添加OpenCV技术文章
Showing
OpenCV/README.md
0 → 100644
OpenCV/imgs/1.png
0 → 100644
{kind=link}

16.4 KB
OpenCV/imgs/10.jpg
0 → 100644
{kind=link}
85.4 KB
OpenCV/imgs/10.webp
0 → 100644
{kind=link}
文件已添加
OpenCV/imgs/11.jpg
0 → 100644
{kind=link}
116.7 KB
OpenCV/imgs/11.webp
0 → 100644
{kind=link}
文件已添加
OpenCV/imgs/12.jpg
0 → 100644
{kind=link}
102.2 KB
OpenCV/imgs/12.webp
0 → 100644
{kind=link}
文件已添加
OpenCV/imgs/13.jpg
0 → 100644
{kind=link}
96.8 KB
OpenCV/imgs/13.webp
0 → 100644
{kind=link}
文件已添加
OpenCV/imgs/14.jpg
0 → 100644
{kind=link}
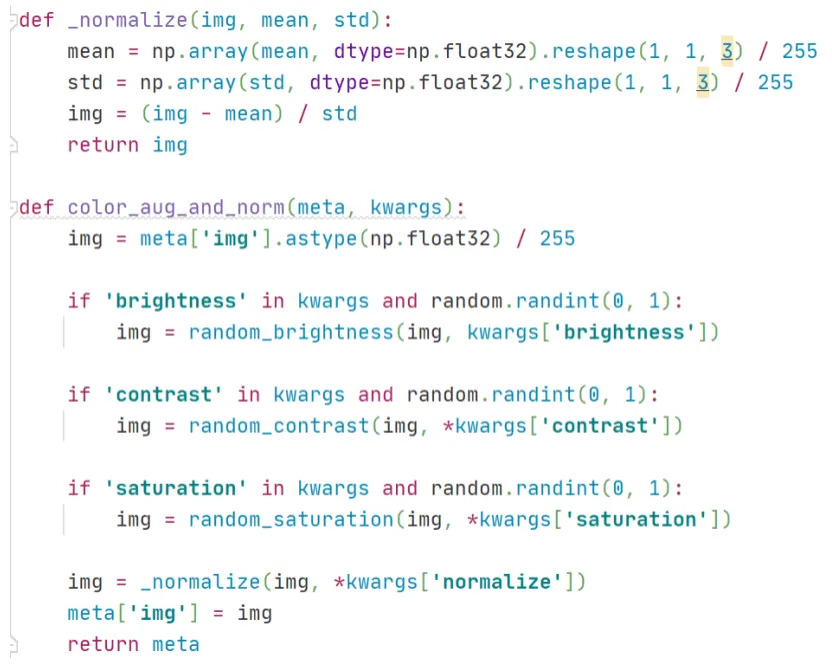
119.4 KB
OpenCV/imgs/14.webp
0 → 100644
{kind=link}
文件已添加
OpenCV/imgs/15.jpg
0 → 100644
{kind=link}
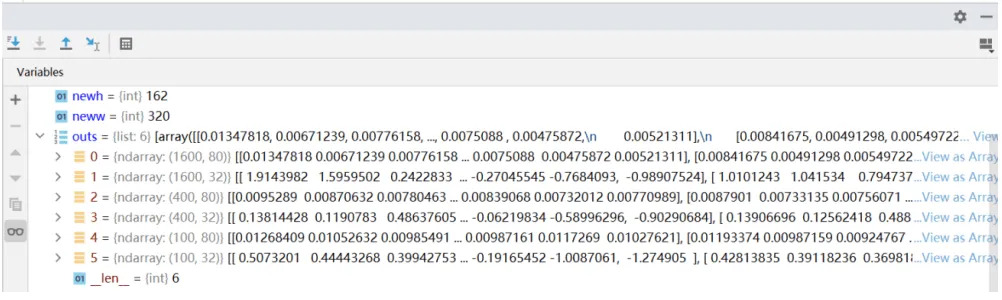
89.8 KB
OpenCV/imgs/15.webp
0 → 100644
{kind=link}
文件已添加
OpenCV/imgs/16.jpg
0 → 100644
{kind=link}
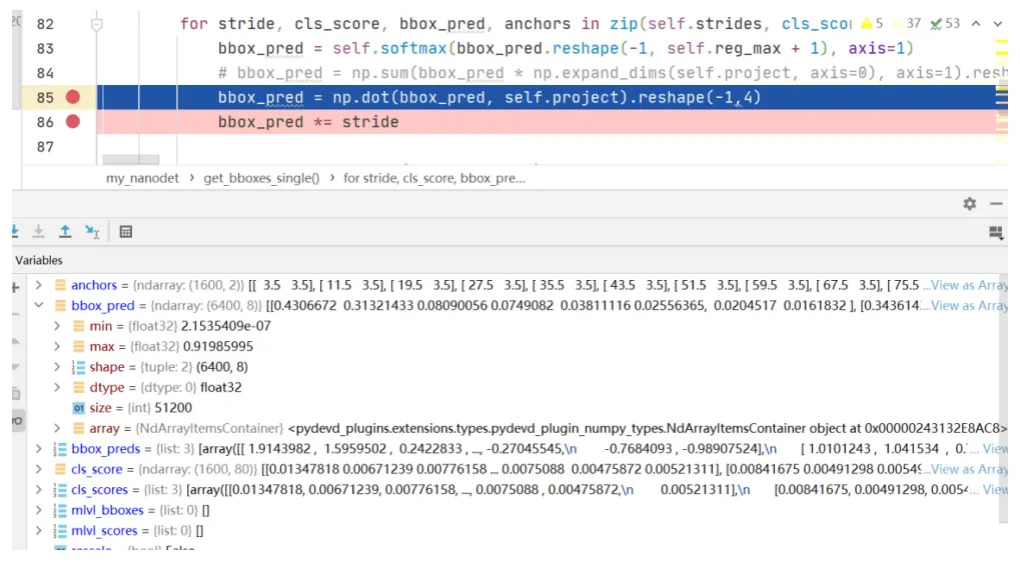
134.8 KB
OpenCV/imgs/16.webp
0 → 100644
{kind=link}
文件已添加
OpenCV/imgs/17.jpg
0 → 100644
{kind=link}
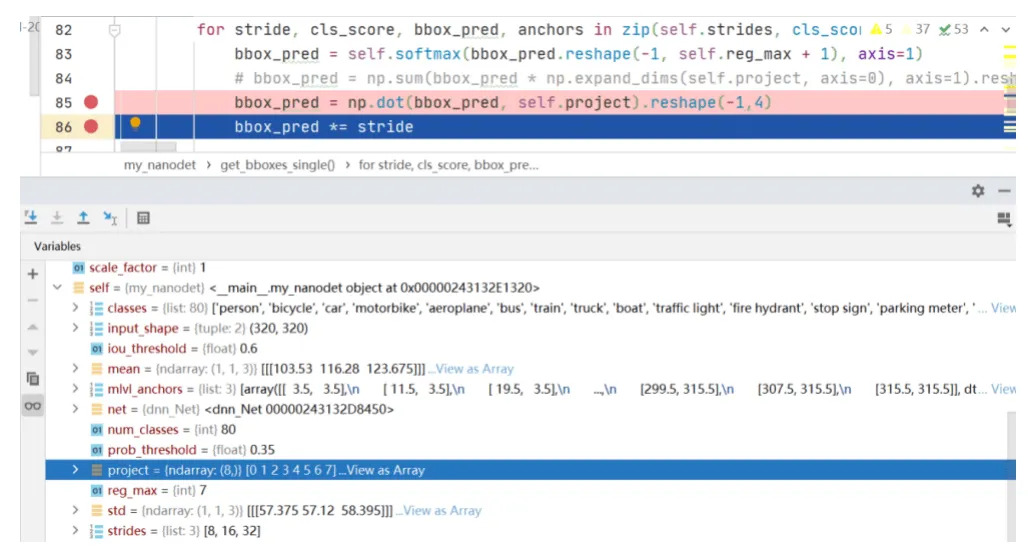
118.5 KB
OpenCV/imgs/17.webp
0 → 100644
{kind=link}
文件已添加
OpenCV/imgs/18.jpg
0 → 100644
{kind=link}
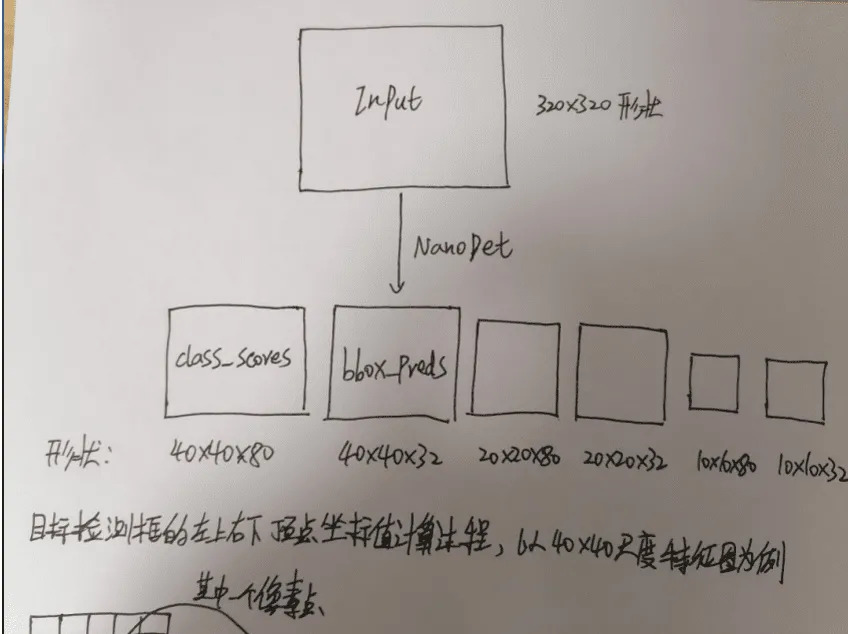
70.8 KB
OpenCV/imgs/18.webp
0 → 100644
{kind=link}
文件已添加
OpenCV/imgs/19.jpg
0 → 100644
{kind=link}
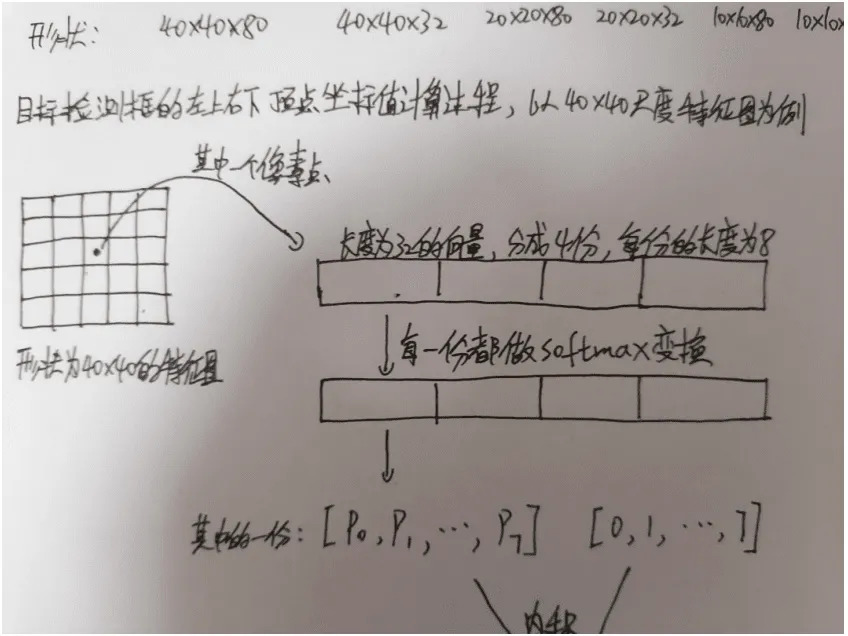
87.6 KB
OpenCV/imgs/19.webp
0 → 100644
{kind=link}
文件已添加
OpenCV/imgs/2.png
0 → 100644
{kind=link}

99.0 KB
OpenCV/imgs/20.jpg
0 → 100644
{kind=link}
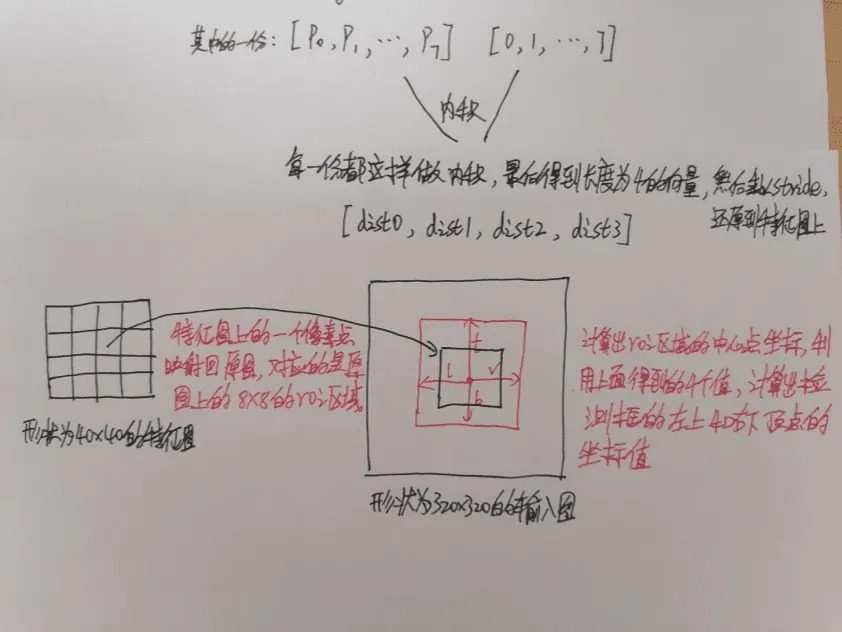
78.5 KB
OpenCV/imgs/20.webp
0 → 100644
{kind=link}
文件已添加
OpenCV/imgs/21.jpg
0 → 100644
{kind=link}

187.2 KB
OpenCV/imgs/21.webp
0 → 100644
{kind=link}
文件已添加
OpenCV/imgs/22.jpg
0 → 100644
{kind=link}

34.8 KB
OpenCV/imgs/22.webp
0 → 100644
{kind=link}
文件已添加
OpenCV/imgs/23.jpg
0 → 100644
{kind=link}

40.7 KB
OpenCV/imgs/23.webp
0 → 100644
{kind=link}
文件已添加
OpenCV/imgs/24.jpg
0 → 100644
{kind=link}
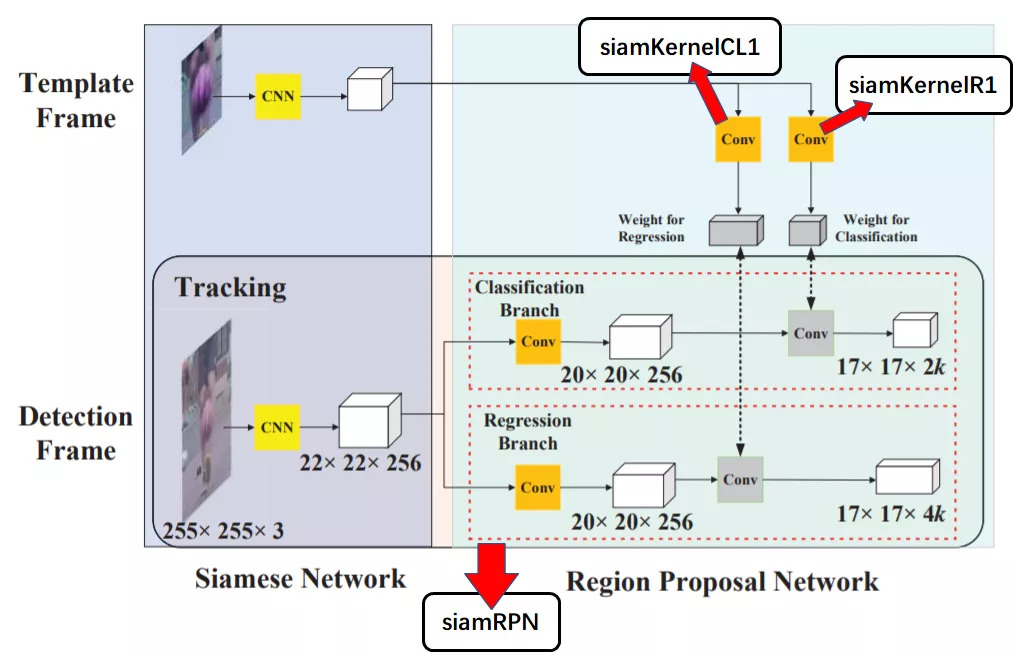
121.2 KB
OpenCV/imgs/24.webp
0 → 100644
{kind=link}
文件已添加
OpenCV/imgs/25.png
0 → 100644
{kind=link}

298.7 KB
OpenCV/imgs/3.png
0 → 100644
{kind=link}

50.7 KB
OpenCV/imgs/4.png
0 → 100644
{kind=link}

166.9 KB
OpenCV/imgs/5.png
0 → 100644
{kind=link}

39.7 KB
OpenCV/imgs/6.png
0 → 100644
{kind=link}
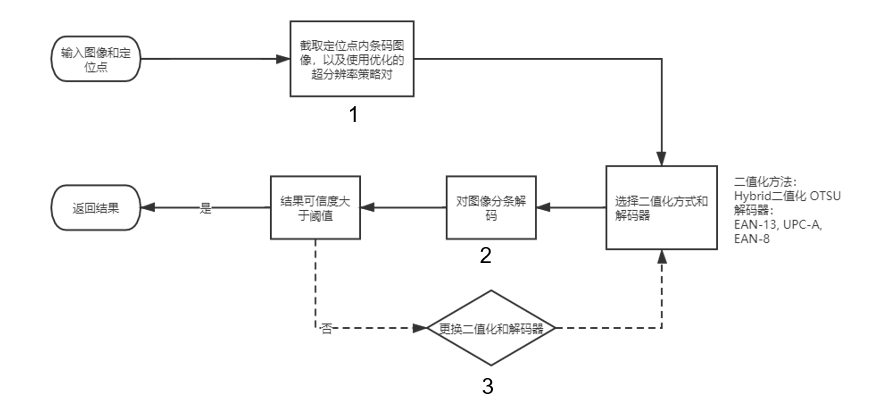
20.3 KB
OpenCV/imgs/7.png
0 → 100644
{kind=link}

731 字节
OpenCV/imgs/8.jpg
0 → 100644
{kind=link}

54.8 KB
OpenCV/imgs/8.webp
0 → 100644
{kind=link}
文件已添加
OpenCV/imgs/9.jpg
0 → 100644
{kind=link}
88.2 KB
OpenCV/imgs/9.webp
0 → 100644
{kind=link}
文件已添加
我爱计算机视觉/imgs/1.jpg
已删除
100644 → 0
{kind=link}
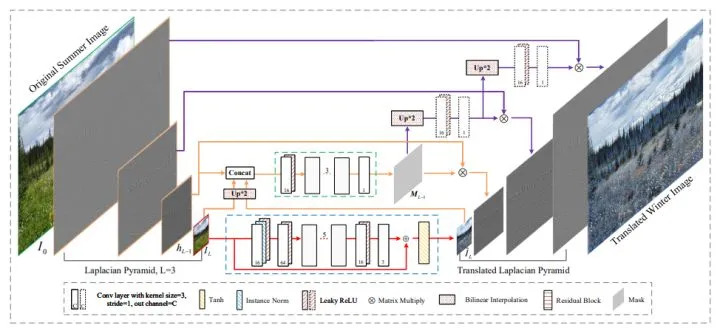
62.2 KB
我爱计算机视觉/imgs/1.webp
已删除
100644 → 0
{kind=link}
文件已删除
我爱计算机视觉/imgs/10.jpg
已删除
100644 → 0
{kind=link}

108.2 KB
我爱计算机视觉/imgs/10.webp
已删除
100644 → 0
{kind=link}
文件已删除
我爱计算机视觉/imgs/2.jpg
已删除
100644 → 0
{kind=link}

168.3 KB
我爱计算机视觉/imgs/2.webp
已删除
100644 → 0
{kind=link}
文件已删除
我爱计算机视觉/imgs/3.jpg
已删除
100644 → 0
{kind=link}
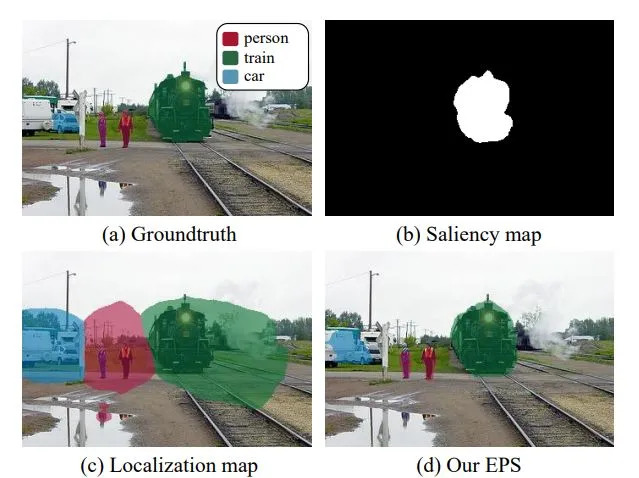
72.5 KB
我爱计算机视觉/imgs/3.webp
已删除
100644 → 0
{kind=link}
文件已删除
我爱计算机视觉/imgs/4.png
已删除
100644 → 0
{kind=link}

385.2 KB
我爱计算机视觉/imgs/5.jpg
已删除
100644 → 0
{kind=link}
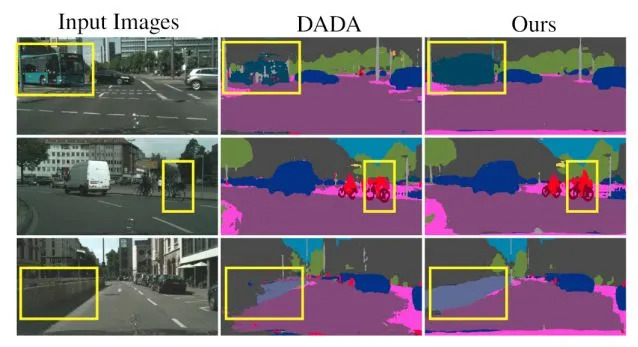
64.4 KB
我爱计算机视觉/imgs/5.webp
已删除
100644 → 0
{kind=link}
文件已删除
我爱计算机视觉/imgs/6.jpg
已删除
100644 → 0
{kind=link}
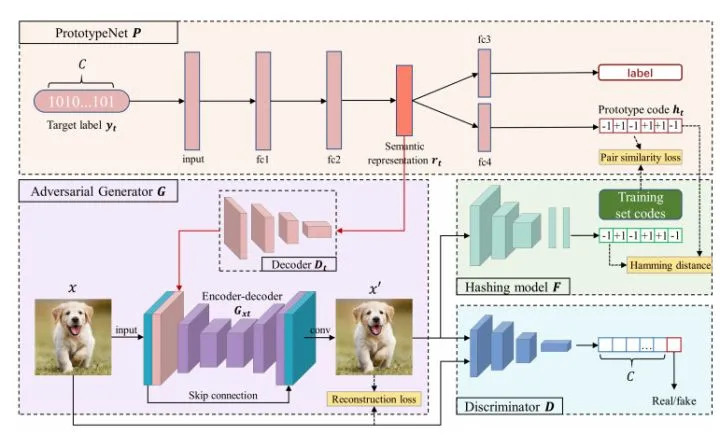
76.9 KB
我爱计算机视觉/imgs/6.webp
已删除
100644 → 0
{kind=link}
文件已删除
我爱计算机视觉/imgs/7.jpg
已删除
100644 → 0
{kind=link}
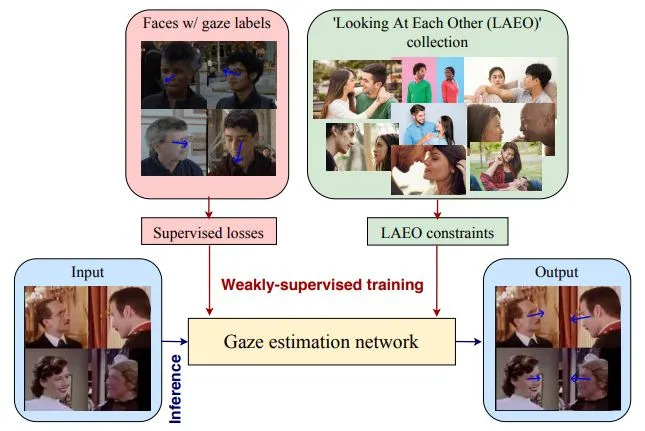
76.3 KB
我爱计算机视觉/imgs/7.webp
已删除
100644 → 0
{kind=link}
文件已删除
我爱计算机视觉/imgs/8.jpg
已删除
100644 → 0
{kind=link}
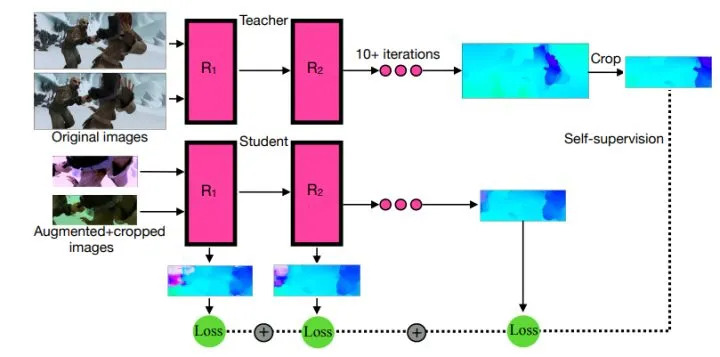
48.2 KB
我爱计算机视觉/imgs/8.webp
已删除
100644 → 0
{kind=link}
文件已删除
我爱计算机视觉/imgs/9.jpg
已删除
100644 → 0
{kind=link}
72.4 KB
我爱计算机视觉/imgs/9.webp
已删除
100644 → 0
{kind=link}
文件已删除