke.csv'
,
'a'
,
newline
=
''
,
encoding
=
'utf-8-sig'
)
as
f
:
w
=
csv
.
writer
(
f
)
w
.
writerow
(
results
)
```
---
# <font color=#FF0000>【5x00】完整代码</font>
```
python
# =============================================
# --*-- coding: utf-8 --*--
# @Time : 2019-10-09
# @Author : TRHX
# @Blog : www.itrhx.com
# @CSDN : https://blog.csdn.net/qq_36759224
# @FileName: anjuke.py
# @Software: PyCharm
# =============================================
import
requests
import
time
import
csv
import
random
from
bs4
import
BeautifulSoup
headers
=
{
'User-Agent'
:
'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/75.0.3770.142 Safari/537.36'
}
def
parse_pages
(
url
,
num
):
response
=
requests
.
get
(
url
=
url
,
headers
=
headers
)
soup
=
BeautifulSoup
(
response
.
text
,
'lxml'
)
result_list
=
soup
.
find_all
(
'li'
,
class_
=
'list-item'
)
# print(len(result_list))
for
result
in
result_list
:
# 标题
title
=
result
.
find
(
'a'
,
class_
=
'houseListTitle'
).
text
.
strip
()
# print(title)
# 户型
layout
=
result
.
select
(
'.details-item > span'
)[
0
].
text
# print(layout)
# 面积
cover
=
result
.
select
(
'.details-item > span'
)[
1
].
text
# print(cover)
# 楼层
floor
=
result
.
select
(
'.details-item > span'
)[
2
].
text
# print(floor)
# 建造年份
year
=
result
.
select
(
'.details-item > span'
)[
3
].
text
# print(year)
# 单价
unit_price
=
result
.
find
(
'span'
,
class_
=
'unit-price'
).
text
.
strip
()
# print(unit_price)
# 总价
total_price
=
result
.
find
(
'span'
,
class_
=
'price-det'
).
text
.
strip
()
# print(total_price)
# 关键字
keyword
=
result
.
find
(
'div'
,
class_
=
'tags-bottom'
).
text
.
strip
()
# print(keyword)
# 地址
address
=
result
.
find
(
'span'
,
class_
=
'comm-address'
).
text
.
replace
(
' '
,
''
).
replace
(
'
\n
'
,
''
)
# print(address)
# 详情页url
details_url
=
result
.
find
(
'a'
,
class_
=
'houseListTitle'
)[
'href'
]
# print(details_url)
results
=
[
title
,
layout
,
cover
,
floor
,
year
,
unit_price
,
total_price
,
keyword
,
address
,
details_url
]
with
open
(
'anjuke.csv'
,
'a'
,
newline
=
''
,
encoding
=
'utf-8-sig'
)
as
f
:
w
=
csv
.
writer
(
f
)
w
.
writerow
(
results
)
# 判断是否还有下一页
next_url
=
soup
.
find_all
(
'a'
,
class_
=
'aNxt'
)
if
len
(
next_url
)
!=
0
:
num
+=
1
print
(
'第'
+
str
(
num
)
+
'页数据爬取完毕!'
)
# 3-60秒之间随机暂停
time
.
sleep
(
random
.
randint
(
3
,
60
))
parse_pages
(
next_url
[
0
].
attrs
[
'href'
],
num
)
else
:
print
(
'所有数据爬取完毕!'
)
if
__name__
==
'__main__'
:
with
open
(
'anjuke.csv'
,
'a'
,
newline
=
''
,
encoding
=
'utf-8-sig'
)
as
fp
:
writer
=
csv
.
writer
(
fp
)
writer
.
writerow
([
'标题'
,
'户型'
,
'面积'
,
'楼层'
,
'建造年份'
,
'单价'
,
'总价'
,
'关键字'
,
'地址'
,
'详情页地址'
])
start_num
=
0
start_url
=
'https://wuhan.anjuke.com/sale/'
parse_pages
(
start_url
,
start_num
)
```
---
# <font color=#FF0000>【6x00】数据截图</font>
<fancybox>
</fancybox>
---
# <font color=#FF0000>【7x00】程序不足的地方</font>
-
虽然使用了随机暂停爬取的方法,但是在爬取了大约 20 页的数据后依然会出现验证页面,导致程序终止
-
原来设想的是可以由用户手动输入城市的拼音来查询不同城市的信息,方法是把用户输入的城市拼音和其他参数一起构造成一个 URL,然后对该 URL 发送请求,判断请求返回的代码,如果是 200 就代表可以访问,也就是用户输入的城市是正确的,然而发现即便是输入错误,该 URL 依然可以访问,只不过会跳转到一个正确的页面,没有搞清楚是什么原理,也就无法实现由用户输入城市来查询这个功能
source/_posts/A55-pyspider-hupu.md
0 → 100644
浏览文件 @
066b5155
---
title
:
Python3 爬虫实战 — 虎扑论坛步行街
tags
:
-
爬虫
-
虎扑论坛
categories
:
-
Python3 学习笔记
-
爬虫实战
thumbnail
:
https://cdn.jsdelivr.net/gh/TRHX/ImageHosting/ITRHX-PIC/thumbnail/combat.png
avatar
:
https://cdn.jsdelivr.net/gh/TRHX/CDN-for-itrhx.com@2.1.9/images/trhx.png
---
> 爬取时间:2019-10-12
> 爬取难度:★★☆☆☆☆
> 请求链接:https://bbs.hupu.com/bxj
> 爬取目标:爬取虎扑论坛步行街的帖子,包含主题,作者,发布时间等,数据保存到 MongoDB 数据库
> 涉及知识:请求库 requests、解析库 Beautiful Soup、数据库 MongoDB 的操作
> 完整代码:https://github.com/TRHX/Python3-Spider-Practice/tree/master/hupu
> 其他爬虫实战代码合集(持续更新):https://github.com/TRHX/Python3-Spider-Practice
> 爬虫实战专栏(持续更新):https://itrhx.blog.csdn.net/article/category/9351278
---
<!--more-->
# <font color=#FF0000>【1x00】循环爬取网页模块</font>
观察虎扑论坛步行街分区,请求地址为:https://bbs.hupu.com/bxj
第一页:https://bbs.hupu.com/bxj
第二页:https://bbs.hupu.com/bxj-2
第三页:https://bbs.hupu.com/bxj-3
不难发现,每增加一页,只需要添加
`-页数`
参数即可,最后一页是第 50 页,因此可以利用 for 循环依次爬取,定义一个
`get_pages()`
函数,返回初始化 Beautiful Soup 的对象 page_soup,方便后面的解析函数调用
虽然一共有 50 页,但是当用户访问第 10 页以后的页面的时候,会要求登录虎扑,不然就没法查看,而且登录时会出现智能验证,所以程序只爬取前 10 页的数据
```
python
def
get_pages
(
page_url
):
headers
=
{
'User-Agent'
:
'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/75.0.3770.142 Safari/537.36'
}
response
=
requests
.
get
(
url
=
page_url
,
headers
=
headers
)
page_soup
=
BeautifulSoup
(
response
.
text
,
'lxml'
)
return
page_soup
if
__name__
==
'__main__'
:
for
i
in
range
(
1
,
11
):
url
=
'https://bbs.hupu.com/bxj-'
+
str
(
i
)
soup
=
get_pages
(
url
)
```
---
# <font color=#FF0000>【2x00】解析模块</font>
使用 Beautiful Soup 对网页各个信息进行提取,最后将这些信息放进一个列表里,然后调用列表的
`.append()`
方法,再将每条帖子的列表依次加到另一个新列表里,最终返回的是类似于如下形式的列表:
```
python
[[
'帖子1'
,
'作者1'
],
[
'帖子2'
,
'作者2'
],
[
'帖子3'
,
'作者3'
]]
```
这样做的目的是:方便 MongoDB 依次储存每一条帖子的信息
```
python
def
parse_pages
(
page_soup
):
data_list
=
[]
all_list
=
page_soup
.
find
(
'ul'
,
class_
=
'for-list'
)
post_list
=
all_list
.
find_all
(
'li'
)
# print(result_list)
for
post
in
post_list
:
# 帖子名称
post_title
=
post
.
find
(
'a'
,
class_
=
'truetit'
).
text
# print(post_title)
# 帖子链接
post_url
=
'https://bbs.hupu.com'
+
post
.
find
(
'a'
,
class_
=
'truetit'
)[
'href'
]
# print(post_url)
# 作者
author
=
post
.
select
(
'.author > a'
)[
0
].
text
# print(author)
# 作者主页
author_url
=
post
.
select
(
'.author > a'
)[
0
][
'href'
]
# print(author_url)
# 发布日期
post_date
=
post
.
select
(
'.author > a'
)[
1
].
text
# print(post_date)
reply_view
=
post
.
find
(
'span'
,
class_
=
'ansour'
).
text
# 回复数
post_reply
=
reply_view
.
split
(
'/'
)[
0
].
strip
()
# print(post_reply)
# 浏览量
post_view
=
reply_view
.
split
(
'/'
)[
1
].
strip
()
# print(post_view)
# 最后回复时间
last_data
=
post
.
select
(
'.endreply > a'
)[
0
].
text
# print(last_data)
# 最后回复用户
last_user
=
post
.
select
(
'.endreply > span'
)[
0
].
text
# print(last_user)
data_list
.
append
([
post_title
,
post_url
,
author
,
author_url
,
post_date
,
post_reply
,
post_view
,
last_data
,
last_user
])
# print(data_list)
return
data_list
```
---
# <font color=#FF0000>【3x00】MongoDB 数据储存模块</font>
首先使用
`MongoClient()`
方法,向其传入地址参数 host 和 端口参数 port,指定数据库为
`hupu`
,集合为
`bxj`
将解析函数返回的列表传入到储存函数,依次循环该列表,对每一条帖子的信息进行提取并储存
```
python
def
mongodb
(
data_list
):
client
=
MongoClient
(
'localhost'
,
27017
)
db
=
client
.
hupu
collection
=
db
.
bxj
for
data
in
data_list
:
bxj
=
{
'帖子名称'
:
data
[
0
],
'帖子链接'
:
data
[
1
],
'作者'
:
data
[
2
],
'作者主页'
:
data
[
3
],
'发布日期'
:
str
(
data
[
4
]),
'回复数'
:
data
[
5
],
'浏览量'
:
data
[
6
],
'最后回复时间'
:
str
(
data
[
7
]),
'最后回复用户'
:
data
[
8
]
}
collection
.
insert_one
(
bxj
)
```
---
# <font color=#FF0000>【4x00】完整代码</font>
```
python
# =============================================
# --*-- coding: utf-8 --*--
# @Time : 2019-10-12
# @Author : TRHX
# @Blog : www.itrhx.com
# @CSDN : https://blog.csdn.net/qq_36759224
# @FileName: hupu.py
# @Software: PyCharm
# =============================================
import
requests
import
time
import
random
from
pymongo
import
MongoClient
from
bs4
import
BeautifulSoup
def
get_pages
(
page_url
):
headers
=
{
'User-Agent'
:
'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/75.0.3770.142 Safari/537.36'
}
response
=
requests
.
get
(
url
=
page_url
,
headers
=
headers
)
page_soup
=
BeautifulSoup
(
response
.
text
,
'lxml'
)
return
page_soup
def
parse_pages
(
page_soup
):
data_list
=
[]
all_list
=
page_soup
.
find
(
'ul'
,
class_
=
'for-list'
)
post_list
=
all_list
.
find_all
(
'li'
)
# print(result_list)
for
post
in
post_list
:
# 帖子名称
post_title
=
post
.
find
(
'a'
,
class_
=
'truetit'
).
text
# print(post_title)
# 帖子链接
post_url
=
'https://bbs.hupu.com'
+
post
.
find
(
'a'
,
class_
=
'truetit'
)[
'href'
]
# print(post_url)
# 作者
author
=
post
.
select
(
'.author > a'
)[
0
].
text
# print(author)
# 作者主页
author_url
=
post
.
select
(
'.author > a'
)[
0
][
'href'
]
# print(author_url)
# 发布日期
post_date
=
post
.
select
(
'.author > a'
)[
1
].
text
# print(post_date)
reply_view
=
post
.
find
(
'span'
,
class_
=
'ansour'
).
text
# 回复数
post_reply
=
reply_view
.
split
(
'/'
)[
0
].
strip
()
# print(post_reply)
# 浏览量
post_view
=
reply_view
.
split
(
'/'
)[
1
].
strip
()
# print(post_view)
# 最后回复时间
last_data
=
post
.
select
(
'.endreply > a'
)[
0
].
text
# print(last_data)
# 最后回复用户
last_user
=
post
.
select
(
'.endreply > span'
)[
0
].
text
# print(last_user)
data_list
.
append
([
post_title
,
post_url
,
author
,
author_url
,
post_date
,
post_reply
,
post_view
,
last_data
,
last_user
])
# print(data_list)
return
data_list
def
mongodb
(
data_list
):
client
=
MongoClient
(
'localhost'
,
27017
)
db
=
client
.
hupu
collection
=
db
.
bxj
for
data
in
data_list
:
bxj
=
{
'帖子名称'
:
data
[
0
],
'帖子链接'
:
data
[
1
],
'作者'
:
data
[
2
],
'作者主页'
:
data
[
3
],
'发布日期'
:
str
(
data
[
4
]),
'回复数'
:
data
[
5
],
'浏览量'
:
data
[
6
],
'最后回复时间'
:
str
(
data
[
7
]),
'最后回复用户'
:
data
[
8
]
}
collection
.
insert_one
(
bxj
)
if
__name__
==
'__main__'
:
for
i
in
range
(
1
,
11
):
url
=
'https://bbs.hupu.com/bxj-'
+
str
(
i
)
soup
=
get_pages
(
url
)
result_list
=
parse_pages
(
soup
)
mongodb
(
result_list
)
print
(
'第'
,
i
,
'页数据爬取完毕!'
)
time
.
sleep
(
random
.
randint
(
3
,
10
))
print
(
'前10页所有数据爬取完毕!'
)
```
---
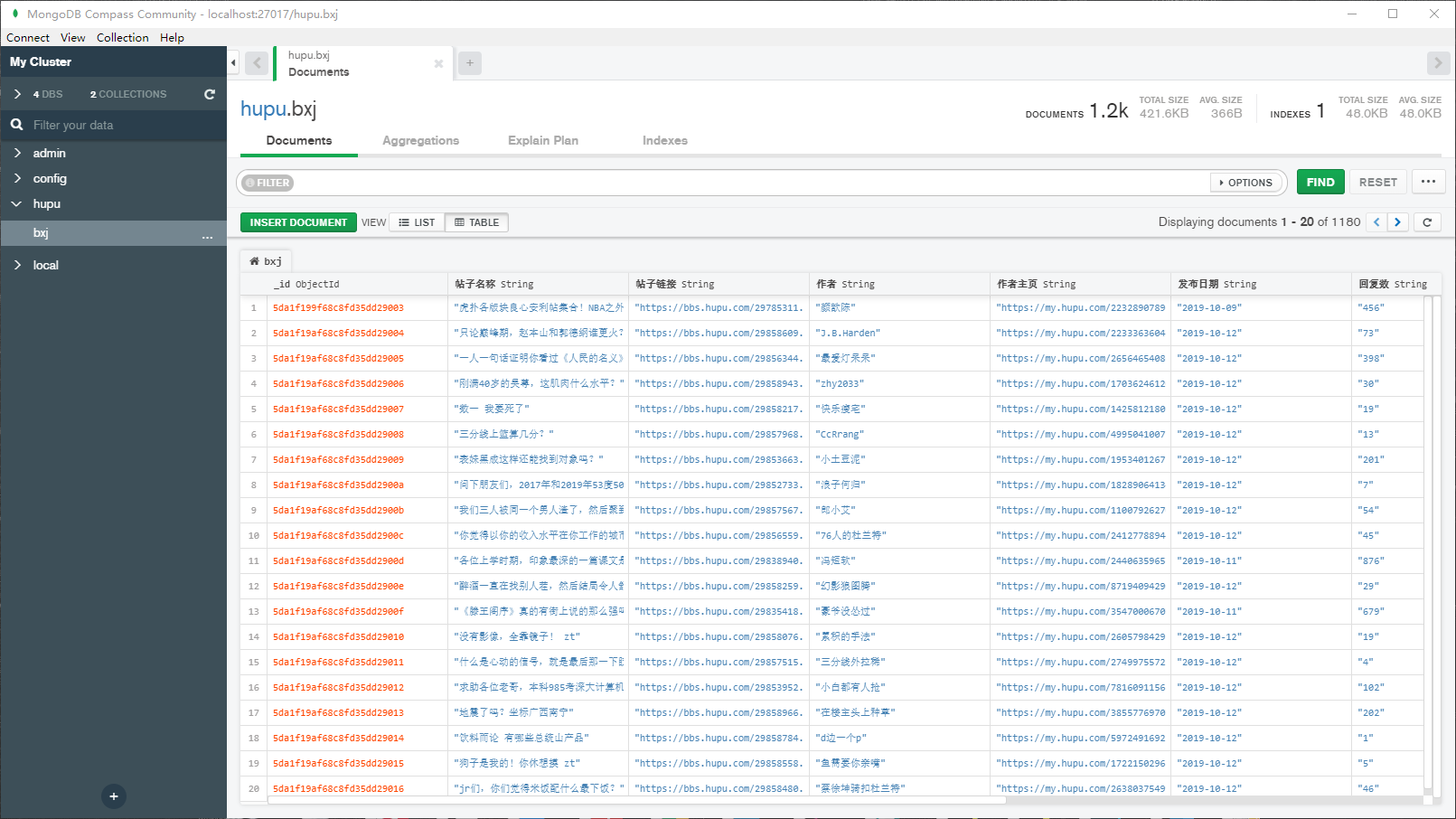
# <font color=#FF0000>【5x00】数据截图</font>
一共爬取到 1180 条数据:
<fancybox>
</fancybox>
# <font color=#FF0000>【6x00】程序不足的地方</font>
程序只能爬取前 10 页的数据,因为虎扑论坛要求从第 11 页开始,必须登录账号才能查看,并且登录时会有智能验证,可以使用自动化测试工具 Selenium 模拟登录账号后再进行爬取。
source/_posts/A56-pyspider-bilibili-login.md
0 → 100644
浏览文件 @
066b5155
此差异已折叠。
点击以展开。
source/_posts/A57-pyspider-12306-login.md
0 → 100644
浏览文件 @
066b5155
---
title
:
Python3 爬虫实战 — 模拟登陆12306【点触验证码对抗】
tags
:
-
爬虫
-
12306
categories
:
-
Python3 学习笔记
-
爬虫实战
thumbnail
:
https://cdn.jsdelivr.net/gh/TRHX/ImageHosting/ITRHX-PIC/thumbnail/combat.png
avatar
:
https://cdn.jsdelivr.net/gh/TRHX/CDN-for-itrhx.com@2.1.9/images/trhx.png
---
> 登陆时间:2019-10-21
> 实现难度:★★★☆☆☆
> 请求链接:https://kyfw.12306.cn/otn/resources/login.html
> 实现目标:模拟登陆中国铁路12306,攻克点触验证码
> 涉及知识:点触验证码的攻克、自动化测试工具 Selenium 的使用、对接在线打码平台
> 完整代码:https://github.com/TRHX/Python3-Spider-Practice/tree/master/12306-login
> 其他爬虫实战代码合集(持续更新):https://github.com/TRHX/Python3-Spider-Practice
> 爬虫实战专栏(持续更新):https://itrhx.blog.csdn.net/article/category/9351278
---
<!--more-->
# <font color=#ff0000>【1x00】思维导图</font>
<fancybox>
</fancybox>
-
利用自动化测试工具 Selenium 直接模拟人的行为方式来完成验证
-
发送请求,出现验证码后,剪裁并保存验证码图片
-
选择在线打码平台,获取其API,以字节流格式发送图片
-
打码平台人工识别验证码,返回验证码的坐标信息
-
解析返回的坐标信息,模拟点击验证码,完成验证后点击登陆
<fancybox>
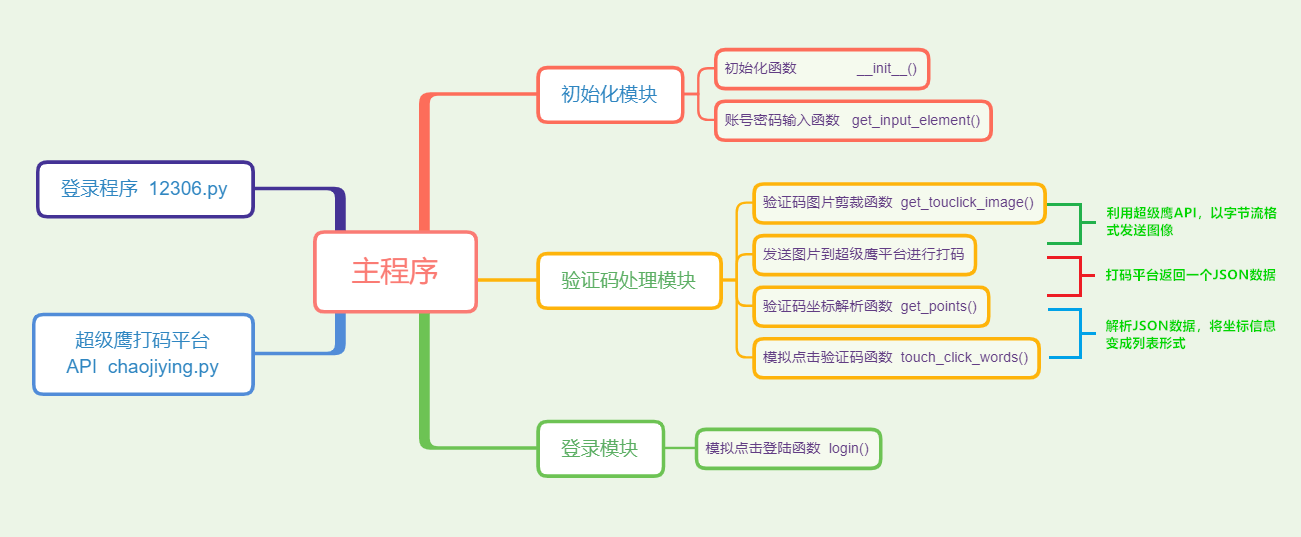
</fancybox>
---
# <font color=#ff0000>【2x00】打码平台选择</font>
关于打码平台:在线打码平台全部都是人工在线识别,准确率非常高,原理就是先将验证码图片提交给平台,平台会返回识别结果在图片中的坐标位置,然后我们再解析坐标模拟点击即可,常见的打码平台有超级鹰、云打码等,打码平台是收费的,拿超级鹰来说,1元 = 1000题分,识别一次验证码将花费一定的题分,不同类型验证码需要的题分不同,验证码越复杂所需题分越高,比如 7 位中文汉字需要 70 题分,常见 4 ~ 6 位英文数字只要 10 题分,其他打码平台价格也都差不多,本次实战使用
[
超级鹰打码平台
](
http://www.chaojiying.com/
)
使用打码平台:在超级鹰打码平台注册账号,官网:http://www.chaojiying.com/ ,充值一块钱得到 1000 题分,在用户中心里面申请一个软件 ID ,在
[
价格体系
](
http://www.chaojiying.com/price.html
)
里面确定验证码的类型,先观察 12306 官网,发现验证码是要我们点击所有满足条件的图片,一般有 1 至 4 张图片满足要求,由此可确定在超级鹰打码平台的验证码类型为 9004(坐标多选,返回1~4个坐标,如:x1,y1|x2,y2|x3,y3), 然后在
[
开发文档
](
http://www.chaojiying.com/api.html
)
里面获取其
[
Python API
](
http://www.chaojiying.com/download/Chaojiying_Python.rar
)
,下载下来以备后用
---
# <font color=#ff0000>【3x00】初始化模块</font>
## <font color=#1BC3FB>【3x01】初始化函数</font>
```
python
# 12306账号密码
USERNAME
=
'155********'
PASSWORD
=
'***********'
# 超级鹰打码平台账号密码
CHAOJIYING_USERNAME
=
'*******'
CHAOJIYING_PASSWORD
=
'*******'
# 超级鹰打码平台软件ID
CHAOJIYING_SOFT_ID
=
'********'
# 验证码类型
CHAOJIYING_KIND
=
'9004'
class
CrackTouClick
():
def
__init__
(
self
):
self
.
url
=
'https://kyfw.12306.cn/otn/resources/login.html'
# path是谷歌浏览器驱动的目录,如果已经将目录添加到系统变量,则不用设置此路径
path
=
r
'F:\PycharmProjects\Python3爬虫\chromedriver.exe'
chrome_options
=
Options
()
chrome_options
.
add_argument
(
'--start-maximized'
)
self
.
browser
=
webdriver
.
Chrome
(
executable_path
=
path
,
chrome_options
=
chrome_options
)
self
.
wait
=
WebDriverWait
(
self
.
browser
,
20
)
self
.
username
=
USERNAME
self
.
password
=
PASSWORD
self
.
chaojiying
=
ChaojiyingClient
(
CHAOJIYING_USERNAME
,
CHAOJIYING_PASSWORD
,
CHAOJIYING_SOFT_ID
)
```
定义 12306 账号(
`USERNAME`
)、密码(
`PASSWORD`
)、超级鹰用户名(
`CHAOJIYING_USERNAME`
)、超级鹰登录密码(
`CHAOJIYING_PASSWORD`
)、超级鹰软件 ID(
`CHAOJIYING_SOFT_ID`
)、验证码类型(
`CHAOJIYING_KIND`
),登录页面 url ,谷歌浏览器驱动的目录(
`path`
),浏览器启动参数等,将超级鹰账号密码等相关参数传递给超级鹰 API
---
## <font color=#1BC3FB>【3x02】账号密码输入函数</font>
```
python
def
get_input_element
(
self
):
# 登录页面发送请求
self
.
browser
.
get
(
self
.
url
)
# 登录页面默认是扫码登录,所以首先要点击账号登录
login
=
self
.
wait
.
until
(
EC
.
presence_of_element_located
((
By
.
CSS_SELECTOR
,
'.login-hd-account'
)))
login
.
click
()
time
.
sleep
(
3
)
# 查找到账号密码输入位置的元素
username
=
self
.
wait
.
until
(
EC
.
presence_of_element_located
((
By
.
CSS_SELECTOR
,
'input#J-userName'
)))
password
=
self
.
wait
.
until
(
EC
.
presence_of_element_located
((
By
.
CSS_SELECTOR
,
'input#J-password'
)))
# 输入账号密码
username
.
send_keys
(
self
.
username
)
password
.
send_keys
(
self
.
password
)
```
分析页面可知,登陆页面默认出现的是扫描二维码登陆,所以要先点击账号登录,找到该 CSS 元素为
`login-hd-account`
,调用
`click()`
方法实现模拟点击,此时出现账号密码输入框,同样找到其 ID 分别为
`J-userName`
和
`J-password`
,调用
`send_keys()`
方法输入账号密码
---
# <font color=#ff0000>【4x00】验证码处理模块</font>
```
python
def
crack
(
self
):
# 调用账号密码输入函数
self
.
get_input_element
()
# 调用验证码图片剪裁函数
image
=
self
.
get_touclick_image
()
bytes_array
=
BytesIO
()
image
.
save
(
bytes_array
,
format
=
'PNG'
)
# 利用超级鹰打码平台的 API PostPic() 方法把图片发送给超级鹰后台,发送的图像是字节流格式,返回的结果是一个JSON
result
=
self
.
chaojiying
.
PostPic
(
bytes_array
.
getvalue
(),
CHAOJIYING_KIND
)
print
(
result
)
# 调用验证码坐标解析函数
locations
=
self
.
get_points
(
result
)
# 调用模拟点击验证码函数
self
.
touch_click_words
(
locations
)
# 调用模拟点击登录函数
self
.
login
()
try
:
# 查找是否出现用户的姓名,若出现表示登录成功
success
=
self
.
wait
.
until
(
EC
.
text_to_be_present_in_element
((
By
.
CSS_SELECTOR
,
'.welcome-name'
),
'谭先生'
))
print
(
success
)
cc
=
self
.
browser
.
find_element
(
By
.
CSS_SELECTOR
,
'.welcome-name'
)
print
(
'用户'
+
cc
.
text
+
'登录成功'
)
# 若没有出现表示登录失败,继续重试,超级鹰会返回本次识别的分值
except
TimeoutException
:
self
.
chaojiying
.
ReportError
(
result
[
'pic_id'
])
self
.
crack
()
```
`crack()`
为验证码处理模块的主函数
调用账号密码输入函数
`get_input_element()`
,等待账号密码输入完毕
调用验证码图片剪裁函数
`get_touclick_image()`
,得到验证码图片
利用超级鹰打码平台的 API
`PostPic()`
方法把图片发送给超级鹰后台,发送的图像是字节流格式,返回的结果是一个JSON,如果识别成功,典型的返回结果类似于:
```
python
{
'err_no'
:
0
,
'err_str'
:
'OK'
,
'pic_id'
:
'6002001380949200001'
,
'pic_str'
:
'132,127|56,77'
,
'md5'
:
'1f8e1d4bef8b11484cb1f1f34299865b'
}
```
其中,
`pic_str`
就是识别的文字的坐标,是以字符串形式返回的,每个坐标都以
`|`
分隔
调用
`get_points()`
函数解析超级鹰识别结果
调用
`touch_click_words()`
函数对符合要求的图片进行点击
调用模拟点击登录函数
`login()`
,点击登陆按钮模拟登陆
使用
`try-except`
语句判断是否出现了用户信息,判断依据是是否有用户姓名的出现,出现的姓名和实际姓名一致则登录成功,如果失败了就重试,超级鹰会返回该分值
---
## <font color=#1BC3FB>【4x01】验证码图片剪裁函数</font>
```
python
def
get_touclick_image
(
self
,
name
=
'12306.png'
):
# 获取验证码的位置
element
=
self
.
wait
.
until
(
EC
.
presence_of_element_located
((
By
.
CSS_SELECTOR
,
'.login-pwd-code'
)))
time
.
sleep
(
3
)
location
=
element
.
location
size
=
element
.
size
top
,
bottom
,
left
,
right
=
location
[
'y'
],
location
[
'y'
]
+
size
[
'height'
],
location
[
'x'
],
location
[
'x'
]
+
size
[
'width'
]
# 先对整个页面截图
screenshot
=
self
.
browser
.
get_screenshot_as_png
()
screenshot
=
Image
.
open
(
BytesIO
(
screenshot
))
# 根据验证码坐标信息,剪裁出验证码图片
captcha
=
screenshot
.
crop
((
left
,
top
,
right
,
bottom
))
captcha
.
save
(
name
)
return
captcha
```
首先查找到验证码的坐标信息,先对整个页面截图,然后根据验证码坐标信息,剪裁出验证码图片
location 属性可以返回该图片对象在浏览器中的位置,坐标轴是以屏幕左上角为原点,x 轴向右递增,y 轴向下递增,size 属性可以返回该图片对象的高度和宽度,由此可以得到验证码的位置信息
---
## <font color=#1BC3FB>【4x02】验证码坐标解析函数</font>
```
python
def
get_points
(
self
,
captcha_result
):
# 超级鹰识别结果以字符串形式返回,每个坐标都以|分隔
groups
=
captcha_result
.
get
(
'pic_str'
).
split
(
'|'
)
# 将坐标信息变成列表的形式
locations
=
[[
int
(
number
)
for
number
in
group
.
split
(
','
)]
for
group
in
groups
]
return
locations
```
`get_points()`
方法将超级鹰的验证码识别结果变成列表的形式
---
## <font color=#1BC3FB>【4x03】模拟点击验证码函数</font>
```
python
def
touch_click_words
(
self
,
locations
):
element
=
self
.
wait
.
until
(
EC
.
presence_of_element_located
((
By
.
CSS_SELECTOR
,
'.login-pwd-code'
)))
# 循环点击正确验证码的坐标
for
location
in
locations
:
print
(
location
)
ActionChains
(
self
.
browser
).
move_to_element_with_offset
(
element
,
location
[
0
],
location
[
1
]).
click
().
perform
()
```
循环提取正确的验证码坐标信息,依次点击验证码
---
# <font color=#ff0000>【5x00】登录模块</font>
```
python
def
login
(
self
):
submit
=
self
.
wait
.
until
(
EC
.
element_to_be_clickable
((
By
.
ID
,
'J-login'
)))
submit
.
click
()
```
分析页面,找到登陆按钮的 ID 为
`J-login`
,调用
`click()`
方法模拟点击按钮实现登录
---
# <font color=#ff0000>【6x00】完整代码</font>
## <font color=#1BC3FB>【6x01】12306.py</font>
```
python
# =============================================
# --*-- coding: utf-8 --*--
# @Time : 2019-10-21
# @Author : TRHX
# @Blog : www.itrhx.com
# @CSDN : https://blog.csdn.net/qq_36759224
# @FileName: 12306.py
# @Software: PyCharm
# =============================================
import
time
from
io
import
BytesIO
from
PIL
import
Image
from
selenium
import
webdriver
from
selenium.webdriver.chrome.options
import
Options
from
selenium.webdriver
import
ActionChains
from
selenium.webdriver.common.by
import
By
from
selenium.webdriver.support.ui
import
WebDriverWait
from
selenium.webdriver.support
import
expected_conditions
as
EC
from
chaojiying
import
ChaojiyingClient
from
selenium.common.exceptions
import
TimeoutException
# 12306账号密码
USERNAME
=
'155********'
PASSWORD
=
'***********'
# 超级鹰打码平台账号密码
CHAOJIYING_USERNAME
=
'********'
CHAOJIYING_PASSWORD
=
'********'
# 超级鹰打码平台软件ID
CHAOJIYING_SOFT_ID
=
'******'
# 验证码类型
CHAOJIYING_KIND
=
'9004'
class
CrackTouClick
():
def
__init__
(
self
):
self
.
url
=
'https://kyfw.12306.cn/otn/resources/login.html'
# path是谷歌浏览器驱动的目录,如果已经将目录添加到系统变量,则不用设置此路径
path
=
r
'F:\PycharmProjects\Python3爬虫\chromedriver.exe'
chrome_options
=
Options
()
chrome_options
.
add_argument
(
'--start-maximized'
)
self
.
browser
=
webdriver
.
Chrome
(
executable_path
=
path
,
chrome_options
=
chrome_options
)
self
.
wait
=
WebDriverWait
(
self
.
browser
,
20
)
self
.
username
=
USERNAME
self
.
password
=
PASSWORD
self
.
chaojiying
=
ChaojiyingClient
(
CHAOJIYING_USERNAME
,
CHAOJIYING_PASSWORD
,
CHAOJIYING_SOFT_ID
)
def
crack
(
self
):
# 调用账号密码输入函数
self
.
get_input_element
()
# 调用验证码图片剪裁函数
image
=
self
.
get_touclick_image
()
bytes_array
=
BytesIO
()
image
.
save
(
bytes_array
,
format
=
'PNG'
)
# 利用超级鹰打码平台的 API PostPic() 方法把图片发送给超级鹰后台,发送的图像是字节流格式,返回的结果是一个JSON
result
=
self
.
chaojiying
.
PostPic
(
bytes_array
.
getvalue
(),
CHAOJIYING_KIND
)
print
(
result
)
# 调用验证码坐标解析函数
locations
=
self
.
get_points
(
result
)
# 调用模拟点击验证码函数
self
.
touch_click_words
(
locations
)
# 调用模拟点击登录函数
self
.
login
()
try
:
# 查找是否出现用户的姓名,若出现表示登录成功
success
=
self
.
wait
.
until
(
EC
.
text_to_be_present_in_element
((
By
.
CSS_SELECTOR
,
'.welcome-name'
),
'谭先生'
))
print
(
success
)
cc
=
self
.
browser
.
find_element
(
By
.
CSS_SELECTOR
,
'.welcome-name'
)
print
(
'用户'
+
cc
.
text
+
'登录成功'
)
# 若没有出现表示登录失败,继续重试,超级鹰会返回本次识别的分值
except
TimeoutException
:
self
.
chaojiying
.
ReportError
(
result
[
'pic_id'
])
self
.
crack
()
# 账号密码输入函数
def
get_input_element
(
self
):
# 登录页面发送请求
self
.
browser
.
get
(
self
.
url
)
# 登录页面默认是扫码登录,所以首先要点击账号登录
login
=
self
.
wait
.
until
(
EC
.
presence_of_element_located
((
By
.
CSS_SELECTOR
,
'.login-hd-account'
)))
login
.
click
()
time
.
sleep
(
3
)
# 查找到账号密码输入位置的元素
username
=
self
.
wait
.
until
(
EC
.
presence_of_element_located
((
By
.
CSS_SELECTOR
,
'input#J-userName'
)))
password
=
self
.
wait
.
until
(
EC
.
presence_of_element_located
((
By
.
CSS_SELECTOR
,
'input#J-password'
)))
# 输入账号密码
username
.
send_keys
(
self
.
username
)
password
.
send_keys
(
self
.
password
)
# 验证码图片剪裁函数
def
get_touclick_image
(
self
,
name
=
'12306.png'
):
# 获取验证码的位置
element
=
self
.
wait
.
until
(
EC
.
presence_of_element_located
((
By
.
CSS_SELECTOR
,
'.login-pwd-code'
)))
time
.
sleep
(
3
)
location
=
element
.
location
size
=
element
.
size
top
,
bottom
,
left
,
right
=
location
[
'y'
],
location
[
'y'
]
+
size
[
'height'
],
location
[
'x'
],
location
[
'x'
]
+
size
[
'width'
]
# 先对整个页面截图
screenshot
=
self
.
browser
.
get_screenshot_as_png
()
screenshot
=
Image
.
open
(
BytesIO
(
screenshot
))
# 根据验证码坐标信息,剪裁出验证码图片
captcha
=
screenshot
.
crop
((
left
,
top
,
right
,
bottom
))
captcha
.
save
(
name
)
return
captcha
# 验证码坐标解析函数,分析超级鹰返回的坐标
def
get_points
(
self
,
captcha_result
):
# 超级鹰识别结果以字符串形式返回,每个坐标都以|分隔
groups
=
captcha_result
.
get
(
'pic_str'
).
split
(
'|'
)
# 将坐标信息变成列表的形式
locations
=
[[
int
(
number
)
for
number
in
group
.
split
(
','
)]
for
group
in
groups
]
return
locations
# 模拟点击验证码函数
def
touch_click_words
(
self
,
locations
):
element
=
self
.
wait
.
until
(
EC
.
presence_of_element_located
((
By
.
CSS_SELECTOR
,
'.login-pwd-code'
)))
# 循环点击正确验证码的坐标
for
location
in
locations
:
print
(
location
)
ActionChains
(
self
.
browser
).
move_to_element_with_offset
(
element
,
location
[
0
],
location
[
1
]).
click
().
perform
()
# 模拟点击登录函数
def
login
(
self
):
submit
=
self
.
wait
.
until
(
EC
.
element_to_be_clickable
((
By
.
ID
,
'J-login'
)))
submit
.
click
()
if
__name__
==
'__main__'
:
crack
=
CrackTouClick
()
crack
.
crack
()
```
---
## <font color=#1BC3FB>【6x02】chaojiying.py</font>
```
python
import
requests
from
hashlib
import
md5
class
ChaojiyingClient
(
object
):
def
__init__
(
self
,
username
,
password
,
soft_id
):
self
.
username
=
username
password
=
password
.
encode
(
'utf8'
)
self
.
password
=
md5
(
password
).
hexdigest
()
self
.
soft_id
=
soft_id
self
.
base_params
=
{
'user'
:
self
.
username
,
'pass2'
:
self
.
password
,
'softid'
:
self
.
soft_id
,
}
self
.
headers
=
{
'Connection'
:
'Keep-Alive'
,
'User-Agent'
:
'Mozilla/4.0 (compatible; MSIE 8.0; Windows NT 5.1; Trident/4.0)'
,
}
def
PostPic
(
self
,
im
,
codetype
):
"""
im: 图片字节
codetype: 题目类型 参考 http://www.chaojiying.com/price.html
"""
params
=
{
'codetype'
:
codetype
,
}
params
.
update
(
self
.
base_params
)
files
=
{
'userfile'
:
(
'ccc.jpg'
,
im
)}
r
=
requests
.
post
(
'http://upload.chaojiying.net/Upload/Processing.php'
,
data
=
params
,
files
=
files
,
headers
=
self
.
headers
)
return
r
.
json
()
def
ReportError
(
self
,
im_id
):
"""
im_id:报错题目的图片ID
"""
params
=
{
'id'
:
im_id
,
}
params
.
update
(
self
.
base_params
)
r
=
requests
.
post
(
'http://upload.chaojiying.net/Upload/ReportError.php'
,
data
=
params
,
headers
=
self
.
headers
)
return
r
.
json
()
```
---
# <font color=#ff0000>【7x00】效果实现动图</font>
最终实现效果图:(关键信息已经过打码处理)
<fancybox>
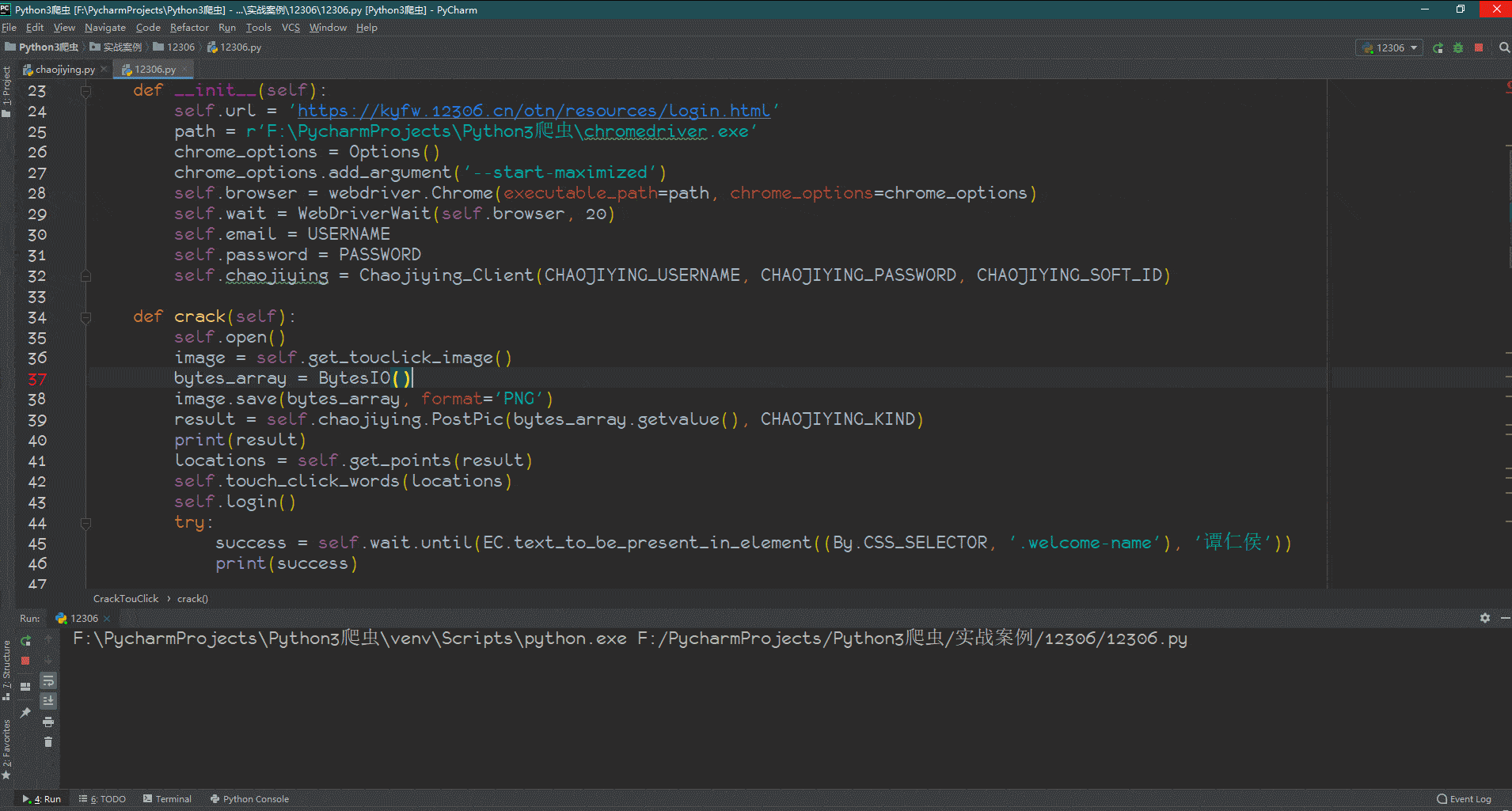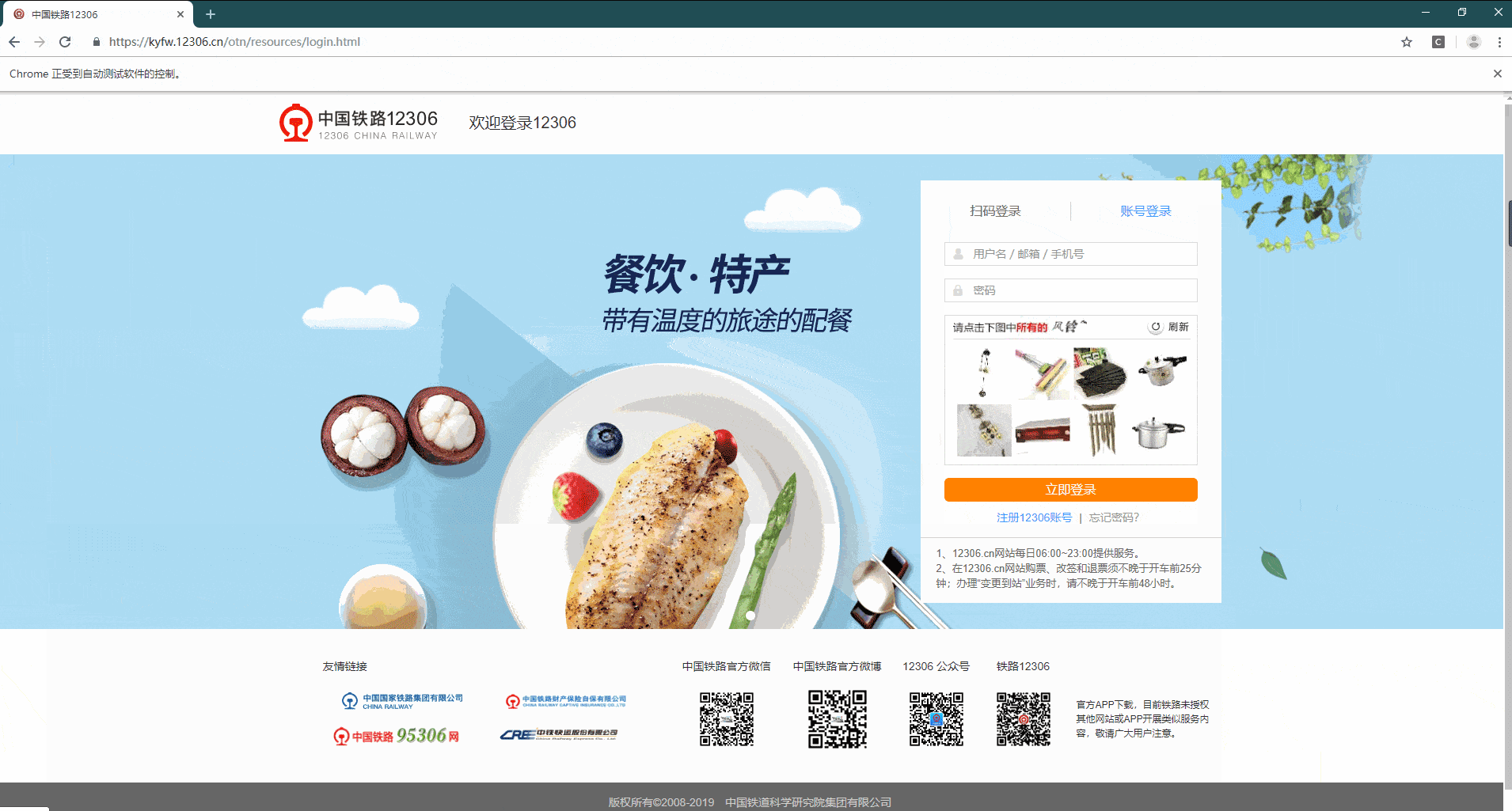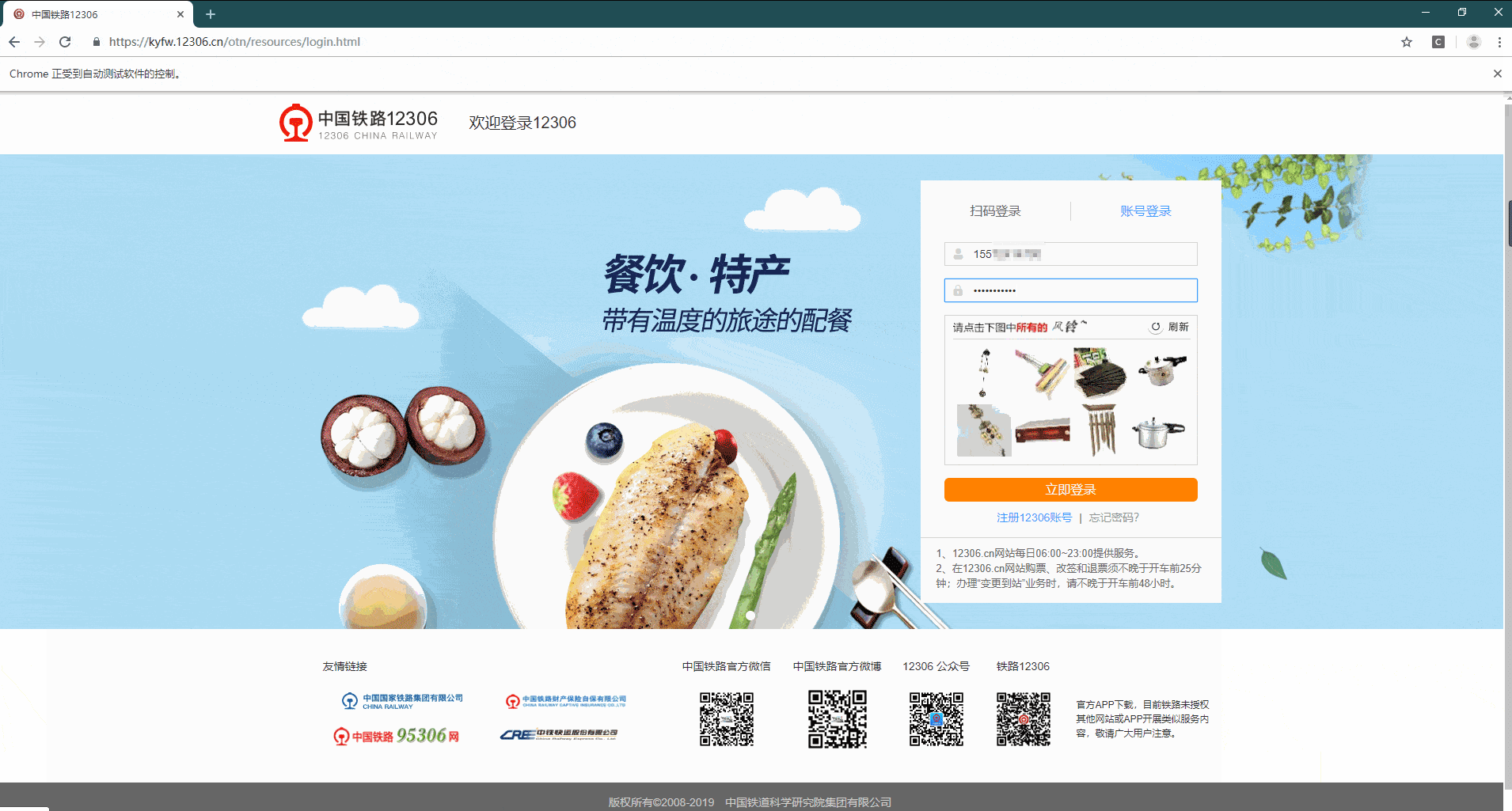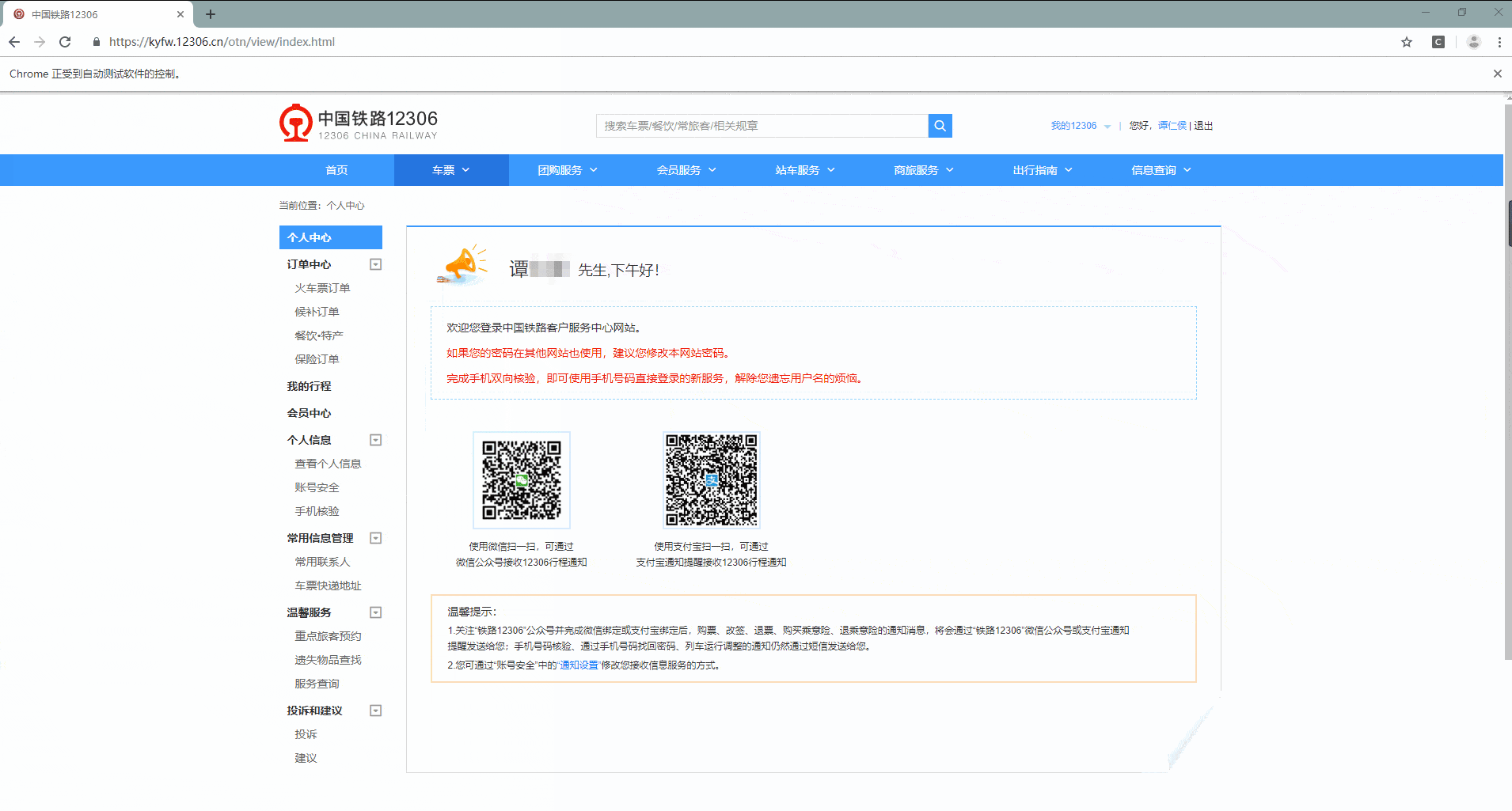
</fancybox>
source/_posts/A58-pyspider-58tongcheng.md
0 → 100644
浏览文件 @
066b5155
此差异已折叠。
点击以展开。
source/comments/index.md
浏览文件 @
066b5155
...
...
@@ -6,5 +6,4 @@ meta:
footer
:
false
sidebar
:
false
---
<div class="style-example example"><ul class="pure circle center about"><li><img src="https://cdn.jsdelivr.net/gh/TRHX/CDN-for-itrhx.com@2.2.0/images/trhx.png" data-original="https://cdn.jsdelivr.net/gh/TRHX/CDN-for-itrhx.com@2.2.0/images/trhx.png"></li></ul><center><a href="https://github.com/TRHX" target="_blank" title="GITHUB">GITHUB</a> <a href="http://csdn.itrhx.com/" target="_blank" title="CSDN">CSDN</a> <a href="https://www.cnblogs.com/TRHX/" target="_blank" title="博客园">博客园</a> <a href="https://www.zhihu.com/people/tan-70-56/activities" target="_blank" title="知乎">知乎</a> <a href="http://wpa.qq.com/msgrd?v=3&uin=2273902448&site=qq&menu=yes" target="_blank" title="QQ">QQ</a> <a href="https://t.me/TRHX" target="_blank" title="TELEGRAM">TELEGRAM</a> <a href="http://mail.qq.com/cgi-bin/qm_share?t=qm_mailme&email=-4uNl4e-mZCHkp6Wk9GckJI" target="_blank" title="EMAIL">EMAIL</a> <a href="https://www.itrhx.com/atom.xml" target="_blank" title="RSS">RSS</a></center><p></p><hr><p></p><center>采用 Gitalk 评论系统,需使用 GitHub 账号登录,请尽情灌水吧!<p></p><hr><p></p></center><center><marquee><font style="color: #ff0000; font-weight: normal; font-size: 30pt; line-height: normal; font-style: normal; font-variant: normal" face="楷体">热烈庆祝中华人民共和国成立七十周年💖</font></marquee><p></p><hr><p></p></center><img src="https://cdn.jsdelivr.net/gh/TRHX/CDN-for-itrhx.com@2.2.0/images/70.jpg"><br><img src="https://cdn.jsdelivr.net/gh/TRHX/CDN-for-itrhx.com@2.2.0/images/logo2.png"><br><img src="https://cdn.jsdelivr.net/gh/TRHX/CDN-for-itrhx.com@2.2.0/images/china.png">
<div class="style-example example"><ul class="pure circle center about"><li><img src="https://cdn.jsdelivr.net/gh/TRHX/CDN-for-itrhx.com@2.2.0/images/trhx.png" data-original="https://cdn.jsdelivr.net/gh/TRHX/CDN-for-itrhx.com@2.2.0/images/trhx.png"></li></ul><center><a href="https://github.com/TRHX" rel="GitHub" target="_blank" title="GitHub"><i class="fab fa-github"></i></a> <a href="http://csdn.itrhx.com/" rel="CSDN" target="_blank" title="CSDN"><i class="fab fa-cuttlefish"></i></a> <a href="https://www.cnblogs.com/TRHX/" rel="博客园" target="_blank" title="博客园"><i class="fa fa-blog"></i></a> <a href="https://www.zhihu.com/people/tan-70-56/activities" rel="知乎" target="_blank" title="知乎"><i class="fab fa-zhihu"></i></a> <a href="http://wpa.qq.com/msgrd?v=3&uin=2273902448&site=qq&menu=yes" rel="QQ" target="_blank" title="QQ"><i class="fab fa-qq"></i></a> <a href="https://t.me/TRHX" rel="Telegram" target="_blank" title="Telegram"><i class="fab fa-telegram-plane"></i></a> <a href="http://mail.qq.com/cgi-bin/qm_share?t=qm_mailme&email=-4uNl4e-mZCHkp6Wk9GckJI" rel="Email" target="_blank" title="Email"><i class="fa fa-envelope"></i></a> <a href="https://www.itrhx.com/atom.xml" rel="RSS" target="_blank" title="RSS"><i class="fa fa-rss"></i></a></center><p></p><hr><p></p><center>采用 Gitalk 评论系统,需使用 GitHub 账号登录,请尽情灌水吧!😉<p></p><hr><p></p></center><center><img src="https://cdn.jsdelivr.net/gh/TRHX/CDN-for-itrhx.com@2.2.0/images/logo2.png"><br><img src="https://cdn.jsdelivr.net/gh/TRHX/CDN-for-itrhx.com@2.2.0/images/china.png">
source/friends/index.md
浏览文件 @
066b5155
...
...
@@ -28,21 +28,14 @@ links:
-
人工智能
-
人生感悟
-
name
:
欧阳博客
avatar
:
https://cdn.jsdelivr.net/gh/TRHX/ImageHosting/ITRHX-LINKS/5658.png
url
:
https://5658.pw/
backgroundColor
:
'
#967ADC'
textColor
:
'
#fff'
tags
:
-
三分孤独,七分狂傲
-
name
:
shansan
avatar
:
https://cdn.jsdelivr.net/gh/TRHX/ImageHosting/ITRHX-LINKS/shansan.jpeg
url
:
https://shan
san.top
/
url
:
https://shan
333.cn
/
backgroundColor
:
'
#A47366'
textColor
:
'
#fff'
tags
:
-
C++
-
Python
-
name
:
yue_luo‘s Blog
avatar
:
https://cdn.jsdelivr.net/gh/TRHX/ImageHosting/ITRHX-LINKS/yueluo.png
...
...
@@ -58,7 +51,7 @@ links:
backgroundColor
:
'
#B96948'
textColor
:
'
#fff'
tags
:
-
生
信
-
生
物信息
-
Python
-
name
:
一去二三遥
...
...
@@ -87,14 +80,15 @@ links:
textColor
:
'
#fff'
tags
:
-
iOS
-
前端
-
name
:
清酒踏月
avatar
:
https://cdn.jsdelivr.net/gh/TRHX/ImageHosting/ITRHX-LINKS/lkxin.png
url
:
https://www.lkxin.cn/
backgroundColor
:
'
#
FE7472
'
backgroundColor
:
'
#
967ADC
'
textColor
:
'
#fff'
tags
:
-
技术
-
网络
技术
-
前端
-
name
:
Mark's blog
...
...
@@ -121,7 +115,9 @@ links:
backgroundColor
:
'
#53AECA'
textColor
:
'
#fff'
tags
:
-
今日事 今日畢
-
Android
-
Java
-
前端
-
name
:
attack204
avatar
:
https://cdn.jsdelivr.net/gh/TRHX/ImageHosting/ITRHX-LINKS/attack204.png
...
...
@@ -148,7 +144,8 @@ links:
backgroundColor
:
'
#E9535B'
textColor
:
'
#fff'
tags
:
-
技术
-
Python
-
JavaScript
-
二次元
-
name
:
asplun
...
...
@@ -165,8 +162,8 @@ links:
backgroundColor
:
'
#8FB0C7'
textColor
:
'
#fff'
tags
:
-
人工智能
-
人生感悟
-
前端
-
摄影
-
name
:
Tohot
avatar
:
https://cdn.jsdelivr.net/gh/TRHX/ImageHosting/ITRHX-LINKS/tohot.jpg
...
...
@@ -183,7 +180,8 @@ links:
backgroundColor
:
'
#34A853'
textColor
:
'
#fff'
tags
:
-
心念所囚即为牢笼·心念所驻即为坚城
-
海员
-
技术分享
-
name
:
漫道求索
avatar
:
https://cdn.jsdelivr.net/gh/TRHX/ImageHosting/ITRHX-LINKS/yangyufeng96.jpg
...
...
@@ -227,7 +225,7 @@ links:
backgroundColor
:
'
#696969'
textColor
:
'
#fff'
tags
:
-
念念不忘,必有回响
-
机器学习
-
name
:
Mohen's blog
avatar
:
https://cdn.jsdelivr.net/gh/TRHX/ImageHosting/ITRHX-LINKS/mcmohen.jpg
...
...
@@ -251,7 +249,7 @@ links:
-
name
:
Steven_MengのBlog
avatar
:
https://cdn.jsdelivr.net/gh/TRHX/ImageHosting/ITRHX-LINKS/stevenmhy.png
url
:
https://stevenmhy.tk/
backgroundColor
:
'
#
71BCFF
'
backgroundColor
:
'
#
F4606C
'
textColor
:
'
#fff'
tags
:
-
蒟蒻
...
...
@@ -263,7 +261,8 @@ links:
backgroundColor
:
'
#34A853'
textColor
:
'
#fff'
tags
:
-
一个非常爱吃土豆的程序猿
-
JAVA工程师
-
Python
-
name
:
Sublime’s NoteBook
avatar
:
https://cdn.jsdelivr.net/gh/TRHX/ImageHosting/ITRHX-LINKS/sublimerui.jpg
...
...
@@ -275,6 +274,44 @@ links:
-
嵌入式
-
蒟蒻
-
name
:
Singularity
avatar
:
https://cdn.jsdelivr.net/gh/TRHX/ImageHosting/ITRHX-LINKS/singularity2u.jpg
url
:
https://www.singularity2u.top/
backgroundColor
:
'
#0086F1'
textColor
:
'
#fff'
tags
:
-
ACM
-
name
:
暗部精英
avatar
:
https://cdn.jsdelivr.net/gh/TRHX/ImageHosting/ITRHX-LINKS/anbujingying.jpg
url
:
https://anbujingying.coding.me/
backgroundColor
:
'
#53AECA'
textColor
:
'
#fff'
tags
:
-
蒟蒻
-
C++
-
HTML
-
name
:
刘向洋
avatar
:
https://cdn.jsdelivr.net/gh/TRHX/ImageHosting/ITRHX-LINKS/liuxiangyang.jpg
url
:
https://liuxiangyang.space/
backgroundColor
:
'
#E1524C'
textColor
:
'
#fff'
tags
:
-
运维
-
python
-
Linux
-
name
:
松林羊
avatar
:
https://cdn.jsdelivr.net/gh/TRHX/ImageHosting/ITRHX-LINKS/andus.png
url
:
http://www.andus.top
backgroundColor
:
'
#696969'
textColor
:
'
#fff'
tags
:
-
DevOps
-
Java
-
前端
-
group
:
虐狗博主
icon
:
fas fa-heartbeat
items
:
...
...
@@ -332,7 +369,7 @@ links:
-
name
:
中国博客联盟
avatar
:
https://cdn.jsdelivr.net/gh/TRHX/ImageHosting/ITRHX-LINKS/zgboke.png
url
:
https://zgboke.org/
backgroundColor
:
'
#
53AECA
'
backgroundColor
:
'
#
34A853
'
textColor
:
'
#fff'
tags
:
-
中国博客联盟
...
...
@@ -340,7 +377,7 @@ links:
-
name
:
一站之星
avatar
:
https://cdn.jsdelivr.net/gh/TRHX/ImageHosting/ITRHX-LINKS/izstar.png
url
:
https://www.izstar.cn/
backgroundColor
:
'
#
3F51B5
'
backgroundColor
:
'
#
F7474F
'
textColor
:
'
#fff'
tags
:
-
一站之星,学生党博客之家!
...
...
@@ -351,7 +388,7 @@ links:
-
name
:
QQ交流群
avatar
:
https://cdn.jsdelivr.net/gh/TRHX/ImageHosting/ITRHX-LINKS/groups.jpg
url
:
https://jq.qq.com/?_wv=1027&k=5F6HRuG
backgroundColor
:
'
#0
4A8DF
'
backgroundColor
:
'
#0
086F1
'
textColor
:
'
#fff'
tags
:
-
Hugo&Hexo博客群(技术交流)
...
...
@@ -359,7 +396,7 @@ links:
-
name
:
Telegram交流群
avatar
:
https://cdn.jsdelivr.net/gh/TRHX/ImageHosting/ITRHX-LINKS/groups.jpg
url
:
https://t.me/hexoisthebest
backgroundColor
:
'
#
04A8DF
'
backgroundColor
:
'
#
967ADC
'
textColor
:
'
#fff'
tags
:
-
Hexo&Hugo博客(迫真TG分群)
...
...
@@ -372,13 +409,16 @@ links:
---
*
海内存知己,天涯若比邻!相见即是缘分,欢迎各位大佬留言互换友链!
*
互换友链前请先添加本站点为友链!
*
必须要有名称、头像链接、至少一个标签或者一个简介哦~
*
一段时间内无法访问贵站将会被分组到【404 NOT FOUND】,请及时恢复站点!
> * 海内存知己,天涯若比邻!相见即是缘分,欢迎各位大佬留言互换友链!
> * <font color=#FF0000>互换友链前请先添加本站点为友链!若单方面删除本站友链,本站将不再保留贵站友链!</font>
> * 一段时间内无法访问贵站将会被分组到【404 NOT FOUND】,请及时恢复站点!
> * 留言请告诉我你的名称、主页、头像、标签或者简介哦~
> * 如果想定制你的卡片颜色,也可以留言告诉我哦~(十六进制颜色码,如:#FF0000)
---
> 名称:TRHX'S BLOG
> 主页:https://www.itrhx.com/
> 头像:https://www.itrhx.com/images/trhx.png
> 标签:Python、爬虫、前端
> 简介:求知若饥
虚心若愚
> 简介:求知若饥
,虚心若愚!
themes/material-x-1.2.1/_config.yml
浏览文件 @
066b5155
...
...
@@ -4,11 +4,11 @@ info:
docs
:
https://xaoxuu.com/wiki/material-x/
cdn
:
# 把对应的那一行注释掉就使用本地的文件
css
:
style
:
https://cdn.jsdelivr.net/gh/TRHX/CDN-for-itrhx.com@2.
1.9
/css/style.css
style
:
https://cdn.jsdelivr.net/gh/TRHX/CDN-for-itrhx.com@2.
2.1
/css/style.css
js
:
app
:
https://cdn.jsdelivr.net/gh/TRHX/CDN-for-itrhx.com@2.
1.9
/js/app.js
search
:
https://cdn.jsdelivr.net/gh/TRHX/CDN-for-itrhx.com@2.
1.9
/js/search.js
volantis
:
https://cdn.jsdelivr.net/gh/TRHX/CDN-for-itrhx.com@2.
1.9
/js/volantis.min.js
app
:
https://cdn.jsdelivr.net/gh/TRHX/CDN-for-itrhx.com@2.
2.1
/js/app.js
search
:
https://cdn.jsdelivr.net/gh/TRHX/CDN-for-itrhx.com@2.
2.1
/js/search.js
volantis
:
https://cdn.jsdelivr.net/gh/TRHX/CDN-for-itrhx.com@2.
2.1
/js/volantis.min.js
...
...
@@ -33,12 +33,12 @@ music:
mode
:
circulation
# random (随机) single (单曲) circulation (列表循环) order (列表)
server
:
netease
# netease(网易云音乐)tencent(QQ音乐) xiami(虾米) kugou(酷狗)
type
:
playlist
# song (单曲) album (专辑) playlist (歌单) search (搜索)
id
:
2625522030
# 歌曲/专辑/歌单 ID
id
:
3019271605
# 歌曲/专辑/歌单 ID
volume
:
0.7
# 音量, 0~1
autoplay
:
false
# 自动播放
# 友链页头像占位图
avatar_placeholder
:
https://cdn.jsdelivr.net/gh/TRHX/CDN-for-itrhx.com@2.
1.9
/images/bitmap.gif
avatar_placeholder
:
https://cdn.jsdelivr.net/gh/TRHX/CDN-for-itrhx.com@2.
2.1
/images/bitmap.gif
# 日期格式 http://momentjs.com/docs/
date_format
:
'
YYYY-MM-DD'
# 文章发布日期的格式
...
...
@@ -50,8 +50,8 @@ backstretch:
duration
:
5000
# 持续时间(毫秒)
fade
:
1500
# 渐变(毫秒)
images
:
#- https://cdn.jsdelivr.net/gh/TRHX/CDN-for-itrhx.com@2.
1.9
/images/background/017.webp
-
https://cdn.jsdelivr.net/gh/TRHX/CDN-for-itrhx.com@2.
1.9
/images/background/021.webp
#- https://cdn.jsdelivr.net/gh/TRHX/CDN-for-itrhx.com@2.
2.1
/images/background/017.webp
-
https://cdn.jsdelivr.net/gh/TRHX/CDN-for-itrhx.com@2.
2.1
/images/background/021.webp
############################### 自定义 ###############################
...
...
@@ -60,7 +60,7 @@ cover:
scheme
:
search
# 后期将会提供多种封面方案
# height: half # full(默认值): 首页封面占据整个第一屏幕,其他页面占半个屏幕高度, half: 所有页面都封面都只占半个屏幕高度
# title: "TRHX'S BLOG"
logo
:
https://cdn.jsdelivr.net/gh/TRHX/CDN-for-itrhx.com@2.
1.9
/images/logo.png
# logo和title只显示一个,若同时设置,则只显示logo
logo
:
https://cdn.jsdelivr.net/gh/TRHX/CDN-for-itrhx.com@2.
2.1
/images/logo.png
# logo和title只显示一个,若同时设置,则只显示logo
search_placeholder
:
'
世界之大,探索一下!'
# 主页封面菜单
features
:
...
...
@@ -147,7 +147,7 @@ body: [article, comments]
# 侧边栏小部件,默认按下面给定的顺序全部显示,文章中还可以自定义显示一部分以及顺序
sidebar
:
-
widget
:
author
avatar
:
https://cdn.jsdelivr.net/gh/TRHX/CDN-for-itrhx.com@2.
1.9
/images/trhx.png
avatar
:
https://cdn.jsdelivr.net/gh/TRHX/CDN-for-itrhx.com@2.
2.1
/images/trhx.png
title
:
TRHX'S BLOG
body
:
一入IT深似海,从此学习无绝期
social
:
true
...
...
@@ -195,7 +195,7 @@ sidebar:
-
widget
:
plain
icon
:
fas fa-comments
title
:
交流群组
body
:
'
<img
src="https://cdn.jsdelivr.net/gh/TRHX/CDN-for-itrhx.com@2.
1.9
/images/groups.png"><a
id="goroups_button"
class="goroups_button_new"
target="_blank"
href="https://jq.qq.com/?_wv=1027&k=5F6HRuG">QQ
交流群</a><a
id="goroups_button"
class="goroups_button_new"
target="_blank"
href="https://t.me/hexoisthebest">Telegram
交流群</a>'
body
:
'
<img
src="https://cdn.jsdelivr.net/gh/TRHX/CDN-for-itrhx.com@2.
2.1
/images/groups.png"><a
id="goroups_button"
class="goroups_button_new"
target="_blank"
href="https://jq.qq.com/?_wv=1027&k=5F6HRuG">QQ
交流群</a><a
id="goroups_button"
class="goroups_button_new"
target="_blank"
href="https://t.me/hexoisthebest">Telegram
交流群</a>'
# - widget: list
# icon: fas fa-link
# title: 特别链接
...
...
@@ -229,12 +229,12 @@ sidebar:
title
:
"
最近在听"
more
:
icon
:
far fa-heart
url
:
https://music.163.com/#/
playlist?id=2415512873
url
:
https://music.163.com/#/
user/home?id=1379654769
rel
:
external nofollow noopener noreferrer
target
:
_blank
server
:
netease
# netease(网易云音乐)tencent(QQ音乐) xiami(虾米) kugou(酷狗)
type
:
playlist
# song (单曲) album (专辑) playlist (歌单) search (搜索)
id
:
2625522030
# 歌曲/专辑/歌单 ID
id
:
3019271605
# 歌曲/专辑/歌单 ID
# 社交信息
social
:
...
...
themes/material-x-1.2.1/layout/_partial/article.ejs
浏览文件 @
066b5155
...
...
@@ -29,7 +29,7 @@
<%
var items = [];
post.prev.tags.each(function(item){
items.push('<a class="tag" href="'+url_for(item.path)+'"><i class="fas fa-tags fa-fw" aria-hidden="true"></i>' + item.name + '</a>');
items.push('<a class="tag" href="'+url_for(item.path)+'"><i class="fas fa-tags fa-fw" aria-hidden="true"></i>
' + item.name + '</a>');
});
%>
<h6 class="tags">
...
...
@@ -56,7 +56,7 @@
<%
var items = [];
post.next.tags.each(function(item){
items.push('<a class="tag" href="'+url_for(item.path)+'"><i class="fas fa-tags fa-fw" aria-hidden="true"></i>' + item.name + '</a>');
items.push('<a class="tag" href="'+url_for(item.path)+'"><i class="fas fa-tags fa-fw" aria-hidden="true"></i>
' + item.name + '</a>');
});
%>
<h6 class="tags">
...
...
themes/material-x-1.2.1/layout/_partial/footer.ejs
浏览文件 @
066b5155
...
...
@@ -51,7 +51,7 @@
<i class="fab fa-creative-commons"></i> <a rel="license" href="https://creativecommons.org/licenses/by-nc-sa/4.0/deed.zh" title="本站点采用知识共享署名-非商业性使用-相同方式共享 4.0 国际许可协议进行许可" target="_blank">BY-NC-SA 4.0</a> |
-->
<a href="https://www.itrhx.com/sitemap.xml" target="_blank">站点地图</a> |
<a href="https://tongji.baidu.com/" target="_blank">站长统计</a><br><br>
<a href="https://tongji.baidu.com/
web/welcome/ico?s=df0bc7c6bdbd80356ba4db429724ccad
" target="_blank">站长统计</a><br><br>
<div class="github-badge">
<a style="color: #fff" rel="license" href="https://hexo.io/" target="_blank" title="由 Hexo 强力驱动">
<span class="badge-subject">Powered</span><span class="badge-value bg-blue">Hexo</span></a>
...
...
themes/material-x-1.2.1/layout/_partial/post.ejs
浏览文件 @
066b5155
...
...
@@ -15,7 +15,7 @@
<% if (post.tags && post.tags.length) { %>
<div class="full-width auto-padding tags">
<% post.tags.each(function(item){ %>
<a href="<%- url_for(item.path) %>" rel="nofollow"><i class="fas fa-tags fa-fw"></i><%=item.name %></a>
<a href="<%- url_for(item.path) %>" rel="nofollow"><i class="fas fa-tags fa-fw"></i>
<%=item.name %></a>
<%})%>
</div>
<% } %>
...
...
themes/material-x-1.2.1/source/less/_article.less
浏览文件 @
066b5155
...
...
@@ -4,6 +4,9 @@
line-height: @lineheight_base;
word-break: break-all;
word-wrap: break-word;
@media (max-width: @on_phone) {
font-size: @fontsize_base_phone;
}
img {
position: relative;
margin: 0 auto;
...
...
@@ -62,7 +65,7 @@
list-style: initial;
padding-left: 10px;
margin-left: 10px;
margin-bottom: 1em;
/*margin-bottom: 1em;*/
&.center{
justify-content: center;
}
...
...
themes/material-x-1.2.1/source/less/_base.less
浏览文件 @
066b5155
...
...
@@ -68,7 +68,7 @@ fancybox{
.title, .logo{
font-size: @fontsize_h1*3;
line-height: @fontsize_h1*3.3;
margin-top: ~"calc(28vh -
2
*@{gap})";
margin-top: ~"calc(28vh -
1
*@{gap})";
text-align: center;
font-weight: bold;
}
...
...
@@ -112,6 +112,11 @@ fancybox{
left: @iconMargin+1px;
font-size: @fontsize_base;
color: fade(@color_text_main, 60%);
@media(max-width: @on_phone){
font-size: @fontsize_base * 0.8;
height: @searchbar_height_cover * 0.8;
line-height: @searchbar_height_cover * 0.8;
}
}
.input {
display: block;
...
...
@@ -126,6 +131,8 @@ fancybox{
padding-left: @iconW + @iconMargin;
@media(max-width: @on_phone){
padding-left: @iconW + @iconMargin;
font-size: @fontsize_base * 0.8;
height: @searchbar_height_cover * 0.8;
}
border-radius: @height_navbar;
background: @color_bg_code_block;
...
...
themes/material-x-1.2.1/source/less/_color.less
浏览文件 @
066b5155
...
...
@@ -33,9 +33,9 @@
// 标题文字颜色(h3)
@color_text_h3: darken(@color_text_main, 20%);
// 链接颜色
@color_text_link: @
color_md_deep_orange
;
@color_text_link: @
theme_main
;
// 链接高亮颜色
@color_text_highlight: @
theme_main
;
@color_text_highlight: @
color_md_deep_orange
;
// 在主题色中显示的文本(一般为白或深灰)
@color_text_in_header: @white;
// 正文文字颜色
...
...
themes/material-x-1.2.1/source/less/_fonts.less
浏览文件 @
066b5155
...
...
@@ -27,7 +27,8 @@
// 字号
// base
@fontsize_base: 17px;
@fontsize_base: 16px;
@fontsize_base_phone: 14px;
@fontsize_small: @fontsize_base * 0.875;
@fontsize_footnote: @fontsize_base * 0.7;
@lineheight_base: 1.7;
...
...
@@ -39,5 +40,5 @@
@fontsize_h5: @fontsize_base * 1;
@fontsize_h6: @fontsize_small;
// article
@fontsize_article_title: @fontsize_h1 * 1.
2
;
@fontsize_article_title_phone: @fontsize_h2;
@fontsize_article_title: @fontsize_h1 * 1.
1
;
@fontsize_article_title_phone: @fontsize_h2
* 0.9
;
themes/material-x-1.2.1/source/less/_main.less
浏览文件 @
066b5155
...
...
@@ -676,7 +676,7 @@ a.goroups_button_new {
padding: 15px 27px 13px;
margin: 10px auto;
text-transform: uppercase;
width:
@width_sidebar * 0.8
;
width:
90%
;
}
a.goroups_button_new:hover {
background: #04A8DF;
...
...
编辑
预览
Markdown
is supported
0%
请重试
或
添加新附件
.
添加附件
取消
You are about to add
0
people
to the discussion. Proceed with caution.
先完成此消息的编辑!
取消
想要评论请
注册
或
登录